未検出データを追加すべきか、先送りすべきか。
機械学習のためにデータを収集して学習を実行する人のために、経験的な知見をメモしたいと思う。
機械学習に詳しくない人は、「未検出のデータを片っ端から学習データに加えればうまくいくんだろう」と思っているかもしれない。
しかし、経験的に言えば、追加していいデータと追加してはいけないデータとがある。
そのことを以下の説明で述べる。
仮説:少なすぎる追加データは、学習結果の低下をまねく。
機械学習を改良しようとおもう状況は、ちょっとばかり機械学習が動き始めた状況だ。
典型的なポジティブサンプルに対しては検出できるようになり始めた段階だ。
このデータでも検出できればいいのにというわけだ。
「検出できるようにするためには、未検出のポジティブのデータを学習に加えればいいんですよ」というアドバイスにしたがって学習をしてみる。
しかし、意に反して、学習結果は前よりもひどい結果になってしまっている。
そういう経験はないだろうか。
この文章では、なぜそういうことが起こるのか、そういう状況に陥らない方法を述べたいと思う。
学習したのに前よりも悪い結果になったことがないという人は、この文章を読む必要はない。
アルゴリズムはデータの分布の影響を受ける。
機械学習は、教師あり学習だろうが、教師なし学習だろうが、データの分布から特徴に基づいて行われる。
データの分布が簡単であれば、学習はしやすい。
外れ値の影響を受けやすい程度は、アルゴリズムによって異なる。
外れ値の影響を受けすぎる最小2乗法
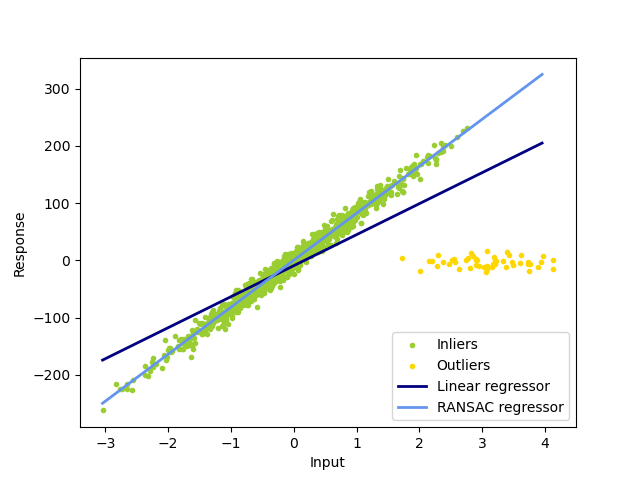
次の図は、scikit-learn の例題か引用する例だ。
外れ値(outliers)の分布によって、回帰直線がどう違ってくるのかがわかる。
データ分析の目的が外れ値を除きた点に対する回帰直線を引きたいのならば、最小2乗法は押す勧めできないことがわかるだろう。
(RANSACのライブラリを使えば、良好な結果が得られる.)
損失関数に及ぼす外れ値の影響
損失関数に残差の2乗和が含まれていると、外れ値は1つあたりの残差が他のデータよりも大きいために、他のデータよりも1個あたりの影響力が大きくなってしまう。
そのため、損失関数を残差の2乗和だけで定義しているアルゴリズムは、たいがいうまくいかない。
そのため、損失関数の定義には正則化項が加わっている。
データはどう分布しているのか
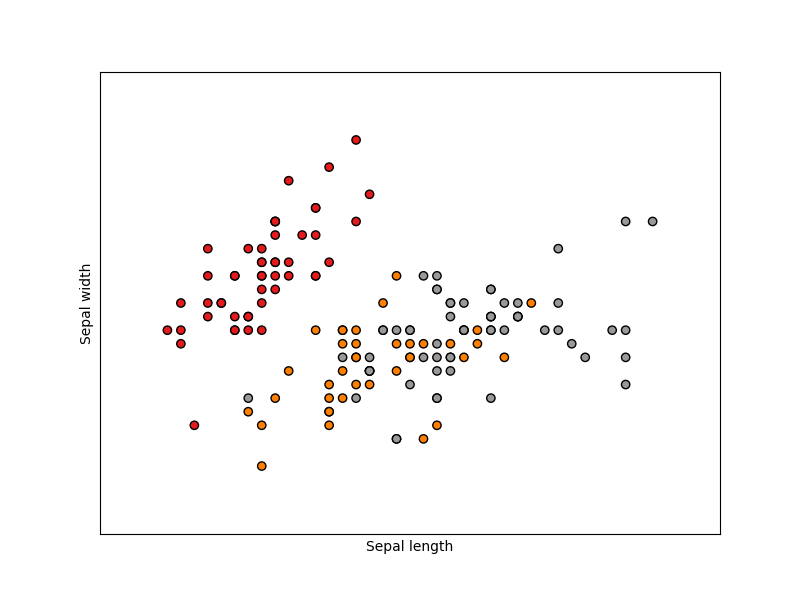
次に示す例はIris dataset (アヤメの花弁の形状のデータセット)です。
 )
)
この程度のデータセットの場合には、2次元、3次元プロットでデータの分布を可視化することができます。
それによって知見を得て次に進むことができます。
多次元のデータではどうしたらよいか
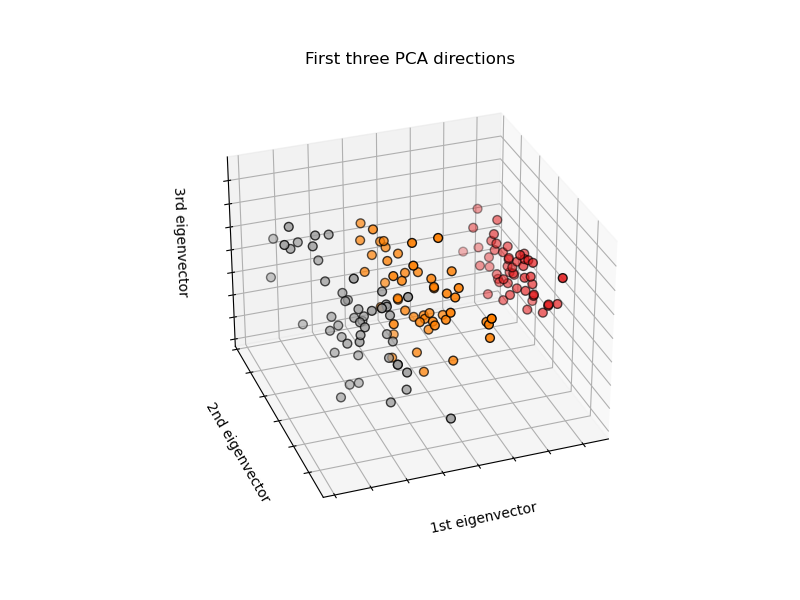
- 主成分分析を行い、第1主成分軸・第2主成分軸によるデータのプロット
次のスライドの中には、第1主成分軸・第2主成分軸によるプロットが示されています。
「データの分布が線形モデルで扱えないんですけど」にはカーネル主成分分析
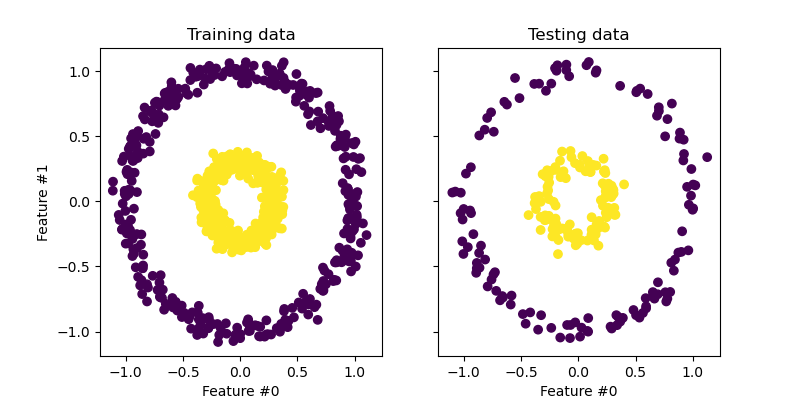
同心円状にデータが分布している場合には、元々の主成分分分析では、データの分布が分離しやすい分布に帰られていません。
しかし、カーネル主成分分析では、左下のプロットのようにデータが明確に分離しやすい分布に置き換えられています。
非線形のデータの分布もこのようにして可視化することができます。
最近人気の次元圧縮 t-SNE による可視化
最近見かけることの増えている可視化手法は、t-SNE を用いている手法だ。
qiita t-SNEによるイケてる次元圧縮&可視化

MNISTの手書き数字のデータセットの分布をt-SNEで2次元プロットにしたもの。(上記のqiitaのページから引用)
こういった例題を眺めながら、自分の扱っているデータはどういう素性のデータでどんな分布をしているのだろうかと想像力を働かしてみよう。
未検出データは、これらのデータの分布のどこに位置しているのかを想像してみよう。
機械学習に用いる学習モデルの自由度
低すぎる自由度のモデルの限界
HaarCascade検出器では、異なる顔向きを扱えない。
低すぎる自由度では、そのモデルで表現できる内容に限界がある。
そのため、学習後の残差が大きなまま残ってしまう。
正面顔の学習データに、横顔の学習データを追加して、HaarCascade学習器を実行してみよう。
横顔のデータを加えることで著しい性能の劣化を生じたはずだ。
横顔を検出できないだけではない。
従来とれていた正面顔さえとれなくなったはずだ。
「検出が不十分なときには、未検出のポジティブサンプルを与えるだけで
うまくいくようになる」は間違いであることに気づいてもらえたろうか。
機械学習の問題は、どうデータを与えるのかというのが、
エンジニアが取り組む価値のある問題であることがわかってもらえただろうか。
高すぎる自由度が生み出す不幸な結果
(いろいろあります。後日追加予定)
使用している機械学習アルゴリズムの癖を理解しよう。
機械学習アルゴリズムによっては癖があります。
- 区別しやすいポジティブサンプルだけ増やしていくと、従来と検出できていたものさえ検出できなくなるアルゴリズム。
- 少数の外れ値によって結果が影響を受けすぎるアルゴリズム。
- 学習データに対する残差はとても小さくなるのだが、テストデータに対する残差は減らず、汎化性が不十分なアルゴリズムと学習パラメータの組み合わせ。
- 学習データの与える順序によって、学習結果の性能が大きく変化する学習アルゴリズム。
こういったことを考慮して、学習データを作成していくことです。
ポジティブデータのクラスタ
ポジティブデータとネガティブサンプルの境界の精度がでないポジティブデータの分布があると、そこが誤検出を誘発する。
そのことがわかってもらえただろうか。
今加えようと考えている未検出データを加えたときに、何が起きるのかを想像してみることです。
夜間の屋外でのものの見え方と昼間のオフィス内のものの見え方はまったく異なります。
夜間の屋外データを対象とする必要性がなければ、夜間の屋外データを対象に加えてはいけません。
夜間の屋外データを扱えるようにするための必要なデータの収集な並大抵の努力ではないことを覚悟してください。
夜間の屋外でしかも雨が降っているときのカメラ画像(しかもレンズには水滴がついてしまったりする)での歩行者検出というのは、あまっちょろい話ではないことを覚悟して取り組んでほしい。
- 路面反射で、人の陰が2重に映ります。
- レンズについた汚れに光があたって、そこからの散乱光が、視認性を低下させます。
ではどうすればよいのか
- 外れ値の影響を受けにくいアルゴリズムを使うこと
- 外れ値の影響を受けにくいパラメータ設定
- 悪影響を引き起こしにくいポジティブサンプルの追加
もう少しで検出できるポジティブサンプルと手強いポジティブサンプル
もう少しで検出できるポジティブサンプルの特徴
既存の検出器でしきい値を少し緩めるだけで検出できるようになるデータ。
データの分布を可視化した際に、従来から成功しているデータのクラスタにとても近接していて、ネガティブサンプルのクラスタとは離れているデータ。
このようなデータの場合には、悪影響を与えることが少なく、ポジティブサンプルを増やしていくことによって改善していきます。
手強いポジティブサンプル
手強いポジティブサンプルは。今までの学習結果での判定では、スコアが低くて簡単には改善できないものです。
しかもデータの分布を可視化したときには、従来のポジティブサンプルのクラスタとはかなりかけ離れていたりします。
しかも、そのようなポジティブサンプルのデータの収集が簡単ではなかったりすることがあります。
例として画像でのオブジェクト検出をあげてみます。
人検出器がほどほどにできているとします。ここに、傘をさしている人の検出を追加したいと思います。
黒い傘をさしている人の頭部は、傘に隠れてしまうことがあります。
そのため、頭部が見えていることを前提としていた人検出器では検出できないことが想定されます。
(実際にそのような画像で検出を試してみればはっきりします。)
透明なビニール傘をさした人で試してみましょう。
(おそらく、こっちは検出したんじゃないかな)
透明ではない傘で、前からみて人の頭部が見えているのにも試してみましょう。
(検出できたり、検出できなかったりというところでしょうか)
- 今はあきらめることも必要。
最初の改善としては、今検出できている透明なビニール傘の人・傘をした人のうち頭部が隠れていない人に限って、学習データを追加してみましょう。
この場合ならば、従来検出できていたものに近い範囲でポジティブサンプルを増やすことになるので、学習結果が破綻する危険を減らすことができます。
透明のビニール傘での学習を進めておけば、それに近い半透明の色付きのビニール傘でも検出できる可能性がでてくるかもしれません。
- 透明の透明のビニール傘の人の検出・傘をした人のうち頭部が隠れていない人の検出がうまくいくようになったら
いよいよ、頭部が隠れてしまう場合の傘をした人の検出です。
アドバイス
- 傘をした人のデータを多数、多様性を確保しながら集めます。
- 傘をさして頭部が隠れる度合いによって、データを分けます。
- 傘による頭部の隠れが少ないデータから学習に加えます。
- 適合率の改善が足らないときには、傘をさした人物の画像を増やしていきます。
- 傘の色を変える・傘の模様を変える・傘の持ち方を変える・被写体の人の服装を変える。持ち物を変える。
- 撮影時の背景を変える。撮影時の光の当て方を変える。撮影するカメラの高さを変える。
-そのような工夫をして学習データに追加していってみる。
このような努力でデータを増やしていくことで、ポジティブサンプルとネガティブサンプルの境界を決める学習が可能になるのではないかと推測します。
未検出データを十分に増やしてからだと、なぜうまくいきやすくなるのか
- 未検出データを増やしていく、そのデータのクラスタの分布が見えてくるようになります。
- そうするとその分布の広がりも明確になってきます。どの程度分布の裾を引くのかがわかるようになってきます。
- 主成分分析に基づく手法を考えてみると、データの数が増えてくると、その未検出データに基づく主成分が明確に見えてくるようになります。そうするとそのデータの特徴を利用した判定がしやすくなります。
- 未検出データを十分に増やしていくと、仮にその未検出データだけをポジティブサンプルとした学習を実施したときでも十分なデータの分離ができるレベルになってきます。
適合率を改善するには
- 適合率を改善するためには、ネガティブサンプルの背景画像を増やしていく必要がある。
- やみくもに今までとおなじような特徴をもつ画像群を同じような頻度で加えるよりは、効果的な方法があるかもしれない。
効果的な方法の案
- 物体検出で誤検出しやすいものは、凸物体で色あいが似たものがありうる。
- 手法:
- 検出対象の物体と似た色合いの凸物体を集中的に集めて、背景画像として学習・評価用に追加する。
- 期待している内容:
- 追加した一群の画像中の色合いの似た凸物体と、検出対象物とを区別する境界面の精度が向上する。
- そのために、ポジティブサンプルを検出するために利用する特徴量の選択の精度が向上する。
あなたの今の状況を確認しよう
- プロジェクトの中でのその未検出のおよぶ影響の範囲と影響の大きさを確認しよう。
- 未検出を改善するために必要になるデータ収集のコストを見積もってみよう。
チームとしての判断をして、検出目標と先送り項目を決めよう
多くの未検出データの中から、改善するターゲットのポジティブサンプルを絞りこもう
- そのパターンのデータの出現頻度
- そのパターンのポジティプサンプルのデータ取得のしやすさ
- データを取得するための実験の立案と実行
- 改善できているか判断できるための評価データのサブセットを用意すること。
- 学習後、そのサプセットの再現率・適合率が学習の前後で確認されたかを確認する。
- 検出結果に変化を生じた部分を確認する。
これがあなたの問題へのヒントになれば幸いです。
追記(2020.12.01)
SSII2020 オーガナイズドセッション [限られたデータからの深層学習]
(https://confit.atlas.jp/guide/event/ssii2020/static/organized#OS2)
を参考にして、ドメイン適応などの手法を適用すれば、この文章の中に書いた問題が軽減される可能性があります。