はじめに
機械学習のイントロダクションとして世界一メジャーな存在となっているCoursera Machine Learning。Matlab/Octaveのプログラミング課題を勉強しがてらPythonで実装してみるシリーズ第3回です。
今回はex3の前半、ロジスティック回帰を用いて手書き数字を認識するタスク。データセットはMNISTのサブセットということで、20x20ピクセルのグレースケール画像が5000枚、これがMatlab/Octaveの.matというデータ形式で与えられています。
実は、scikit-learnにはfetch_mldata()という関数があり、これでMNISTのデータ(28x28ピクセル、70000枚)をダウンロードすることもできます (→ こちらの記事参照:多層パーセプトロンでMNISTの手書き数字認識 )が、今回は比較のために、上記の.matデータを利用することにします。
なお、ex3の後半はニューラルネットワークのforward propagation部分だけ作成するというちょっと中途半端な内容なので、割愛します。
コード
データも整形されており、scikit-learnのLogisticRegressionクラスを使うだけなので、シンプルなコードです。Matlabの.mat形式のデータは、Scipyのscipy.io.loadmat()関数を使って読み込むことができます。
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as scio
from sklearn import linear_model
# scipy.io.loadmat()を使ってmatlabデータを読み込み
data = scio.loadmat('ex3data1.mat')
X = data['X'] # X は 5000x400 行列
y = data['y'].ravel() # y は 5000 x 1 行列、ravel()を使って5000次元ベクトルに変換
model = linear_model.LogisticRegression(penalty='l2', C=10.0) # モデルの定義
model.fit(X,y) # 訓練データで学習
model.score(X,y) # 訓練データでの正答率
実行すると、訓練データでの文字認識の正答率が0.96499999999999997 と表示されました。
機械学習的ポイント
正則化の強さを表すパラメータ$\lambda$はCourseraでは$\lambda=0.1$となっていました。前回の記事でもご紹介したとおり、sklearn.linear_model.LogisticRegressionクラスでは正則化パラメータは$C$($\lambda$の逆数に相当)で指定するため、今回はC=10.0としてモデルを定義しました。
結果、訓練データでの正答率は上記のように96.5%。Matlab/Octaveでの結果は94.9%だったので、ややオーバーフィット気味?理由はよくわかりません。
その他ポイント
これだけだとあっさりしすぎなので、認識を間違えたデータを表示するコードも書いてみました。
上記モデルで学習すると、訓練データ5000のうち175を間違って判定します。このうちランダムで選んだ25個について、画像とともにラベル(どう間違えたか)を表示してみます。
wrong_index = np.array(np.nonzero(np.array([model.predict(X) != y]).ravel())).ravel()
wrong_sample_index = np.random.randint(0,len(wrong_index),25)
fig = plt.figure()
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.5, hspace=0.5)
for i in range(0,25):
ax = fig.add_subplot(5,5,i+1)
ax.axis('off')
ax.imshow(X[wrong_index[wrong_sample_index[i]]].reshape(20,20).T, cmap = plt.get_cmap('gray'))
ax.set_title(str(model.predict(X[wrong_index[wrong_sample_index[i]]])[0]))
plt.show()
- 1行目:
np.array([model.predict(X) != y])で、認識を間違えたらTrue、正解したらFalseが入った行列(5000x1)を取り出します。それをnp.nonzero()関数に入れると、Trueのデータのインデックスが入った行列が手に入ります。最終的にはベクトルで取り出したいので、.ravel()を2回使っています。 - 2行目:
wrong_sample_indexは、1行目で取り出した間違えたインデックスの入ったベクトル(この場合は175個)の中から、ランダムで25個取り出すために作成したインデックスです。 - 表示は
pyplotのsubplotを使って、5x5のサブプロットで表示します。 -
set_titleのところで、画像のタイトルとしてモデルがつけた(間違った)ラベルを表示します。ラベルはmodel.predict(X[wrong_index[wrong_sample_index[1]]])で取得しますが、1x1行列として返ってくるため、[0]をつけてスカラーとして取り出します。
結果はこのとおり。
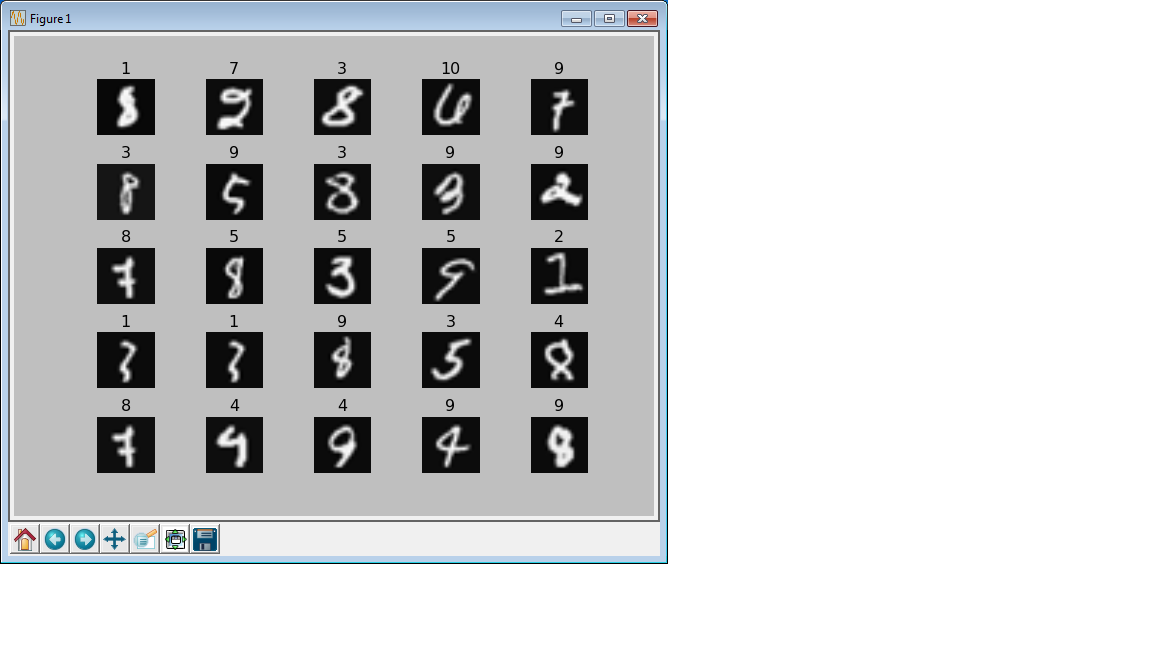
4を9と間違えるとか、その逆とか、何となく納得できる間違いもありますが、そうでないのもありますね。まあ、何の特徴抽出もしないでただピクセルデータをロジスティック回帰しただけなので、こんなものなのかもしれません。それよりもややオーバーフィット気味かもしれませんので、Courseraでは後のモジュールで出てくる内容のCross Validationなどを用いて、適切な正則化パラメータ$C$を選んだほうがいいようです。