はじめに
- Sparkの用語や処理の流れのメモです。
Sparkとは
Apache Spark™ is a unified analytics engine for large-scale data processing.- 大規模データに対して高速に分散処理を行うオープンソースのフレームワーク。大量のメモリを活用して高速化を実現するのが特徴。
Sparkの仕組み
アーキテクチャ
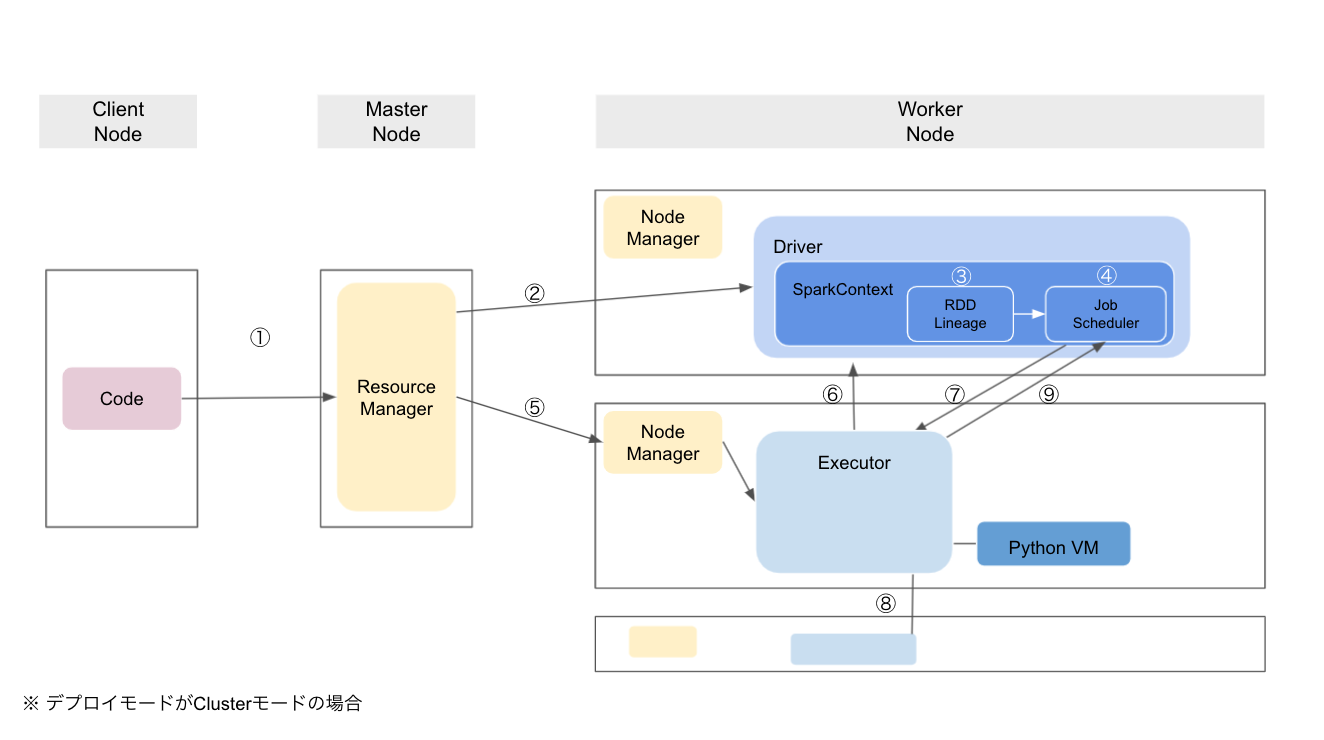
- Clientモードの概要図は、Spark Architectureが分かりやすい
処理の流れ
①ClientがResource Managerに、DriverとExecutorの割り当てを依頼する
- Executorの数、要求するリソース量(コア数/メモリ量)などを指示する
- Driverの位置がURLで返される
- Clientモードの場合は、DriverプログラムがCluster Managerに対してResource Negotiationをかける
| 用語 | 意味 |
|---|---|
| Application | ・Driverプログラム + Executor から構成される ・ApplicationごとにExecutorが起動され、共有されることはない |
| Driver | ・SparkContextオブジェクトを生成するコンポーネント(DataFrameやDataset APIの場合はSparkSession) ・-> SparkContextがSparkアプリケーション全体を通して状態を管理して、様々なAPIをユーザーに提供する ・RDDの生成や変換の処理を記述したもの ・-> ユーザプログラムをTaskに変換し、Executorに実行を命令する + Actionに伴いExecutorからデータを取得する ・Executorは起動時に自分自身をDriverに対して登録するため、Driverは自分のApplicationのExecutorの様子を常に把握できる ・インタラクティブシェルの場合は起動時にClient側で生成されているので、明示的に用意しなくて良い ・インタラクティブシェルであっても、クラスタ上で分散処理ができる ・spark-shellとspark-submit ・JVM上で動作する |
| Executor | ・Driverから命令されたTaskを実行する ・Worker Nodeごとに1プロセス起動し、その中で複数のスレッドを起動する ・RDDをキャッシュする ・JVM上で動作する |
| 用語 | 意味 |
|---|---|
| Clientモード | ・Client側でDriverプログラムが実行される |
| Clusterモード | ・Application Master上でDriverプログラムが実行される (ApplicationがsubmitされてSparkContextが生成されると、SparkContextはCluster Managerに処理を実行するためのコンピュートリソースをリクエストする) |
| 用語 | 意味 |
|---|---|
| Resource Manager, Node Manager | ・Standalone, Yarn, Apache Mesos, Kubernetesから選択できる ・Standalone: Hadoopなしで動作する |
②Worker Nodeにて、Driverを起動する
③Driverが、ユーザが記述したRDD変換手順からLineageを作成する
- ユーザプログラムがTransormationを組み合わせてRDD参照グラフを作成(③)
- -> ユーザプログラムがActionを実行
- -> DriverがRDD参照グラフからStageのDagを作成(④)
- -> Executorに各Stageの処理を命令する(⑦)
- -> Actionに伴いExecutorからデータを取得する(⑨)
④Lineageを元に、JobをTaskに分割し、個々のTaskをSckedulerに割り当てる
| 用語 | 意味 |
|---|---|
| RDD, Dataframe, Dataset | ・処理対象データセット。データコレクションの抽象表現。 ・パーティションという単位に分割されてノードごとに分散配置される ・イミュータブル。再利用前提なので。処理の中で新しいRDDを作っていく。 ・キャッシュや複数ノードへのレプリケーションのため ・イミュータブルでないと値が変更されるたびにキャッシュを複数ノード間で同期する必要があり、複雑な処理が必要になる ・入力データを読み込みRDD化して、RDDに対して次々に変換を行ったあと、最終的に結果を出力する ・インターフェイスは2つ ・Transormation ・既存のRDDから、変換処理などを通じて新しいRDDを作り出す ・Action ・Driverにデータを戻したり、外部にデータを書き込んだり ・Actionのタイミング(=実際にデータが必要になるタイミング)で遅延実行される ・PythonはDataframe |
| Lineage | ・RDD参照グラフ ・LineageからDAGが生成される ・DAGをさかのぼることで同一のRDDを作り直すことができる ・Sparkは、データセットとしてのRDDとプログラミングモデルとしてのDAGの2つがコアアイデア+オンメモリでの分散処理に特化していること |
| Scheduler | ・Dag SchedulerとTask Scheduler ・Dag SchedulerがLineageをStageに分割する ・-> パーティションごとにExecutor1つがまとめて計算できる変換の範囲を決めるため ・DAG: RDDを変換していく過程。論理実行プラン。 ・JobをTaskに分割したり、TaskをExecutorに割り当てる |
| 用語 | 意味 |
|---|---|
| Application | ・submitする単位 |
| Job | ・RDDの変換を繰り返して目的の結果を得る一連の処理 ・独立した実行アクション ・Actionを実行するとJobが作成される |
| Stage | ・JobはShuffleが必要となるタイミングで複数のStageを分ける ・<- 別パーティションが必要となるタイミングでShuffleが発生する |
| Task | ・最小実行単位 |
⑤Executorを起動するWorker Nodeを割り当てる
⑥Jobに割り当てられたExecutorをDriverに通知する
⑦Driverが、ExecutorにTaskを割り当てる
- アプリケーションコードをExecutorに送ってTaskを実行する