最近、マルチエージェント開発に関して、Cognition AI は「Don’t Build Multi-Agents」という記事を公表し、コンテキストエンジニアリングの原則を提唱し、原則に従わないマルチエージェントは本番運用に脆弱だと警鐘を鳴らしている。これに対して、Anthropic は「How we built our multi-agent research system」という記事を公表し、探索型リサーチではマルチエージェントによる並列化が 90 % 以上の精度向上という成功例を公開した。そして、LangChain Blog は「How and when to build multi-agent systems」にてコンテキストエンジニアリングの重要性を再確認し、エージェントは解決したい問題に応じて適材適所で使えと主張した。
とても勉強になる記事だ。何も考えずにマルチエージェントを作ろう!は危ないと思った。
本稿ではこの三者の主張を整理し、AutoGen の機能(GraphFlow/GroupChat+Filter/Memory+RAG/UserProxyAgent/Tracing ほか)がどのように各主張を吸収・実装できるかを考えたい。
各社の主張
Cognition AI「Don’t Build Multi-Agents」
コーディングタスクの並列化についての例を示しながら、「コンテキストエンジニアリングの原則」を提唱。
- 完全なコンテキスト共有がなければ誤解が連鎖する
- 各行動に暗黙の決定が含まれ衝突する
- 現状のフレームワークはこの 2 原則を満たせず「マルチエージェントは本番に脆弱」と主張
問題の解決策としてシングルスレッドのシーケンシャルエージェントを推奨しつつコンテキスト圧縮の必要性についても紹介している。
Anthropic「How we built our multi-agent research system」
マルチエージェントの効果と適用領域
-
幅優先クエリ(探索型リサーチ)で特に有効
例:S&P500 の IT 企業取締役全員の特定など、ひとつの問いに対して「複数の独立した方向性」を同時に追いかけるタスクで 90.2% ものパフォーマンス向上。リードエージェント(Opus 4)がタスクを分割し、サブエージェント(Sonnet 4)が並列処理。単独 LLM は逐次サーチしかできず失敗。 -
全エージェントが同じコンテキストを共有する必要が高いタスクや、依存度の高い領域(コーディングなど)には現状不向き。リアルタイムな協調や委任には未熟。研究タスクのような並列化可能な領域で最大効果。
-
アーキテクチャ:オーケストレーター・ワーカー型
リードが全体進行を調整し、各サブエージェントが専門タスクを担当。
この記事、インサイトフルすぎる・・・
あれ、この時点で議論しているタスクがそれぞれちゃうやんけ!
と思ったあなた、この二社に対して LangChain Blog が反応した。
LangChain Blog「How and When to Build Multi-Agent Systems」
「コンテキストエンジニアリング」が重要だ!
- 単一エージェントでも複数エージェントでも、モデルへの“やるべきこと”の文脈を正確に提供するのが難しく、これがエージェント設計のコア課題
- 二者のコーディングタスクとリサーチタスクから得られた重要な知見は、読み取りアクションは書き込みアクションよりも本質的に並列化しやすいということ
- 一方で、ライティング系タスクはエージェント間で書き分け・統合作業が必要なため、競合や矛盾が発生しやすく、並列化によるコスト・複雑性が上がる
- 非決定的な LLM 実行の可視化とデバッグ性に対応するため、トレースや可観測性が重要
- Anthropic の「エージェントの効果的な評価」というセクションを高評価
まとめると…
適材適所
Cognition AI の警告は、コーディングタスクにおいて、完全なコンテキスト共有がなければフランケンシュタインのようなプログラムが生まれてしまう。このようなタスクを対応策なくマルチエージェントにするのは危険だ。ただ、Anthropic が示すように研究・探索のような “広く探し狭く絞る” タスクではマルチエージェントが劇的効果を発揮している。つまりこれは適材適所で使い分けようということか。
設計原則は収束してきている?
Anthropic と LangChain は共に「コンテキスト管理・評価」に重点を置いている。Cognition AI も適切なコンテキストの共有に重点を置いている。
| 会社 / 記事 | 主張(概要) | 推奨アーキテクチャ・設計指針 | 懸念・制約 |
|---|---|---|---|
|
Cognition AI 「Don’t Build Multi-Agents」 |
- 原則①: Share context(エージェント間で完全な履歴を共有せよ) - 原則②: Actions carry implicit decisions(暗黙の決定が衝突すると破綻) |
- 単線型(Single-thread)エージェントを基本に、必要なら履歴圧縮モデルを挟む階層構造を提案 | - 並列化するとコンテキストの分散・決定衝突で信頼性低下 - クロスエージェントコンテキスト伝搬の研究が未成熟で、導入コストが見合わないと警告 |
|
Anthropic 「How We Built Our Multi-Agent Research System」 |
- オーケストレータ+並列サブエージェントで研究タスクを高速化し、単独 Opus4 に比べ 90.2 % 上回る精度を達成 - 性能の 95 % を説明する要因は「トークン数・ツール呼び出し数・モデル選択」 |
- 徹底的なプロンプトエンジニアリング - スケーリングルールを導入: - 簡易事実→1 agent/3-10 calls - 比較→2-4 agents/10-15 calls - 複雑研究→10+ agents と タスクごとの“努力予算” をプロンプトに埋め込む - Tool-Testing Agent でツール記述を自動改善し 40 % 時間短縮 |
- マルチエージェントは トークン消費がチャットの約 15 倍、コスト高 - 全員が同一コンテキストを要するコーディング等には不向き - 同期処理はボトルネック、非同期化は調整や一貫性の新たな課題 |
|
LangChain Blog 「How and When to Build Multi-Agent Systems」 |
- Cognition と Anthropic の両記事を踏まえ 「コンテキストエンジニアリングが肝」 と総括 - 「読むタスク(情報収集)は並列化しやすいが 書くタスクは衝突リスクが高い」 |
LangGraph は LLM に渡される内容と、LLM に渡されるコンテキストを生成するために実行されるステップとその順序を完全に制御可能 | 長期対話では 永続実行・観測性・評価 の新ツールが必須(LangSmith 等) |
特に Anthropic による「研究エージェントの迅速なエンジニアリングと評価」の 8 項目および付録は一見の価値がある。
結局のところ・・・
Context Egineering(コンテキストエンジニアリング)の重要性
「AIの新しいスキルはプロンプティングではなくコンテキストエンジニアリングです」
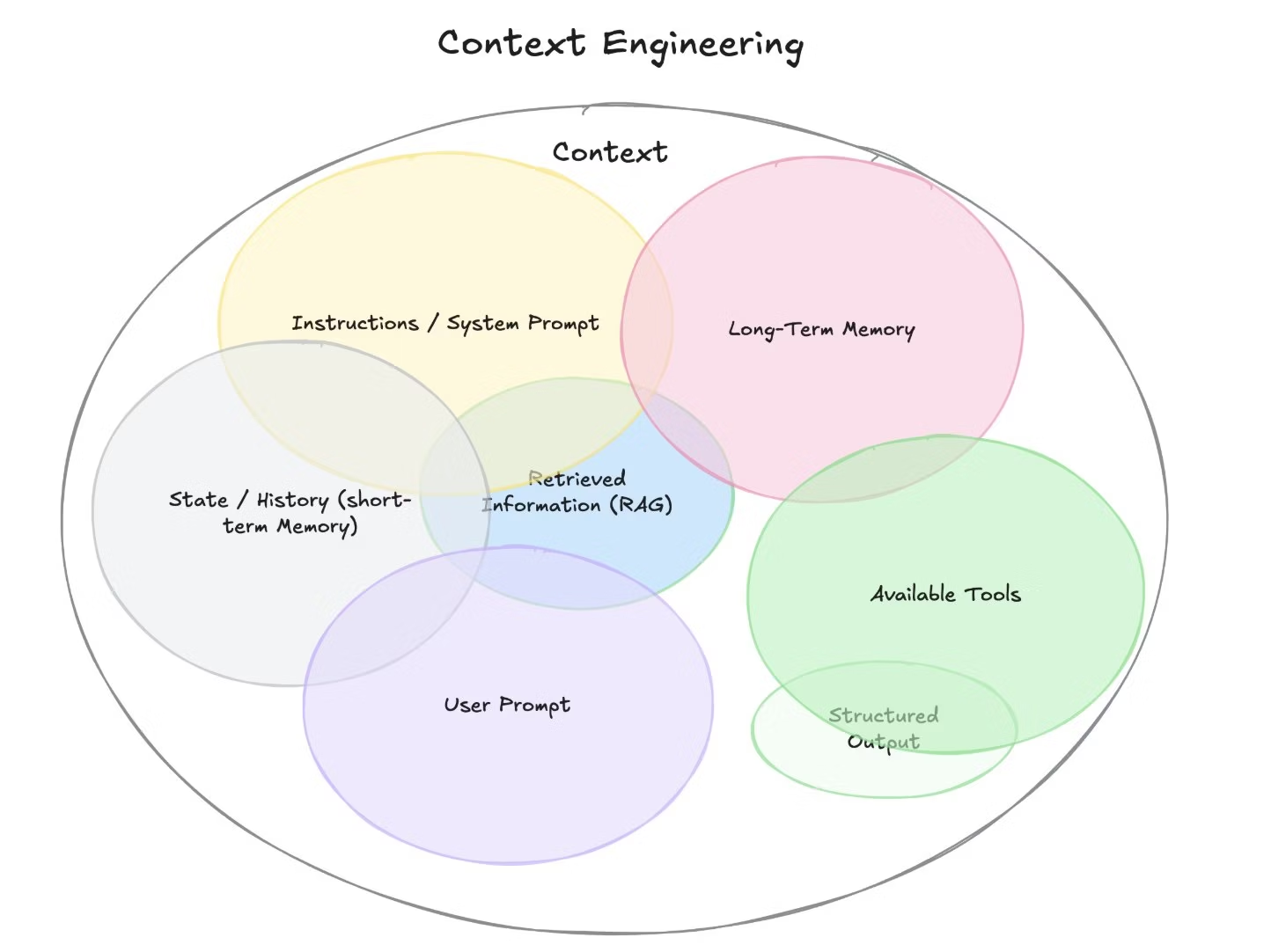
上図は Google DeepMind の Philipp Schmid 氏の Blog からの引用。
- Instructions/System Prompt
- User Prompt
- State/History(短期記憶)
- Long-Term Memory(長期記憶)
- Retrieved Information(RAG)
- Available Tools/Structured Output(ツール呼び出し・構造化出力)
という 6 つの構成要素を「コンテキスト」として設計し、動的に適切な情報と適切なツールを適切なタイミングで提供することでエージェントの精度を上げていこうとしている。
コンテキストエンジニアリングがこれからの技術者が習得すべきスキルってことですか。
あれっ?これまで私が AutoGen などで紹介してきた機能、これらの要素を完璧にカバーしてない?
AutoGen による対応策
三者の主張を AutoGen の実装ではどのように吸収・解決するのかを以下のように整理しました。最新の AutoGen を使えば、ベストプラクティスを同一コードベースで試行 → 計測 → 改善でき、マルチエージェント導入のリスクを大きく下げられそう。
・・・と思ったけど、AutoGen はそもそも本番適用よりも研究用途で使ってもらうのを想定していることに注意。本番環境には SemanticKernel を薦めている。
| 要件 | AutoGen 機能 | 関連記事との対応 |
|---|---|---|
| 全コンテキスト vs 部分コンテキスト |
GroupChat は全履歴共有、MessageFilterAgent で部分共有に切替可 |
Cognition AI のコンテキスト懸念 |
| 制御付き並列 |
GraphFlow は DAG で順次・並列・条件・ループを厳密制御 |
Anthropic の orchestrator-worker を忠実に再現可能 |
| 長期メモリ |
Memory/Task-Centric Memory で要約+RAG |
コンテキスト圧縮と外部知識注入を統合 |
| 人間介入 |
UserProxyAgent の human_input_mode=ALWAYS/NEVER/TERMINATE
|
Anthropic の人力テスト |
| 観測性 | トレーシングでメッセージ・トークン監視 | Anthropic の“速いフィードバックループ”を実装 |
| 評価 | (昔)AgentEval、LLM-as-a-judge を実装、Anthropic のような 最終状態評価を実装 | Cognition AI の「評価困難」を定量化可能 |
| ガードレール | Termination Conditions(MaxMessages、TextMention、FunctionCall等) | Anthropic が手動でプロンプトに埋め込んでいた停止ルールを、AutoGen では型安全かつ柔軟にコード化 |
AutoGen の GroupChat/Selector/Swarm では全コンテキストが共有される仕様
すでに紹介している通り、AutoGen の AgentChat で構築したマルチエージェントはすべてのエージェントが同じコンテキストを共有する仕組みになっている。
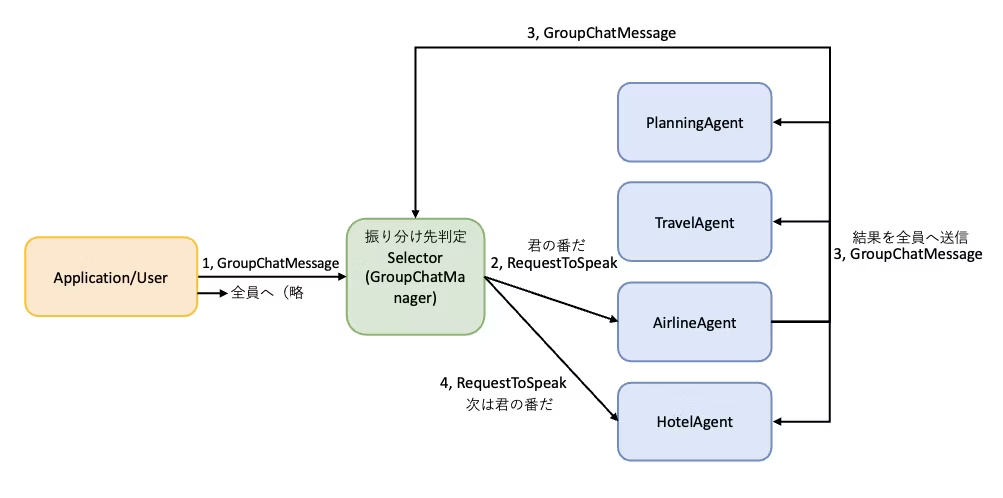
アーキテクチャ図だとそれぞれのエージェントが単独で動いているように見えるが内部ではコンテキストが全員に伝播する仕組みになっている。
全コンテキスト vs 部分コンテキスト
メッセージフィルタリング MessageFilterAgent は、各エージェントが受信するメッセージをフィルタリングし、そのモデルコンテキストを関連する情報に限定する独立した機能。メッセージフィルタのセットがフロー内のメッセージグラフを定義する。
以下の点が改善可能:
- 幻覚の削減
- メモリ負荷の制御
- エージェントを関連する情報にのみ集中させる
GraphFlow による並列化によるコンテキスト共有問題
この機能こそが Cognition AI の主張する課題にピンポイントで対応する部分。
AutoGen にはエージェントの制御をグラフで記述できる GraphFlow が実装されている。 v0.5 系ではたとえ並列のファンアウト/ファンインアーキテクチャであっても内部ではシーケンシャルに実行され片方の実行結果が伝播される仕組みになっていた。ただし、v0.6 系では完全に並列実行になり他方の実行結果が共有されなくなってしまった。(←ここは選択制にすればいい気がする)

長期記憶
Cognition AI のコンテキスト圧縮は Memory 機能や Task-Centric Memoryで実装可能だ。

Azure OpenAI Developers セミナー 2025
短期記憶
AutoGen にはタスク台帳で短期記憶を保持するような仕組みもある。
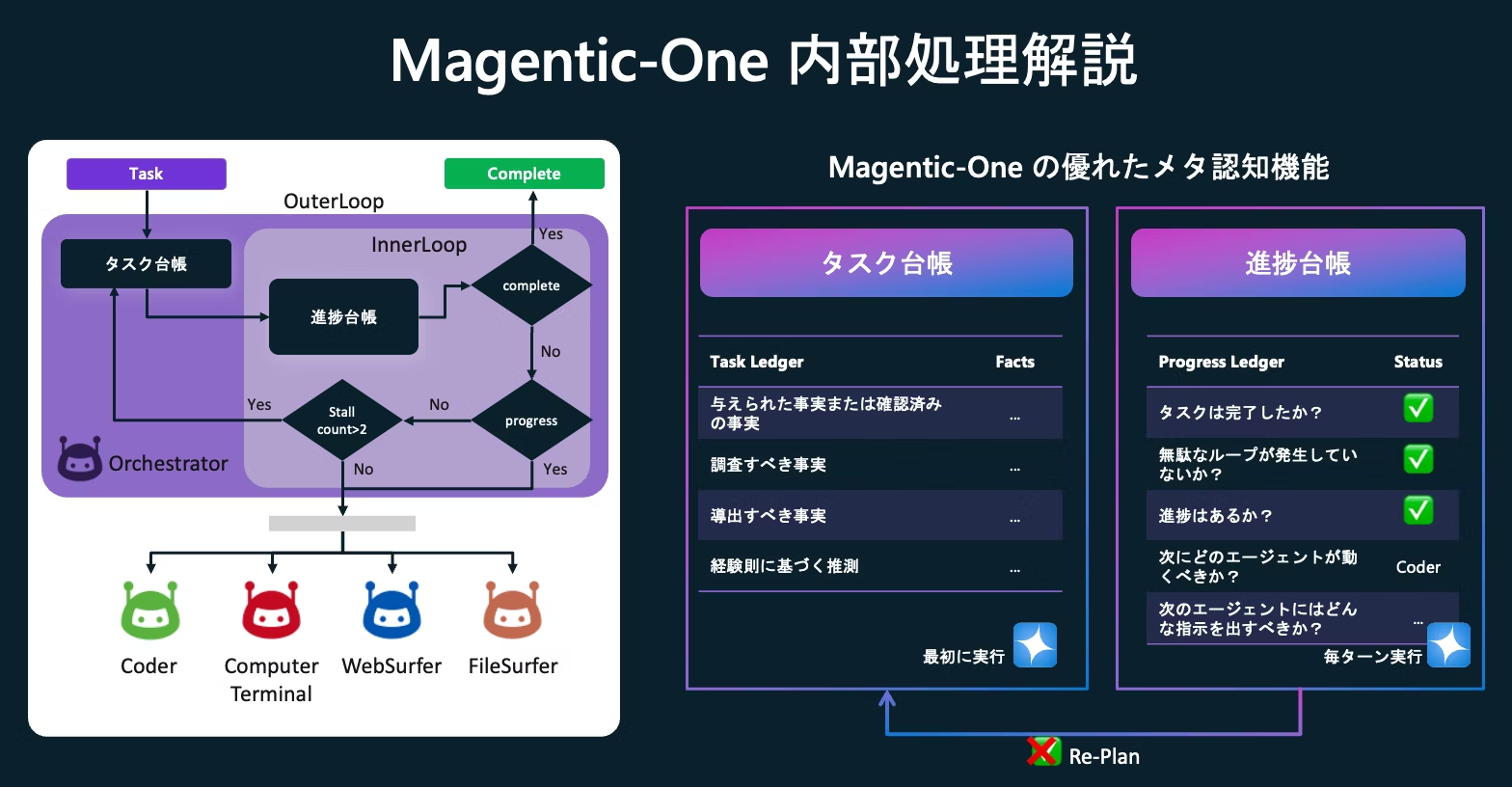
ちなみに Anthropic が開発した LeadResearcher はまずアプローチを検討し、コンテキストを保持するためにプランをメモリに保存している。
さらに、各エージェントの状態管理も実装されており JSON で取得できることはすでに紹介済みだ。
可観測性
AutoGen には、アプリケーションの実行に関する包括的な記録を収集するためのトレースと観測のサポートが組み込まれている。この機能は、デバッグ、パフォーマンス分析、そしてアプリケーションのフローを理解するのに役立つ。
この機能は OpenTelemetry ライブラリを活用しているため、OpenTelemetry と互換性のある Azure AI Foundry を使う例を紹介している。
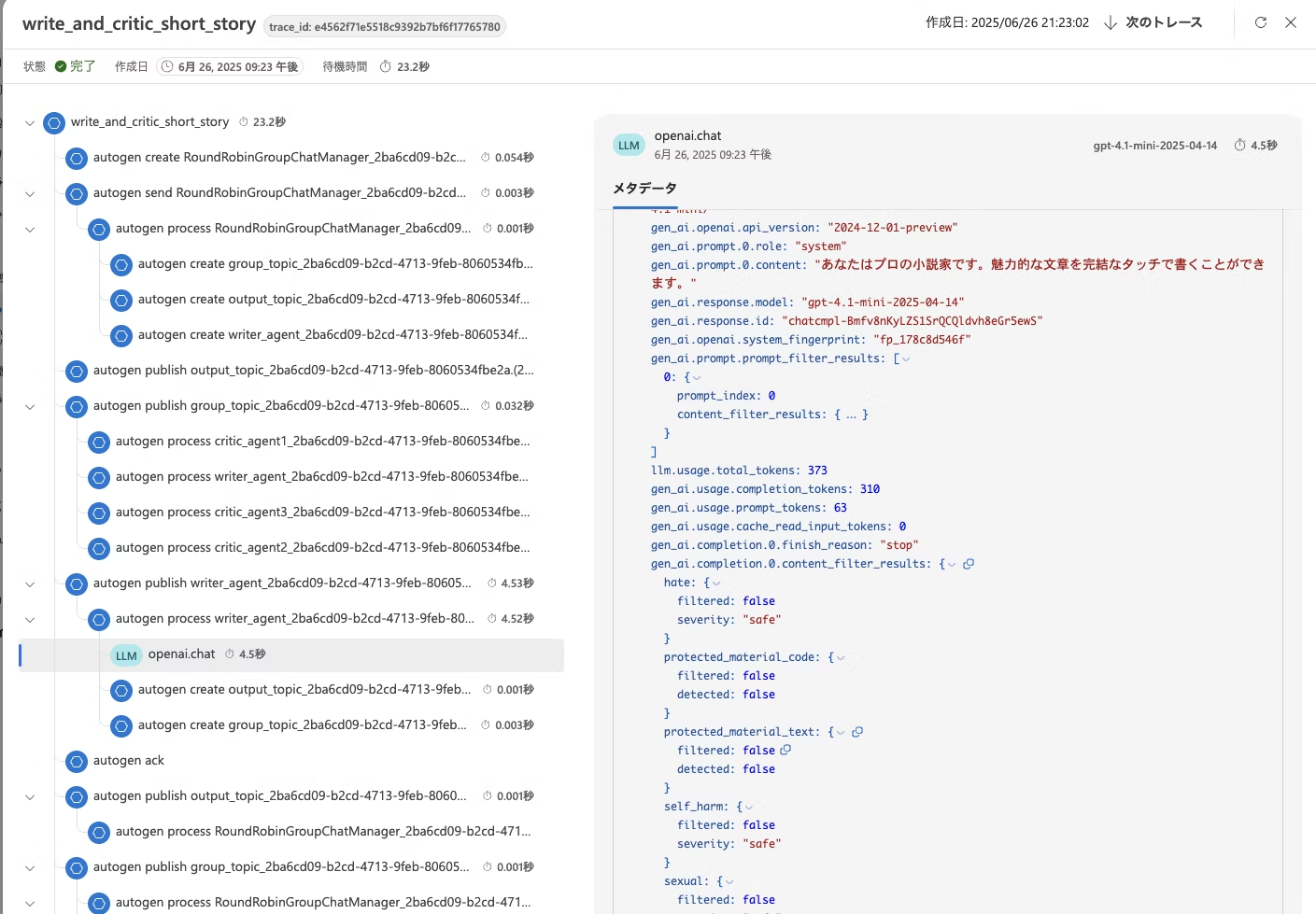
さらに、OSS の Jaeger も使用できる。
ガードレール
Anthropic はプロンプト内に「スケーリングルール」を明示し、エージェント自身がどれだけの労力(エージェント数・ツール呼び出し回数)をかけるべきか判断しづらいため、あらかじめ以下のような基準を与える方式を採用した。
- 簡単な事実の検索:サブエージェント1体、ツール呼び出し3~10回
- 比較系クエリ(例:A社 vs B社の比較):サブエージェント2~4体、各エージェント10~15回の呼び出し
- 複雑・本格調査:10体を超えるサブエージェントによる分担
これにより、「簡単な質問にやたら時間をかける」ような過剰リソース投入を防ぎ、効率的な運用が可能になった。AutoGen は適切な終了条件を設定しないとよく無意味なループに陥る。この問題は以下のような複数の停止条件によって制御可能だ。
- MaxMessageTermination: 指定された数のメッセージ(エージェント・タスク両方)が生成された後に停止
- TextMentionTermination: メッセージ内に特定のテキスト(例:「TERMINATE」)が記載された場合に停止
- TokenUsageTermination: 一定数のトークンが使用されると停止(トークン使用状況の報告が必要)
- TimeoutTermination: 指定された秒数が経過すると停止
- HandoffTermination: 特定のターゲットへのハンドオフ要求時に停止。Swarmパターンなど、UIやユーザー操作待ちに便利
- SourceMatchTermination: 特定のエージェントが応答した場合に停止
- ExternalTermination: 外部プログラムからの停止制御(例:UIの「停止」ボタン)
- StopMessageTermination: StopMessageエージェントがStopMessageを生成したときに停止
- TextMessageTermination: TextMessageエージェントがTextMessageを生成したときに停止
- FunctionCallTermination: 指定名のFunctionExecutionResultを含むToolCallExecutionEventが生成されたときに停止
- FunctionalTermination: メッセージの最後で関数式がTrueになった時点で停止(カスタム終了条件に便利)
さいごに
単にこれらの要素技術が提供されていることと、使いこなせるということは別の話なので今後もウォッチを続けていこうと思う。Azure OpenAI + Azure AI Foundry Agent Service についてもこれらの観点でしっかり整理しようと思う。
AutoGen のチームにも追々記事出してほしいですね…
AutoGen の最新機能をすべて試せるガチハンズオン公開中
*本記事は筆者個人の見解であり、特定の企業や団体の公式な意見や立場を代表するものではありません。内容については十分に注意を払っておりますが、その正確性や完全性を保証するものではありません。ご利用に際してはご自身の判断でお願いいたします。