はじめに
この記事は、Azure Purview を遊びながら開発しよう(基本編)の第二弾となります。
データ変換
Azure Purview では、データの変換操作をエンティティとして保持することができます。そのためのエンティティとして Process 型が用意されています。
ひとまず以下のコードを実行します。
from pyapacheatlas.core import AtlasProcess
input01 = AtlasEntity("inputprocess01.csv","DataSet", "pyapacheatlas://inputprocess01", guid=-100)
output01= AtlasEntity("outputprocess01.csv","DataSet", "pyapacheatlas://outputprocess01", guid=-101)
process = AtlasProcess(
name="データ変換処理1",
typeName="Process",
qualified_name="pyapacheatlas://hanaprocess1",
inputs=[input01],
outputs=[output01],
guid=-102
)
results = client.upload_entities(
batch=[input01, output01, process]
)
print(json.dumps(results, indent=2))
そして、"データ変換" などのキーワードでカタログを検索すると、Process 型のエンティティがヒットします。
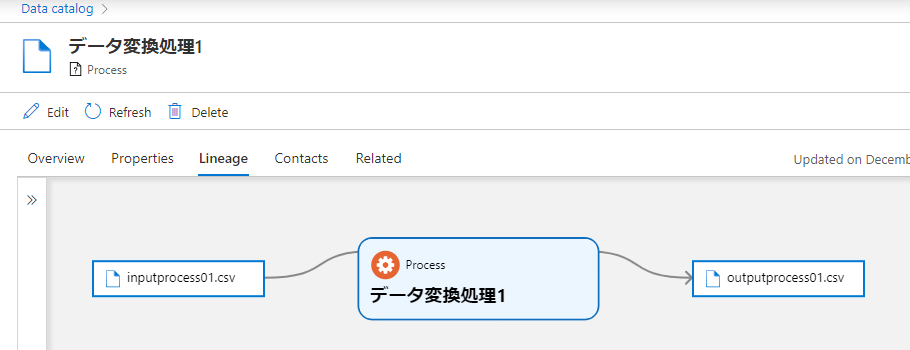
pyapacheatlas.core の AtlasProcess クラスに inputs と outputs となるエンティティを指定してあげることで、データの処理過程を系列(Lineage)として表現することができます。Azure Purview では、Azure Data Factory や Azure Synapse のコピーアクティビティやデータフローアクティビティなどのデータ処理が系列として表示できます。これを自動的に連携するには事前にそれぞれのサービス側から Azure Purview へ接続しておく必要があります。
それでは、Azure Purview で定義されている Process 型についてもう少し詳しく調べてみましょう。
typedef = client.get_typedef(name="Process")
print(json.dumps(typedef, indent=2))
出力結果から、Asset 型を継承していることが分かります。つまり、Process 型は DataSet型と同階層に属する型ということです。
Referenceable
└ Asset
├ DataSet
└ Process
├ azure_synapse_activity
├ azure_synapse_pipeline
├ adf_process
├ azure_sql_stored_procedure
├ azure_sql_query_run
...46 items
ただし、それぞれの型の下にもサブタイプが存在し、結構複雑です。しっかり型定義を見ていく必要があります。例えば Azure Data Factory で Copy アクティビティを実行した場合、adf_copy_activity が作成されます。この型には、adf_pipeline 型のエンティティを必要としますし、adf_copy_operation 型のエンティティをオプションで受け入れます。
複数データソースを系列に追加する
ETL/ELT 処理では複数のデータソースを入力し、一つの出力を得ることもあるかと思いますがそれも簡単にできます。AtlasEntity を作成して、AtlasProcess の inputs 配列に追加するだけです。
from pyapacheatlas.core import AtlasProcess
input01 = AtlasEntity("inputprocess01.csv","DataSet", "pyapacheatlas://inputprocess01", guid=-100)
input02 = AtlasEntity("inputprocess02.csv","DataSet", "pyapacheatlas://inputprocess02", guid=-101)
output01= AtlasEntity("outputprocess01.csv","DataSet", "pyapacheatlas://outputprocess01", guid=-102)
process = AtlasProcess(
name="データ変換処理1",
typeName="Process",
qualified_name="pyapacheatlas://hanaprocess1",
inputs=[input01, input02],
outputs=[output01],
guid=-103
)
results = client.upload_entities(
batch=[input01, input02, output01, process]
)
print(json.dumps(results, indent=2))
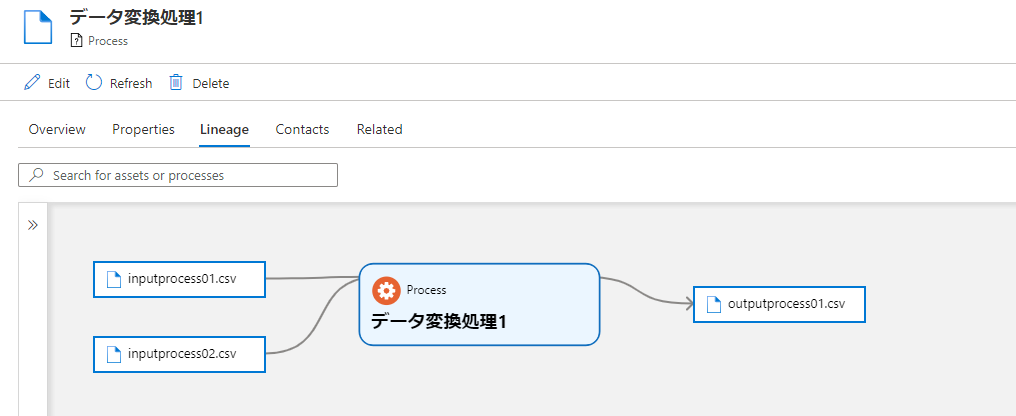
はい、ファイルが追加されましたね。もし、typeName に azure_synapse_pipeline に変えて実行すると…
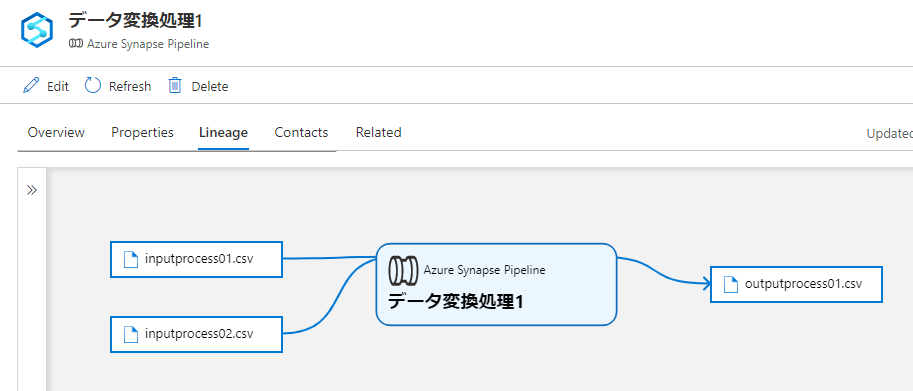
こんな感じに変わります。ただ、属性や関連に何も値を指定していないので、クリックしても Azure Synapse の該当ページへのリンクも表示されません。
Azure Data Factory の Copy アクティビティの作成
通常、Azure Purview と正しく接続できていれば Copy アクティビティ実行後、Azure Purview 側で Scan することで系列が自動的に連携されます。でも、内部はどうなっているのか知りたいですよね… この Copy アクティビティは Atlas API から作成しようとするとかなり複雑ですが、以下のコードを実行すれば一発で作成することができます。
# qualified_name のパスを指定しておく
adf_qualifiedPath = "/subscriptions/12345/resourceGroups/purviewhanatest1/providers/Microsoft.DataFactory/factories"
adf_qName = adf_qualifiedPath + "/adf01"
adf_pipeline_qName = adf_qName + "/pipelines/hanaadf_pipeline1"
adf_activity_qName = adf_pipeline_qName + "/activities/hanaadf_copy_activity1"
adf_operation_qName = adf_activity_qName + "#hanaadf_copy_operation1"
# 最上位は azure_data_factory 型
adf = AtlasEntity("adf01","azure_data_factory", adf_qName, guid=-100)
# Process 型への input と output
input01 = AtlasEntity("sql_input01","azure_sql_dw_table", "pyapacheatlas://sql_input01", guid=-101)
output01= AtlasEntity("sql_output01","azure_sql_table", "pyapacheatlas://sql_output01", guid=-102)
# Pipeline の作成
proc_pipeline = AtlasProcess(
name="データ変換処理_パイプライン",
typeName="adf_pipeline",
qualified_name=adf_pipeline_qName,
guid=-103,
inputs=[],
outputs=[]
)
# Activity の作成
proc_activity = AtlasProcess(
name="データ変換処理_Copyアクティビティ",
typeName="adf_copy_activity",
qualified_name=adf_activity_qName,
inputs=[],
outputs=[],
guid=-104,
attributes = {"status": "Completed"}
)
# Operation の作成
proc_operation = AtlasProcess(
name="データ変換処理_オペレーション",
typeName="adf_copy_operation",
qualified_name=adf_operation_qName,
guid=-105,
inputs=[input01],
outputs=[output01],
)
# Relationship の作成
proc_activity.addRelationship(subProcesses=[proc_operation.to_json(minimum=True)])
proc_pipeline.addRelationship(subProcesses=[proc_activity.to_json(minimum=True)])
adf.addRelationship(pipelines=[proc_pipeline.to_json(minimum=True)])
results = client.upload_entities(
batch=[adf, proc_pipeline, proc_activity, proc_operation, input01, output01]
)
print(json.dumps(results, indent=2))
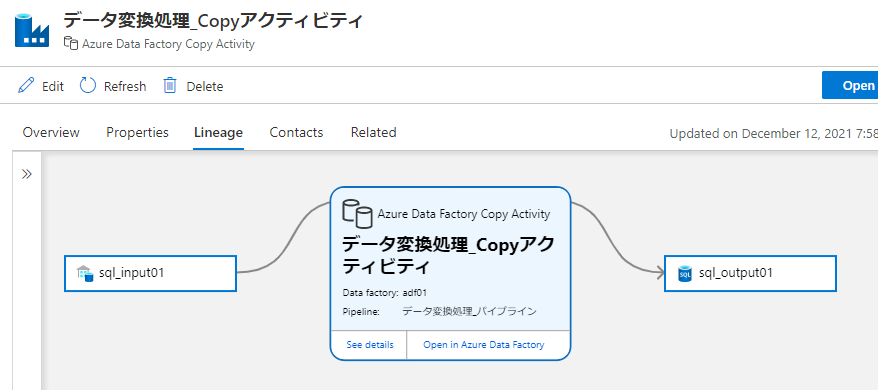
各 Process 型に特有の設定がありますが、Azure Data Factory の Copy アクティビティの例を知っておけば他にも応用が利くと思います。単に adf_copy_activity 型のエンティティに input/output を指定するだけでは正しく系列が表示されません。この場合は、adf_copy_activity の下に adf_copy_operation 型のエンティティを作成し、そちらに指定してあげる必要があります。そして、上位のエンティティとの間に関係を作成します。
さらに、正しい Copy アクティビティはこのように階層が表示されます。
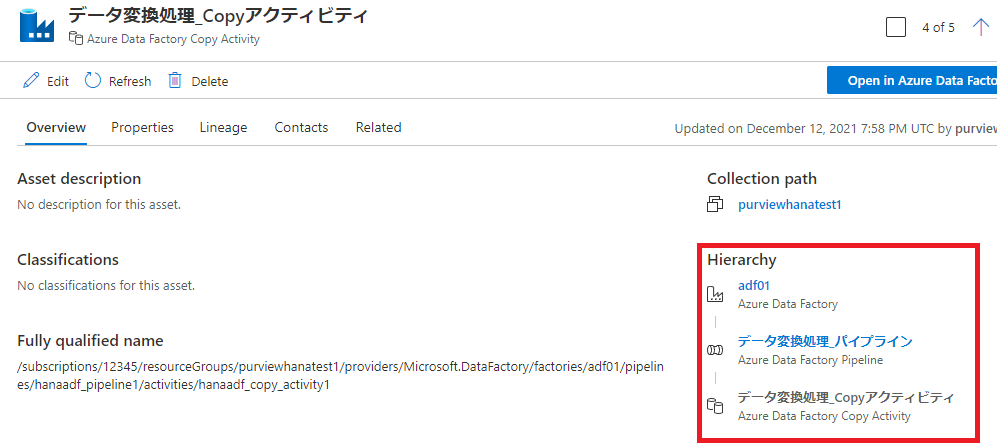
この階層表示および Related タブの階層は、関係を作成しただけでは表示されません。既定のパス形式に沿って設定された qualified_name が必要です。adf_copy_activity の場合は上記コードのようなパスが必要ですが、カスタムする場合でも qualified_name の命名規則はしっかり決めておいた方がいいです。
ちなみに、系列ボックス上の「Open in Azure Data Factory」ボタンで開かれるリンク先 URL の生成に qualified_name が使用されます。
系列のカラムマッピング作成
これまではデータセット粒度での系列でしたが、Azure Purview ではさらにカラム粒度での系列を表示し、データ変換処理を経て、どのようにカラムが伝播していったのかを追跡することができます。
from pyapacheatlas.core import AtlasProcess
from pyapacheatlas.core.typedef import EntityTypeDef, AtlasAttributeDef
# columnMapping 属性の定義を含むカスタムプロセスエンティティ型を定義
procType = EntityTypeDef(
"ProcessWithColumnMapping",
superTypes=["Process"],
attributeDefs = [
AtlasAttributeDef("columnMapping")
]
)
# 型定義のアップロード
type_results = client.upload_typedefs(entityDefs=[procType], force_update=True)
print(json.dumps(type_results,indent=2))
input01 = AtlasEntity("sql_col_input01","azure_sql_dw_table", "pyapacheatlas://sql_col_input01", guid=-100)
output01= AtlasEntity("sql_col_output01","azure_sql_table", "pyapacheatlas://sql_col_output01", guid=-101)
# カラムマッピングの定義
column_mapping = [
{"ColumnMapping": [
{"Source": "In01_ID", "Sink": "Out01_ID"},
{"Source": "In01_Name", "Sink": "Out01_Name"}],
"DatasetMapping": {
"Source": input01.qualifiedName, "Sink": output01.qualifiedName}
}
]
process = AtlasProcess(
name="データ変換処理_カラムマッピング",
typeName="ProcessWithColumnMapping",
qualified_name="pyapacheatlas://hana_col_process1",
inputs=[input01],
outputs=[output01],
guid=-102,
attributes={"columnMapping": json.dumps(column_mapping)}
)
results = client.upload_entities(
batch=[input01, output01, process]
)
print(json.dumps(results, indent=2))
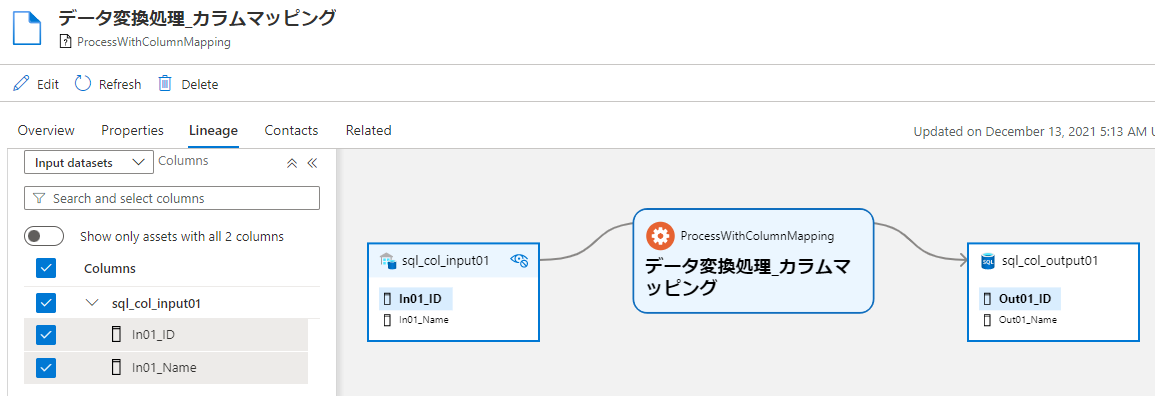
このように入力テーブルのカラムがデータ変換処理の後、どこへ伝播したかを示す系列を作成できました。この時、EntityTypeDef クラスを使って columnMapping 属性を持つ新たな Process 型のエンティティ ProcessWithColumnMapping を定義しました。これは既定でカラムマッピング属性を保持できるシンプルな Process 型が無かったためです。azure_synapse_operation 型や adf_copy_activity 型、ssis_package_process 型などは既定でカラムマッピング属性を保持できますが、前述のとおり作るのがめんどくさいです。
複数のカラムマッピング作成
データ変換処理で 1 つのカラムから複数のカラムを生成するパターンもよくあると思います。これも簡単にできます。
column_mapping = [
{"ColumnMapping": [
{"Source": "In01_ID", "Sink": "Out01_ID"},
{"Source": "In01_Name", "Sink": "Out01_LastName"},
{"Source": "In01_Name", "Sink": "Out01_FirstName"}],
"DatasetMapping": {
"Source": input01.qualifiedName, "Sink": output01.qualifiedName}
}
]
process = AtlasProcess(
name="データ変換処理_カラムマッピング",
typeName="ProcessWithColumnMapping",
qualified_name="pyapacheatlas://hana_col_process1",
inputs=[input01],
outputs=[output01],
guid=-102,
attributes={"columnMapping": json.dumps(column_mapping)}
)
results = client.upload_entities(
batch=[input01, output01, process]
)
print(json.dumps(results, indent=2))
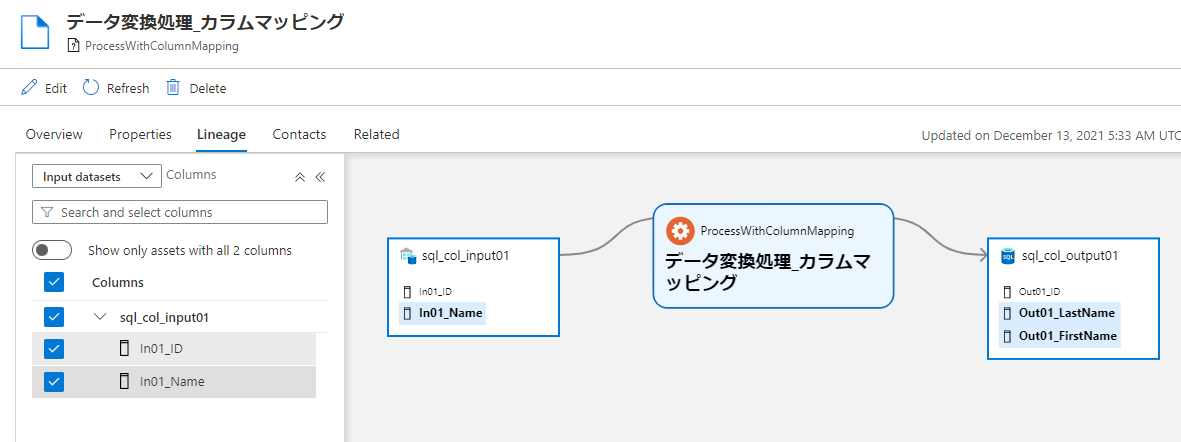
いいですね!
試しにさっき作った Azure Data Factory の Copy アクティビティにカラムマッピングを追加するにはどうすればいいかというと、
input01 = AtlasEntity("sql_input01","azure_sql_dw_table", "pyapacheatlas://sql_input01", guid=-101)
output01= AtlasEntity("sql_output01","azure_sql_table", "pyapacheatlas://sql_output01", guid=-102)
column_mapping = [
{"ColumnMapping": [
{"Source": "In01_ID", "Sink": "Out01_ID"},
{"Source": "In01_Name", "Sink": "Out01_Name"}],
"DatasetMapping": {
"Source": input01.qualifiedName, "Sink": output01.qualifiedName}
}
]
proc_activity = AtlasProcess(
name="データ変換処理_Copyアクティビティ",
typeName="adf_copy_activity",
qualified_name=ADF_QUALIFIED_NAME + "/adf01/pipelines/hanaadf_pipeline1/activities/hanaadf_copy_activity1",
inputs=[],
outputs=[],
guid=-103,
attributes = {"status": "Completed", "columnMapping": json.dumps(column_mapping)}
)
results = client.upload_entities(
batch=[proc_activity]
)
print(json.dumps(results, indent=2))
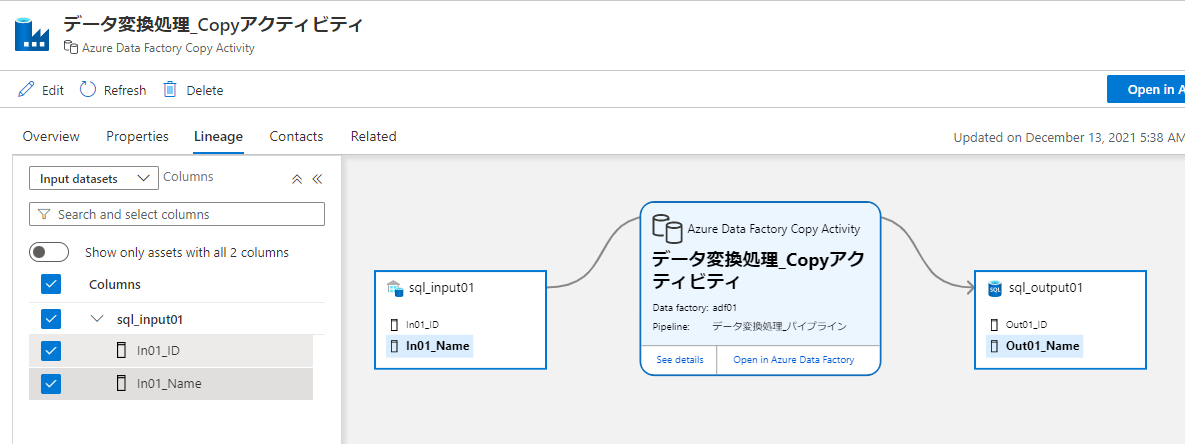
サクッと行けましたね!
Process 型に columnMapping という属性が無いと追加できないということです。
さらに次のデータ処理を追加する
前回の出力データに対して、さらに後段のデータ処理を追加するには、以下のように書きます。
from pyapacheatlas.core import AtlasEntity, AtlasProcess
output01= AtlasEntity("sql_output01","azure_sql_table", "pyapacheatlas://sql_output01", guid=-100)
next01 = AtlasEntity("sql_next01","azure_sql_table", "pyapacheatlas://sql_next01", guid=-101)
process = AtlasProcess(
name="データ変換処理その2",
typeName="Process",
qualified_name= "pyapacheatlas://hanaprocess2",
inputs=[output01],
outputs=[next01],
guid=-102
)
results = client.upload_entities(
batch=[output01, next01, process]
)
print(json.dumps(results, indent=2))
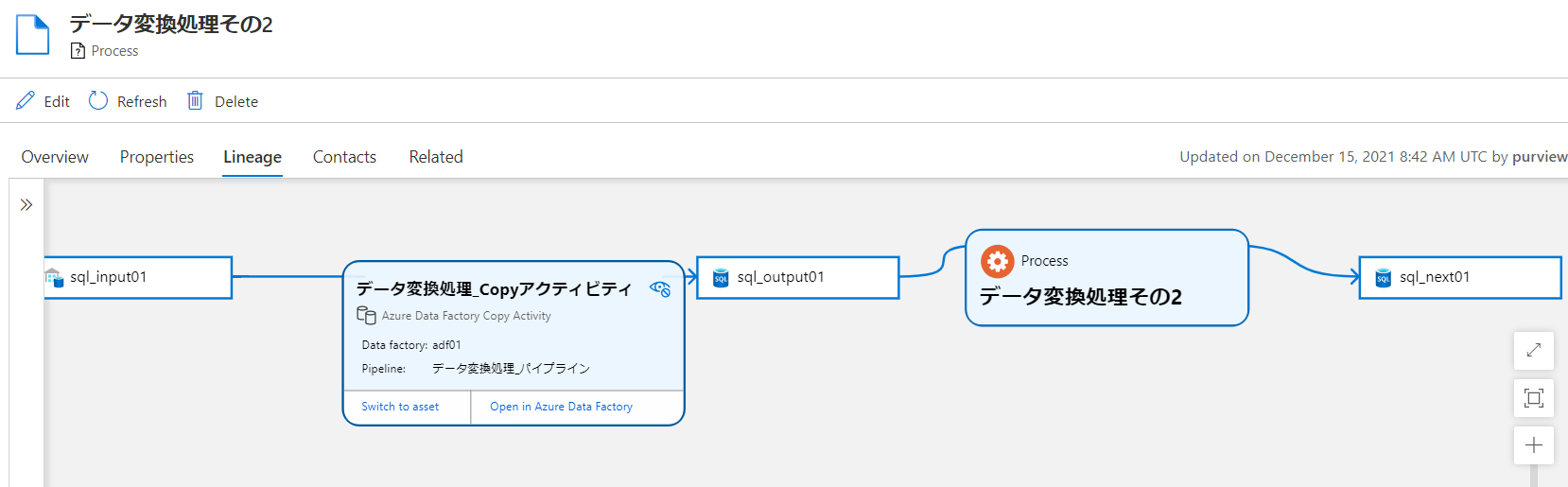
簡単にできましたね。 AtlasProcess の inputs に前回の AtlasEntity を指定するだけです。
関係を作成する別の方法
すでに作成済みのエンティティ同士を関連付けるには、upload_relationship メソッドを使用することもできます。
relationship01 = client.get_entity(qualifiedName="pyapacheatlas://sql_output01", typeName="azure_sql_table")
relationship02 = client.get_entity(qualifiedName="pyapacheatlas://hanaprocess3", typeName="Process")
relationship = {
"typeName": "dataset_process_inputs",
"attributes": {},
"guid": -100,
"end1": {
"guid": relationship01['entities'][0]['guid']
},
"end2": {
"guid": relationship02['entities'][0]['guid']
}
}
# 新しい関係をアップロードする
results = client.upload_relationship(relationship)
print(json.dumps(results, indent=2))
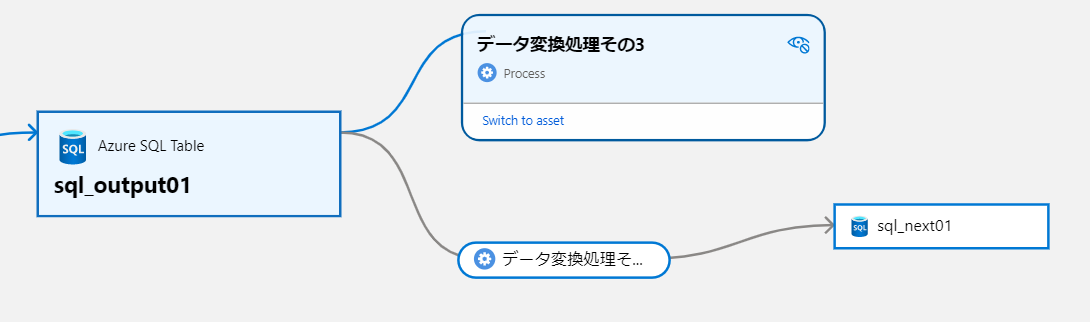
既定で作成できる関係は、データセットとデータ変換やテーブルとカラムなどの定義された関係に限られます。この関係の事前定義については、get_all_typedefs() の root/relationshipDefs 以下に定義されています。データ変換とインプット側の関係を作成する際は dataset_process_inputs 型を、データ変換とアウトプット側の関係を作成する場合は、process_dataset_outputs 型を使用します。
さいごに
はい、こんな感じで Azure Purview の開発を楽しんでいただければと思います。Azure Purview にはこの他にも色々な機能があるので試してみるのも面白いのではないでしょうか。そして Azure Purview の開発を通して、新たなデータガバナンスエコシステムが活性化されることを楽しみにしています。