はじめに
Azure Purview は、Microsoft が 2020 年に発表した、統合データガバナンスサービスです。日本語ではパァビュー(pˈɚːvjuː)という感じで発音します。プレビューではないです。
Azure Purview を使えば、オンプレでもマルチクラウドでも SaaS でも対応しているデータソースであればメタデータカタログとして集中管理することができるようになります。すでに日本の企業でも導入が始まっており、組織内でデータ利活用を始める際のファーストステップとしてデータの場所をカタログ化し、検索可能にすることの重要性が認知され始めています。また、新たにデータ分析基盤を構築する際の基本的コンポーネントとして取り入れられています。
Azure Purview 開発
Azure Purview は オープンソースのコア基盤ガバナンスサービス である、Apache Atlas Open API エコシステムをベースとしており、Microsoft によっていくつかの機能拡張と追加が行われています。
Azure Purview では Atlas と同様、管理するメタデータオブジェクトのモデルを定義できます。考え方はオブジェクト指向プログラミングととても良く似ています。この辺の基礎的な部分は Atlas の Type System を参照してください。そして、Apache Atlas API 互換の REST API や Python クライアント(PyApacheAtlas)を使用してあらゆる操作が可能になっています。
今回は PyApacheAtlas を使って遊んでみたいと思います。
事前準備
こちらを参照し、以下を完了してください。クライアントの PyApacheAtlas から Azure Purview を操作するために必要です。
- Azure Purview アカウント作成
- サービス プリンシパル (アプリケーション) を作成
- サービス プリンシパルを使用して認証を設定する
- トークンを取得する
- PyApacheAtlas のインストール (
pip install pyapacheatlas)
Azure Purview への接続
import json
import os
from pyapacheatlas.auth import ServicePrincipalAuthentication
from pyapacheatlas.core import PurviewClient
SUBSCRIPTION_ID = "" # fill in
RESOURCE_GROUP = "" # fill in
PURVIEW_NAME = "" # fill in
SERVICE_PRINCIPAL_NAME = "" # fill in
oauth = ServicePrincipalAuthentication(
tenant_id=os.environ.get("TENANT_ID", "<Service Principal Tenant ID>"),
client_id=os.environ.get("CLIENT_ID", "<Service Principal Client ID>"),
client_secret=os.environ.get("CLIENT_SECRET","<Service Principal Client Secret>")
)
# PurviewClient のインスタンス化
client = PurviewClient(
account_name = os.environ.get("PURVIEW_NAME", PURVIEW_NAME),
authentication=oauth
)
エンティティの作成
まずは以下のコードを打ち込んでみましょう。
from pyapacheatlas.core import AtlasEntity
input01_qn = "pyapacheatlas://hanainput01"
dataset_type_name = "DataSet"
input01 = AtlasEntity(
name="hanainput01",
typeName=dataset_type_name,
qualified_name=input01_qn,
guid="-100"
)
results = client.upload_entities(
batch=[input01]
)
print(json.dumps(results, indent=2))
何が起きたかを確認するには、Azure Purview Studio をブラウザで開き、Data map->Collenctions->[Purview 名]をウォッチします。Atlas API で登録した場合、Scan しなくてもすぐに結果を確認できます。Python コードを実行後、 Refresh ボタンをクリックすると、Assets の値が 1 つ増えるかと思います。
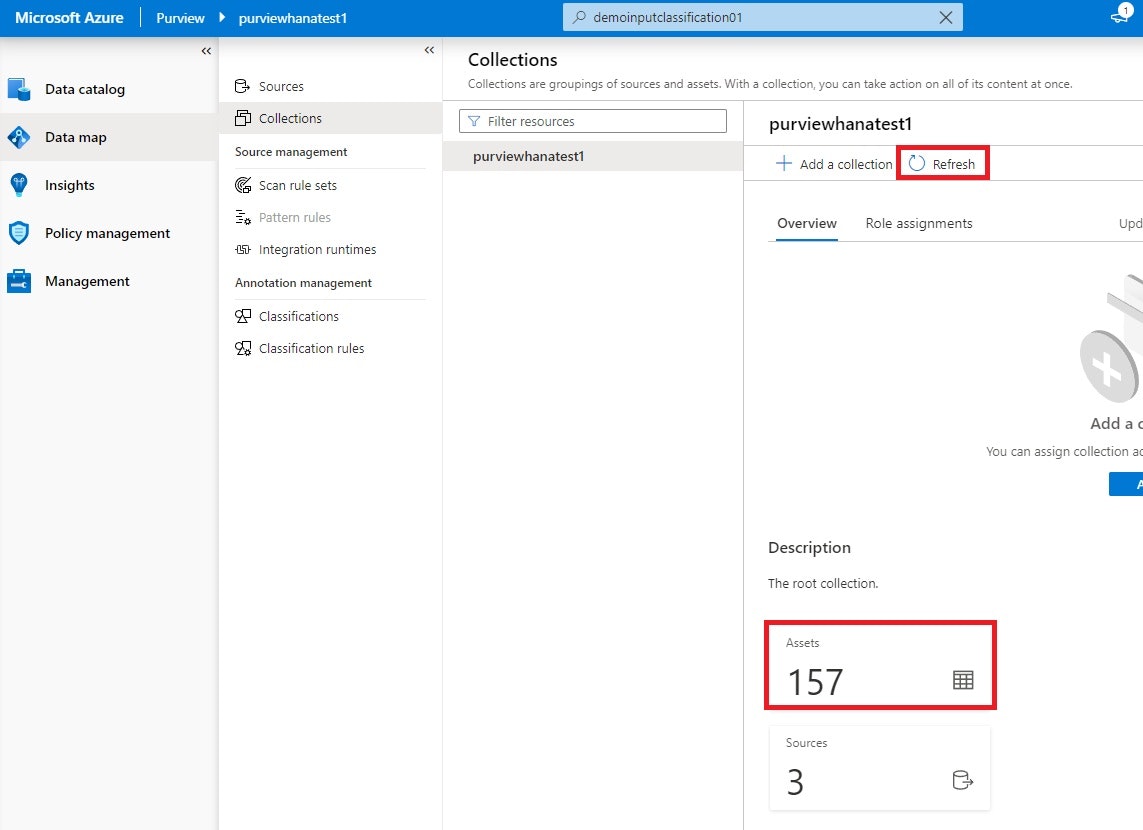
Assets のボックスをクリックすると、Assets 一覧が表示され、そこに今回作成した hanainput01 エンティティが出てきます。

これをクリックすると、最もシンプルなエンティティのメタ情報が表示されます。
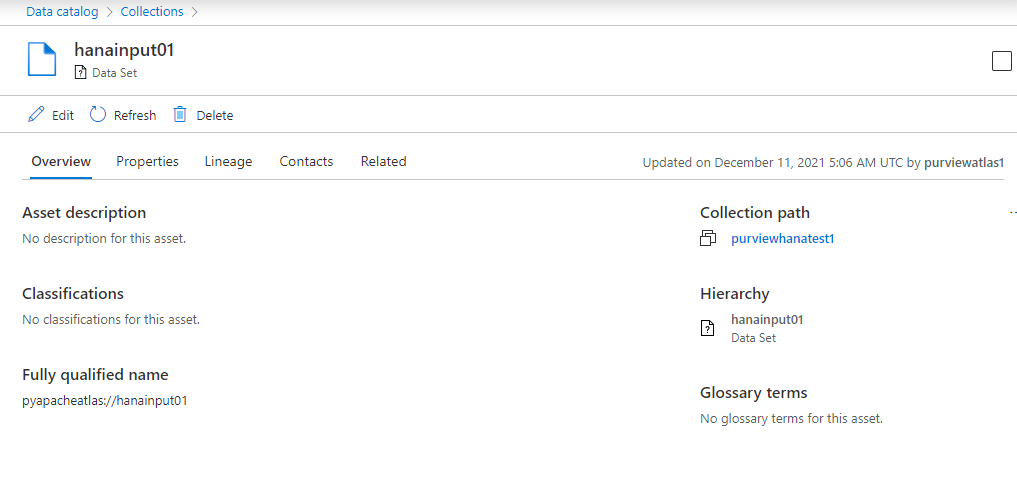
これを Hello, world! としましょう。
型
さて、最初のエンティティ作成では、typeName を DataSet と指定しましたが、これはどういう意味でしょうか。Atlas で扱うエンティティには必ず型の定義が必要で、型には事前定義された型とそれ継承する型が多数存在します。
例えば、以下のコードを実行します。
from pyapacheatlas.core import AtlasEntity
input01_qn = "pyapacheatlas://hanainput01"
dataset_type_name = "azure_datalake_gen2_filesystem"
input01 = AtlasEntity(
name="hanainput01",
typeName=dataset_type_name,
qualified_name=input01_qn,
guid="-100"
)
results = client.upload_entities(
batch=[input01]
)
print(json.dumps(results, indent=2))
typeName を azure_datalake_gen2_filesystem に変更し、その他の値は変更しません。

表示名が同じで、Source type が Azure Data Lake Storage Gen2 となっているエンティティが新たに作成されました。

アイコンも変わってますね。型を使えば、Azure Purview 上でデータのソースの種類を出しわけることができそうです。では、Azure Purview 上で定義されている型の一覧を取得するにはどうすればいいかというと、get_all_typedefs() メソッドを使用します。
all_typedefs = client.get_all_typedefs()
with open("get_all_typedefs.json", "w") as fp:
json.dump(all_typedefs, fp)
はい、なんと 2MB もの JSON ファイルが生成されました… 読むのつれぇわ…
これを丹念に JSON Editor などで見ていくと Azure Purview の全体像が見えてきます。
型の継承関係は以下のようになっており、DataSet 型の下に様々なデータソースが事前定義されていることが分かります。データベースの場合、テーブルとカラムというように分かれている点が重要です。Atlas ではカラム 1 つが 1 つのエンティティとして扱われます。
Referenceable
└ Asset
└ DataSet
├ azure_datalake_gen2_filesystem
├ azure_datalake_gen2_path
├ azure_synapse_dedicated_sql_table
├ azure_synapse_dedicated_sql_column
├ tabular_schema
...187 items
ちなみに、型名が分かっている場合は、get_typedef メソッドを使用することでピンポイントで定義を取得できます。
# azure_datalake_gen2_filesystem の型定義
typedef= client.get_typedef(name="azure_datalake_gen2_filesystem")
print(json.dumps(typedef, indent=2))
# DataSet の型定義
typedef= client.get_typedef(name="DataSet")
print(json.dumps(typedef, indent=2))
DataSet 型を継承している型は、属性としてスキーマ情報を持ったりデータ変換情報を保持することで系列(Lineage)グラフを Azure Purview 上で表示できるようになります。
基本的に Azure Purview で対応しているデータソースは、スキャンでこれらのエンティティが自動作成されますが、型を自分で定義して、カスタムデータソースを作成することができるので、ご自分のソリューションを Azure Purview と統合することができます。
属性の追加
次に、メタデータ管理の中心となる属性の付加を行います。
以下のコードを実行します。
from pyapacheatlas.core import AtlasEntity
input01_qn = "pyapacheatlas://hanainput01"
dataset_type_name = "azure_datalake_gen2_filesystem"
input01 = AtlasEntity(
name="hanainput01",
typeName=dataset_type_name,
qualified_name=input01_qn,
guid="-100",
attributes = {
"description": "ファイルについての説明"
}
)
results = client.upload_entities(
batch=[input01]
)
print(json.dumps(results, indent=2))
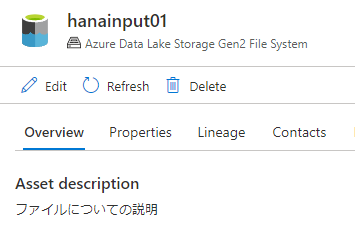
Asset description 項目に値が表示されましたね!
このように、エンティティに属性を付加するには、attributes プロパティに辞書型で属性を指定します。指定できる属性は、型の中の attributeDefs で定義されていなければなりません。今回追加した description は 上位の Asset 型の中で定義されています。
コード実行時、result の中で "UPDATE" と出力されたかと思いますが、upload_entities メソッド実行時、qualified_name と typeName がキーとなり、すでに存在している場合は、上書きされます。qualified_name にはデータセットが一意の値になるように命名します。例:https://purviewhanatest1adcadls.dfs.core.windows.net/starter1/{Year}/{Month}/{Day}/Contoso_AccountsPayable_{N}.csv
連絡先の追加
エンティティの Contacts タブでは、データセットへの連絡先を設定することができます。
input01 = AtlasEntity(
name="hanainput01",
typeName="azure_datalake_gen2_filesystem",
qualified_name="pyapacheatlas://hanainput01",
guid="-100",
contacts= { "Expert": [],
"Owner": [
{
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"info": "データを使いたかったら連絡して😎"
}
]
}
)
results = client.upload_entities(
batch=[input01]
)
print(json.dumps(results, indent=2))
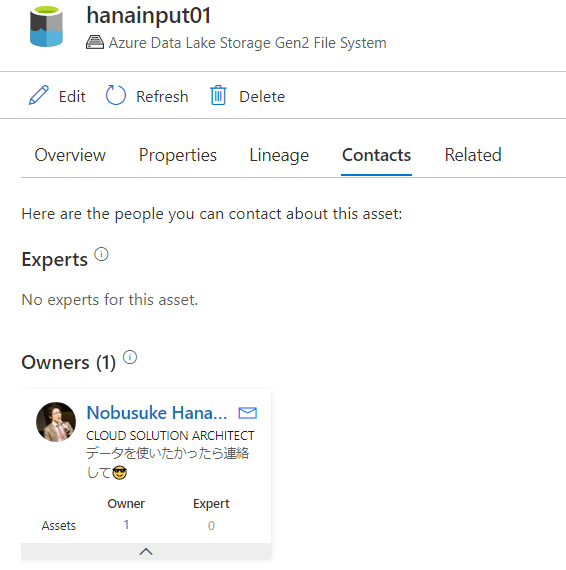
はい、このようにデータセットのオーナーが追加されましたね。id には、Microsoft Graph オブジェクトの ID を設定します。連絡先を設定しておくことで、データ利用者がデータに関する質問や使用可否を問い合わせることができるようになります。
エンティティを操作する
エンティティを取得する
Atlas ではエンティティを一意に特定する値として GUID もしくは qualifiedName と typeName の組み合わせが使用されます。GUID は、Azure Purview Studio で特定のエンティティを開いたとき、URL に含まれている guid と同一です。
# qualifiedName と typeName からエンティティを取得
response = client.get_entity(qualifiedName="pyapacheatlas://hanainput01", typeName="azure_datalake_gen2_filesystem")
print(json.dumps(response, indent=2))
# GUID からエンティティを取得
response = client.get_entity(guid="41df8786-c2da-4384-8397-f93ef52a5d0b")
print(json.dumps(response, indent=2))
get_entity メソッドの戻り値は dict 型なので、これを pyapacheatlas.core.entity の AtlasEntity クラスに変換するには、from_json メソッドを使用します。後から既存のエンティティをロードして使いたい場合などに使用します。
AtlasEntity.from_json(response['entities'][0])
エンティティを検索する
エンティティを検索するには、 search_entities メソッドを使用します。ここでは検索クエリ構文が使用できます。
search = client.search_entities("hana*")
for entity in search:
print(json.dumps(entity, indent=2))
エンティティを削除する
エンティティを削除するには、delete_entity メソッドを使用します。
response = client.delete_entity(guid="6026ecde-4759-4daf-9b95-05a4229f485c")
print(json.dumps(response, indent=2))
スキーマの追加
データソースがデータベース系の場合、カラム情報もメタデータとして管理したいですよね。その場合、以下のように実行します。
# 1 つのテーブルを追加
table = AtlasEntity("hanasqldw001","azure_sql_dw_table", "pyapacheatlas://hanasqldw001", guid="-1")
# 2 つのカラムを追加
c1 = AtlasEntity("column1", "azure_sql_dw_column", "pyapacheatlas://hanasqldw001#col1", guid="-2", attributes={"data_type":"str"})
c2 = AtlasEntity("column2", "azure_sql_dw_column", "pyapacheatlas://hanasqldw001#col2", guid="-3", attributes={"data_type":"int"})
columns_to_add = [c1, c2]
table.addRelationship(columns=[c.to_json(minimum=True) for c in columns_to_add])
result = client.upload_entities([table, c1, c2])
print(json.dumps(result , indent=2))
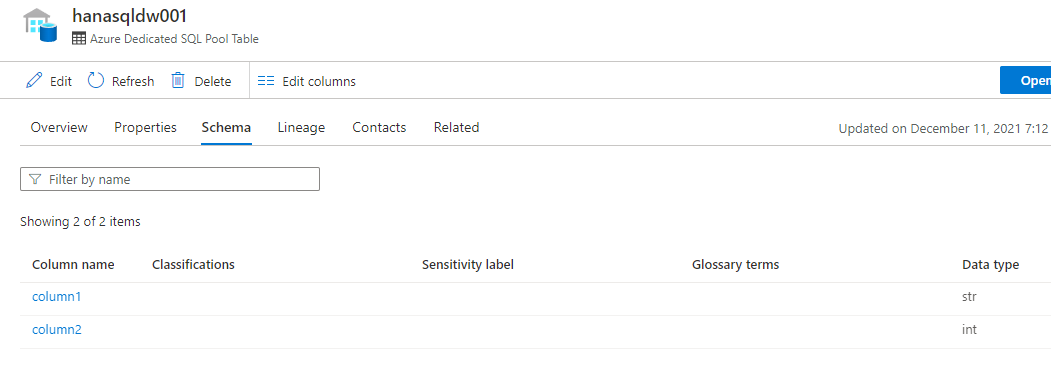
Azure Dedicated SQL Pool Table 型のテーブルを作ってその中に含まれるカラムを Azure Dedicated SQL Pool Column 型で作成しました。Atlas では 1 カラム 1 エンティティとして扱います。そして、addRelationship メソッドを使用して、関係 を作成しました。これによってエンティティ間の関係性を表現することができるようになります。
CSV ファイルなんかもヘッダーがあるので、同様にスキーマを追加することができます。この場合 delimited_text_schema 型のエンティティに delimited_text_schema_columns 型のカラムエンティティを関連付けます。
分類の追加
エンティティに分類を追加するには、以下のように実行します。
from pyapacheatlas.core import AtlasClassification
# 追加したいエンティティの GUID
guid = "5e597602-af21-4b5f-96f3-6cf6f6f60000"
# 1 つのエンティティを複数のカテゴリーに分類
one_entity_multi_class = client.classify_entity(
guid=guid,
classifications=[
AtlasClassification("MICROSOFT.PERSONAL.JAPANESE.MY.NUMBER.CORPORATE"),
AtlasClassification("MICROSOFT.PERSONAL.NAME")
],
force_update=True
)
print(json.dumps(one_entity_multi_class, indent=2))
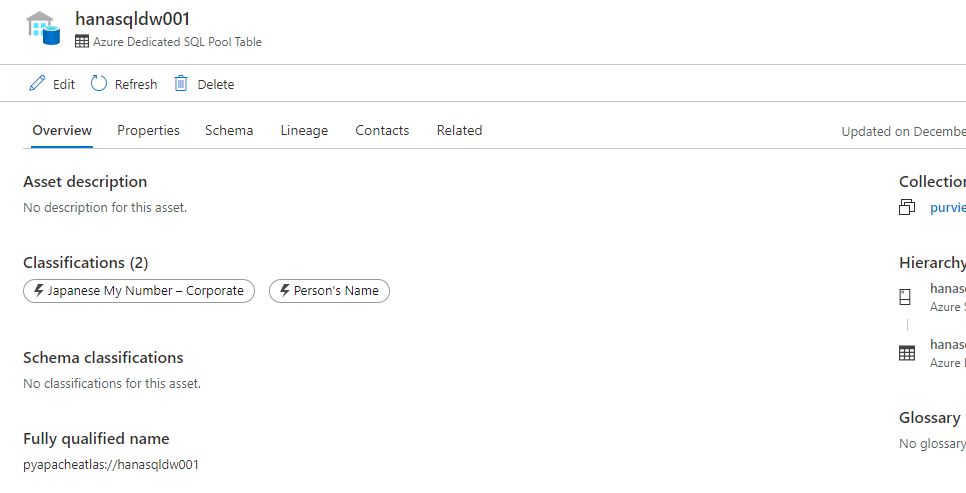
おー分類が追加されましたね。
この分類の事前定義については、get_all_typedefs() の root/classificationDefs 以下に定義されています。
特定の分類を削除するには、declassify_entity メソッドで削除できます。
client.declassify_entity(guid=guid,classificationName="MICROSOFT.PERSONAL.JAPANESE.MY.NUMBER.CORPORATE")
さて、基本的な操作について覚えたところで、次はもっと面白いデータ変換やリネージュと呼ばれるデータ系列の作成をしていきたいと思います。が、記事が長くなってきたので、次回の記事にて書こうと思います。
こんな感じで遊びながら触ってるだけでも内部の仕組みについて理解できると思いますので、皆さんも Azure Purview を触ってみてほしいなと思います。そして、一緒に新しいソリューションを作っていけたら幸いです。
つづきはこちら
参考
pyapacheatlas の Documents は doc 以下で Sphinx をビルドしてください。
samples の中にたくさんの使えるコードがあります。