はじめに
Elasticのv9.1に登場したES|QLクエリーのCATEGORIZEコマンドをログに対して使うと、数万行に及ぶログでも、数十通りのログパターンとして分類することができます。
そして、同じくv9.1に登場したES|QLクエリーのCOMPLETIONコマンドを使うと、ログそれぞれに対してLLMにそのログの解析や解説をしてもらうことができます。
今回はこれらの機能を使い、Elasticに投入されているログの全体像を把握できるかを挑戦していきます。
そして最後にv9.3で登場したElastic Workflowsを使ってログ解析結果をElasticのIndexに記録、保存することもやってみました。
CATEGORIZEコマンドのドキュメント
https://www.elastic.co/docs/reference/query-languages/esql/functions-operators/grouping-functions#esql-categorize
COMPLETIONコマンドのドキュメント
https://www.elastic.co/docs/reference/query-languages/esql/commands/completion
今回の利用環境は2026年1月時点のElastic Cloud Serverless - Observability Completeです。オンプレのElastic StackやElastic Cloud Hostedの場合はElastic Stack v9.3を使えば同じ結果になると思います。また、今回のCOMPLETIONSやWorkflowsの機能は、Elastic StackとElastic Cloud Hostedの場合はEnterpriseサブスクリプションが必要な機能です。CATEGORIZEはPlatinumサブスクリプションが必要です。これら全てElastic Stack/Cloudのフリートライアル版で試すこともできます。
CATEGORIZEコマンドについて
以下が簡単な使用例です。message列にログ本文が格納されており、同じパターン分類でログ数を集計します。
FROM sample_data
| STATS count=COUNT() BY category=CATEGORIZE(message)
| count:long | category:keyword |
|---|---|
| 3 | .*?Connected.+?to.*? |
| 3 | .*?Connection.+?error.*? |
| 1 | .*?Disconnected.*? |
同じログパターンと判定するに当たり、どれだけ細かな違いを識別するかは、オプションのsimilarity_thresholdを設定することで調整することができます。指定しない場合、デフォルト値は70です。
CATEGORIZEコマンドを使うときは、事前にログメッセージはパースしておき、ログのタイムスタンプや、IPアドレスといった主な属性はログメッセージから切り離しておかないと分類がうまくされない可能性ありますので、事前にそのように加工しておいてください。以下の記事などを参考にしてください。
[v9.2 Tech Previewの新機能Wired Streamsでどこまでログのパースが楽になるかをやってみた]
https://qiita.com/nobuhikosekiya/items/7f1a17835b114b750f25
実際に本格的なログで検証
https://github.com/logpai/loghub から無料でダウンロードできるOpenStackのログに対して検証してみます。このようにログが何万行とあると、ログの全体像を把握しようなどと考えませんよね?
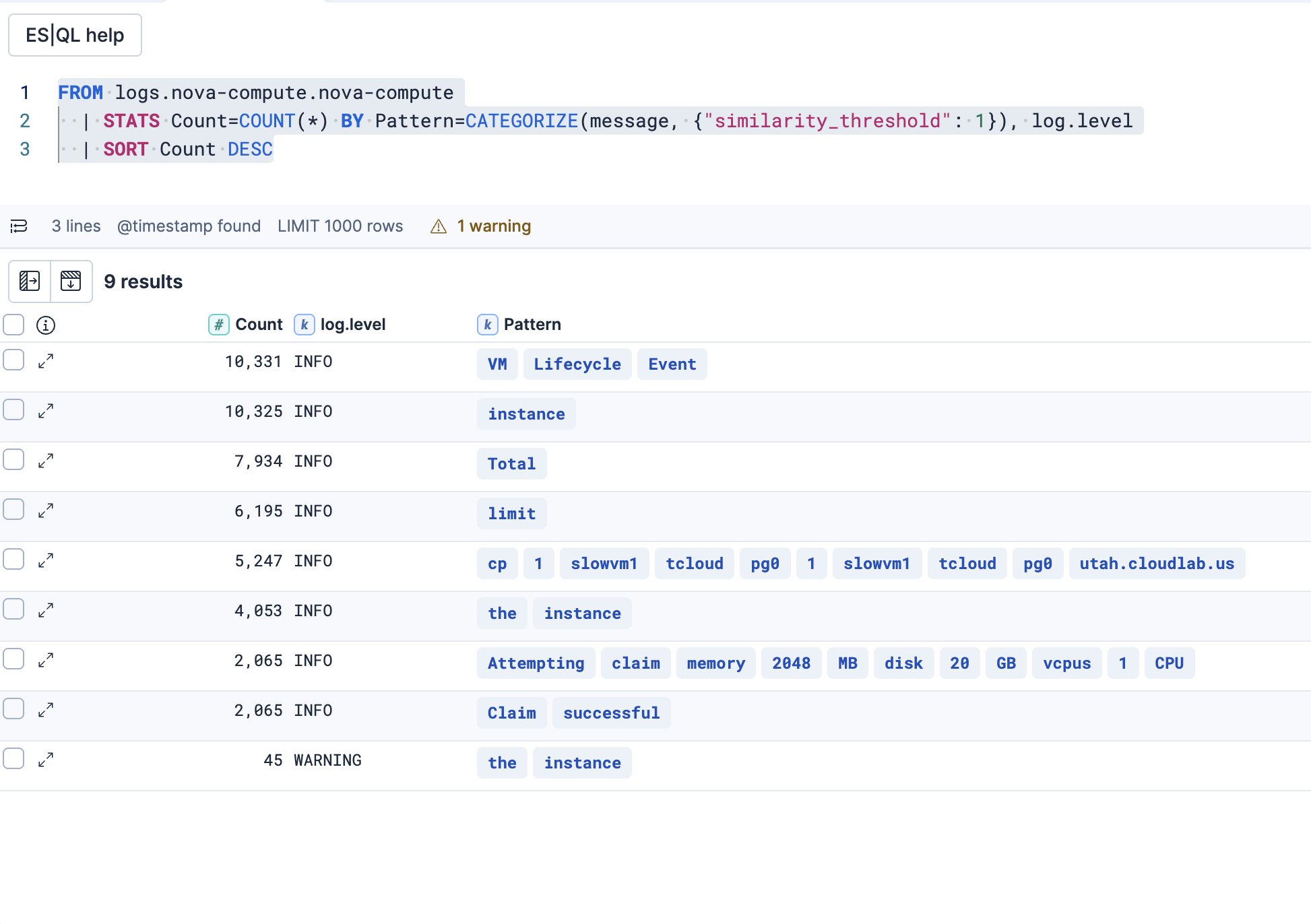
まず最も分類が大雑把なsimilarity_threshold: 1の結果です。数万件のログが9個のパターンに分類されました。パターンを見ると、分類が大雑把すぎてあまり役立たない内容であることがわかります。
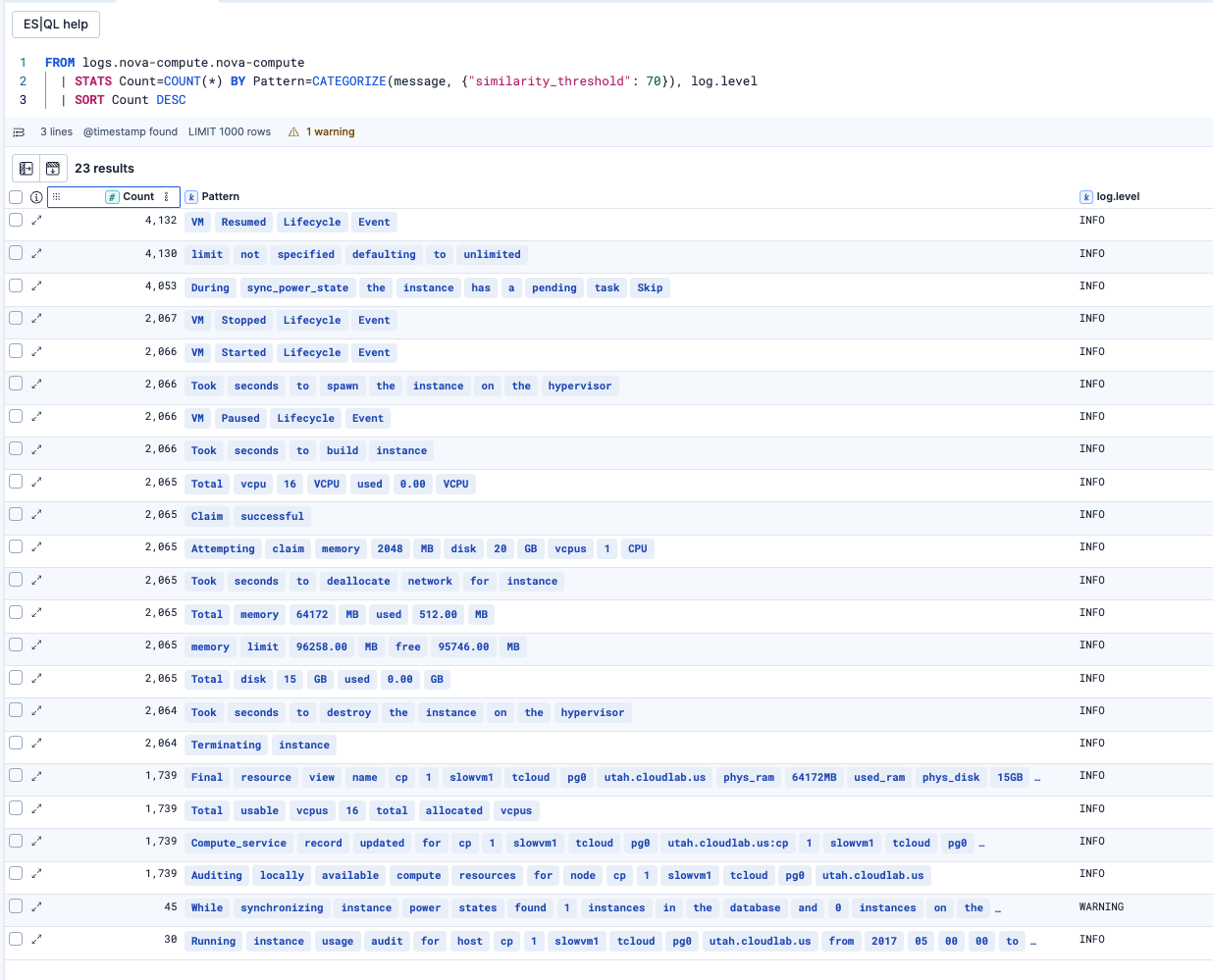
次はデフォルト値と同じsimilarity_threshold: 70の結果です。23件のパターンに分類されました。パターンを見ると、ログの内容が理解できるレベルの分類になっており、分類として使えそうです。
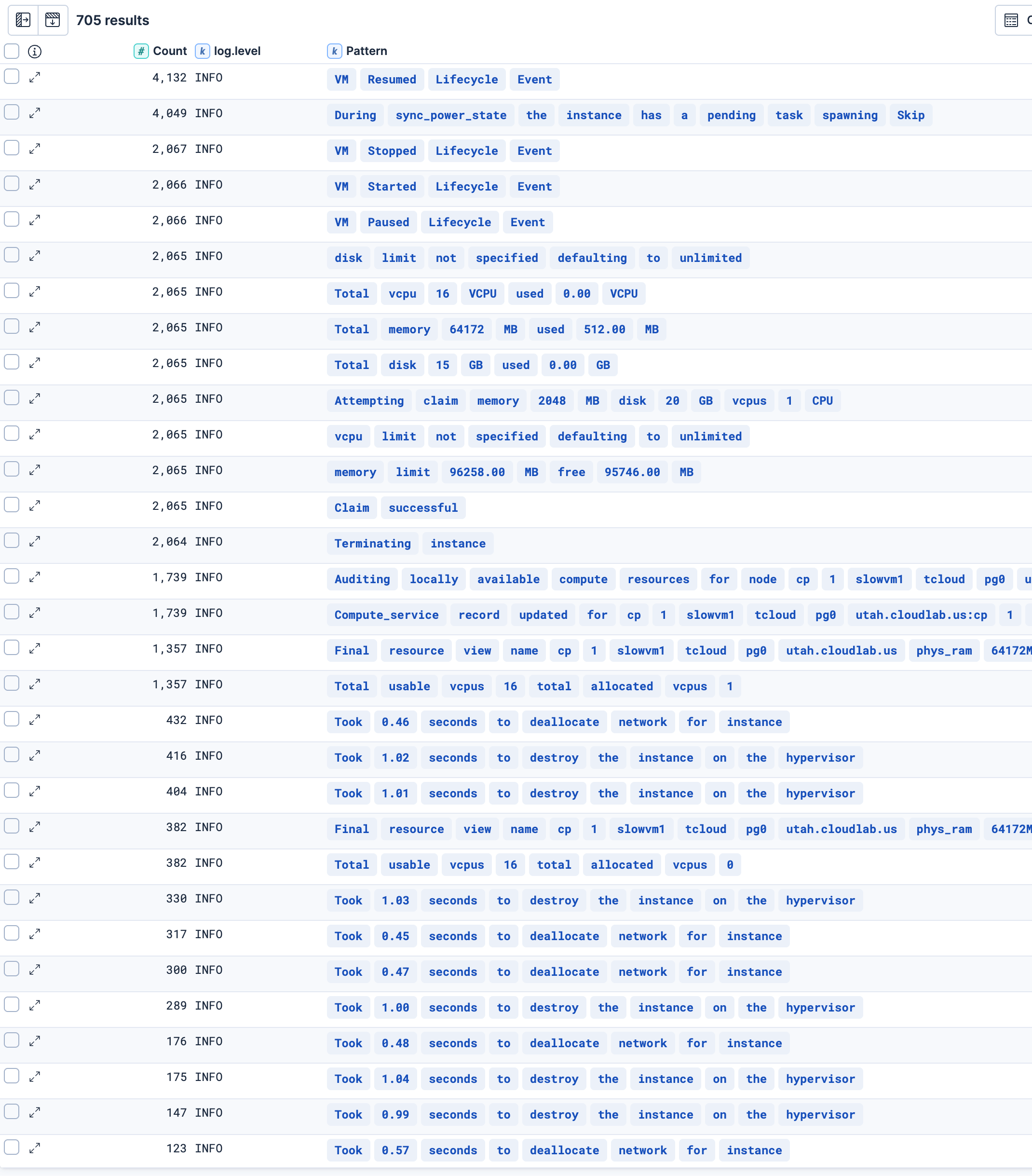
そして、以下が最も過敏に分類してくれるsimilarity_threshold: 100です。これもトップ20行くらいは分類として悪くなさそうですが、下の方のCount: 416のあたりの行から、中の数値だけ異なるけど同じログが別々に分類されてしまっていますので、分類が過敏すぎると言えます。
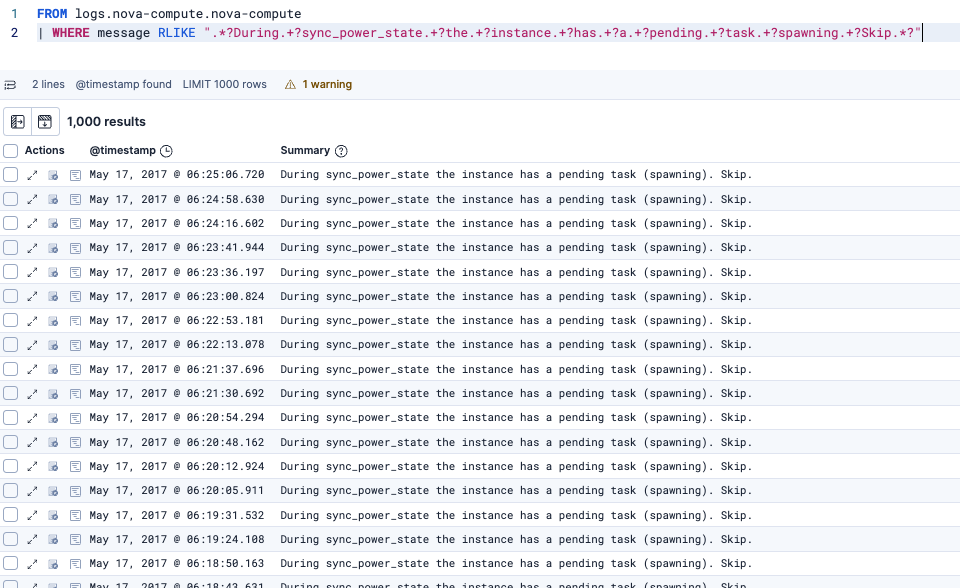
なお、各分類の中の実際のログを確認したい場合は、以下のように元のログに対して、ログパターンの文字列をRLIKEで正規表現マッチさせると確認できます。
また、上記はレンジ内の全てのログに対して分類をしていましたが、主要なログだけ確認できれば良い場合は、SAMPLEコマンドでサンプリングすると、計算を軽く、スピーディにできます。
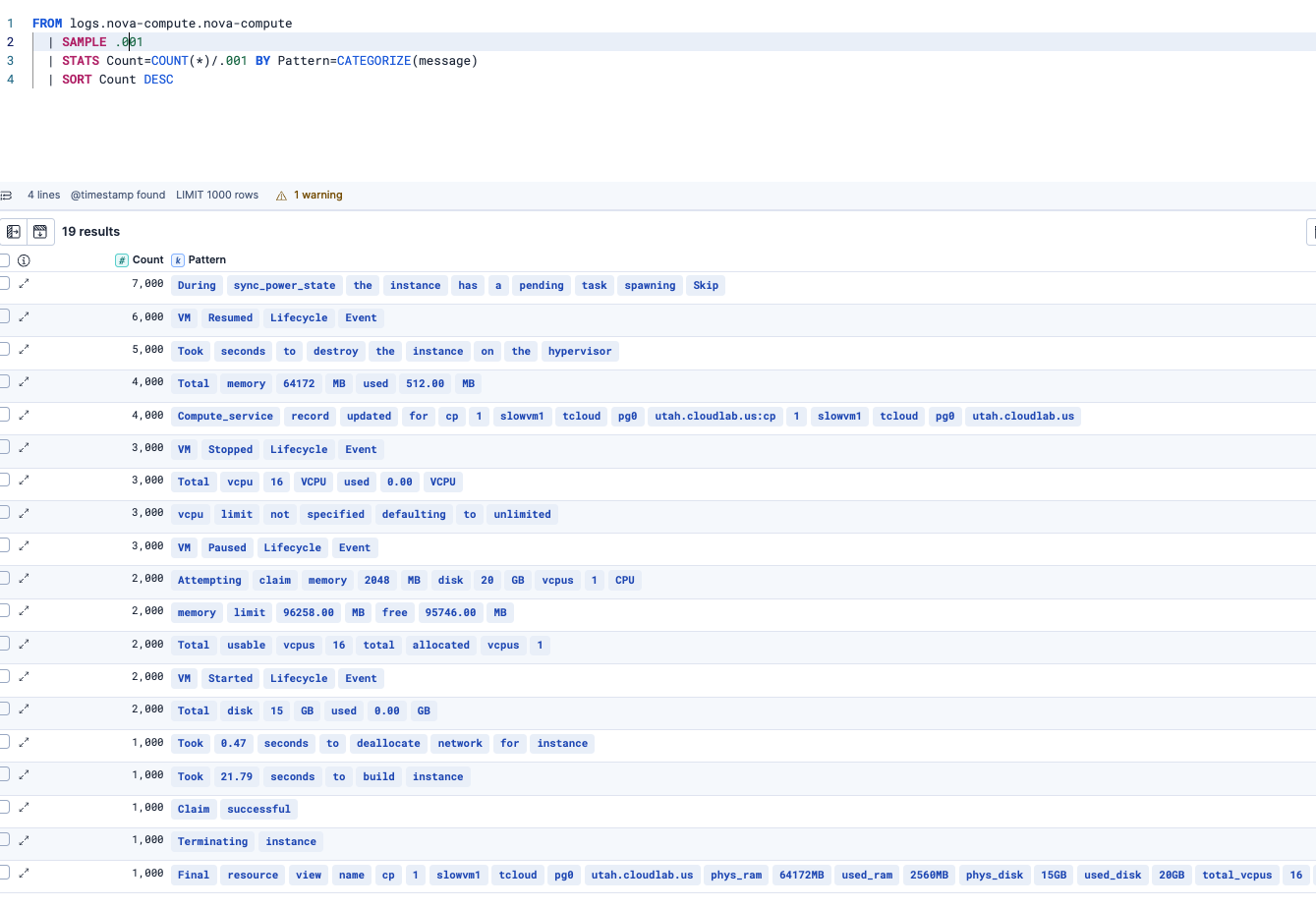
SAMPLEコマンドを使わない場合、CATEGORIZEコマンドは全てのログを分析するので、Elasticのクラスタにそれなりの負荷が掛かる可能性があります。本番環境で使う場合は、まずは対象ログの時間レンジを限定するなどして試してください。
COMPLETIONコマンドでログの意味をLLMにその場で解説してもらう!
ES|QLのCOMPLETIONコマンドを使うと、ログメッセージを自由にLLMに解説させることができます。今回はこれを使い、それぞれのログパターンに対する解説を行ってみます。数万行のログに対してLLMを使うことは現実的ではありませんが、このように数十〜数百行のログパターンになっていれば可能になってきます。
以下はとりあえず3件のログパターンに対して実施してみた結果です。completion列にLLMからの解説が入ってますね!
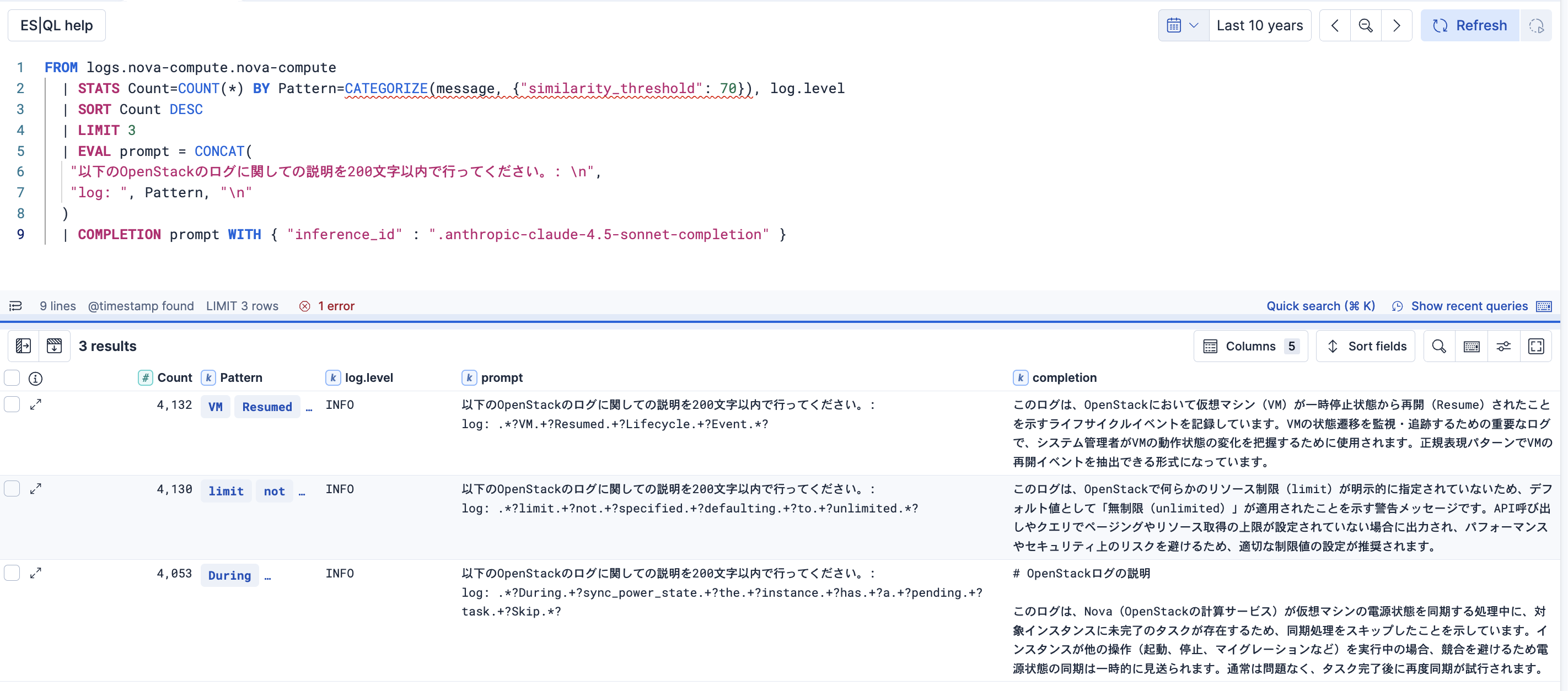
上のES|QLは以下の通りです。
FROM logs.nova-compute.nova-compute
| STATS Count=COUNT(*) BY Pattern=CATEGORIZE(message, {"similarity_threshold": 70}), log.level
| SORT Count DESC
| LIMIT 3
| EVAL prompt = CONCAT(
"以下のOpenStackのログに関しての説明を200文字以内で行ってください。: \n",
"log: ", Pattern, "\n"
)
| COMPLETION prompt WITH { "inference_id" : ".anthropic-claude-4.5-sonnet-completion" }
ログパーンの文字列がPatternに入っているので、それと指示を含めたプロンプトをpromptの変数に設定してます。最後にCOMPLETIONコマンドでは、利用したいLLMを指すInference EndpointのIDを指定することで、LLMのAPIが利用されます。
今回のCOMPLETIONコマンドのinference_idで使っている値.anthropic-claude-4.5-sonnet-completionは、Elastic CloudのElastic Managed LLMが使用できるライセンスタイプであればデフォルトで使うことができるLLMです。(2026年1月現在使えるElastic Managed LLMです。時期が変わると使えるLLMが変わるかもしれません)
プロンプトを変更し、さらにリファレンスになりそうなリンクもつけてもらいましょう。
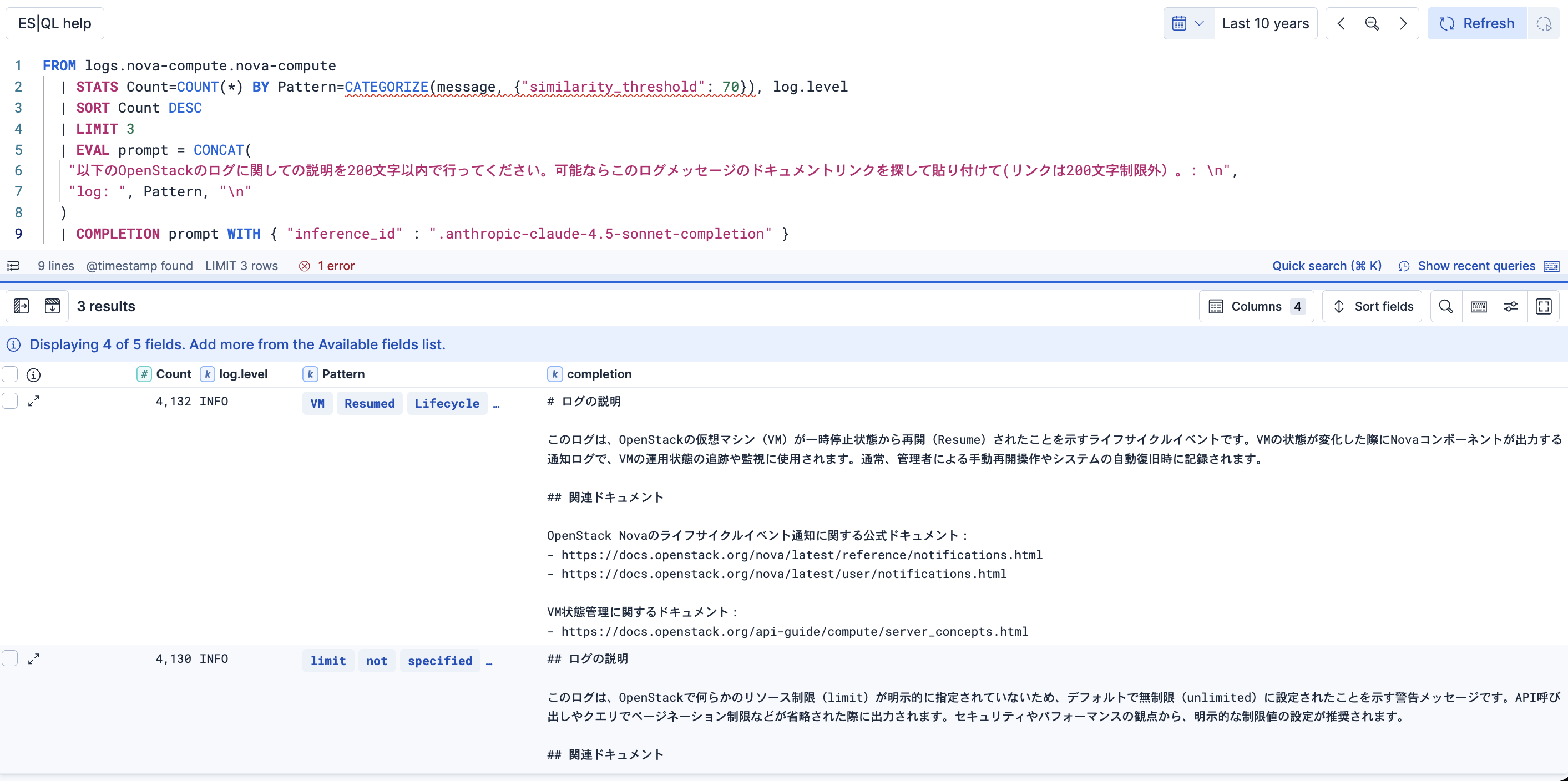
FROM logs.nova-compute.nova-compute
| STATS Count=COUNT(*) BY Pattern=CATEGORIZE(message, {"similarity_threshold": 70}), log.level
| SORT Count DESC
| LIMIT 3
| EVAL prompt = CONCAT(
"以下のOpenStackのログに関しての説明を200文字以内で行ってください。可能ならこのログメッセージのドキュメントリンクを探して貼り付けて(リンクは200文字制限外)。: \n",
"log: ", Pattern, "\n"
)
| COMPLETION prompt WITH { "inference_id" : ".anthropic-claude-4.5-sonnet-completion" }
Elastic v9.3新登場のWorkflowsで結果を保存
ログの意味を知りたいと思ったときに毎回CATEGORIZEとCOMPLETIONSを実行するのはコストがかかるので、新しく出たElastic Workflowsを使って結果を別のIndexに保存してみたいと思います。
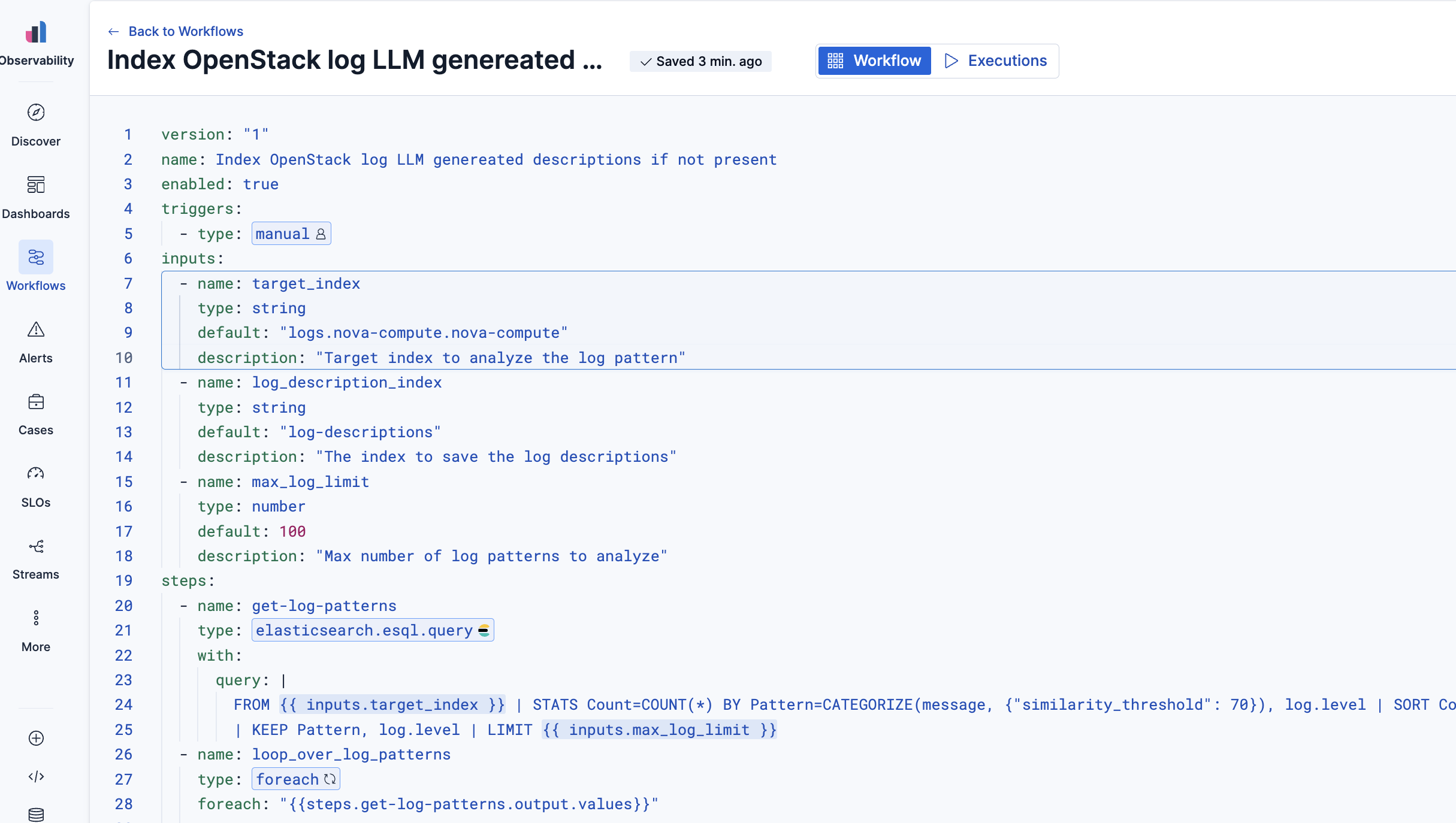
いきなり結果から行きますが、今回のワークフロー定義はこのようなものです。(下の方に全文載せました)
これを使うと、このように別のIndexにログパターンとその解説を保存することができました。
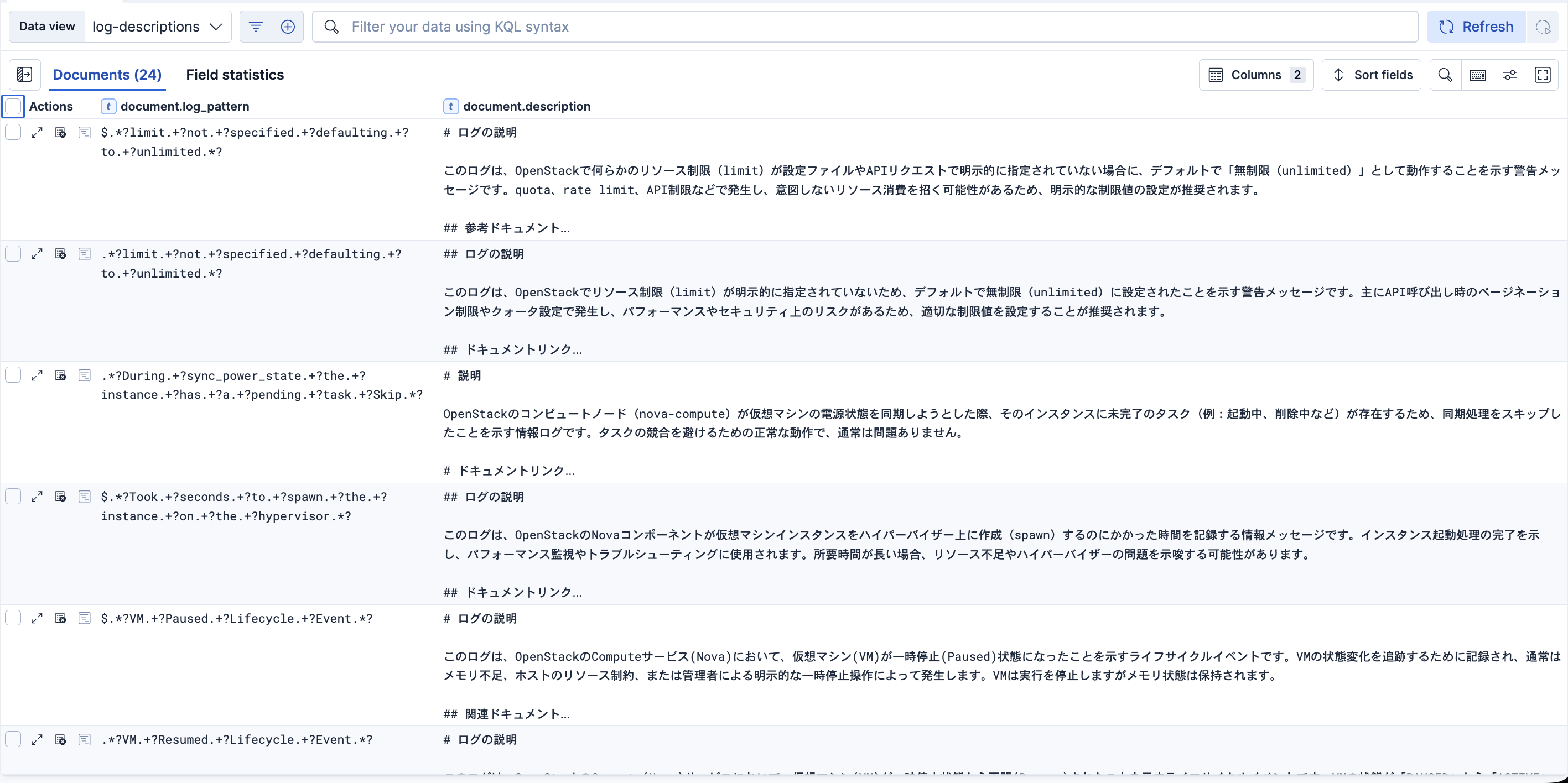
以下は今回のWorkflow設定の全体像です。各Stepについて簡単に説明します。
- get-log-patterns ... 最初にCATEGORIZEを実行し、ログパターンを取得
- loop_over_log_patterns ... それぞれのログパターン毎に次のことを繰り返す
- search_existing_pattern ... 解説保存先Indexにログパターンの解説が既に存在するかをチェック
- check-status ... search_existing_patternの結果のヒット有無を判定。解説がまだ存在しない場合は次を実行
- get_log_description ... COMPLETIONコマンドを使い、ログパターンのLLM解説を取得
- log_to_elasticsearch ... ログ保存先Indexに、ログパターン、解説、ログレベル、更新日時、解析対象Index名などを記録
version: "1"
name: Index OpenStack log LLM genereated descriptions if not present
enabled: true
triggers:
- type: manual
inputs:
- name: target_index
type: string
default: "logs.nova-compute.nova-compute"
description: "Target index to analyze the log pattern"
- name: log_description_index
type: string
default: "log-descriptions"
description: "The index to save the log descriptions"
- name: max_log_limit
type: number
default: 100
description: "Max number of log patterns to analyze"
steps:
- name: get-log-patterns
type: elasticsearch.esql.query
with:
query: |
FROM {{ inputs.target_index }} | STATS Count=COUNT(*) BY Pattern=CATEGORIZE(message, {"similarity_threshold": 70}), log.level | SORT Count DESC
| KEEP Pattern, log.level | LIMIT {{ inputs.max_log_limit }}
- name: loop_over_log_patterns
type: foreach
foreach: "{{steps.get-log-patterns.output.values}}"
steps:
- name: search_existing_pattern
type: elasticsearch.search
with:
index: "{{ inputs.log_description_index }}"
query:
bool:
filter:
- term:
document.log_pattern.keyword: "{{ foreach.item[0] }}"
size: 1
- name: check-status
type: if
condition: "steps.search_existing_pattern.output.hits.total.value: 0"
steps:
- name: get_log_description
type: elasticsearch.esql.query
with:
query: |
ROW Pattern = "{{ foreach.item[0] | replace: "\\", "\\\\" }}", log.level = "{{ foreach.item[1] }}", prompt = CONCAT(
"以下のOpenStackのログに関しての説明を200文字以内で行ってください。可能ならこのログメッセージのドキュメントリンクを探して貼り付けて(リンクは200文字制限外)。: \n",
"log: ", "{{ foreach.item[0] | replace: "\\", "\\\\" }}", "\n"
)
| COMPLETION prompt WITH { "inference_id" : ".anthropic-claude-4.5-sonnet-completion" }
| KEEP Pattern, log.level, completion
- name: log_to_elasticsearch
type: elasticsearch.index
with:
index: "{{ inputs.log_description_index }}"
id: "{{ execution.id }}-{{ foreach.index }}"
document:
log_index: "{{ inputs.target_index }}"
updated_at: "{{ execution.startedAt | date: '%Y-%m-%dT%H:%M:%SZ' }}"
log_pattern: "{{ steps.get_log_description.output.values[0][0] }}"
log.level: "{{ steps.get_log_description.output.values[0][1] }}"
description: "{{ steps.get_log_description.output.values[0][2] }}"
else:
- name: "found existing log pattern entry"
type: console
with:
message: "existing log pattern entry {{ foreach.item[0] }}"
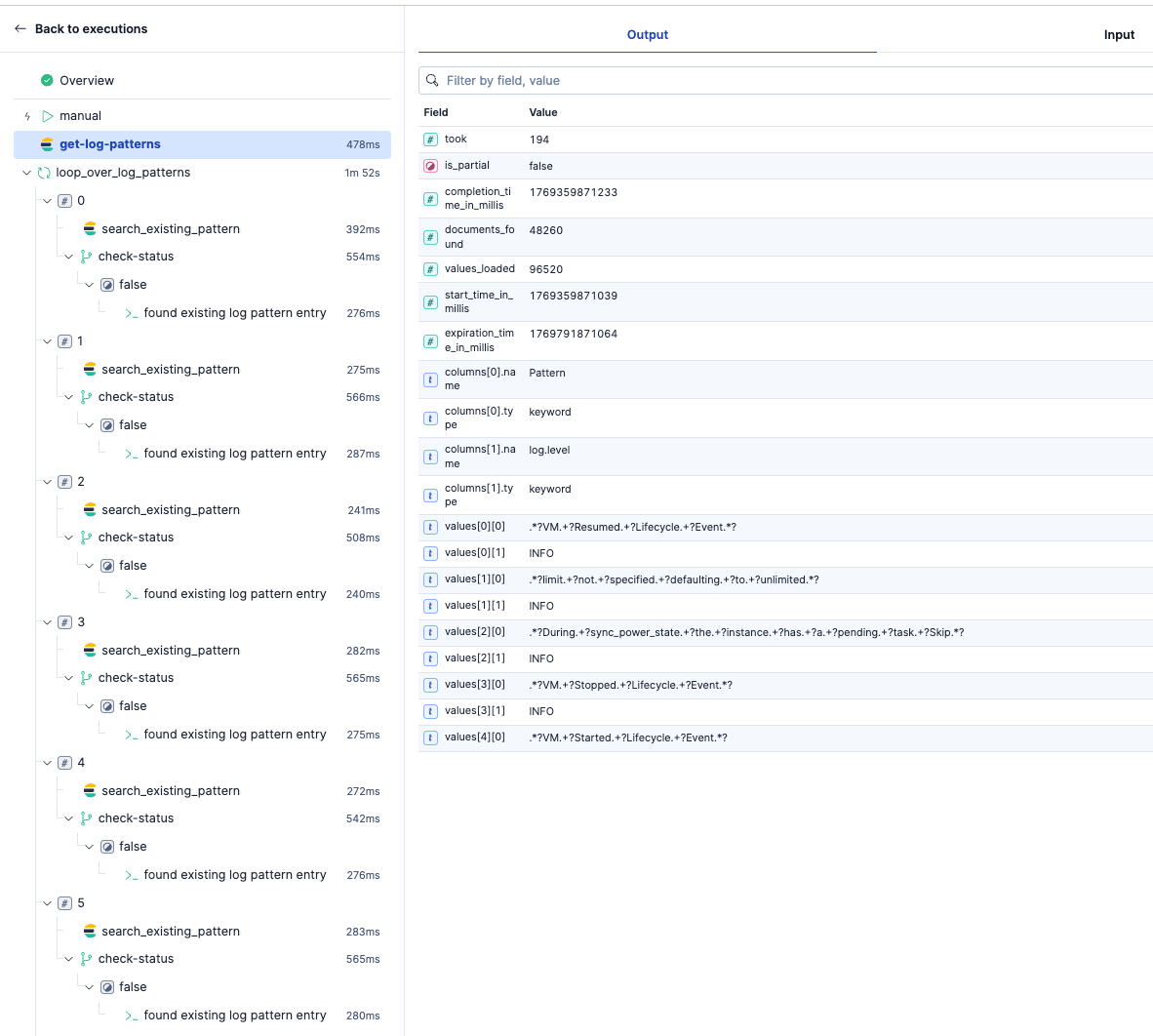
実際の実行例です。ログパターン毎に処理を行っていることがわかります。
最後、上で使ったログ解説保存先のIndexの定義を記しておきます。登録時の_idはログパターンに対するハッシュにしているので、同じログパターンに関しては重複登録されないようになります。
PUT _ingest/pipeline/hash_id_pipeline
{
"processors": [
{
"fingerprint": {
"fields": ["document.log_pattern"],
"method": "MD5",
"target_field": "_id"
}
}
]
}
PUT log-descriptions
{
"settings": {
"index.default_pipeline": "hash_id_pipeline"
},
"mappings": {
"properties": {
"document": {
"properties": {
"log_index": {
"type": "keyword"
},
"description": {
"type": "text"
},
"log": {
"properties": {
"level": {
"type": "keyword"
}
}
},
"log_pattern": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"updated_at": {
"type": "date"
}
}
}
}
}
}
おわり
数万行のログをそのままLLMに与えることはコスト、正確さ、時間の面で現実的といえないと思います。Elasticの強力なログ分類コマンドを使うと、一気にLLMにへ与える情報量をパターン分類として圧縮できます。ES|QL CATEGORIZE + ES|QL COMPLETION + Elastic Workflows は最強のコンビネーションと言えるでしょう。