はじめに ES|QLのおさらい
ElasticsearchのES|QLは、v8.14から使えるElasticsearchのクエリー言語です。2ヶ月前ほどにリリースされたv9.2からRRFのハイブリッド検索をサポートするようになりました。
それ以前からElasticsearchではQuery DSL言語にてハイブリッド検索はできており、RAGのユースケースで利用されています。
今回それがES|QLにて、もっと書きやすいクエリー形式でもできるようになりました。ES|QLはQuery DSLと比べると大分書きやすいため、Kibanaのダッシュボードで使ったり、AIエージェントがElasticsearchをデータソースとしてアクセスする際も、ES|QLを使った方がコーディングしやすくなります。(コード差分表示などのメンテナンスの意味も含め)
この記事の中の機能を全て実践する場合、ElasticのEnteprise Subscriptionが必要です。
ただし、セルフマネージド版やElastic Cloudでのトライアルライセンス版にて、無料でお試しが可能です。
Elastic Stack v9.1/v9.2で何ができるようになったか
例えば、以下のようなナレッジ検索の精度比較用のKibanaダッシュボードが作れるようになりました。
このダッシュボードは、ハイブリッド検索のRRF、ハイブリッド検索無しの日本語形態素解析ありのテキスト検索、日本語形態素解析無し(デフォルトの英語向けの設定)のテキスト検索など、複数の検索手法を一度に実行して、結果を並べて表示しています。
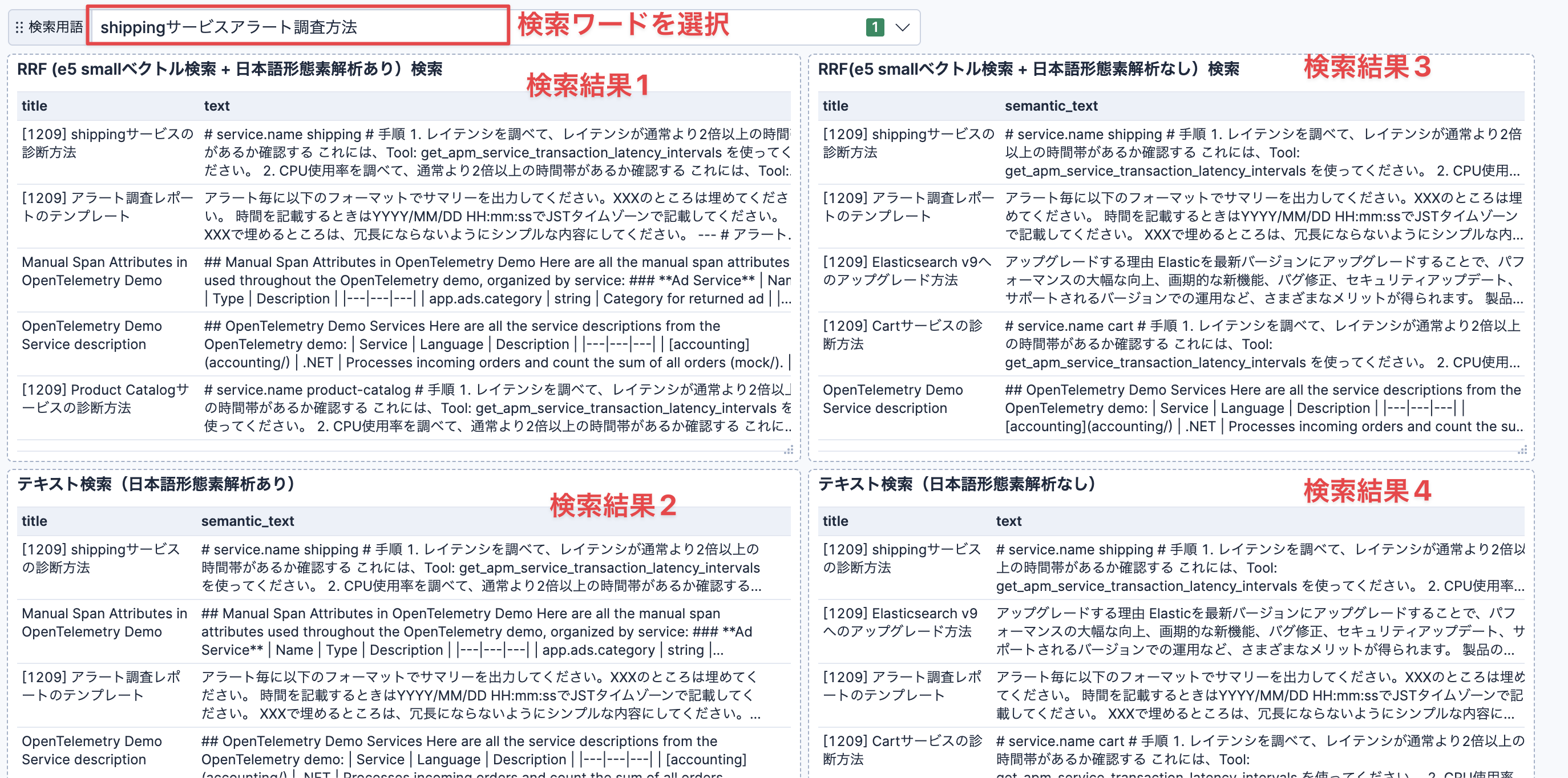
以前はこのようなダッシュボードを作ることはできませんでした。以下の最近の新機能にてこれは実現できるようになりました。
- v8.x: KibanaダッシュボードにES|QLベースのビジュアライゼーションが表示可能になった
- v9.2: ES|QLのFORK, FUSEコマンドがTech Previewとして登場し、RRFがES|QLで可能になった
- v9.1: Kibanaのvariable controls ( 旧名 ES|QL controls ) がTech Previewで登場。ダッシュボード内で使われているES|QLクエリーの中に変数が使え、ダッシュボードのコントロール(コンボボックス)で変数の値を切り替えできるようになった。
- v9.0 GA: ES|QLでMATCHファンクション等、テキスト検索およびベクトル検索用のコマンドが登場
- v8.x: v8系の後半に登場したsemantic_textフィールドタイプにより、シンプルな設定でベクトル検索用フィールドを設定できるようになりました。さらに、semantic_textを使うと自動的なチャンキングもしてくれます。そして柔軟に利用するベクトルMLモデルを変更できます。また、これによってtext型フィールドと同様にMATCHコマンドでベクトル検索も可能になっています。
KibanaダッシュボードでのES|QLを使ったナレッジ検索の利用
左上のウィジットの編集画面を開いた状態です。
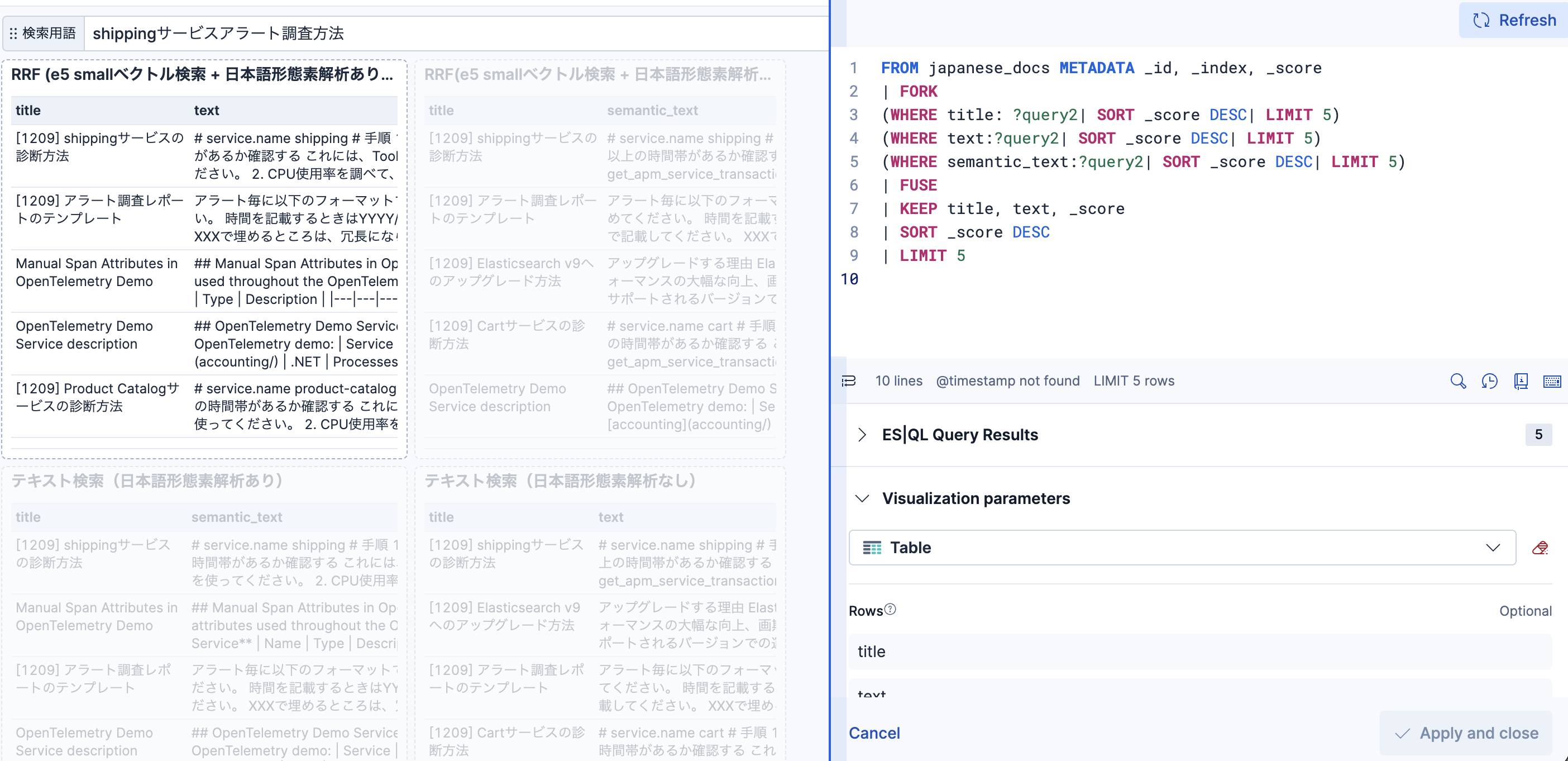
以下のようなES|QLクエリーとなっています。
- titleフィールドに対してのテキスト検索
- textフィールドに対してのテキスト検索
- semantic_textフィールドに対してのe5 smallモデルを使ったベクトル検索
- FORK ~ FUSEにより、各検索手法の結果をマージしつつ、RRFアルゴリズムで検索結果をランキング
-
?で始まるのが変数部分です。ダッシュボードの"検索用語"のラベルがついたコンボボックスでこの値を切り替えています。
ES|QLによるハイブリッド検索は、こちらのElasticのチュートリアルページに解説があります。このブログではクエリーについて細かい解説はしないので、クエリーの書き方についてはこのチュートリアルをご覧いただくと良いです。そのページにはRRFの他、検索結果をマージするときに重みをコントロールできるLinear combinationも紹介されています。
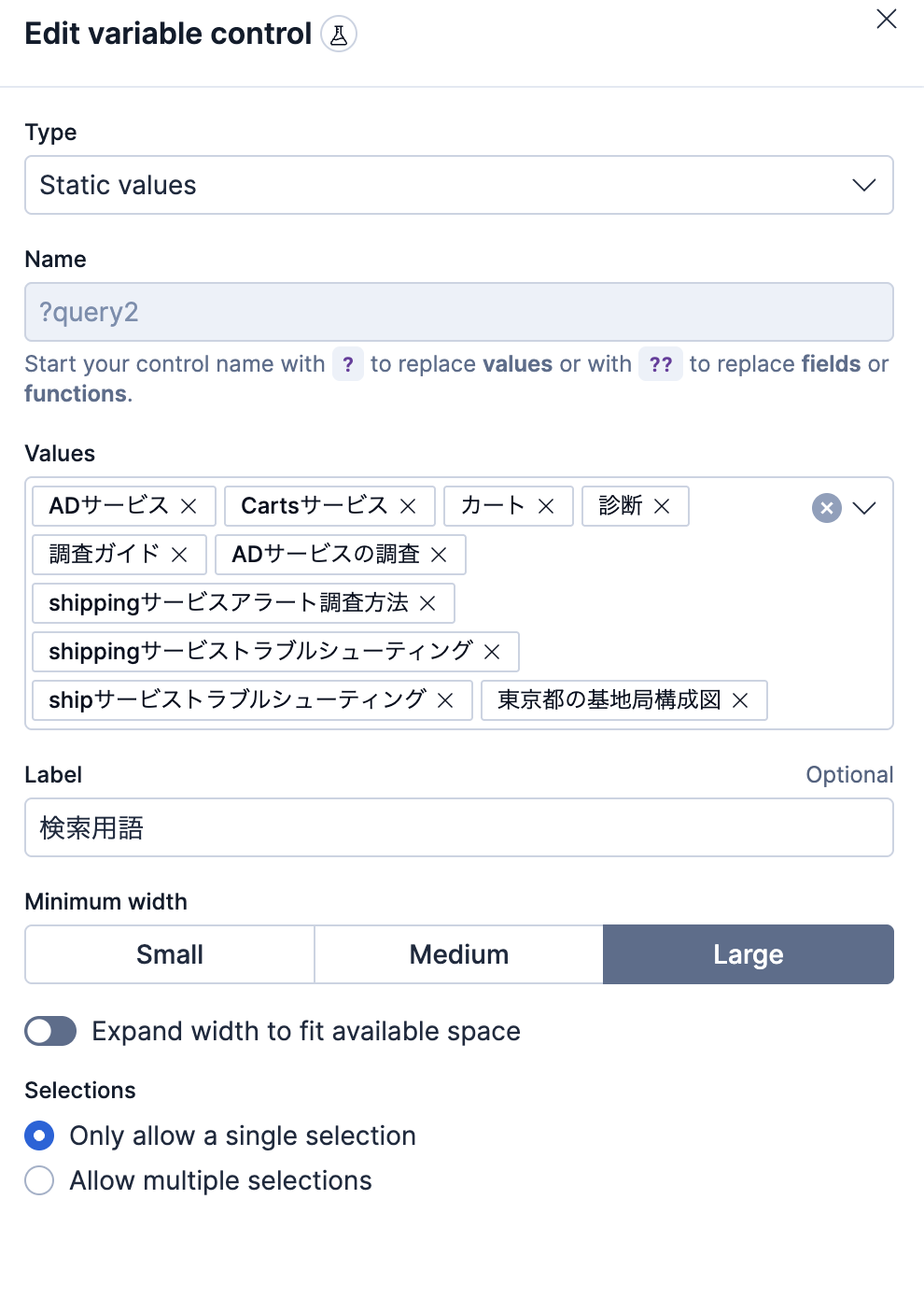
varible controlのコンボボックスの編集画面は以下のようになっています。テストする検索ワードを登録しています。
AIエージェントでどう活用するか? コンテキストエンジニアリングに必要な外部コンテキストの取り込み
v9.2からTech Previewで登場したElastic Agent Builderは、Elasticsearchのデータを活用するためのオリジナルのAIエージェントを作成できる新機能です。MCPにも対応しています。ここで作るMCP Toolsとして、ES|QLクエリーが実行できます。そして、この機能で作られたAIエージェントはES|QLを使ってElasticsearchに蓄積された大量のナレッジドキュメントに対して検索を行い、RAGの手法にてAIがコンテキストを取り込む形となります。
Elastic Agent Builderで作成するToolの例:

ES|QLはElasticsearchのREST APIやElasticsearch SDKでも使えるので、Elastic Agent Builderだけでなく他で作られたAIエージェントでも検索精度の高いElasticsearchをコンテキスト用のデータベースとして使うことができます。
ベクトル検索 + 日本語形態素解析ができるIndexの作成の仕方
従来はElasticsearchのスペシャリストでないと設定が難しかったですが、今は生成AIに聞けば日本語形態素解析用のIndexを簡単に作ってくれます。日本語検索用のkuromojiやicuプラグインを使ったAnalyzerの定義を作ってくれます。以下は今回のダッシュボード作成に使った一例です。
PUT japanese_docs
{
"settings": {
"analysis": {
"tokenizer": {
"ja_tokenizer": {
"type": "kuromoji_tokenizer"
}
},
"analyzer": {
"ja_analyzer": {
"type": "custom",
"tokenizer": "ja_tokenizer",
"filter": [
"kuromoji_baseform",
"kuromoji_part_of_speech",
"kuromoji_stemmer",
"lowercase",
"icu_folding"
],
"char_filter": [
"icu_normalizer"
]
}
}
}
}
}
そして、この日本語Analyzerによる検索を使いたいフィールドに設定します。今回はtextとtitleというフィールドに設定します。
さらに、プラスしてMLモデル(e5多言語モデルなど)を使ったベクトル検索を使いたい場合は、type: semantic_textのフィールドを追加し、そこに利用するMLモデルの設定を行います。今回はsemantic_textとsemantic_titleです。つまり、ナレッジのタイトルと本文両方に対して日本語形態素解析とベクトル検索の良いとこ取りをする設定です。
POST japanese_docs/_mapping
{
"properties": {
"semantic_text": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch",
"model_settings": {
"service": "elasticsearch",
"task_type": "text_embedding",
"dimensions": 384,
"similarity": "cosine",
"element_type": "float"
}
},
"semantic_title": {
"type": "semantic_text",
"inference_id": ".multilingual-e5-small-elasticsearch",
"model_settings": {
"service": "elasticsearch",
"task_type": "text_embedding",
"dimensions": 384,
"similarity": "cosine",
"element_type": "float"
}
},
"text": {
"type": "text",
"analyzer": "ja_analyzer"
},
"title": {
"type": "text",
"analyzer": "ja_analyzer"
}
}
}
ナレッジ ドキュメントの入れ方は?
本格的にやっていく場合、外部のドキュメントサービスからElasticsearchに同期取り込みする仕組みが必要です。例えばSharepoint、Confluence、Box、GitHubなどにあるドキュメントをElasticのコネクター群を使って同期取り込みすることもできます。それ以外に、取り込みのためにスクリプトを組んだりLogstashを使って取り込んだりもできます。(いずれも結局はElasticsearchのBulk Ingest APIを呼び出しています)
今回はKibanaの上で完結するお手軽に実践できるやり方を紹介します。
AIアシスタントのナレッジベース機能を使うと、KibanaのWeb画面から簡単にナレッジを入力可能です。(ただし、MLノードを使うので有償ライセンスもしくはトライアル版出ある必要があります)
画面右上にあるAI AssistantアイコンからManage knowledge baseを開きます。

シンプルですが、ナレッジのタイトルと本文(Markdownをサポート)を入力できます。Kibana画面の中で唯一、APIやJSONを触らずに、簡単にドキュメントを登録できるのが実はこの機能だけです。

この機能で登録したナレッジは、システムのIndex .kibana-observability-ai-assistant-kb-*に入っています。title, textのフィールドにタイトル、本文のテキストが入ります。
このIndexではe5の他言語対応のベクトル検索は使えるものの、日本語形態素解析の対応がされていないので、それが使いたい場合は別のIndexに_reindexコマンドでデータをコピーする形で対応できます。(日本語形態素解析が不要で、他にカスタマイズの必要なければこのIndexをそのまま使うのでOKです)
以下は上で作った新しいIndex(japanese_docs)に_reindexコピーする例です。(Web画面でナレッジを更新・追加する都度この操作が必要です。よって、あくまでちょっとしたテスト向けの場合の手法です)
POST _reindex
{
"source": {
"index": ".kibana-observability-ai-assistant-kb-*",
"_source": ["title", "text"]
},
"dest": {
"index": "japanese_docs"
},
"script": {
"lang": "painless",
"source": """
ctx._id = ctx._source.id != null ? ctx._source.id : ctx._id;
if (ctx._source.title == null) {
ctx._source.title = "";
}
if (ctx._source.text == null) {
ctx._source.text = "";
}
ctx._source = [
"title": ctx._source.title,
"semantic_title": ctx._source.title,
"text": ctx._source.text,
"semantic_text": ctx._source.text
];
"""
}
}
上記を実行すると、今回作ったIndex: japanese_docs で設定された日本語形態素解析や、semantic_title, semantic_textのフィールドでベクトル検索もできるようになります。
_reindexして投入したデータは以下のとおり確認できます。e5モデルのML推論を通して、作成されたベクトルの配列もsemantic_textフィールドにて確認できます。
GET japanese_docs/_search
{
"_source": {
"exclude_vectors": false
}
}
APIのレスポンス:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 34,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "japanese_docs",
"_id": "2016787c-8ede-4db6-8655-1bdd7b1defe6",
"_score": 1,
"_source": {
"semantic_text": """アラート毎に以下のフォーマットでサマリーを出力してください。XXXのところは埋めてください。
時間を記載するときはYYYY/MM/DD HH:mm:ssでJSTタイムゾーンで記載してください。
XXXで埋めるところは、冗長にならないようにシンプルな内容にしてください。
---
# アラート名 XXX の概要
アラート発生時刻:XXX
アラート発生前後のトランザクションレイテンシの上昇発生有無とその時間帯: XXX
アラート発生前後の診断数値毎の上昇有無とその時間帯: XXX
前日との比較を行った場合、前日と比べて上昇していた指標:XXX
""",
"semantic_title": "[1209] アラート調査レポートのテンプレート",
"text": """アラート毎に以下のフォーマットでサマリーを出力してください。XXXのところは埋めてください。
時間を記載するときはYYYY/MM/DD HH:mm:ssでJSTタイムゾーンで記載してください。
XXXで埋めるところは、冗長にならないようにシンプルな内容にしてください。
---
# アラート名 XXX の概要
アラート発生時刻:XXX
アラート発生前後のトランザクションレイテンシの上昇発生有無とその時間帯: XXX
アラート発生前後の診断数値毎の上昇有無とその時間帯: XXX
前日との比較を行った場合、前日と比べて上昇していた指標:XXX
""",
"model_id": "azure_openai_completion",
"title": "[1209] アラート調査レポートのテンプレート",
"category": "その他",
"_inference_fields": {
"semantic_text": {
"inference": {
"inference_id": ".multilingual-e5-small-elasticsearch",
"model_settings": {
"service": "elasticsearch",
"task_type": "text_embedding",
"dimensions": 384,
"similarity": "cosine",
"element_type": "float"
},
"chunks": {
"semantic_text": [
{
"start_offset": 0,
"end_offset": 274,
"embeddings": [
0.08915485,
-0.04745302,
-0.017486628,
-0.016316243,
0.047805045,
-0.029047439,
0.01095663,
0.07229844,
0.075959966,
0.0009981694,
0.062287558,
0.02776891,
0.056178022,
-0.0093903905,
(以下省略)
おわり
今回は、ES|QLでの日本語ハイブリッド検索を試す方法について紹介しました。
次回、LLMの力とES|QLをもっと活用して、検索精度を上げていく方法について書いてみたいと考えています。