1.はじめに
- EDINET APIのバージョン2が8/21から使えるようになった。
- (自分の)注目はxbrlデータをcsvデータに変換したデータがとれる!、ということで、このデータを自動で蓄積できるように設定した。
2. 試したもの
- 毎回colaboratoryを使って起動して、、という形も考えたけれど、たぶん忘れるだろう、ということでボツ。
- 次にWorkflowsを使ってうまくやれればいいと思ったけれど、zipファイルの扱いがうまくできず断念。そもそもこれはGoogleCloudの各サービスを組み立てる際に使うものなのでだめだったかも。
#断念したもの
main:
params: [input]
steps:
- downloadzip:
call: http.get
args:
url: 'https://api.edinet-fsa.go.jp/api/v2/documents/****'
query:
Subscription-Key: ***
type: 5
result: wikiResult
#getしたzipファイルをどうすればいいか、わからなくなる。
- returnOutput:
return: "OK"
3. コード
- 結局、CloudSchedulerでCloudFunctionsを呼び出す形に。
- 毎日1回実行して、その日にあった有価証券報告書をGCSにアップロードする、という処理。
- ありがたいことに設定などすごく簡単だった。
@functions_framework.http
def hello_http():
from datetime import date
today = date.today()
#有償系のdocidのもののみリスト化
doc_id_list = make_doc_id_list([today])
tmpdf = pd.DataFrame(doc_id_list)
df = tmpdf.T.rename(columns={0:"doc_id",1:"comname",2:"secCode",3:"desc"})
for FNAME in df["doc_id"].tolist():
url = "https://api.edinet-fsa.go.jp/api/v2/documents/"+ FNAME + "?Subscription-Key=***fec&type=5"
r = requests.get(url)
filename = FNAME + ".zip"
urlretrieve(url, filename)
blob_name = filename
path_to_file = filename
bucket_name = "*****"
upload_to_bucket(blob_name, path_to_file, bucket_name)
return 'OK!'
あとはCloudSchedulerで指定していけばOK
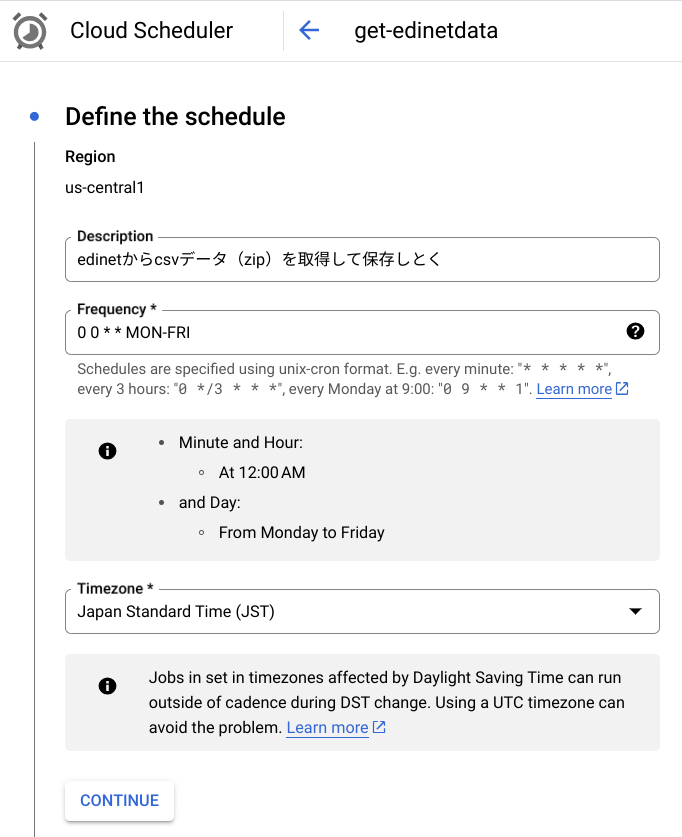
- CloudFunctionsのURLを指定。内部で日付を取得するので、引数はなしでOK.