1. はじめに
- とある S3 オブジェクトがいつ、だれによって削除されたのかを調査する。
- CloudTrail を有効にしていれば、S3オブジェクトレベルのアクセスログが記録される。
- CloudTrail のログは大量かつJSONフォーマットのため、生ログから調査するのは無理がある。
- CloudTrail のログを検索するためには、Amazon Athena を使うと便利。最近は、コンソールからポチポチで Athena に CloudTrail ログのテーブルを作成できる。
- あとは、Athena から さまざまな SQL を投げて調査をすすめる。
【参考】
- AWS CloudTrail User Guide (Version 1.0)を読んで理解を深める
- 【新機能】CloudTrailでS3オブジェクトレベルのアクセスをロギングする
- AWS CloudTrail ログ検索をするために Amazon Athena のテーブルを自動的に作成する方法を教えてください。
2. Amazon Athena に CloudTrail ログ のテーブルを作成する
2.1. デフォルトのテーブルを作成する
設定方法は 公式 を参照

↓
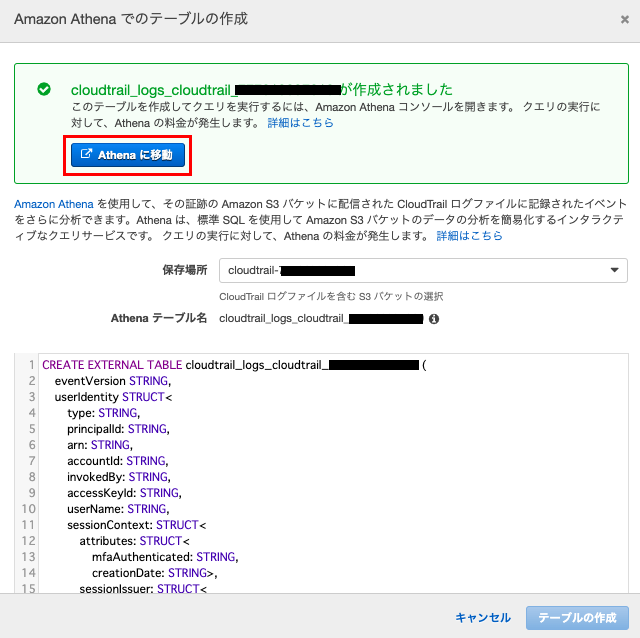
テーブルの作成
↓
↓
「default」 の Database に CloudTrail ログの テーブルが作成された
2.2. デフォルトで作成したテーブルのDDLを確認する
確認方法
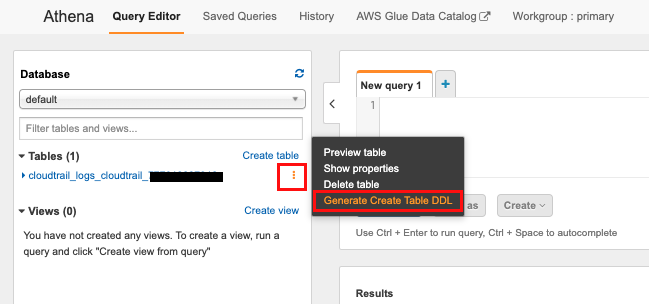
↓
結果にDDLが出力される
CREATE EXTERNAL TABLE `cloudtrail_logs_cloudtrail_************`(
`eventversion` string COMMENT 'from deserializer',
`useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> COMMENT 'from deserializer',
`eventtime` string COMMENT 'from deserializer',
`eventsource` string COMMENT 'from deserializer',
`eventname` string COMMENT 'from deserializer',
`awsregion` string COMMENT 'from deserializer',
`sourceipaddress` string COMMENT 'from deserializer',
`useragent` string COMMENT 'from deserializer',
`errorcode` string COMMENT 'from deserializer',
`errormessage` string COMMENT 'from deserializer',
`requestparameters` string COMMENT 'from deserializer',
`responseelements` string COMMENT 'from deserializer',
`additionaleventdata` string COMMENT 'from deserializer',
`requestid` string COMMENT 'from deserializer',
`eventid` string COMMENT 'from deserializer',
`resources` array<struct<arn:string,accountid:string,type:string>> COMMENT 'from deserializer',
`eventtype` string COMMENT 'from deserializer',
`apiversion` string COMMENT 'from deserializer',
`readonly` string COMMENT 'from deserializer',
`recipientaccountid` string COMMENT 'from deserializer',
`serviceeventdetails` string COMMENT 'from deserializer',
`sharedeventid` string COMMENT 'from deserializer',
`vpcendpointid` string COMMENT 'from deserializer')
COMMENT 'CloudTrail table for cloudtrail-************ bucket'
ROW FORMAT SERDE
'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT
'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://cloudtrailログのバケット/AWSLogs/************/CloudTrail'
TBLPROPERTIES (
'classification'='cloudtrail',
'transient_lastDdlTime'='1586924592')
(「************」は、AWSアカウントID)
デフォルトで作成されるテーブルのS3バケット ロケーション
- 次の通り、全リージョンとなっている。
~
LOCATION
's3://cloudtrail-************/AWSLogs/************/CloudTrail'
~
- CloudTrail を全リージョンで有効にしている場合、デフォルトのロケーション設定では、全リージョンの CloudTrail ログがスキャン対象となっている。

- Athena では、スキャンされたバイト数に対して課金される。また、スキャン対象が多いほど結果に時間がかかる。
- 検索対象を絞れる場合は、ロケーションを指定してテーブルを作成した方がよい。
2.3. S3バケットのロケーションを指定してテーブルを作成する
- 検索対象を、ap-northeast-1 リージョンの 2020年 とする。
- デフォルトで作成されたテーブルの DDL の次の2箇所(テーブル名と、ロケーション)を変更する。
CREATE EXTERNAL TABLE `cloudtrail_ap-northeast-1_2020`(
~
LOCATION
's3://cloudtrailログのバケット/AWSLogs/************/CloudTrail/ap-northeast-1/2020/'
~
- 編集した DDL を実行する
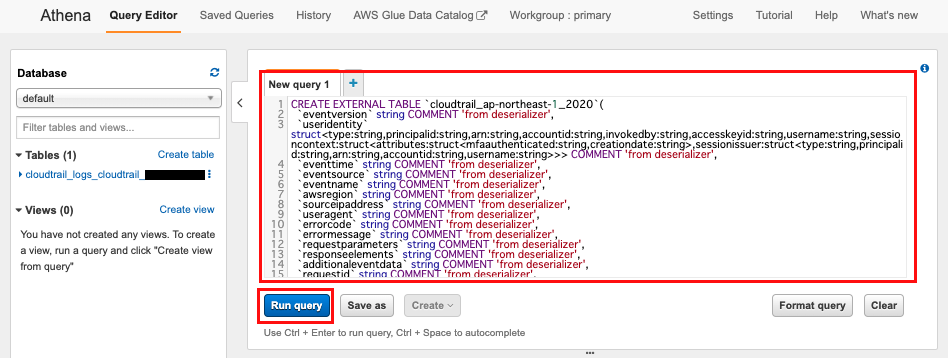
↓
3. Athena テーブルに SQL を投げる際の注意点
配列をフラット化
CloudTrail ログの Athena テーブルに次の配列のフィールドがある。
resources (array<struct<arn:string,accountId:string,type:string>>)
この中の arn が S3オブジェクトの ARN なので、この arn を検索条件にしたいが、この配列のままで SQL を投げるとエラーになるため、CROSS JOIN 演算子を UNNEST 演算子と組み合わせて、配列をフラット化する必要がある。
CROSS JOIN UNNEST(resources) AS t(resource)
【参考】
4. SQL 実行例
4.1. SQL実行例 その1
SQL実行
- S3オブジェクト「foo.png」が削除(DeleteObjectイベント)された日時と、削除したユーザー名を調べる。
- CloudTrail ログバケット「cloudtrail_logs_cloudtrail_************」内のすべてのログが検索対象。
- 結果は 2020-03-01 00:00:00 (UTC) 以降を表示する。
SELECT
eventtime, useridentity.username, eventname, resource.arn
FROM
cloudtrail_logs_cloudtrail_************
CROSS JOIN UNNEST(resources) AS t(resource)
WHERE
resource.arn LIKE '%foo.png%'
AND
eventname = 'DeleteObject'
AND
eventtime >= '2020-03-01T00:00:00Z'
ORDER BY eventtime;
↓
実行結果
※クエリは例。結果は実際のものなので伏せてる

ロケーションを ap-northeast-1 の 2020年に設定した テーブルの場合
- sql
SELECT
eventtime, useridentity.username, eventname, resource.arn
FROM
cloudtrail_ap-northeast-1_2020
CROSS JOIN UNNEST(resources) AS t(resource)
WHERE
resource.arn LIKE '%foo.png%'
AND
eventname = 'DeleteObject'
AND
eventtime >= '2020-03-01T00:00:00Z'
ORDER BY eventtime;
- 結果
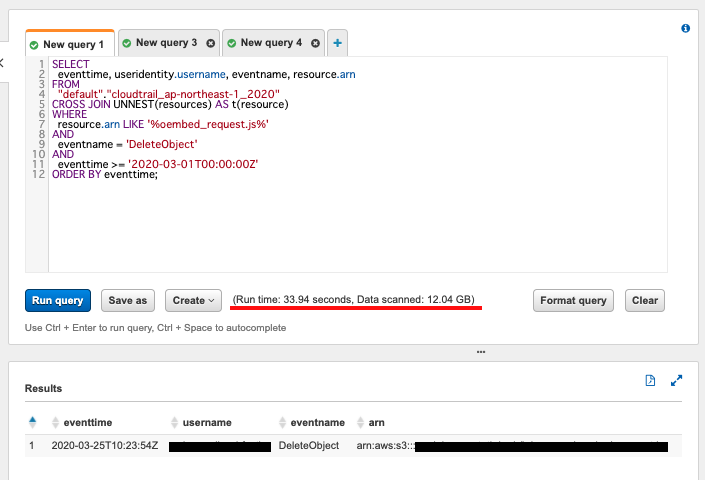
スキャン時間は 2分36秒 から 33.94秒
スキャンされたバイト数は 14.49GB から 12.04GB
スキャン時間が激減した。
4.2. SQL実行例 その2
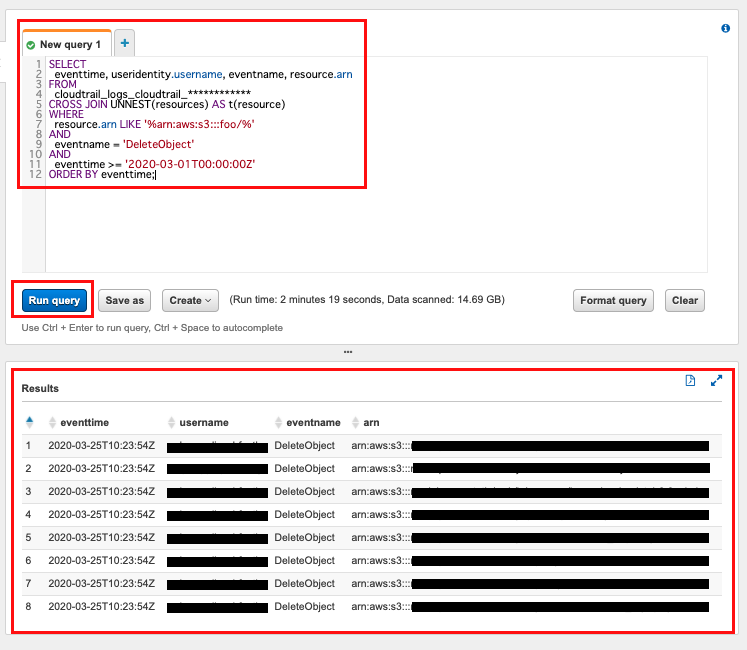
- S3バケット 「foo内のオブジェクトが削除(DeleteObjectイベント)された日時と、削除したユーザー名を調べる。
- CloudTrail ログバケット「cloudtrail_logs_cloudtrail_************」内のすべてのログが検索対象。
- 結果は 2020-03-01 00:00:00 (UTC) 以降を表示する。
SELECT
eventtime, useridentity.username, eventname, resource.arn
FROM
cloudtrail_logs_cloudtrail_************
CROSS JOIN UNNEST(resources) AS t(resource)
WHERE
resource.arn LIKE '%arn:aws:s3:::foo/%'
AND
eventname = 'DeleteObject'
AND
eventtime >= '2020-03-01T00:00:00Z'
ORDER BY eventtime;
↓
実行結果
※クエリは例。結果は実際のものなので伏せてる
5. その他
5.1. Athena の料金
-
Amazon Athena によってスキャンされたバイト数に対して課金される。
-
東京リージョンの場合、スキャンされたデータ 1 TB あたり 5.00USD
-
CloudTrail のログ容量が大きいほど、スキャンに時間がかかるし、Athenaコストもかかる。
(CloudTrailログのバケットは、年単位とかで分けたほうが良いかもしれない。年が変わったら、新しいS3バケットにCloudTrailログを出すように出力設定変するとか。) -
コスト削減方法 その1
-
Athena テーブル作成時にパーティション
分けをすることで、パフォーマンス向上、スキャンするデータ量を制限できる。 -
コスト削減方法 その2
-
CloudTrailログは S3バケットでリージョンと年/月/日でプリフィックス区切りされている。Athenaでテーブル作成時に、S3バケットロケーションで ap-northeast-1 の 2020/04/15 内のログだけをスキャン対象とすることで、スキャンするバイト数を減らすことができる。
CloudTrailログのS3バケット例
【参考】