この記事は2020年03月24日に公開した「Watson Studio上のnotebookからIBM Cloud Object Storage(ICOS)へのFileの読み書き - project-libを使う -」のibm_watson_studio_lib版です。文章も使える部分はそのままにしてます。
5年も経つと製品の名前もライブラリーも変わってしまっていて、最近方法を聞かれたので新しいGUIと新しいライブラリーでの手順を記載します(「新しい」のは2025年1月現在の話ですが)。
ちなみに「Watson Studio」は「wastonx.ai Studio」に名前が2024年11月に変更になりました。
Notebookでコードを書く際、データをファイル経由でロードするのはごく頻繁にあるケースです。ローカルのPC上でjupyter Notebookを動かしている場合は、普通のpythonのお作法で読み書きすれば問題ないですのですが、wastonx.ai Studioのプロジェクトのファイル置き場である「資産」にあるファイルをNotebook上で読み書きする場合は、一般的にはプロジェクトに紐ついたIBM Cloud Object Storage(以下ICOS)に対してファイルの読み書きすることになります。
方法はいくつかあります。ICOSはAWS S3互換のオブジェクトストレージなので、AWS S3と同様の方法も使えます。またwastonx.ai StudioのNotebookの空のコード・セルをクリックし、Notebookのツールバーから 「コード・スニペット」 アイコン (「コード・スニペット」アイコン) をクリックし、 「データの取り込み」 とプロジェクトの資産を選択することで、pandas DataFramesやCredentialsを使ってコード生成する方法もあります。あとはwastonx.ai StudioのNotebook専用となりますが、割と簡単に書けるibm_watson_studio_libを使う方法があります。
ここではこの方法の1つ、ibm_watson_studio_libを使った方法を説明します。
尚ここに書いてある情報はwastonx.ai Studioのドキュメント「ibm-watson-studio-lib (Python 用)」の情報を元にしています。
0. 前提はwastonx.ai Studioのプロジェクトが作成済みであること
前提は既にwastonx.ai Studioのプロジェクトが作成済みであることです。もしまだ作成済みでなく、方法がわからない場合は
を参考にまずプロジェクトを作成してから以下を開始してください。
1. まずはやること
ライブラリーを使う前にやることです!
1-1. プロジェクトを開く
作成済みプロジェクトを開いてください。
方法がわからない場合は
「wastonx.ai Studio サービスとプロジェクトの作成 - 4. プロジェクトの開き方」を参考にして開いてください。
1-2. 前準備「アクセス・トークン」の作成
ibm_watson_studio_libを使うには、関連付けされたICOSを含むプロジェクトの環境にアクセスできるアクセス・トークンを最初に作成しておく必要があります。
これはプロジェクトに対して1つ作成してあればよいです。 ただし権限別に2つ以上作成するのも問題ありません。
1-2-1: 上部メニューから「管理」をクリックし、左側のメニューから「アクセス制御」を選択します・
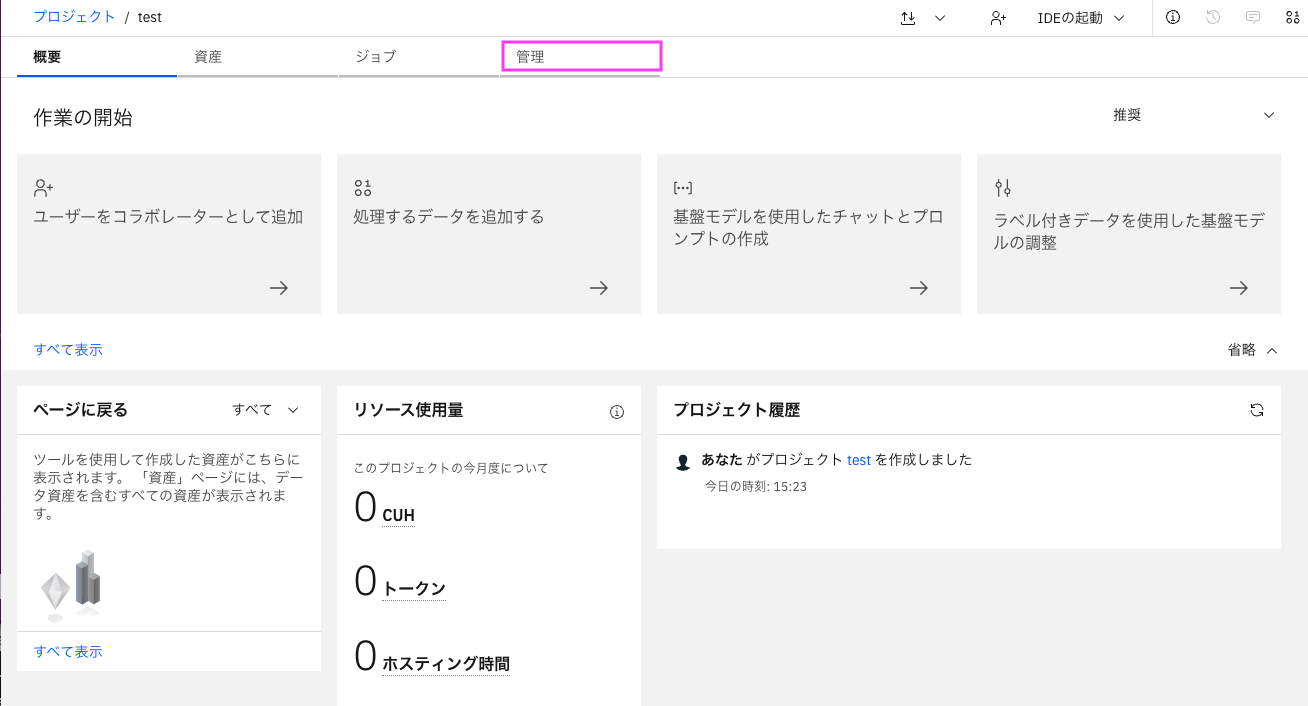

1-2-2: 「アクセス・トークン」のタブをクリックします。右側に表示された「新規トークン+」をクリックします。

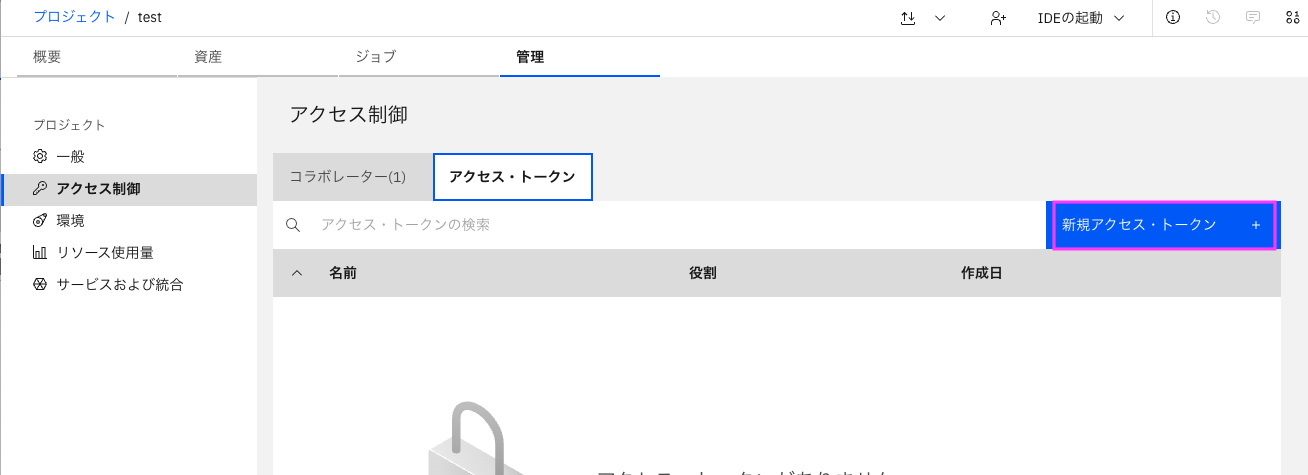
1-2-3: 「新規アクセス・トークン」のウィンドウが表示されますので、「名前」と「アクセス・ロール」を設定し、「作成」をクリックします。
- 名前: 適当にわかりやすい名前(半角で)
- アクセス・ロールの選択: 状況に応じて以下を選択します。
- 読み込みだけの場合は「Viewer」
- 読み込みおよび書き込みもしたい場合は「Editor」
この記事では読み込みおよび書き込み方法を説明しますので、「エディター」を設定した状態に設定しました。
アクセス・トークンの追加
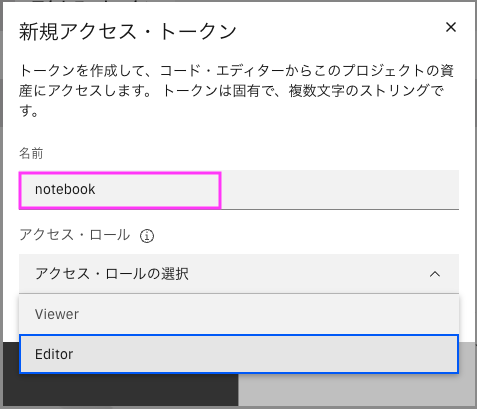

「アクセス・トークン」に設定したトークンが表示されているのを確認します。

これでibm_watson_studio_libを使うNotebook外での準備が完了しました。
1-3. Notebookを開く
既にファイルを読み書きしたいNotebookがあればそれを開いてください。
新たに作ってもよいです。作り方が不明の場合は
watsonx ai Studio notebookの作成・操作を参照して作成してください。
1-4. 読み込ませたいファイルをプロジェクトの「資産」にアップロード
まずは何かしら 読み込ませたいファイルがある場合は、ICOSにまずファイルをアップロードします。書き込むだけなら不要です。
既にアップロード済みの または 読み込みはしない場合は1-5に進んでください。
1-4-1: 右上の[0100]アイコン(プロジェクトへの資産のアップロード)アイコンをクリックします。
尚、Notebookは編集モードでないとこのアイコンはクリックできません。もし編集モードになっていない場合は、「えんびつ」アイコンがあると思いますので、そちらをクリックして編集モードにしてください。
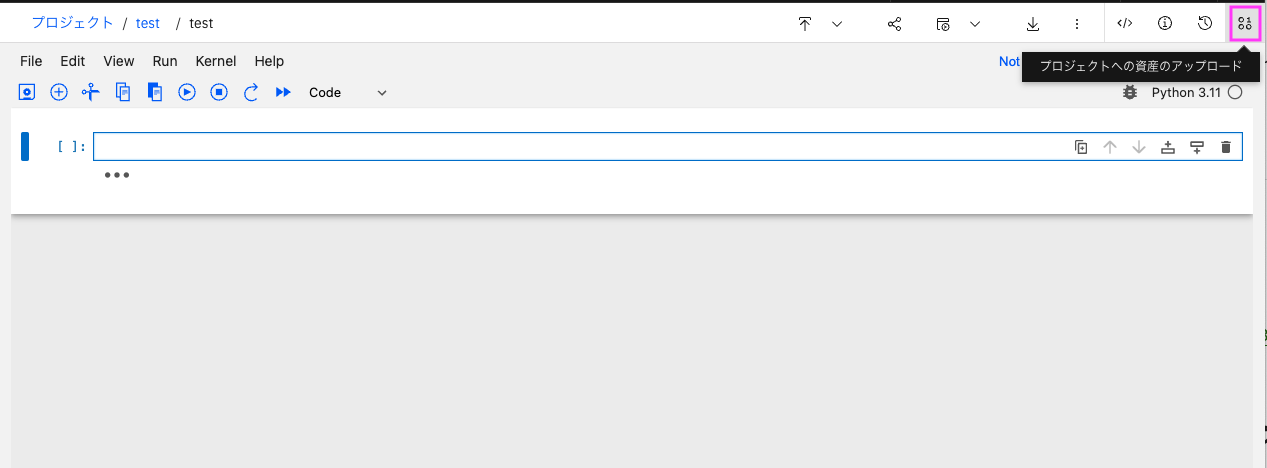
1-4-2: 表示された「ここにデータ・ファイルをドロップするか、アップロードするファイルを参照します」が書いてある四角いエリアに、アップロードしたいファイルをドラッグ&ドロップします
あるいは「ここにデータ・ファイルをドロップするか、アップロードするファイルを参照します」をクリックするとファイルダイアログが表示されますので、そこから選択します。
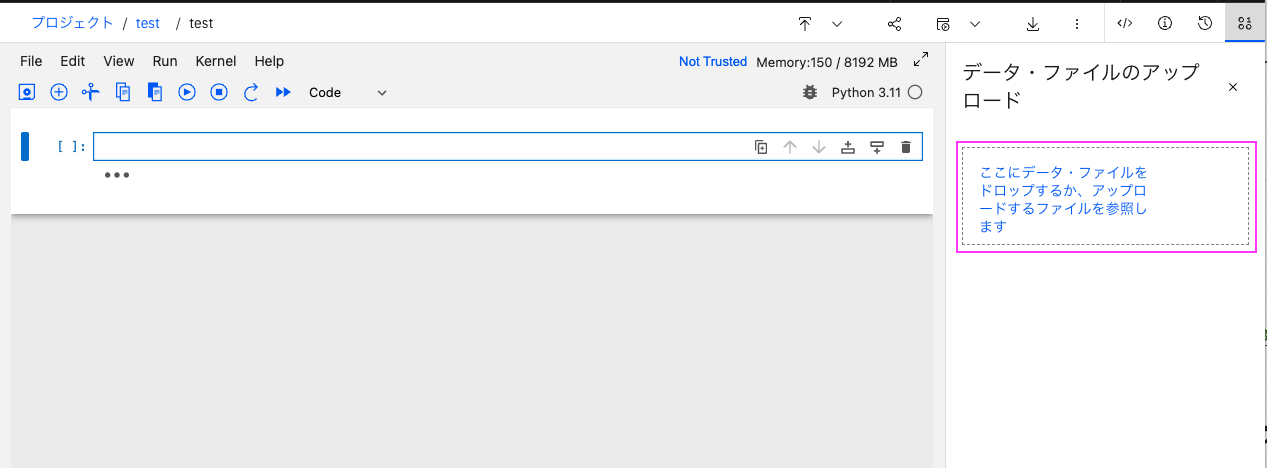
しばらくするとファイルがロードされ、ロードしたファイル名と「アップロードされました!」というメッセージが表示されます。このファイル名とメッセージがしばらくすると消えてしまいます。
1-5: プロジェクト・トークンのnotebookへの挿入
1-5-1: 空のセルを選択します
空のセルがない場合は、作成して選択してください。

1-5-2: 上部メニューの縦の・・・をクリックし、「プロジェクト・トークンの挿入」をクリックします。
2. 前準備「アクセス・トークン」の作成でアクセス・トークンを作成してないと、このメニューは表示されないので、もし表示されてない場合は、2. 前準備「アクセス・トークン」の作成を実施しているか確認してください。

選択していた空のセルにhidden_cellとしてws-libを使うためのライブラリを読み込み、設定したtokenを使用した必要なコードが書かれたコード挿入されます。
尚、以前のproject-libを使うためのコードも上部に挿入されるのですが、こちらは使いません。

1-5-3: セルをクリックして以下のいずれかの方法で実行をします。
- [Shift] + [Enter] を入力
- Windows: Ctrl + Enter
- Mac: ⌘ (command) + Enter または Ctrl + Enter
- 上のメニューから
▶︎ボタンをクリック
実行が完了すると以下の部分に数字が入ります。

これでnotebookの準備は完了です。この作業はnotebook毎に1回必要です。
2. ibm_watson_studio_libを使ってファイルの読み書き
もろもろの準備ができたのでibm_watson_studio_libを使ってみましょう!
では早速notebook上でProjectの資産のファイルを読み書きしてみましょう。1-5で挿入されたセルは実行済みの前提です。
2-1: Projectの資産 <-> notebook ランタイムのファイル・システム間のファイルのコピー
よく本などに載っているサンプルコードでファイルを扱うものは、localのストレージ直で読み書きするものです。notebookの場合、notebookを編集状態にするたびにランタイムが立ち上がりますので、そのファイル・システム領域にファイルをコピーしておけば、localのストレージにあるのと同じですので、サンプルコードはそのまま使えます。逆にサンプルコードで保存した場合は、ランタイムのファイル・システム領域にコピーされてますので、notebookを閉じる前に、 Projectの資産にコピーしておけば、notebookを閉じてもファイルは保存され、ダウンロードも可能です。
2-1-1: プロジェクトの資産からランタイムのファイル・システムへのコピー
データの取り出し より抜粋
-
download_file(asset_name_or_item, file_name=None, attachment_type_or_item=None)
-
このファイルが既に存在している場合は、上書きされます。
-
asset_name_or_item: (必須) 保管されているデータ資産の名前 -
file_name: (オプション) ダウンロードされたデータが保管されるファイルの名前。 デフォルトでは、資産のファイル名になります。 -
attachment_type_or_item: (オプション) ダウンロードするファイルのタイプ。 このパラメーターを指定しない場合、デフォルトの添付ファイル・タイプ ( data_asset ) がダウンロードされます。 添付ファイル・タイプが data_assetでない場合は、このパラメーターを指定します。 例えば、プレーン・テキスト・データ資産に自然言語分析のプロファイルが添付されている場合、これは添付ファイル・タイプ data_profile_nluとしてダウンロードできます。
-
コードの例:
資産にある「地方自治体コード.csv」をコピーします。
filename="地方自治体コード.csv"
wslib.download_file(filename)
上記を実行した時の出力:
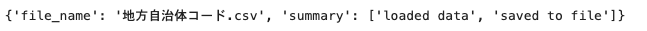
コピーができたかどうかは以下のコマンドをセルで実行すれば確認できます。!を先頭につけるとランタイムのOSコマンド(Linuxコマンド)が実行できます。
!ls -l
実行例:

2-1-2: ランタイムのファイル・システムからプロジェクトの資産へのコピー
データの取り出し より抜粋
-
upload_file(file_path, asset_name=None, file_name=None, overwrite=False, mime_type=None)
-
この関数は、ランタイムのファイル・システム内のデータを、プロジェクトに関連付けられたファイルに保存します。
-
file_path: (必須) ファイル・システム内のファイルへのパス。 -
asset_name: (オプション) 作成されるデータ・アセットの名前。 デフォルトでは、アップロードするファイルの名前になります。
-
このファイル名asset_nameはなぜか英数字と半角スペース、アンダースコア、ピリオドのみしか使用できません。オリジナルファイル名に日本語や半角スペース、アンダースコア、ピリオド以外の記号が含まれている場合は、このパラメーターで別のファイル名を指定してください。
-
-
file_name: (オプション) プロジェクトに関連付けられたストレージ内に作成されるファイルの名前。 デフォルトでは、アップロードするファイルの名前になります。- 「デフォルトでは、アップロードするファイルの名前」で、ここも
asset_nameと同じValidationが走るので、オリジナルファイル名に日本語や半角スペース、アンダースコア、ピリオド以外の記号が含まれている場合は、このパラメーターで別のファイル名(asset_nameと同じでよい)を指定してください。
- 「デフォルトでは、アップロードするファイルの名前」で、ここも
-
overwrite: (オプション) ストレージ内の既存のファイルを上書きします。 デフォルトは false です。 -
mime_type: (オプション) 作成されたアセットの MIME タイプ。 デフォルトでは、MIME タイプはアセット名の接尾部から決定されます。 接尾部なしで資産名を使用する場合は、ここで MIME タイプを指定します。 例えば、プレーン・テキスト・データの場合は mime_type='application/text' です。 アセットを上書きする場合、このパラメーターは無視されます。
-
では上記でランタイムのファイル・システム上にコピーしたファイルをプロジェクトの資産にコピーしてみます。
コピーするファイル名にはライブラリーibm_watson_studio_libの制限で日本語はNGなのでcopy_citycode.csvとしています。
ランタイムのファイル・システムにファイルがあるのを念の為確認:
!ls -l
実行例:

ファイルが動作ディレクトリにあるのが確認できます。
では、このファイル地方自治体コード.csvをプロジェクトの資産copy_citycode.csvとしてコピーしてみましょう。
もし、既存で同じ名前のファイルを上書きしていい場合はoverwrite=Trueのパラメーターも追加しておきます。
src_filename="地方自治体コード.csv"
target_filename="copy_citycode.csv"
wslib.upload_file(src_filename,asset_name=target_filename, file_name=target_filename)
# 既存で同じ名前のファイルを上書してもよい場合 overwrite=True を追加
# wslib.upload_file(src_filename,asset_name=target_filename, file_name=target_filename, overwrite=True)
ちなみに元ファイル名が「英数字と半角スペース、アンダースコア、ピリオドのみ」で、資産に同じファイル名がなければ、パラメーターはオリジナルファイル名のみを指定すればOKです。
# 元ファイル名が「英数字と半角スペース、アンダースコア、ピリオドのみ」で、
# 資産に同じファイル名がない場合の例
src_filename="filename.csv"
wslib.upload_file(src_filename)
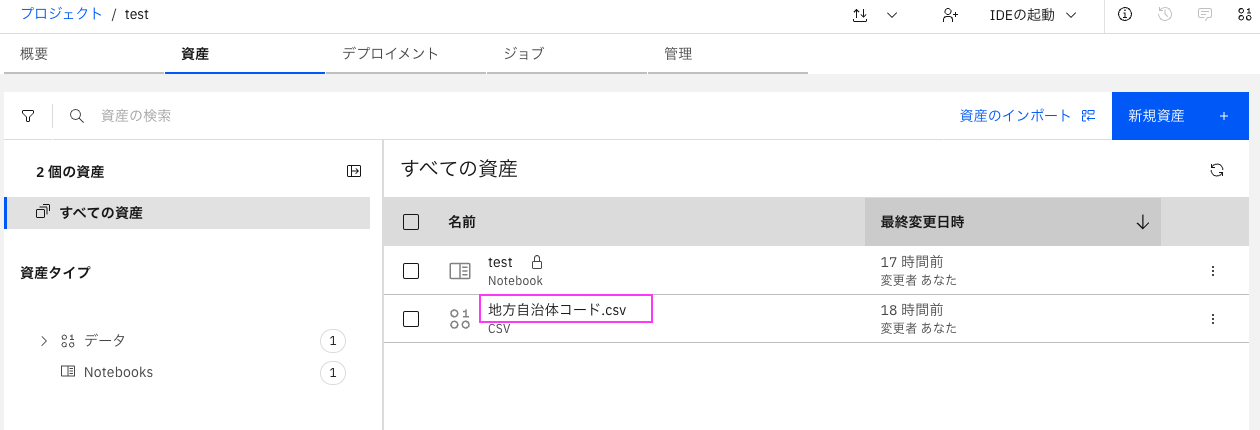
確認はプロジェクトの「資産」タブで行います。
「1.保存」して「2.Project名を右クリック」し、「新しいタブで開く」(ブラウザーによって多少表現に違いがあります)をクリックし、別タブでプロジェクトの画面を開きます。
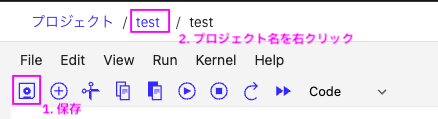
↓

資産タブの全ての資産にコピーしたファイルが表示されているはずです:

2-2: ランタイムのファイル・システム上のファイルを経由せず資産を直接読み書きする方法
サンプルをそのまま使うとかでなければ、わざわざランタイムのファイル・システム上のファイルを経由しなくてもメモリ上で直接処理が可能です。
2-2-1: pandasのDataFrameにプロジェクトの資産から読み込む
データの取り出し より抜粋
-
load_data(asset_name_or_item, attachment_type_or_item=None)
-
この関数は、保管されたデータ資産のデータを BytesIO バッファーにロードします。 この機能は、非常に大きなファイルの場合は推奨されません。
-
asset_name_or_item: (必須) 保管されているデータ資産の名前を含むストリング、または list_stored_data()によって返されるような項目。 -
attachment_type_or_item: (オプション) ロードする添付ファイルのタイプ。 データ資産には、データを含む複数の添付ファイルを含めることができます。 このパラメーターを指定しない場合、デフォルトの接続タイプ、つまり data_asset がロードされます。 添付ファイル・タイプが data_assetでない場合は、このパラメーターを指定します。 例えば、プレーン・テキスト・データ資産に自然言語分析からのプロファイルが添付されている場合、これは添付ファイル・タイプ data_profile_nluとしてロードできます。
-
では、プロジェクトの資産にある地方自治体コード.csvをpandasのDataFrameとして読み込んでみます。
src_filename="地方自治体コード.csv"
my_file = wslib.load_data(src_filename)
my_file.seek(0)
import pandas as pd
df =pd.read_csv(my_file)
df
実行例:

2-2-2: pandasのDataFrameから資産へCSV形式で保存
データの保存 から抜粋
-
save_data(asset_name_or_item, data, overwrite=None, mime_type=None, file_name=None)
- この関数は、メモリー内のデータをプロジェクト・ストレージに保存します。
-
asset_name_or_item: (必須) list_stored_data()によって返される作成済みの資産またはリスト項目の名前。 既存のファイルを上書きする場合は、この項目を使用できます。- 資産に表示される名前です
このファイル名asset_name_or_itemはなぜか英数字と半角スペース、アンダースコア、ピリオドのみしか使用できません。日本語不可です。
-
-
data: (必須) アップロードするデータ。 これは、タイプ bytes-like-objectの任意のオブジェクト (例えば、バイト・バッファー) にすることができます。 -
overwrite: (オプション) 保管データ資産のデータが既に存在する場合は、そのデータを上書きします。 デフォルトでは、これは false に設定されています。 名前の代わりにアセット・アイテムが渡された場合の動作は、アセットを上書きすることです。 -
mime_type: (オプション) 作成されたアセットの MIME タイプ。 デフォルトでは、MIME タイプはアセット名の接尾部から決定されます。 接尾部なしで資産名を使用する場合は、ここで MIME タイプを指定します。 例えば、プレーン・テキスト・データの場合は mime_type=application/text です。 アセットを上書きする場合、このパラメーターは無視されます。 -
file_name: (オプション) プロジェクト・ストレージで使用されるファイル名。 データは、プロジェクトに関連付けられたストレージに保存されます。 新規アセットの作成時に、ファイル名はアセット名から派生しますが、異なる場合があります。 ファイルに直接アクセスする場合は、ファイル名を指定できます。 アセットを上書きする場合、このパラメーターは無視されます。
-
2-2-1で読み込んだDataFrame, dfをcopy_citycode2.csvという名前でプロジェクトの資産に保存します。
target_filename="copy_citycode2.csv"
wslib.save_data(target_filename, df.to_csv(index=False).encode())
# 既存の同じ名前のファイルを上書してもよい場合 overwrite=True を追加
# wslib.save_data(target_filename, df.to_csv(index=False).encode(),overwrite=True)
確認方法はランタイムのファイル・システムからプロジェクトの資産へのコピーと同じです。
2-2-3: プロジェクト資産にあるテキストファイルのStringへの読み込み
直接メモリ上のString の変数にテキストファイルを読み込んでみましょう。
2-2-1で使用したload_dataを使います。
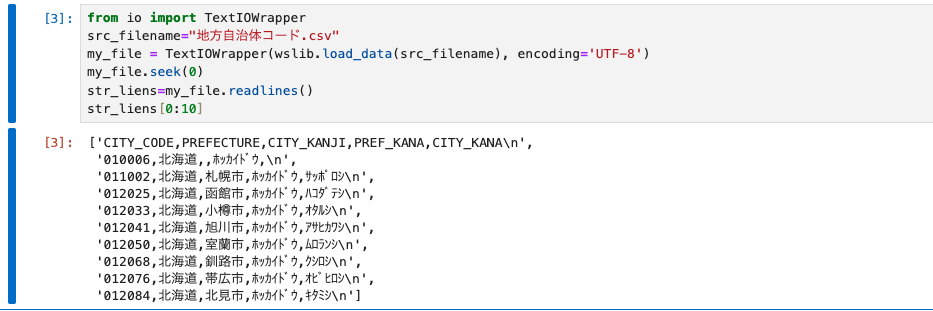
では、プロジェクトの資産にある地方自治体コード.csvをStringの配列に一行つづして読み込んでみます。
from io import TextIOWrapper
src_filename="地方自治体コード.csv"
my_file = TextIOWrapper(wslib.load_data(src_filename), encoding='UTF-8')
my_file.seek(0)
str_liens=my_file.readlines()
str_liens[0:10]
実行例:
文字コードがShift-JISの場合はencodingに'sjis'を指定します:
from io import TextIOWrapper
src_filename="202311_02_02202060_SJIS.csv"
my_file = TextIOWrapper(wslib.load_data(src_filename), encoding='sjis')
my_file.seek(0)
str_liens=my_file.readlines()
str_liens[0:10]
実行例:

2-2-4: String変数からプロジェクト資産にテキストファイルとして書き込む
直接メモリ上のString の変数からプロジェクト資産にテキストファイルとして書き込んでみましょう。
2-2-2で使用したsave_dataを使います。
では、2-2-4で読むこませたStringの配列をプロジェクト資産にstring_city_code.txtとして書き込んでみましょう。
target_filename='string_city_code.txt'
wslib.save_data(target_filename, "".join(str_liens).encode())
確認方法はランタイムのファイル・システムからプロジェクトの資産へのコピーと同じです。
2-2-5: プロジェクト資産にある画像ファイルの表示
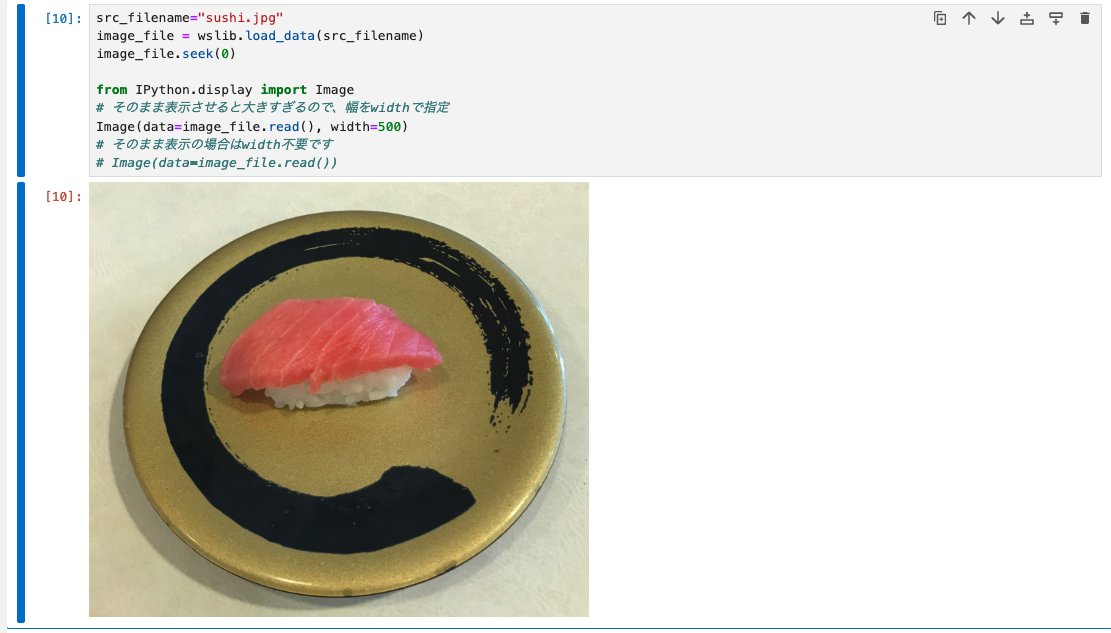
sushi.jpgという画像ファイルがプロジェクトの資産にアップロードされているとします。以下のコードでnotebook上に表示できます。
src_filename="sushi.jpg"
image_file = wslib.load_data(src_filename)
image_file.seek(0)
from IPython.display import Image
# そのまま表示させると大きすぎるので、幅をwidthで指定
Image(data=image_file.read(), width=500)
# そのまま表示の場合はwidth不要です
# Image(data=image_file.read())
実行例:
以上です。
7. まとめ
いかがでしたか? 最初に設定が必要ですが、一度設定すれば以外に簡単にコードが書けたと思います。
wastonx.ai Studioのドキュメント「ibm-watson-studio-lib (Python 用)」には他にも資産情報の一覧を出したり、いろいろな使い方が載っていますので、これを参考に他にもいろいろお試しいただければと思います。