Notebookでコードを書く際、データをファイル経由でロードするのはごく頻繁にあるケースです。ローカルのPC上でjupyter Notebookを動かしている場合は、普通のpythonのお作法で読み書きすれば問題ないですのですが、Watson StudioのNotebook上では恒久的にファイルを読み書きする場合は、一般的にはProjectに紐ついたIBM Cloud Object Storage(以下ICOS)に対してファイルの読み書きをします。
方法はいくつかあります。ICOSはAWS S3互換のオブジェクトストレージなので、AWS S3と同様の方法も使えます。またWatson StudioのNotebookのGUIからInsert pandas DataFramesやInsert StreamingBody objectを使ってコード生成する方法もあります。あとはWatson StudioのNotebook専用となりますが、割と簡単に書けるproject-libを使う方法があります。
ここではこの方法の1つ、project-libを使った方法を説明します。その他の方法は結構Qiita内でも記事になっていますので、容易に見つかると思います。
また、ICOSを使用しない別の方法としてlinuxのコマンドを直接Notebookから実行する方法もあります。他のサーバーかファイルをwget取得、他のサーバーへwputでファイルを保存する方法もあります。こちらはファイルをwget/wputできるサーバーがあることが前提となりますので、ここでは説明しません。
尚ここに書いてある情報はWatson Studioのドキュメント「Using project-lib for Python」の情報を元にしています。
[2022/02/23 Watson Studio新画面に一部更新]
0. 前提はWatson StudioのProjectが作成済みであること
前提は既にWatson StudioのProjectが作成済みであることです。もしまだ作成済みでなく、方法がわからない場合は
を参考にまずプロジェクトを作成してから以下を開始してください。
1. Projectを開く
作成済みProjectを開いてください。
方法がわからない場合は
[ログイン後、作成済Projectの表示方法]
(https://qiita.com/nishikyon/items/ba698b638300848b746e#4-%E3%81%8A%E3%81%BE%E3%81%91%E3%83%AD%E3%82%B0%E3%82%A4%E3%83%B3%E5%BE%8C%E4%BD%9C%E6%88%90%E6%B8%88project%E3%81%AE%E8%A1%A8%E7%A4%BA%E6%96%B9%E6%B3%95)を参考にして開いてください。
2. 前準備アクセス・トークンの作成
project-libを使うには、関連付けされたICOSを含むプロジェクトの環境にアクセスできるアクセス・トークンを最初に作成しておく必要があります。
これは一度プロジェクトに対して作成してあればよいです。
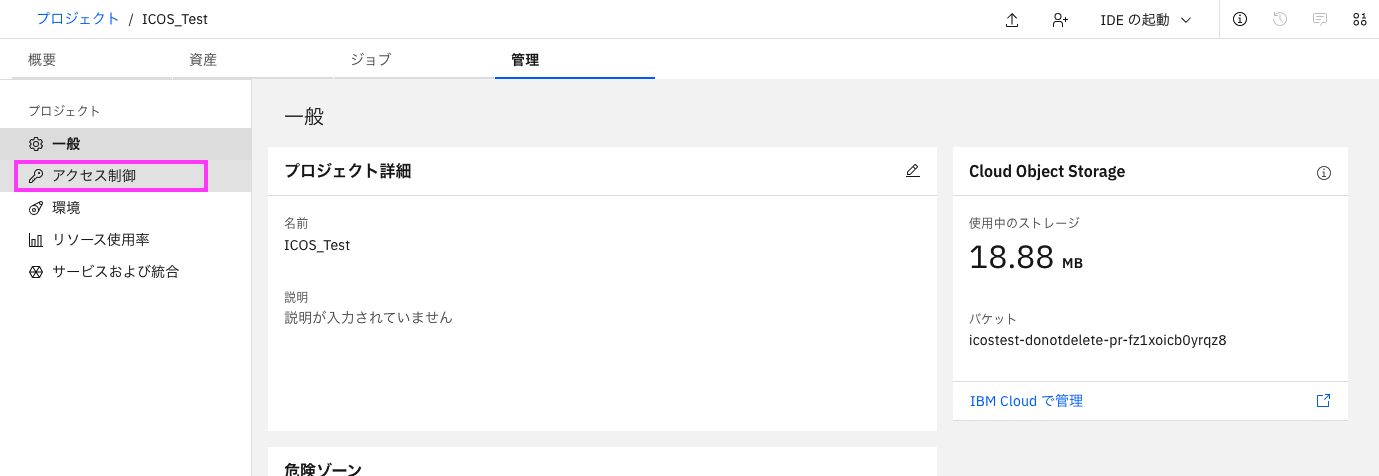
2-1: 上部メニューから「管理」をクリックし、左側のメニューから「アクセス制御」を選択します・
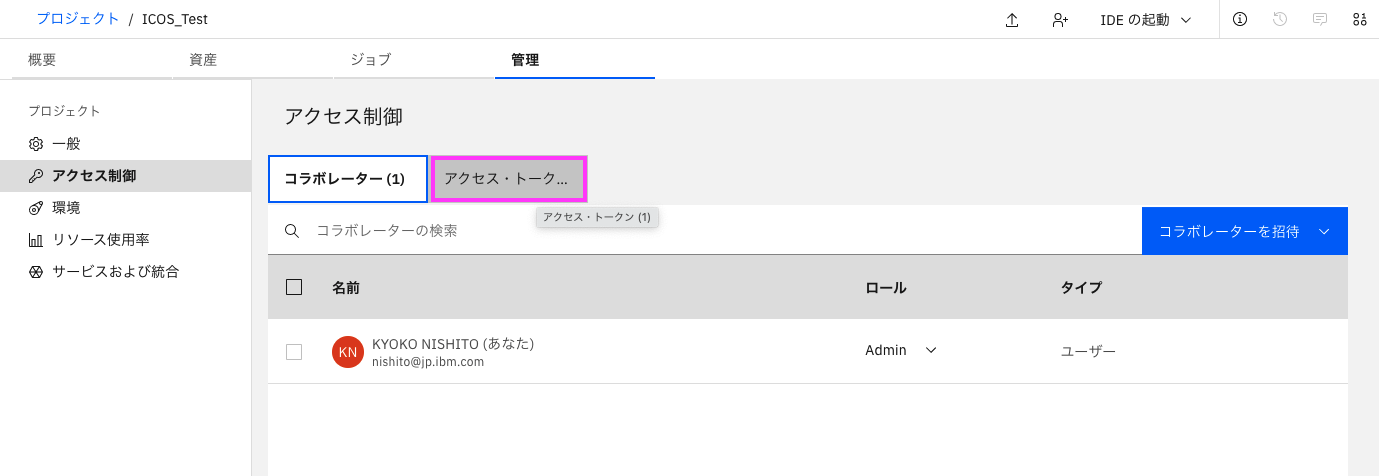
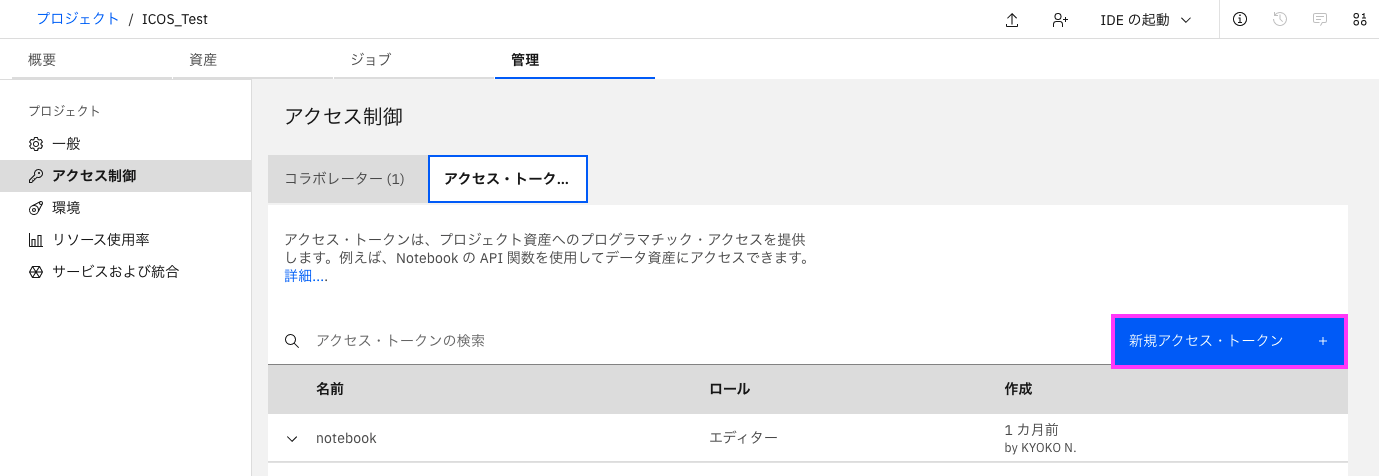
2-2: 「アクセス・トークン」のタブをクリックします。右側に表示された「新規トークン+」をクリックします。
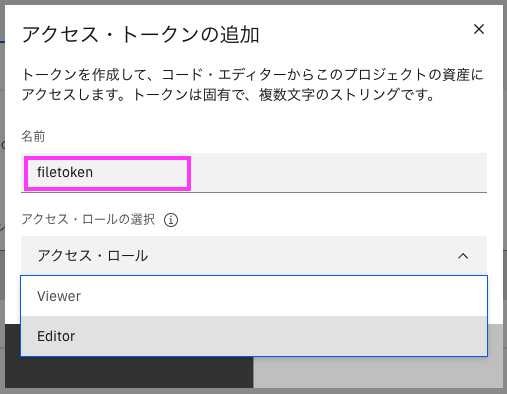
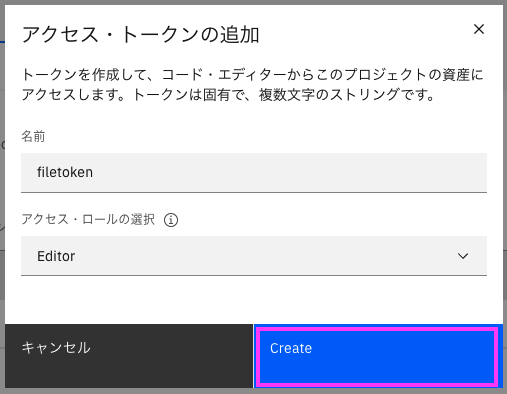
2-3: 「アクセス・トークンの追加」のウィンドウが表示されますので、「名前」と「アクセス・ロール」を設定し、「作成」または「Create」をクリックします。
- 名前: 適当にわかりやすい名前(半角で)
- アクセス・ロールの選択: 状況に応じて以下を選択します。
- 読み込みだけの場合は「ビューアー」または「Viewer」
- 読み込みおよび書き込みもしたい場合は「エディター」または「Editor」
この記事では読み込みおよび書き込み方法を説明しますので、「エディター」を設定した状態に設定しました。
アクセス・トークンの追加
「アクセス・トークン」に設定したトークンが表示されているのを確認します。
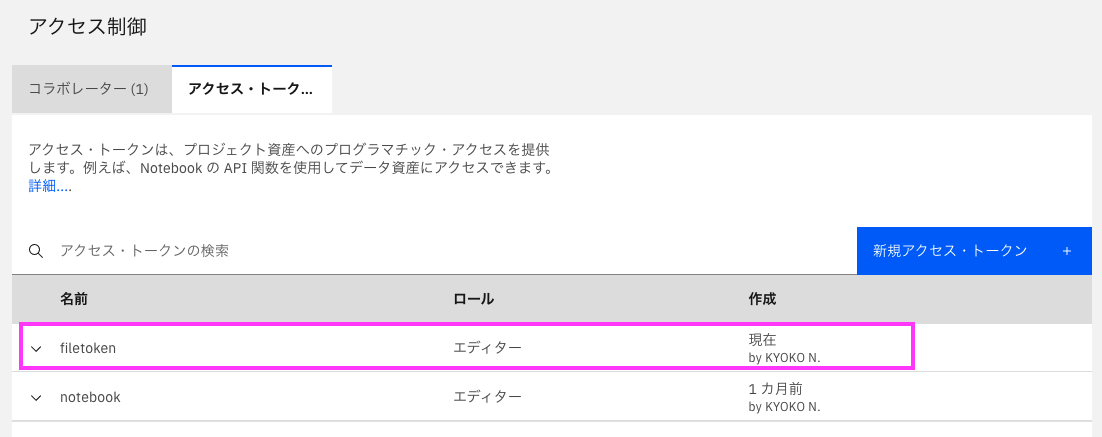
これでproject-libを使うNotebook外での準備が完了しました。
3: Notebookを開く
既にファイルを読み書きしたいNotebookがあればそれを開いてください。
新たに作ってもよいです。作り方が不明の場合は
Watson StudioでJupyter Notebookを使おう! -3. Notebookの作成-を参照して作成してください。
4: 読み込ませたいファイルをICOSにアップロード
最初にも説明しましたが、Watson StudioのNotebook上では恒久的にファイルを読み書きする場合は、一般的にはProjectに紐ついたIBM Cloud Object Storage(以下ICOS)に対してファイルの読み書きをします。 よって何かしらローカル環境(PC)にファイルがある場合は、ICOSにまずファイルをアップロードします。
既にアップロード済みの場合は5に進んでください。
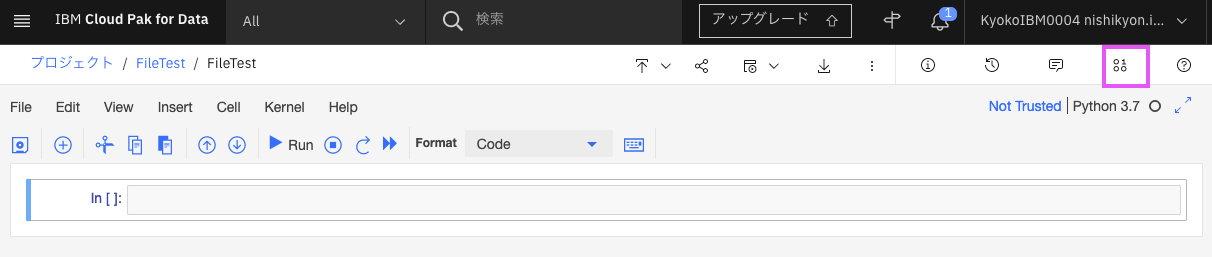
4-1: 右上の[0100]アイコン(File and Add Data)アイコンをクリックします。
尚、Notebookは編集モードでないとこのアイコンはクリックできません。もし編集モードになっていない場合は、「えんびつ」アイコンがあると思いますので、そちらをクリックして編集モードにしてください。
4-2: 表示された「ここにファイルをドラッグ・アンド・ドロップするか、アップロードしてください。」が書いてある四角いエリアに、アップロードしたいファイルをドラッグ&ドロップします。あるいは「ここにファイルをドラッグ・アンド・ドロップするか、アップロードしてください。」をクリックするとファイルダイアログが表示されますので、そこから選択します。
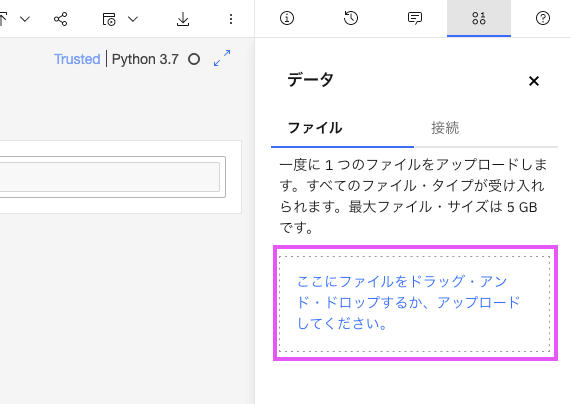
しばらくするとファイルがロードされ、ロードしたファイル名が下に表示されます。
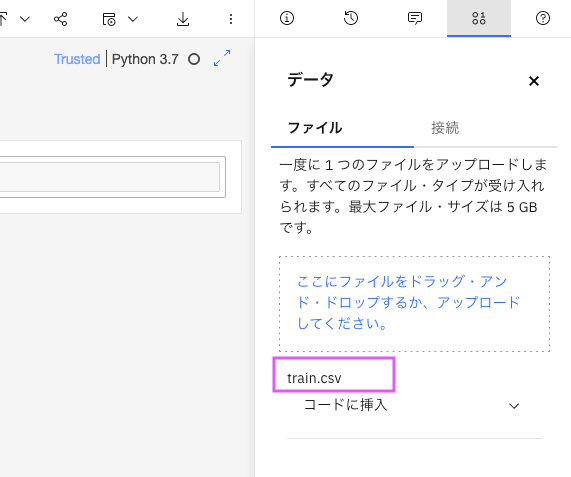
5: プロジェクト・トークンの挿入
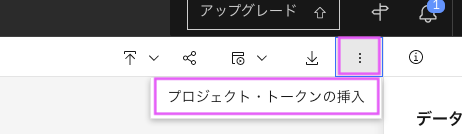
5-1: 上部メニューの縦の・・・をクリックし、「プロジェクト・トークンの挿入」をクリックします。
#2. 前準備 アクセス・トークンの作成でアクセス・トークンを作成してないと、このメニューは表示されないので、もし表示されてない場合は、#2. 前準備 アクセス・トークンの作成を実施しているか確認してください。
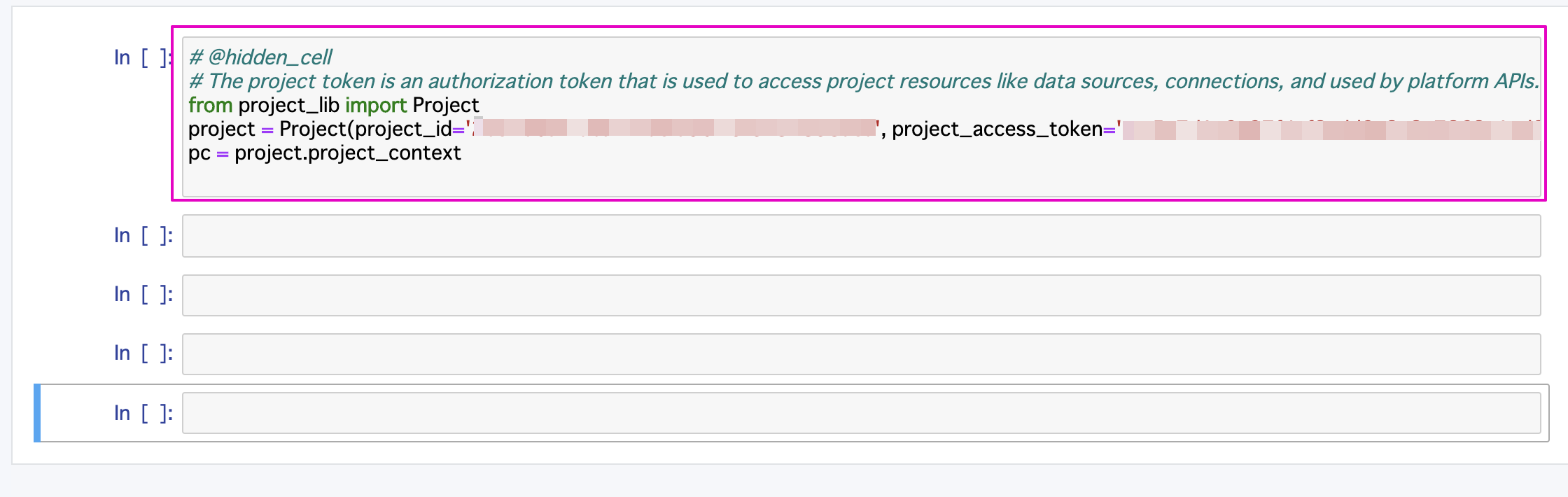
一番上のセルにhidden_cellとしてproject-libを使うためのライブラリを読み込み、設定したProject tokenを使用して必要なコードが書かれたセルが挿入されます。
notebookの下の方で作業していたとしても、必ず一番上のセルに挿入されるので、見当たらない場合は一番上のセルまでスクロールしてください。
5-2: セルをクリックして以下のいずれかの方法で実行をします。
- [Shift] + [Enter] を入力
- 上のメニューから
▶︎Runボタンをクリック

実行が完了すると以下の部分に数字が入ります。
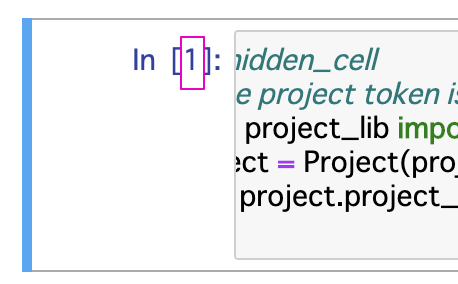
これでnotebookの準備は完了です。この作業はnotebook毎に1回必要です。
6: ファイル読み書き方法
では早速notebook上でProjectのICOS経由ファイルを読み書きしてみましょう。#5で挿入されたセルは実行済みの前提です。
6.1: ICOS <-> notebook VM間のファイルのコピー
よく本などに載っているサンプルコードでファイルを扱うものは、localのストレージ直で読み書きするものです。notebookの場合、notebookを編集状態にするたびにVMが立ち上がりますので、その領域にファイルをコピーしておけば、localのストレージにあるのと同じですので、サンプルコードはそのまま使えます。逆にサンプルコードで保存した場合は、VM領域にコピーされてますので、notebookを閉じる前に、ICOSにコピーしておけば、notebookを閉じてもファイルは保存され、ダウンロードも可能です。
ICOSからVMへのコピー
# Copy a file in project ICOS to VM
csv_file_name = 'train.csv'
csv_file = project.get_file(csv_file_name)
csv_file.seek(0)
with open(csv_file_name,'wb') as out:
out.write(csv_file.read())
コピーができたかどうかは以下のコマンドをセルで実行すれば確認できます。!を先頭につけるとVMのOSコマンド(Linuxコマンド)が実行できます。
!ls -la
実行例:

VMからICOSへのコピー
上記でVM上にコピーしたファイルをICOSにコピーします。コピーしたファイル名はcopy_train.csvとしています。
# Copy a file in VM to project ICOS
with open('train.csv','rb') as f:
project.save_data('copy_train.csv', f, overwrite=True)
確認は一旦notebookを閉じて行います。「1.Save」して「2.Project名をクリックして」notebookを閉じてください。Projectの画面が開きます。
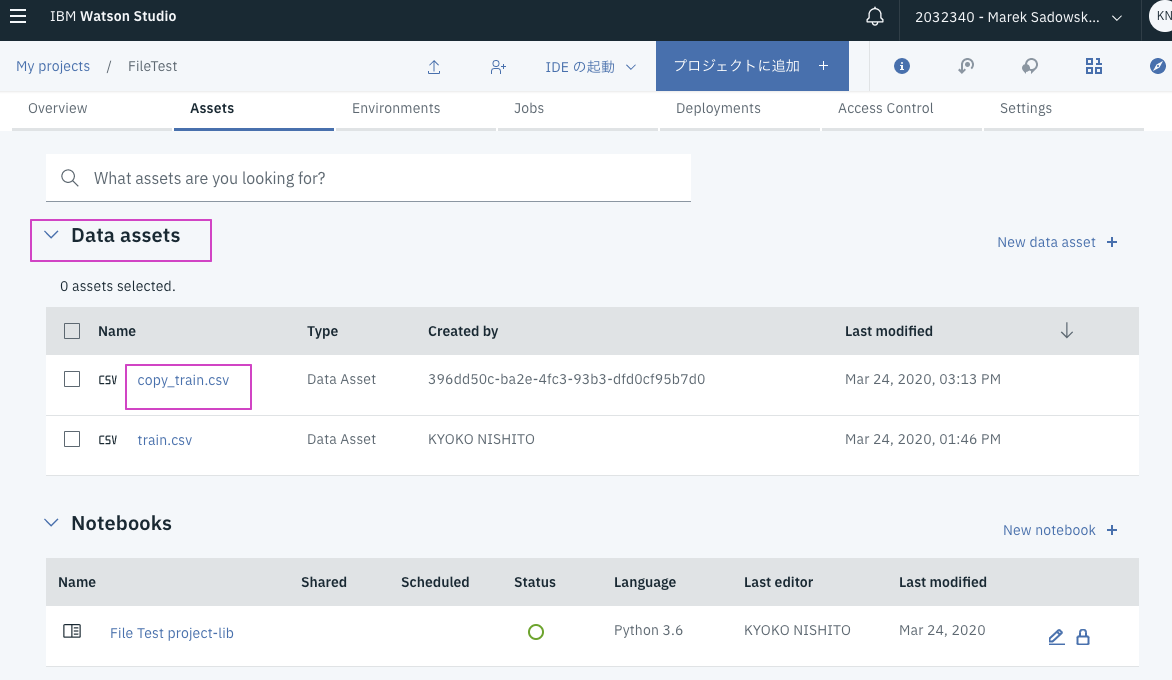
AssetsタブのData assetsの下にコピーしたファイルがあります:
以下はその他直接読み書きする方法です。
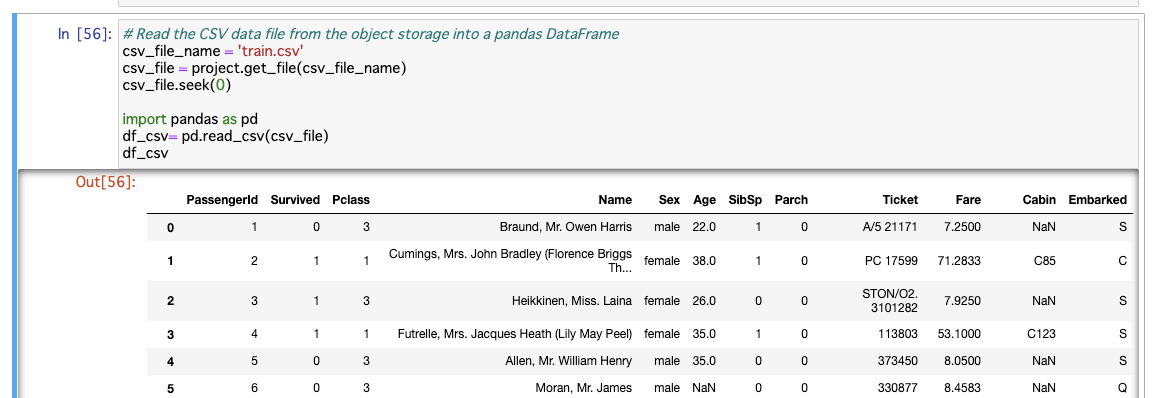
pandasのDataFrameにICOSから読み込む
csv_file_name = 'train.csv'
csv_file = project.get_file(csv_file_name)
csv_file.seek(0)
import pandas as pd
df_csv= pd.read_csv(csv_file)
df_csv
実行例:
pandasのDataFrameからICOSにCSV保存
上記で読み込んだDataFrame, df_csvをcopy_train.csvという名前でICOSに保存します。
project.save_data("copy_train.csv", df_csv.to_csv(index=False), overwrite=True)
確認方法はVMからICOSへのコピーと同じです。
VisualRecognition のAPIのパラメーターとして渡す
イメージファイルをICOSにアップロードしておいて、それをWatsonのVisial Recognitionの認識ファイルとして渡すサンプルです。sushi.jpgファイルがprojectのICOSにアップロードされているとします。
下記の2つはVisualRecognition のsdkを使う前準備です。
!pip install --upgrade "ibm-watson>=4.0.1,< 5.0"
XXXXXXXXXXXXXXには使用するVisual RecognitionのAPIKEYを入れてください。
# Visual Recognition
API_KEY='XXXXXXXXXXXXXX' #replace XXXXXXXXXXXXXX to your APIKEY
from ibm_watson import VisualRecognitionV3
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
authenticator = IAMAuthenticator(API_KEY)
visual_recognition = VisualRecognitionV3(
version='2018-03-19',
authenticator=authenticator
)
以下がproject-libを使ったサンプルコードです:
import json
image_file = project.get_file("sushi.jpg")
image_file.seek(0)
classes = visual_recognition.classify(
images_file=image_file,
images_filename='sushi.jpg',
threshold='0.6',
accept_language='ja').get_result()
# 結果確認
print(json.dumps(classes, indent=2, ensure_ascii=False))
ICOSの画像表示
sushi.jpgという画像ファイルがprojectのICOSにアップロードされているとします。以下のコードでnotebook上に表示できます。
# Image
image_file = project.get_file("sushi.jpg")
image_file.seek(0)
from IPython.display import Image
Image(data=image_file.read())
以上です。
7: まとめ
いかがでしたか? 最初に設定が必要ですが、一度設定すれば以外に簡単にコードが書けたと思います。project.get_file()で戻ってくるのはio.BytesIOなのでいろいろ書けると思いますので、Watson Studioのドキュメント「Using project-lib for Python」の情報を参考に他にもいろいろお試しいただければと思います。