watsonx.dataのHiveテーブルはオブジェクトストレージ上のcsvやParquetファイルなどを使用してテーブル作成が可能で、明示的なLOADなしでデータをテーブルに取り込むことができます。またwatsonx.dataではHiveテーブルからIcebergテーブルを作成することも可能です。
当記事ではwatsonx.data(SaaS版)で、Prestoエンジンと関連付けされたIBM Object Storage(ICOS)上にあるParquetファイルを使用してテーブル作成し、 その後HiveテーブルからIcebergテーブルを作成してみます。
2024/09/06: ファイルを置くオブジェクトストレージはHiveカタログと関連付けされたICOS上に限らず、Prestoエンジンと関連付けがされているICOSであればどこでもよいことがわかったので、修正しました。
前提
1. Hiveカタログ作成済み
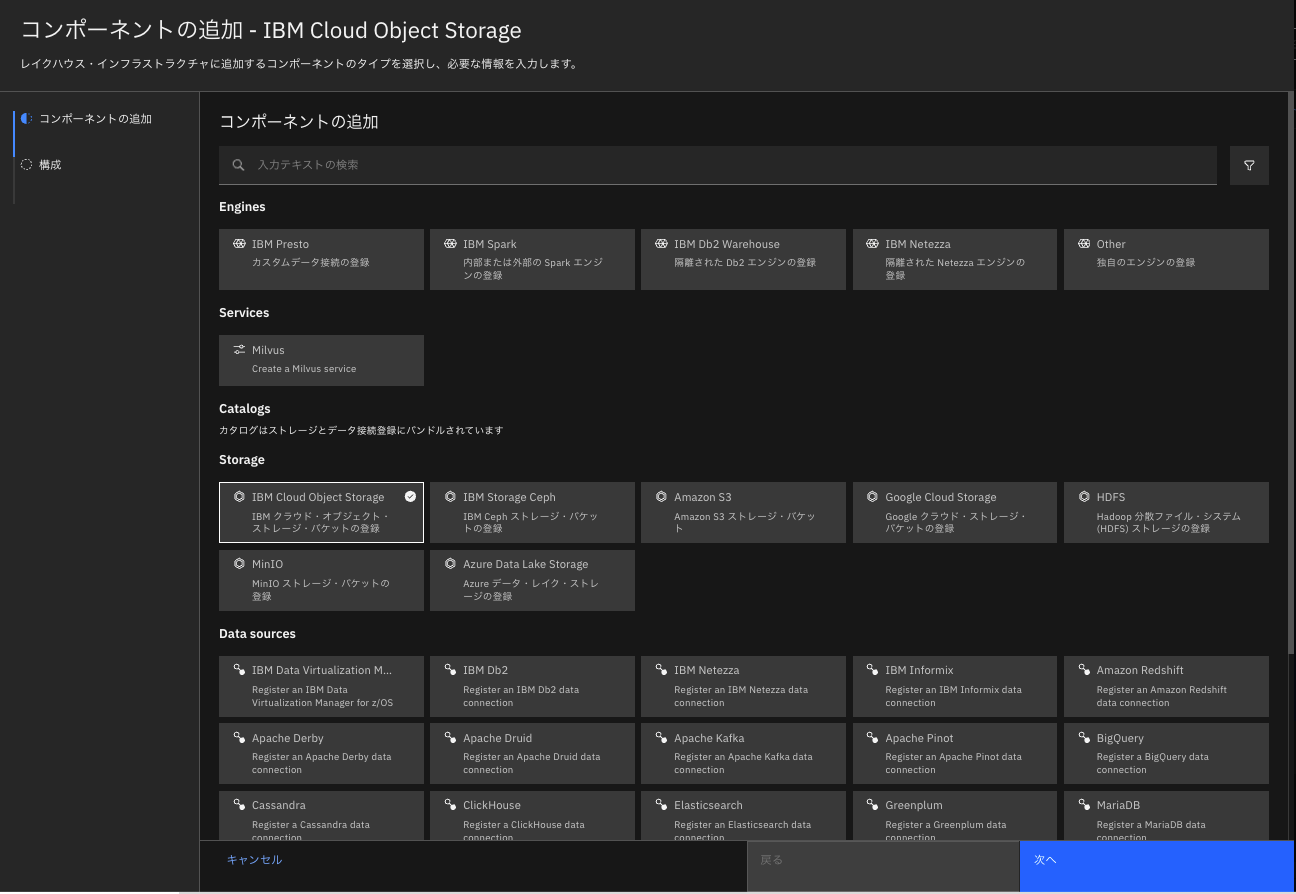
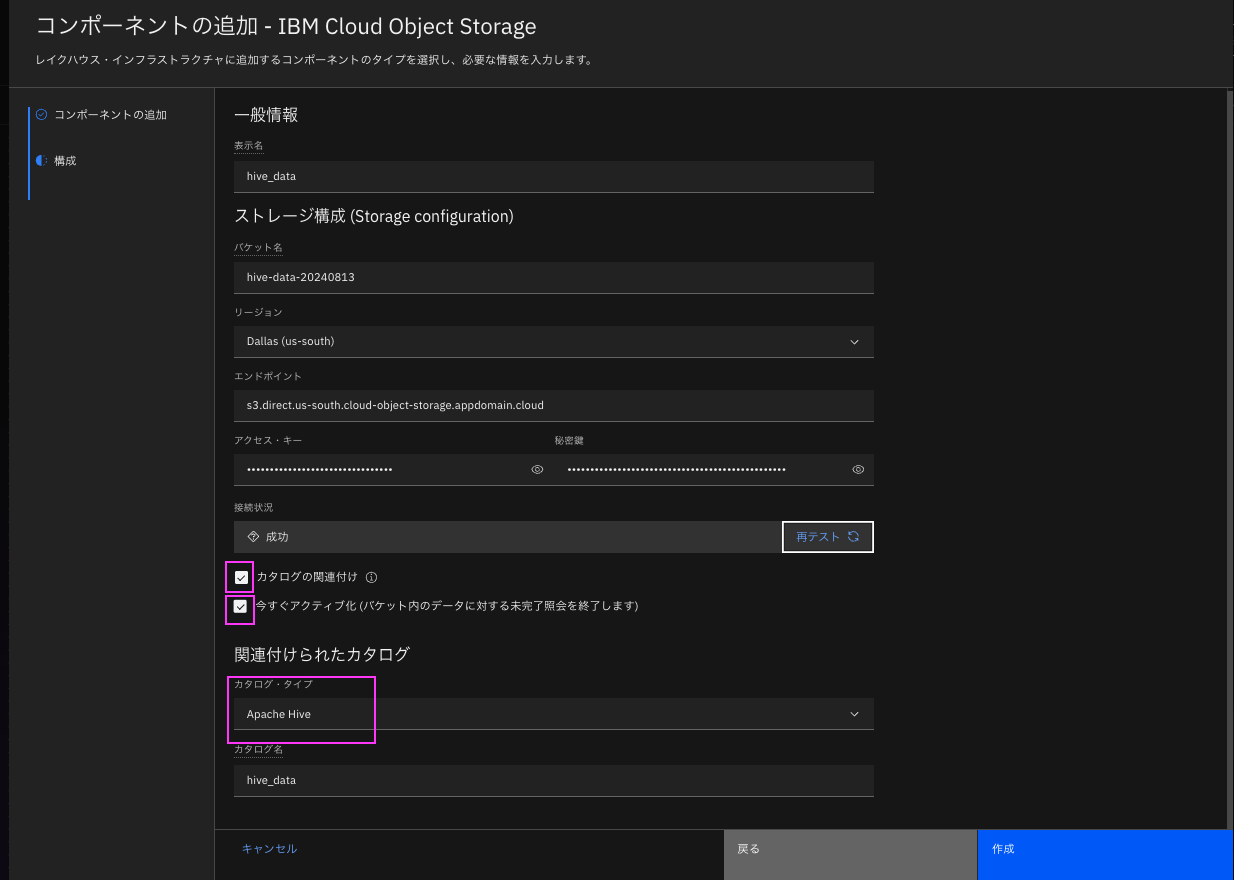
ない場合は「インフラストラクチャー・マネージャー」から「コンポーネントの追加」で使用するStorageを選択後、一般情報、ストレージ構成を入力し、「カタログの関連付け」「今すぐアクティブ化」をチェックし、カタログタイプに「Apache Hive」を設定して作成してください。
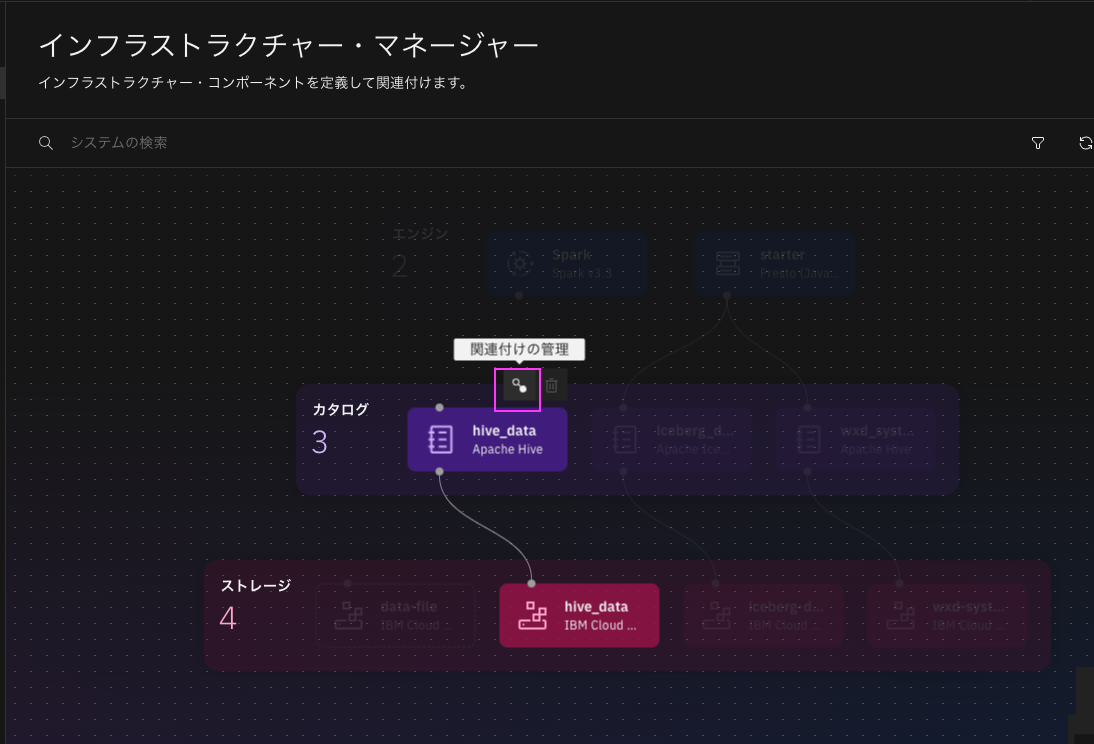
作成後、関連付けの管理で、prestoエンジンと関連づけてください。
ここではhive_dataという名前で Hiveカタログ を作成したとして進めます。

2. Icebergカタログ作成済み
(オプション: HiveテーブルからIcebergテーブルを作成する場合)
ない場合は上記Hiveカタログと同様に「インフラストラクチャー・マネージャー」から「コンポーネントの追加」で使用するStorageを選択後、一般情報、ストレージ構成を入力し、「カタログの関連付け」「今すぐアクティブ化」をチェックし、カタログタイプに「Apache Iceberg」を設定して作成してください。
作成後、関連付けの管理で、prestoエンジンと関連づけてください。
ここではiceberg_dataという名前で Icebergカタログ を作成したとして進めます。

3. ファイルを置くICOSがprestoエンジンと関連づけ済み
ファイルを置くICOSはすでにprestoエンジンと関連づけ済みである必要があります。
上記1、2でカタログを作成したICOSで自分でアクセス可能なものであればOKです。
あるいは新規でまったく別のICOSを関連づけても構いません。ただprestoエンジンと関連づけるためにはカタログ作成が必須なので、なんでもいいのでICOSとカタログのペアで登録してください、
1. 前準備: 使用するParquetファイルの準備
使用するParquetファイルの準備します。
Parquetファイル
Parquetファイルには項目名および通常属性のメタデータが入っています。作成予定テーブルの項目名および属性を使用したでParquetファイル を準備してください(あるいはテーブルをParquetファイルの項目名および属性で作成します)。
ここで使用するParquetファイル
TLC Trip Record Data(NYのタクシーのオープンデータ)を2ヶ月分を取り込んでみます。
TLC Trip Record Dataより、2024年のJanuaryとFebruaryのYellow Taxi Trip Recordsをダウンロードします。
yellow_tripdata_2024-01.parquet, yellow_tripdata_2024-02.parquetというファイルがダウンロードされます。

2. ParquetファイルをPrestoエンジンと関連づけられたICOSのバケットにアップロード
ここではスキーマ名/テーブル名/のフォルダー(=ファイルの接頭部)に取り込みたいParquetファイルを置きます。
尚、フォルダーに入ったファイルであれば場所(path)はどこでもOKです。取り込み時にはファイル名ではなくフォルダーまでのPATHを指定します。
ここではIBM Cloud Object Storage(ICOS)のコンソールを使ってアップロードします。
ここでは、Parquetファイルを取り込むHiveテーブルは
- スキーマ名:
hive_taxi - テーブル名:
ny_taxi_trip
と決めておきます。
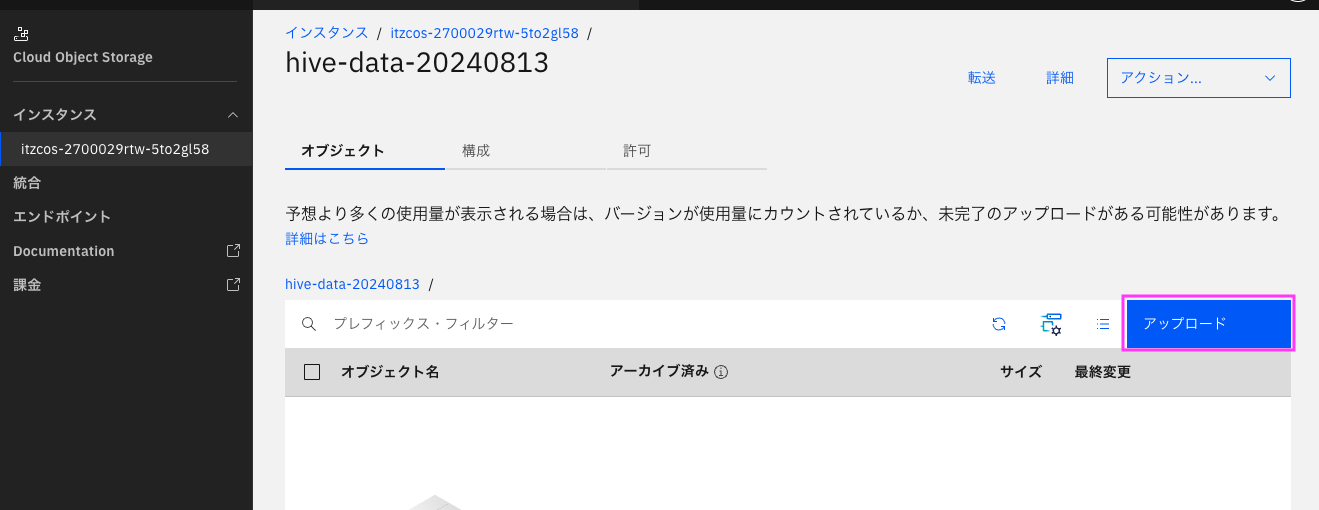
2-1. IBM Cloud Object Storage のコンソールで左側のメニューにある「インスタンス」ドロップダウンメニューをクリックし、Prestoエンジンと関連づけられたクラウド・オブジェクト・ストレージ・インスタンスを選択します。

2-2. Prestoエンジンと関連づけられたバケットをクリックし、右上の「アップロード」ボタンをクリックします
2-3. 右側に表示される「アップロード」画面で、アップロードするParquetファイルをドラッグアンドドロップします。
ここではyellow_tripdata_2024-01.parquetをドラッグアンドドロップします。

2-4. 「オブジェクトの編成(拡張)」をクリックします
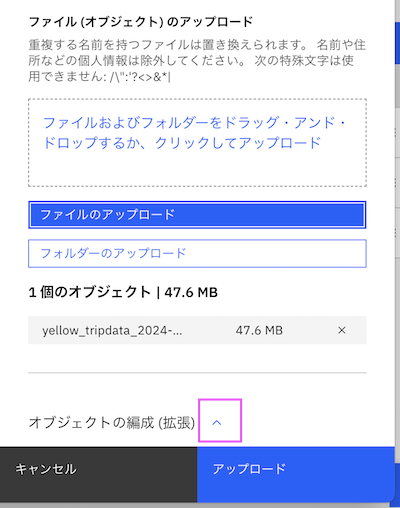
2-5. スクロールダウンして「接頭部」にファイルを入れるフォルダーのPATHを入力します。
ここではhive_taxi/ny_taxi_trip/と入れます。

2-6.「アップロード」をクリックします。
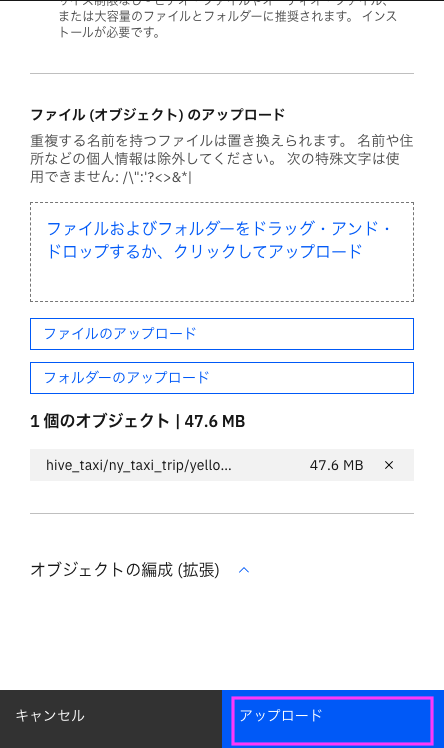
転送状況が表示されます。完了まで待ちます

完了したら「X」をクリックして右画面を消します

2-7. 入力したフィルダー名/取り込みたいparquetファイル のオブジェクト名になっていることを確認します。
ここではhive_taxi/ny_taxi_trip/yellow_tripdata_2024-01.parquetとなっています。

3. watsonx.data上でHiveテーブルの作成
取り込み先のHiveテーブルを作成します。
3-1. watsonx.dataコンソールに戻り、左側のメニューから「データマネージャー」アイコンをクリックします。
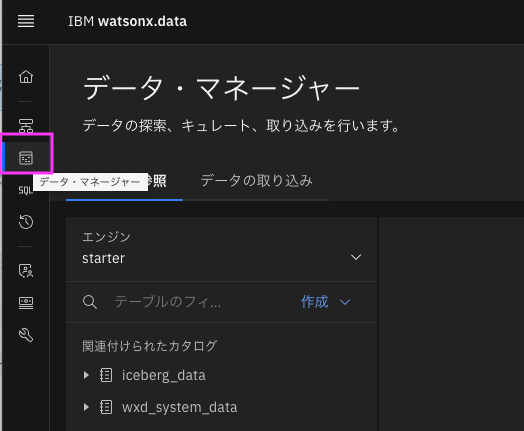
3-1. 「作成」ドロップダウンメニューをクリックし、「図式の作成」を選択します。
* 「図式の作成」は「スキーマの作成」の意味です。おいおい修正されると思います(!)

3-2: 、「図式の作成」ウィンドウで、Catalog に 使用するHiveカタログ、ここではhive_data を選択し、Name に スキーマ名、ここではhive_taxi と入力します(これは、先ほどアップロードした上位レベルフォルダの名前と一致します)。そして「作成」をクリックします。

3-4. 、左側のメニューから「照会ワークスペース」をクリックします
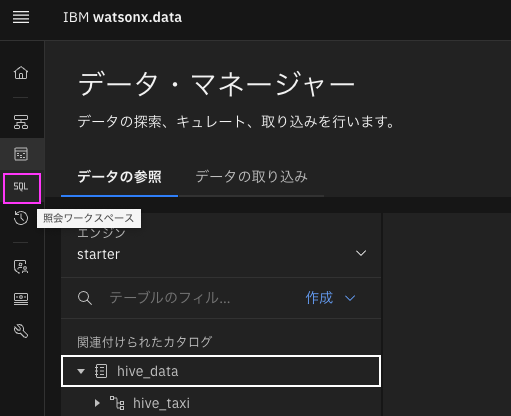
3-5. 取り込みたいparquetファイルと同じフォーマットでテーブル作成します。
以下のようにexternal_locationを指定して作成します。
CREATE TABLE <Hiveカタログ名>.<スキーマ名>.<テーブル名>(
・・・・ テーブル定義を記入
)
WITH (
format = 'PARQUET',
external_location='s3a://<バケット名>/<ファイルを置いたフォルダー名>'
)
ここでは
- Hiveカタログ名:
hive_data - スキーマ名:
hive_taxi - テーブル名:
ny_taxi_trip - ファイルを置いたフォルダー名:
hive_taxi/ny_taxi_trip/
を使います。
以下はyellow_tripdata_2024-01.parquetのフォーマットのテーブル作成ステートメントです。
一番下の<バケット名>は自分のHiveカタログのバケット名で置き換えてください。
CREATE TABLE hive_data.hive_taxi.ny_taxi_trip (
"VendorID" bigint,
"tpep_pickup_datetime" timestamp,
"tpep_dropoff_datetime" timestamp,
"passenger_count" double,
"trip_distance" double,
"RatecodeID" double,
"store_and_fwd_flag" varchar,
"PULocationID" bigint,
"DOLocationID" bigint,
"payment_type" bigint,
"fare_amount" double,
"extra" double,
"mta_tax" double,
"tip_amount" double,
"tolls_amount" double,
"improvement_surcharge" double,
"total_amount" double,
"congestion_surcharge" double,
"airport_fee" double
)
WITH (
format = 'PARQUET',
external_location='s3a://<バケット名>/hive_taxi/ny_taxi_trip'
)
テーブル作成ステートメントを入力したら、「XXXで実行」(XXXはエンジン名)をクリックして実行してください。

結果セットのresultがtrueになっていれば、作成成功です。アップロードしたparquetファイルのデータもテーブルに入っているはずです:
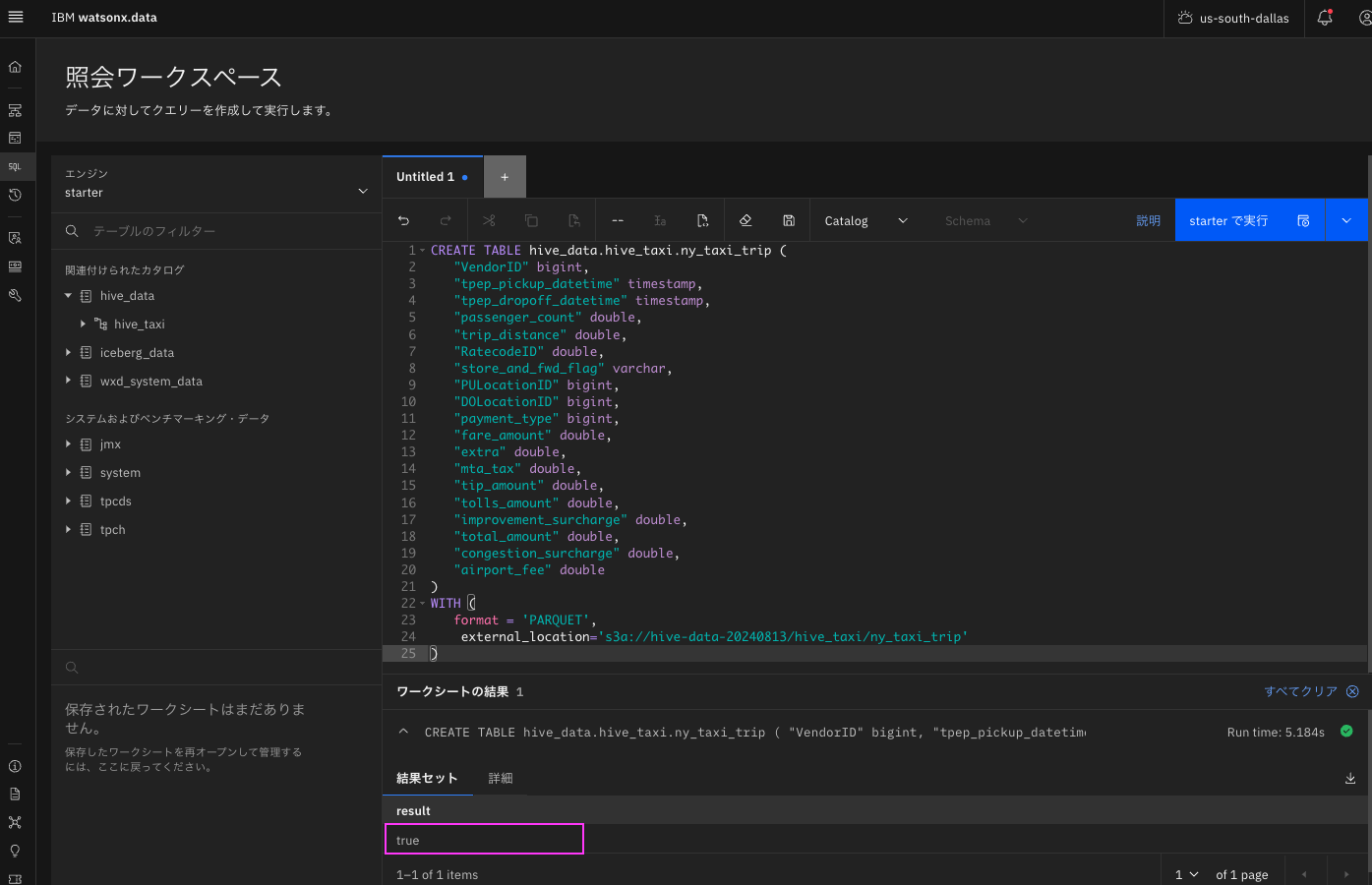
4. Hiveテーブルのデータの確認
以下はhive_data.hive_taxi.ny_taxi_tripの確認例です。
SQLでデータが入ったか確認してみましょう!
SQL:
SELECT
*
FROM
"hive_data"."hive_taxi"."ny_taxi_trip"
LIMIT
10;
実行例: ばっちり入ってますね!

以下からの検証はhive_data.hive_taxi.ny_taxi_tripで説明します。
5. ファイル追加してみます
yellow_tripdata_2024-02.parquetという2024年2月分のファイルをICOSに「アップロードし、データが追加されたか確認します。
確認用に現在のレコード数と、tpep_pickup_datetimeのMAX値を調べておきます。
-- 件数カウント
select count(*) from "hive_data"."hive_taxi"."ny_taxi_trip";
-- tpep_pickup_datetimeのMIN, MAX値
select min(tpep_pickup_datetime) MIN_DATETIME ,max(tpep_pickup_datetime) MAX_DATETIME from "hive_data"."hive_taxi"."ny_taxi_trip";
件数は 2964624件
tpep_pickup_datetimeのMIN, MAX値 はそれぞれ、2002-12-31 22:59:39.000, 2024-02-01 00:01:15.000 となります。
yellow_tripdata_2024-02.parquetをICOSのファイルを置いたパケットの/hive_taxi/ny_taxi_tripにアップロードします。
ここではIBM Cloud Object Storage(ICOS)のコンソールを使ってアップロードします。
5-1. IBM Cloud Object Storage のコンソールで左側のメニューにある「インスタンス」ドロップダウンメニューをクリックし、Hiveカタログと関連づけられたクラウド・オブジェクト・ストレージ・インスタンスを選択します。
5-2. hive_taxiフォルダー、その中のny_taxi_tripフォルダーをクリックして開きます。

5-3. yellow_tripdata_2024-02.parquetをドラッグしてアップロードします
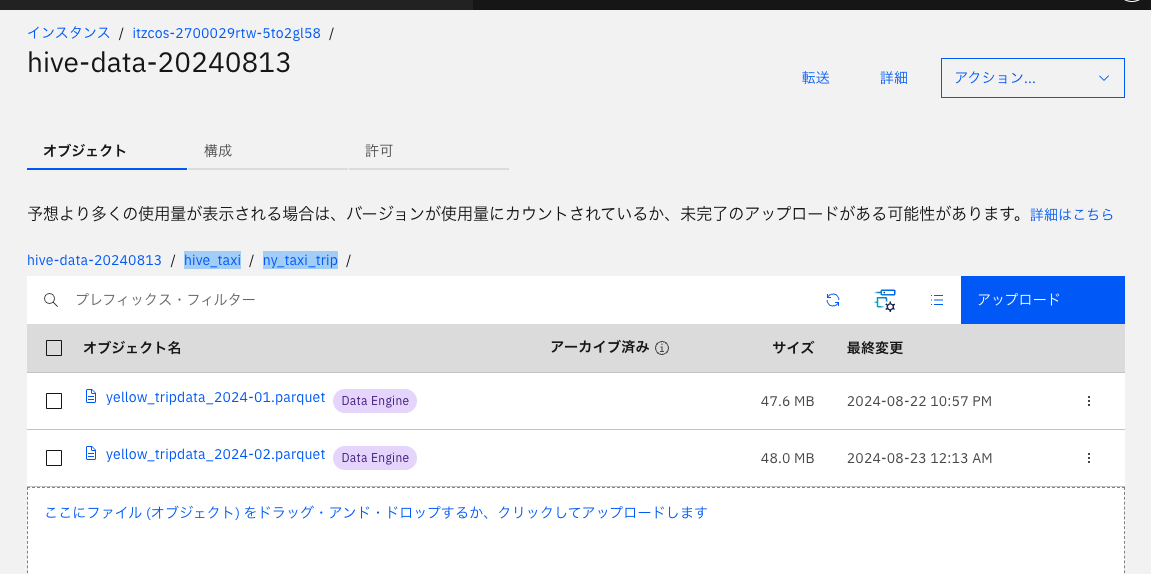
5-4. watsonx.dataコンソールに戻り、「照会ワークスペース」から再度以下のSQLを実行します。
-- 件数カウント
select count(*) from "hive_data"."hive_taxi"."ny_taxi_trip";
-- tpep_pickup_datetimeのMIN, MAX値
select min(tpep_pickup_datetime) MIN_DATETIME ,max(tpep_pickup_datetime) MAX_DATETIME from "hive_data"."hive_taxi"."ny_taxi_trip";
件数は 5972150件となり、2月分が増えています
tpep_pickup_datetimeのMIN, MAX値 はそれぞれ、2002-12-31 22:59:39.000, 2024-03-01 00:01:37.000 となり、2月分が追加されたことがわかります。
このようにファイルを追加すればレコードが追加できます。
6. ファイル削除してみます
追加した yellow_tripdata_2024-02.parquetをICOS上から削除してみます。
6-1. IBM Cloud Object Storage のコンソールで左側のメニューにある「インスタンス」ドロップダウンメニューをクリックし、Hiveカタログと関連づけられたクラウド・オブジェクト・ストレージ・インスタンスを選択します。
6-2. ファイルを置いたバケット → hive_taxiフォルダー → ny_taxi_tripフォルダーをクリックして開きます。
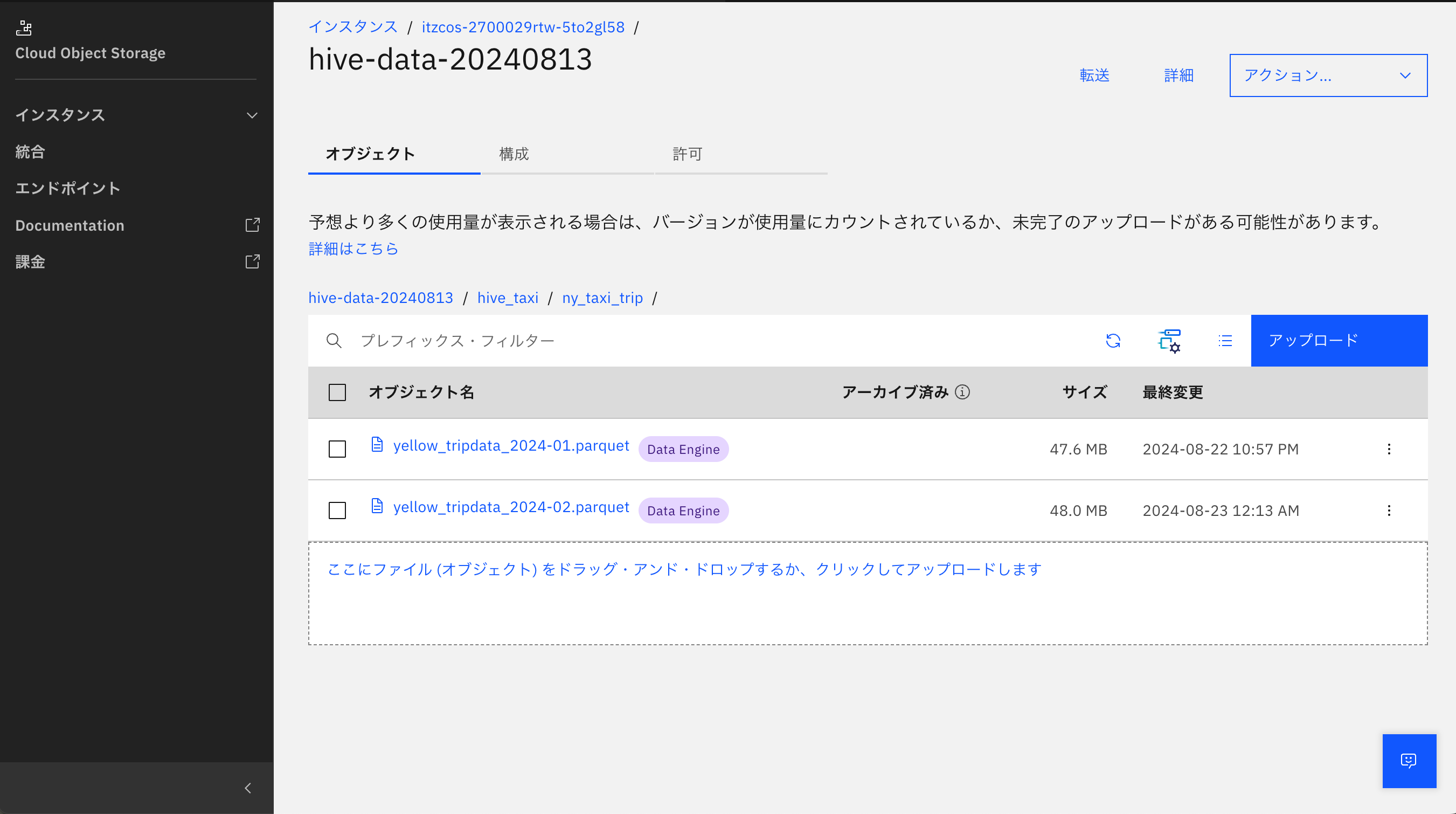
6-3. yellow_tripdata_2024-02.parquetの右側の3点メニューをクリックし「削除」をクリックします。
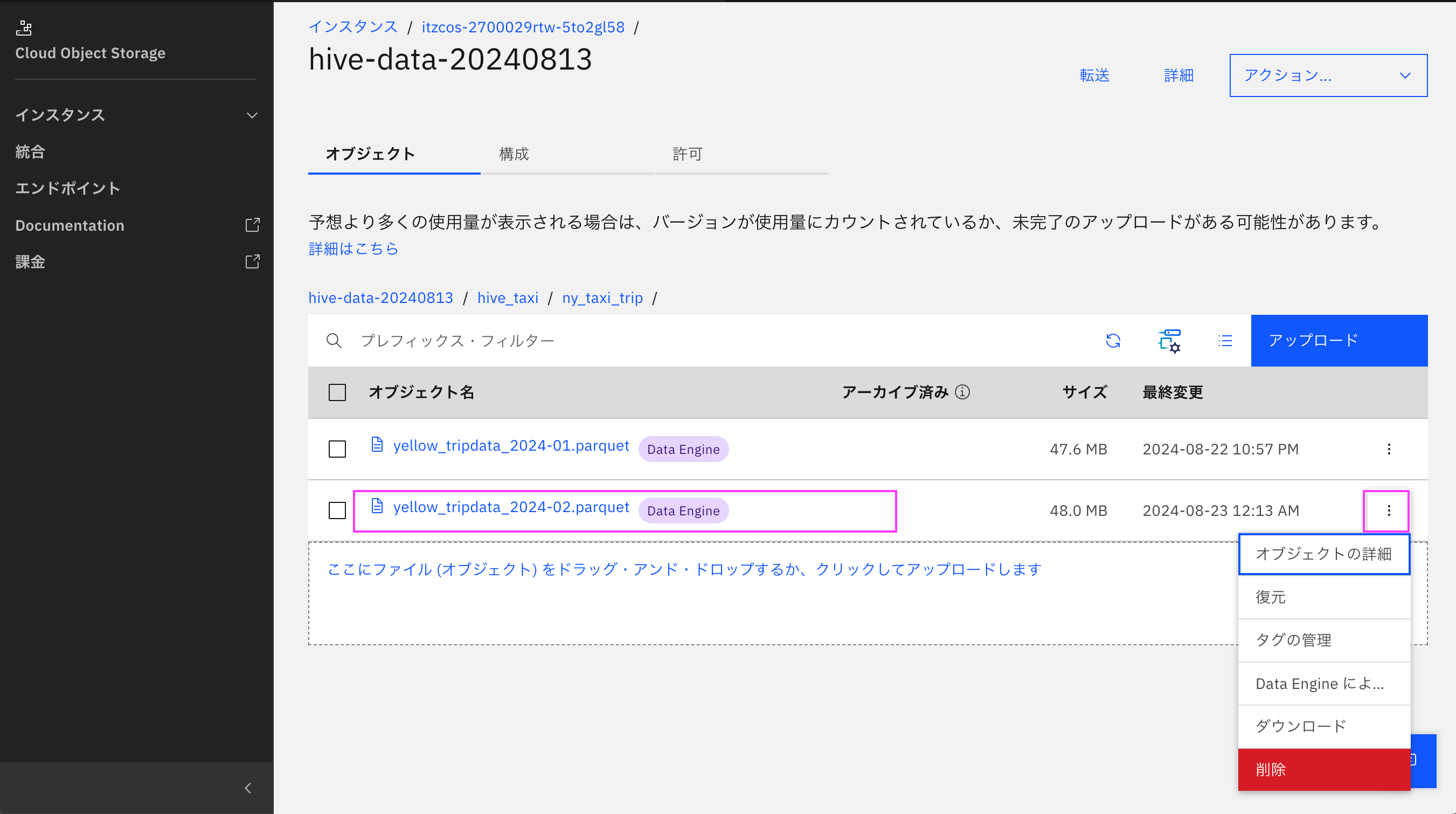
6-4. ファイル名を確認し、「 完全に削除」と入力後、「削除」をクリックします。

削除されました!

6-5. watsonx.dataコンソールに戻り、「照会ワークスペース」から再度以下のSQLを実行します。
-- 件数カウント
select count(*) from "hive_data"."hive_taxi"."ny_taxi_trip";
-- tpep_pickup_datetimeのMIN, MAX値
select min(tpep_pickup_datetime) MIN_DATETIME ,max(tpep_pickup_datetime) MAX_DATETIME from "hive_data"."hive_taxi"."ny_taxi_trip";
件数は 2964624件となり、2月分が削除され、1月分のみになりました。
tpep_pickup_datetimeのMIN, MAX値 はそれぞれ、2002-12-31 22:59:39.000, 2024-02-01 00:01:15.000 となり、最初の状態と同じにもどりました。
このようにファイル削除をすれば、その分のレコードも削除されます。
7. Hiveテーブルから、Icebergテーブルを作成
hive_data.hive_taxi.ny_taxi_tripテーブルから同じ内容でIcebergテーブルを作成します。
ここでは以下のIcebergテーブルを作成します。
- Icebergカタログ名:
iceberg_data - スキーマ名:
ic_taxi - テーブル名:
ny_taxi_trip
を使います。
7-1. スキーマを作成します
今回はコマンドで作成してみます。
watsonx.dataの「照会ワークスペース」から以下のSQLを実行します。
<バケット名>は自分のIcebergカタログのバケット名で置き換えてください。
create schema iceberg_data.ic_taxi with (location = 's3a://<バケット名>/ic_taxi/');
7-2. hive_data.hive_taxi.ny_taxi_tripテーブルから同じ内容でIcebergテーブルを作成します
watsonx.dataの「照会ワークスペース」から以下のSQLを実行します。
create table iceberg_data.ic_taxi.ny_taxi_trip
as select * from hive_data.hive_taxi.ny_taxi_trip;
無事作成できました!

8. Hiveテーブルから、IcebergテーブルにINSERT
Hiveテーブルから、既に作成済みのIcebergテーブルにINSERTしたい場合は、watsonx.dataの「照会ワークスペース」から以下のSQLを実行します。
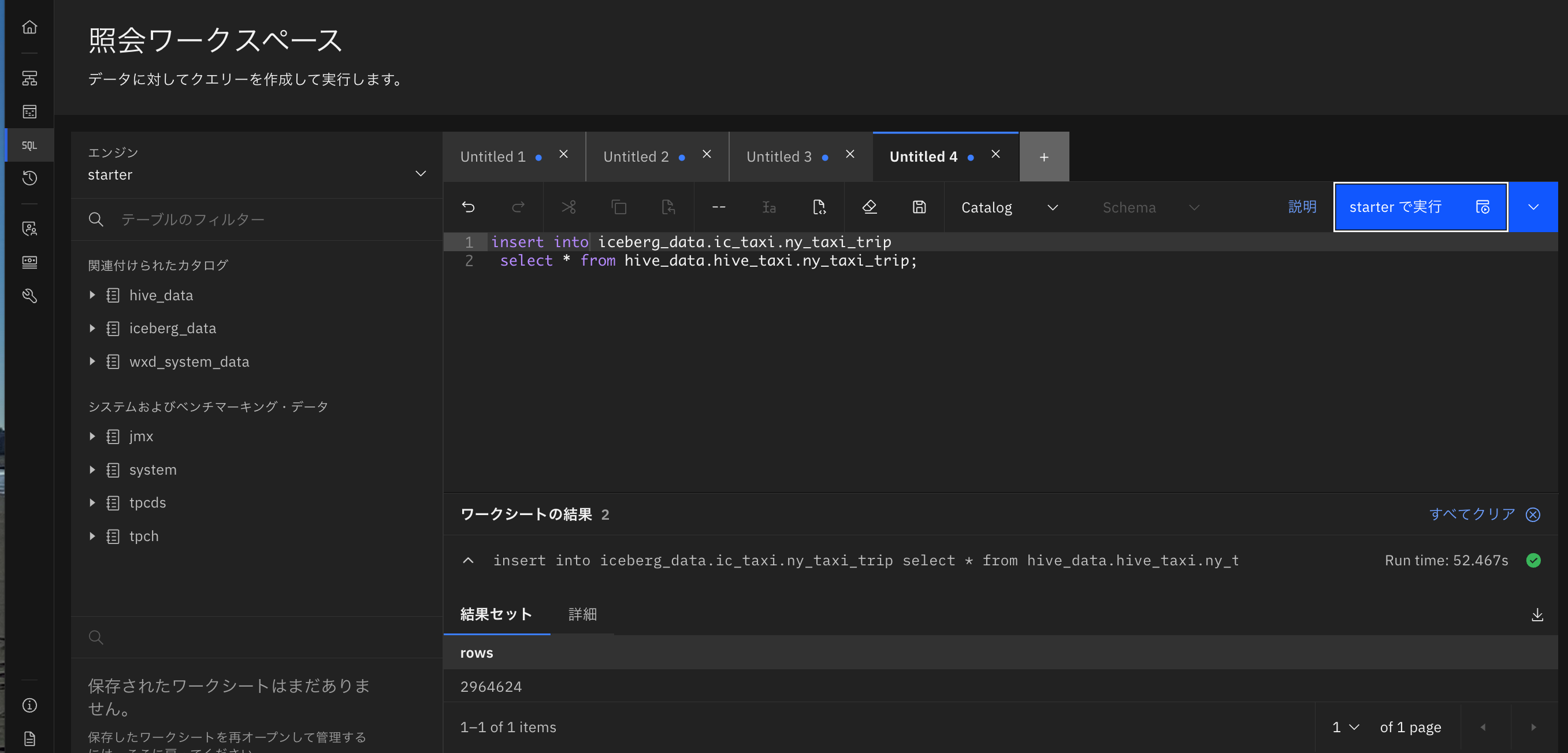
insert into iceberg_data.ic_taxi.ny_taxi_trip
select * from hive_data.hive_taxi.ny_taxi_trip;
無事INSERTできました!
9. まとめ
このようにHiveテーブルは設定すればフォルダーの中にファイルを置くだけで、テーブルとして使用できます。
さらにファイルを追加すればそのレコードが追加されますし、削除すればそのレコードが削除されます。
またそのHiveテーブルからIcebergテーブルも簡単に作成、INSERTできますので、データ取り込み方法の1つとして使用可能です。ぜひ試してみてください。
以上です。