"Graph Convolutional Neural Networks for Web-Scale Recommender Systems"を理解するために読む。
情報
- node2vec: Scalable Feature Learning for Networks
- この記事の画像は上記論文からの転載。
簡単にまとめると、
- Graph構造を持つデータに対して、各nodeの表現ベクトルを学習させたい。
- 自然言語処理で使われるSkip-gramモデルを拡張する。
- Graphの近傍をSkip-gramでのwindowに対応させて、最適化問題を定義する。
- 近傍はrandom walkを使って定義する。
- random walkとは、あるnode $u$ からスタートし、$l$回ランダムにnode上を移動する。
- この移動で通ったnode群を$u$の近傍と定義する。
- 2nd order random walkと呼ぶ方法を提案している。
- マルチラベル分類とリンク推論の2種類のタスクで実験を行い、精度が向上することが示せた。
1. Introduction
- feature engineeringは専門知識が必要となる。
- また様々なタスクへの汎用的な特徴量を作るのは困難である。
- 他の方法として、特徴量を学習させる方法がある。
- そのときの課題は目的関数を定義することにある。
- etc...
Present work.
- node2vecを提案する。これは特徴量学習の半教師ありアルゴリズムである。
- nodeの近傍を生成するために2nd order random walkを用いる。
- それぞれのnodeのrepresentationをペアに拡張する方法も紹介する。
- これにより、nodeに関わるタスクだけでなく、edgeに関わるタスクにも活用できる。
- 実験では2つのタスクにフォーカスする。
- マルチラベル分類タスク
- リンク推論タスク
- etc...
2. Related work
- 線形代数的なアプローチではLaplacianや隣接行列に対してPCAやIsoMapを用いる方法がある。
- 近年、自然言語処理分野で単語に対してcontinuous feature representationを学習するSkip-Gramが提案された。
- etc...
3. Feature Learning framework
- グラフを$G=(V, E)$とする。
- 提案する方法では、weighted/unweighted, directed/undirectedのグラフに対して適用できる。
- nodeからrepresentationへのマップを $f: V \rightarrow R^d$ とする。
- 同等に、$f$を$|V| \times d$の行列と見ることができる。
- すべてのnode $u \in V$に対して近傍$N_S(u) \subset V$を定義する。
- ここで$S$は近傍を定義するためのstrategyとする。
- Skip-gramのアーキテクチャを拡張し、次のような目的関数を最適化する。
- $\max_{f} \sum_{u \in V} \log \text{Pr}(N_S(u) | f(u))$
- 最適化問題を解きやすくするために2つの仮定を導入する。
-
条件付き独立
- $\text{Pr}(N_S(u)|f(u)) = \prod_{n_i \in N_S(u)} \text{Pr}(n_i|f(u))$
-
特徴空間の対称性
- $\text{Pr}(n_i|f(u)) = \frac{\exp(f(n_i) \cdot f(u))}{Z_u}$
- $Z_u = \sum_{v \in V} \exp(f(v) \cdot f(u))$
-
条件付き独立
- この仮定のもとでは目的関数は次のようなる。
- $\max_{f} \sum_{u \in V} (-\log Z_u + \sum_{n_i \in N_S(u)} f(n_i) \cdot f(u))$
- となっているが、下記が正しいと思う。
- $\max_{f} \sum_{u \in V} \sum_{n_i \in N_S(u)} (-\log Z_u + f(n_i) \cdot f(u))$
- $Z_u$ の計算コストは非常に高いので、negative samplingを用いる。
- $N_S(u)$を定義する方法が重要となる。
- Skip-gramでは、線形なので文字列の前後の文字を使うことができたが、Graphでは工夫が必要となる。
3.1 Classical search strategies
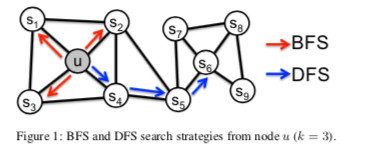
- Breadth-first Sampling (BFS)
- すぐ隣のnodeを近傍とする。
- Depth-first Sampling (DFS)
- 距離が遠くなるようなnodeを近傍とする。
3.2 node2vec
- BFSとDFSを滑らかに補間するようなアルゴリズムを考える。
3.2.1 Random Walks
- Random walkをシミュレートすると次のようになる。
- まずsource node $u$からスタートし、$l$回移動するとする。
- $c_0=u$とし、下記の確率で次のnodeに移動する。
$$P(c_i=x|c_{i-1} = v) = \begin{cases}
\frac{\pi_{vx}}{Z} , , , , , (v, x) \in E\\
0 , , , , , \text{otherwise}
\end{cases}$$ - $\pi_{vx}$ は正規化されていない推移確率
- $Z$ は正規化定数
3.2.2 Search bias alpha
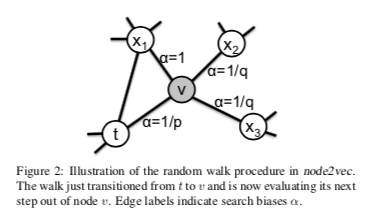
- もっとも単純な推移確率は $\pi_{vx} = w_{vx}$ である。$w_{vx}$はedgeのweight。
- この方法では上手く行かない(WIP: 理由をちゃんと理解する。)
- そこで2つの変数$p$と$q$をもつ2nd order random walkを定義する。
- random walkが$t \rightarrow v$に移動した直後とする。
- 正規化されていない推移確率を$\pi_{vx} = \alpha(t, x) \cdot w_{vx}$
$$\alpha_{pq}(t, x) = \begin{cases}
\frac{1}{p} , , , , , d_{tx} = 0 \\
1 , , , , , d_{tx} = 1 \
\frac{1}{q} , , , , , d_{tx} = 2
\end{cases}$$- $d_{tx}$ は$t$と$x$の最短距離を表す。
3.2.3 The nod2vec algorithm

- etc...
3.3 Learning edge features
- node自体ではなく、nodeのペアに対するタスクもある。
- random walkはGraphの結合の情報を使っている。
- etc...
4. Experiments
- node2vecは他のタスクとは独立して学習させることができる。
- node2vecによる特徴量表現をGraph分析の様々なタスクに活用できる。
4.1 Case Study: Les Miserable network
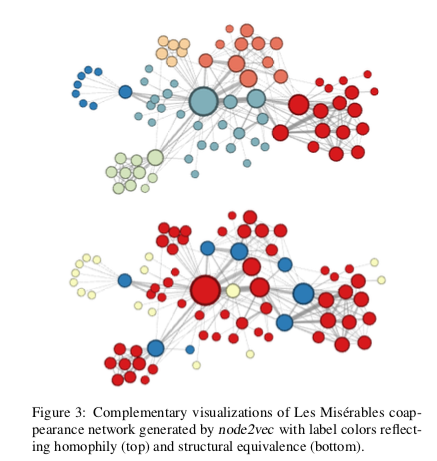
- ネットワーク分析で、コミュニティに分類するタスクとノードの役割で分類するタスクがある。
- random walkのパラメータを調整することでそれぞれのタスクを解くことができる。
- 上部の図 (p=1, q=0.5)
- 近い登場人物が同じ色に分けられている
- 下部の図 (p=1, q=2)
- ネットワーク上の役割が同じ人が同じ色に分けられている。
- 上部の図 (p=1, q=0.5)
4.2 Experimental setup
- node2vecと他の表現学習の方法を比較する。
- 他の表現学習の方法として次の3つを採用する。すでにDeepWalkの優位性が示されている方法とは比較しない。
- Spectral clustering
- Matrix Factorizationの1種。正規化されたLaplacianを固有値分解し、上位$d$個の固有値ベクトルを使う。
- DeepWalk
- 2nd order random walkの $p=1$, $q=1$のバージョン。
- LINE
- $d$次元の表現ベクトルを2分割して、半分をBFSで、もう半分を2-hop distance のノードをサンプリングした方法で学習させた表現ベクトルをしようする。
- Spectral clustering
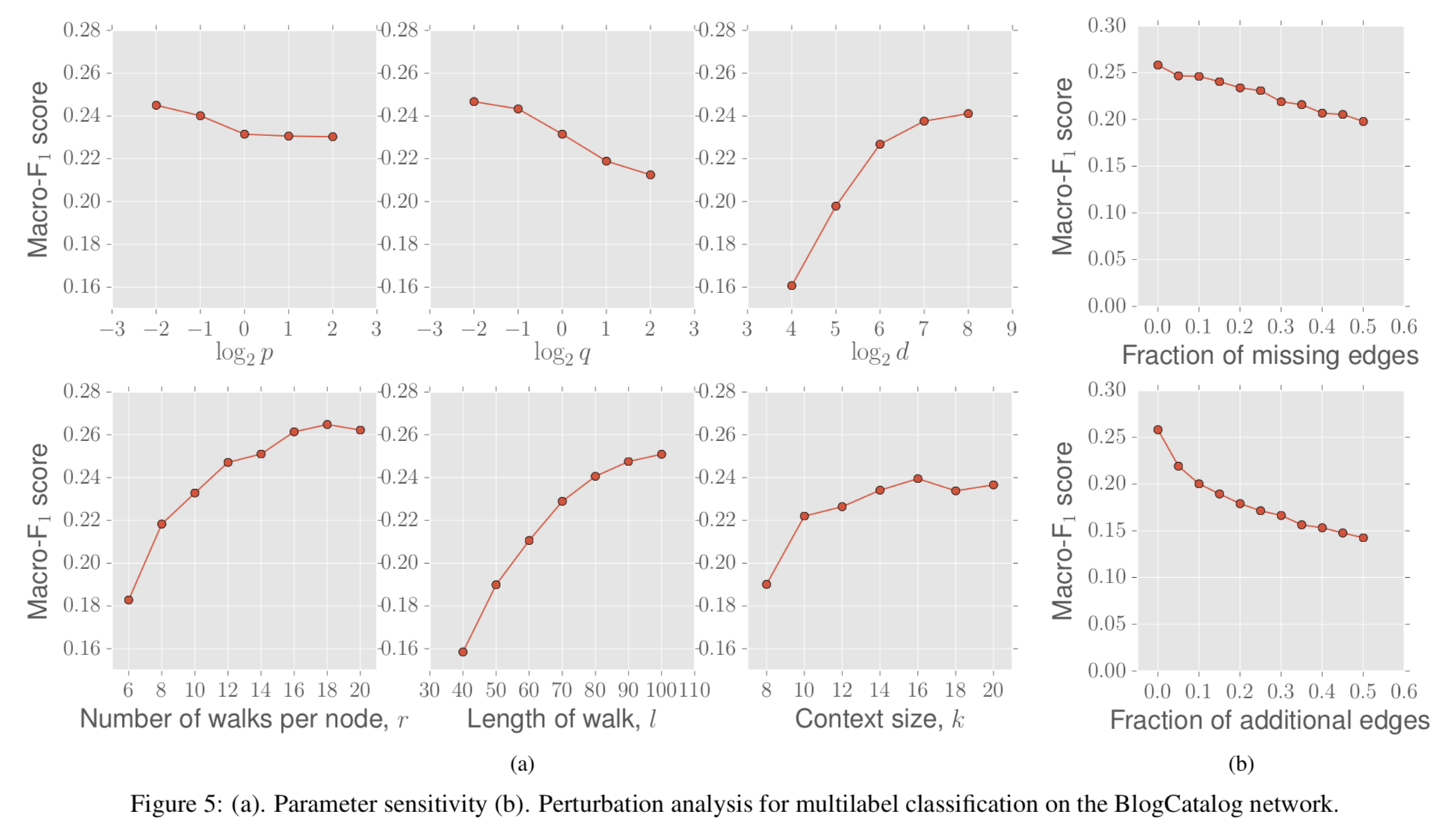
4.3 Multi-label classification
- 下記3つのデータセットを使用する。
- BlogCatalog
- Protein-Protein Interactions(PPI)
- Wikipedia
- それぞれの方法で表現ベクトルを生成したあとに、one-vs-rest のL2正則化したロジスティック回帰分類器でマルチラベル分類問題を解く。
- 結果は下記の通り。