内容
今の時代Raspberry Piでも十分快適に使えるLLMが出ているらしく、気になったのでGoogleが提供しているLLM Gemma 3の1b q4_0 ggufモデルをRaspberry Pi 5(8GB RAM)で動かしてみました。
また、動かすまでの手順を記載しました。
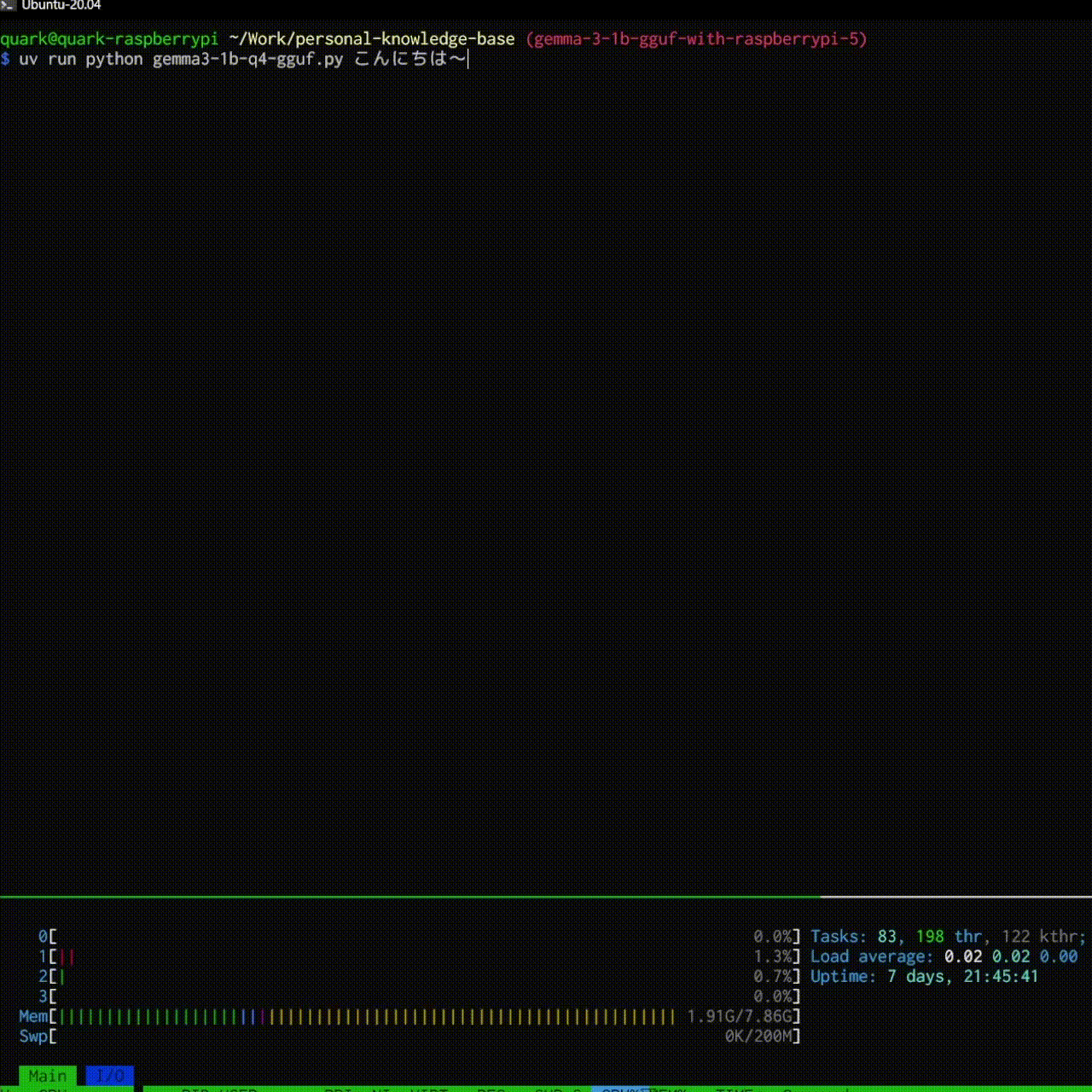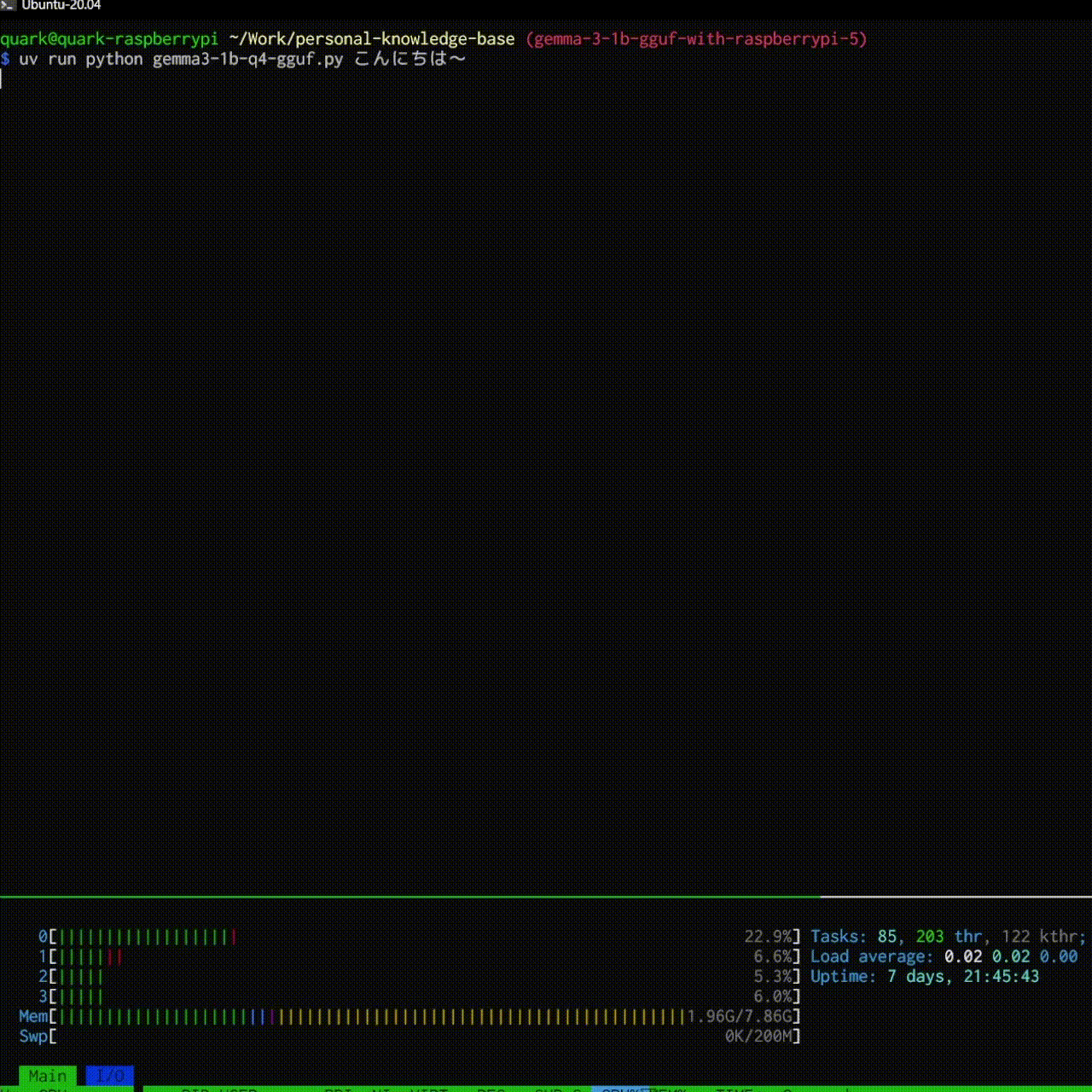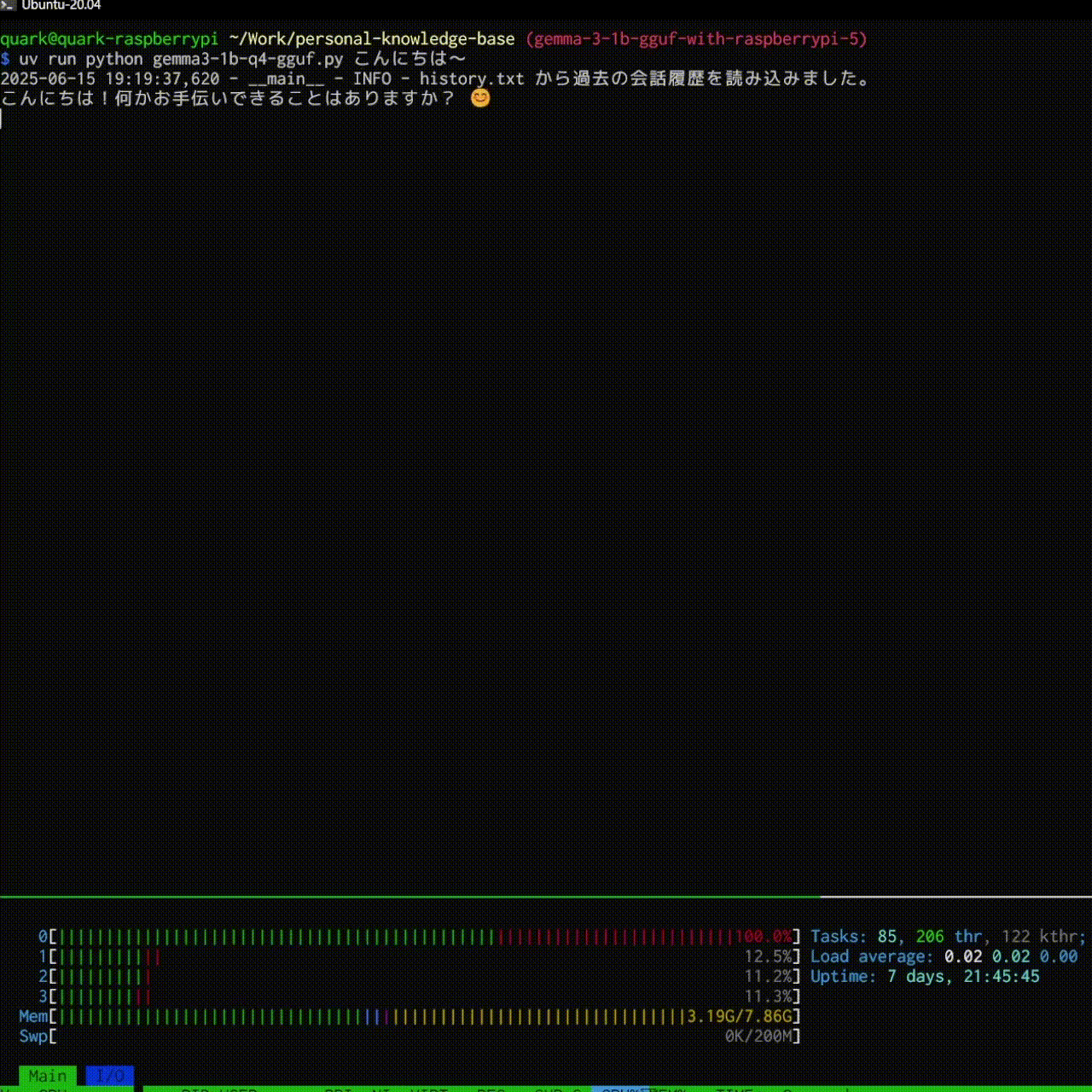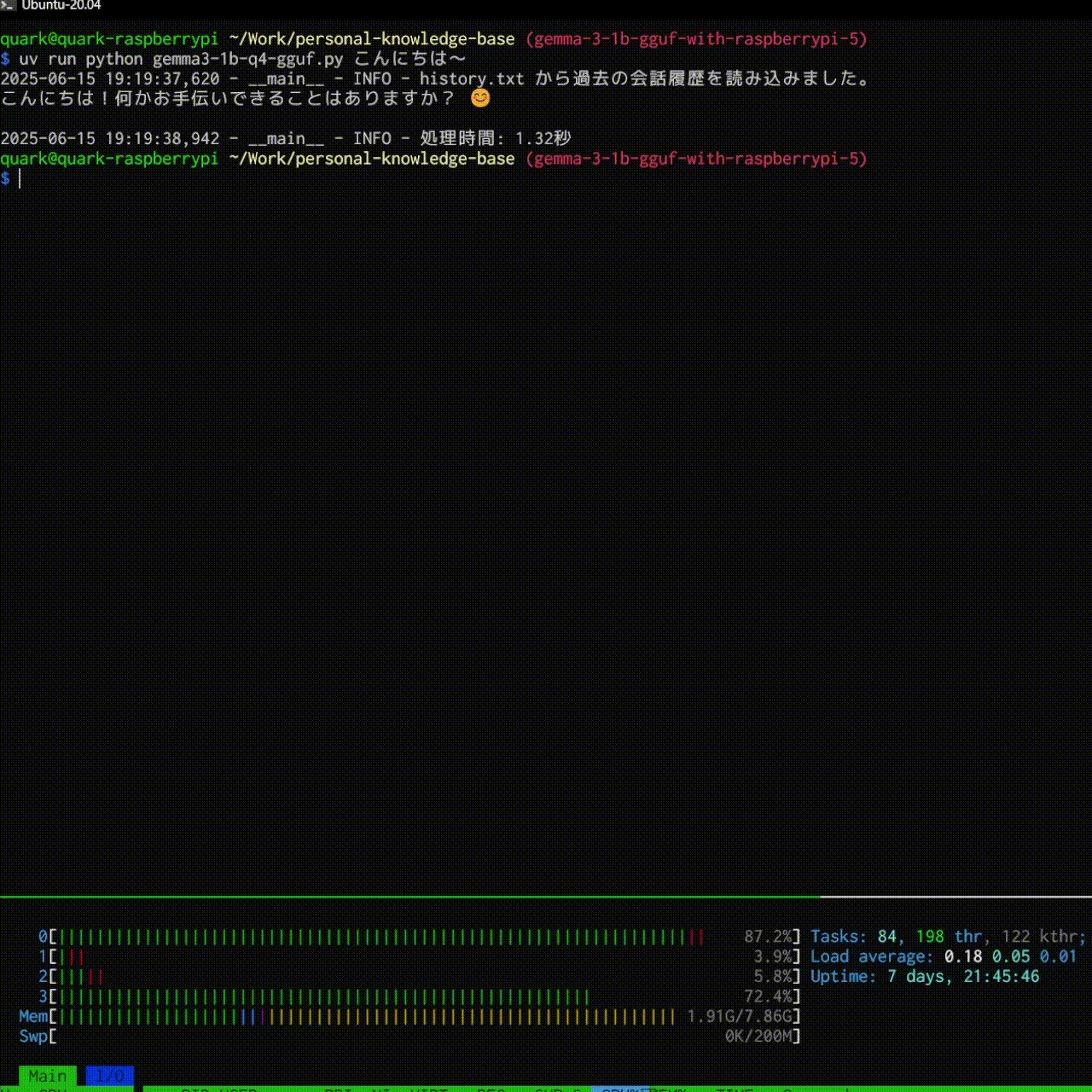
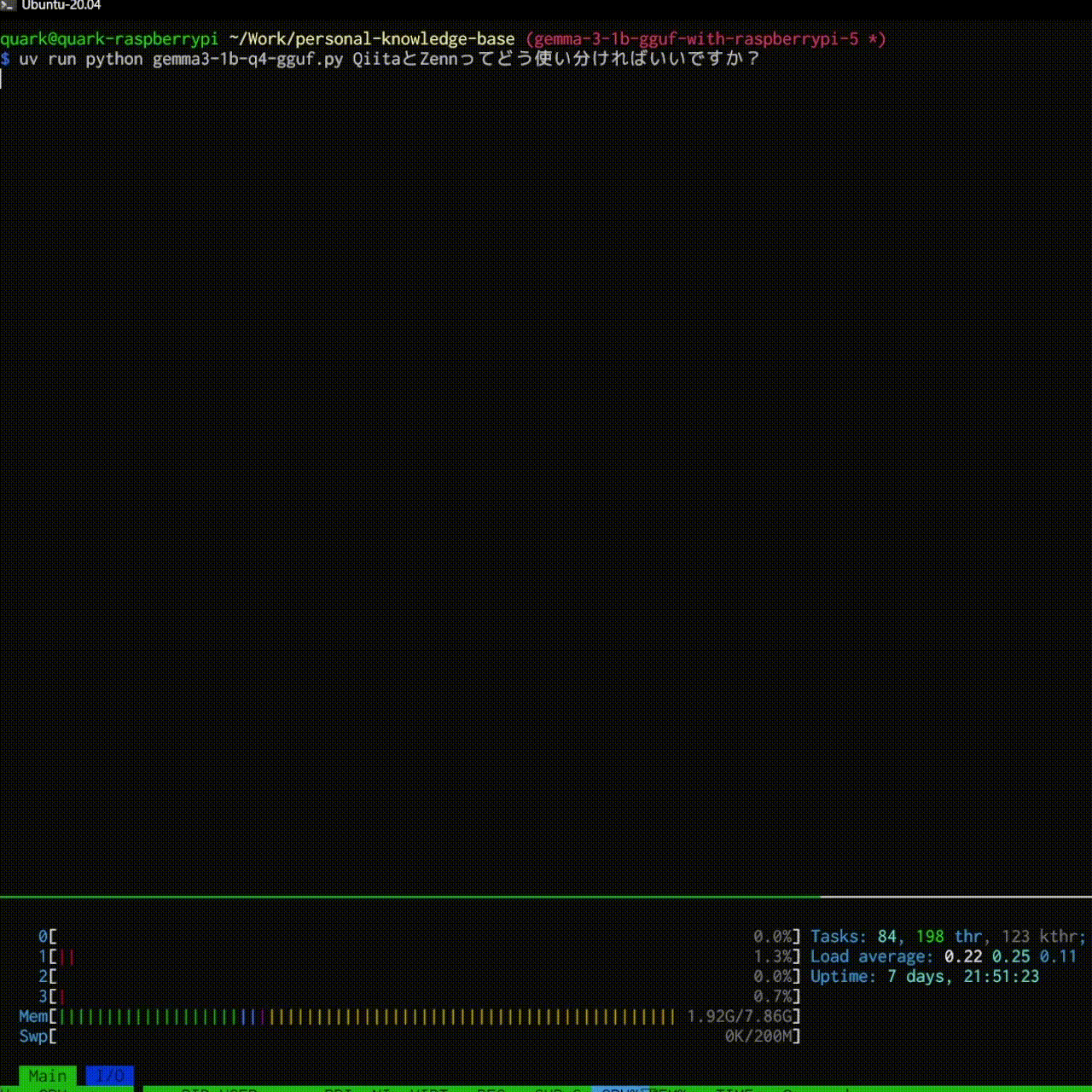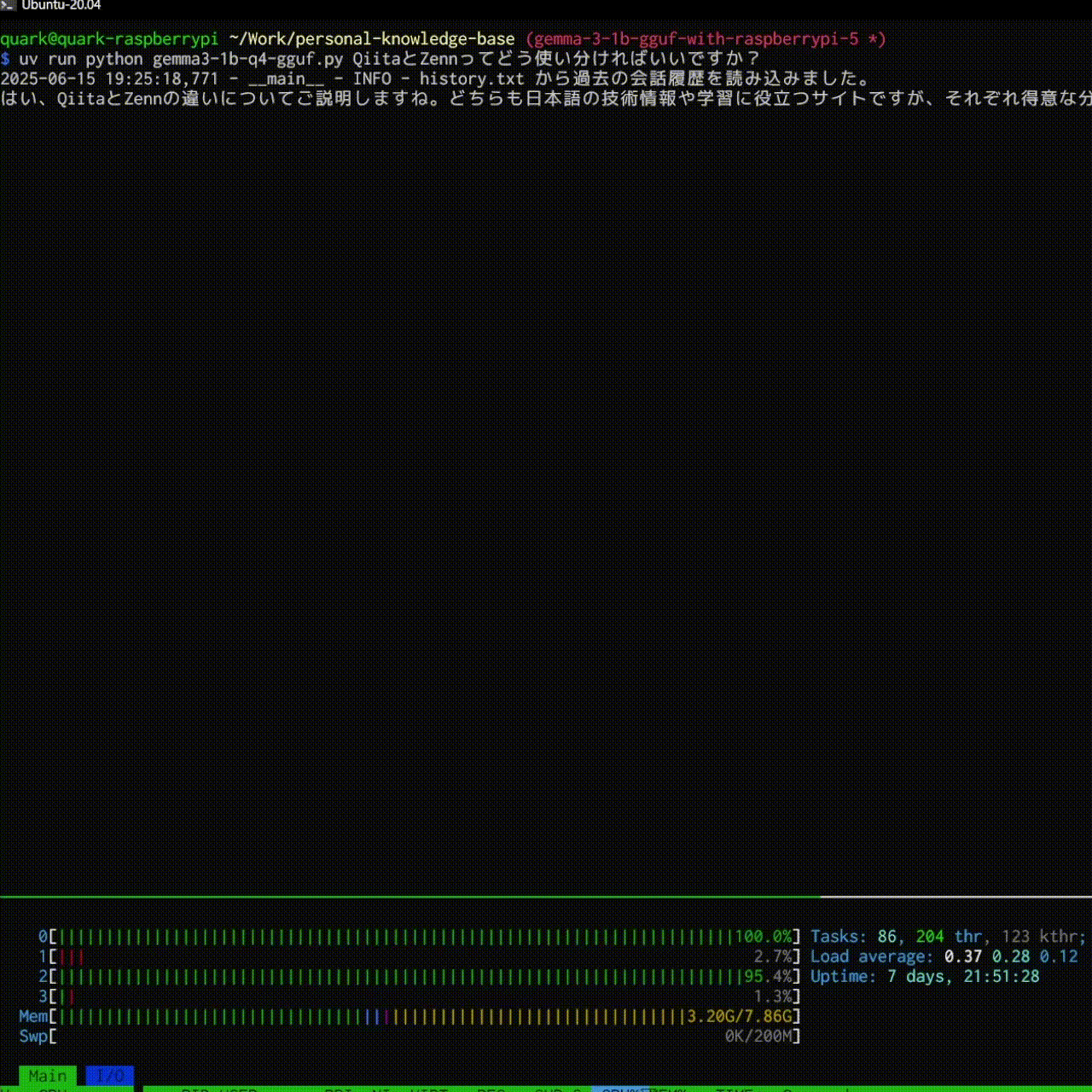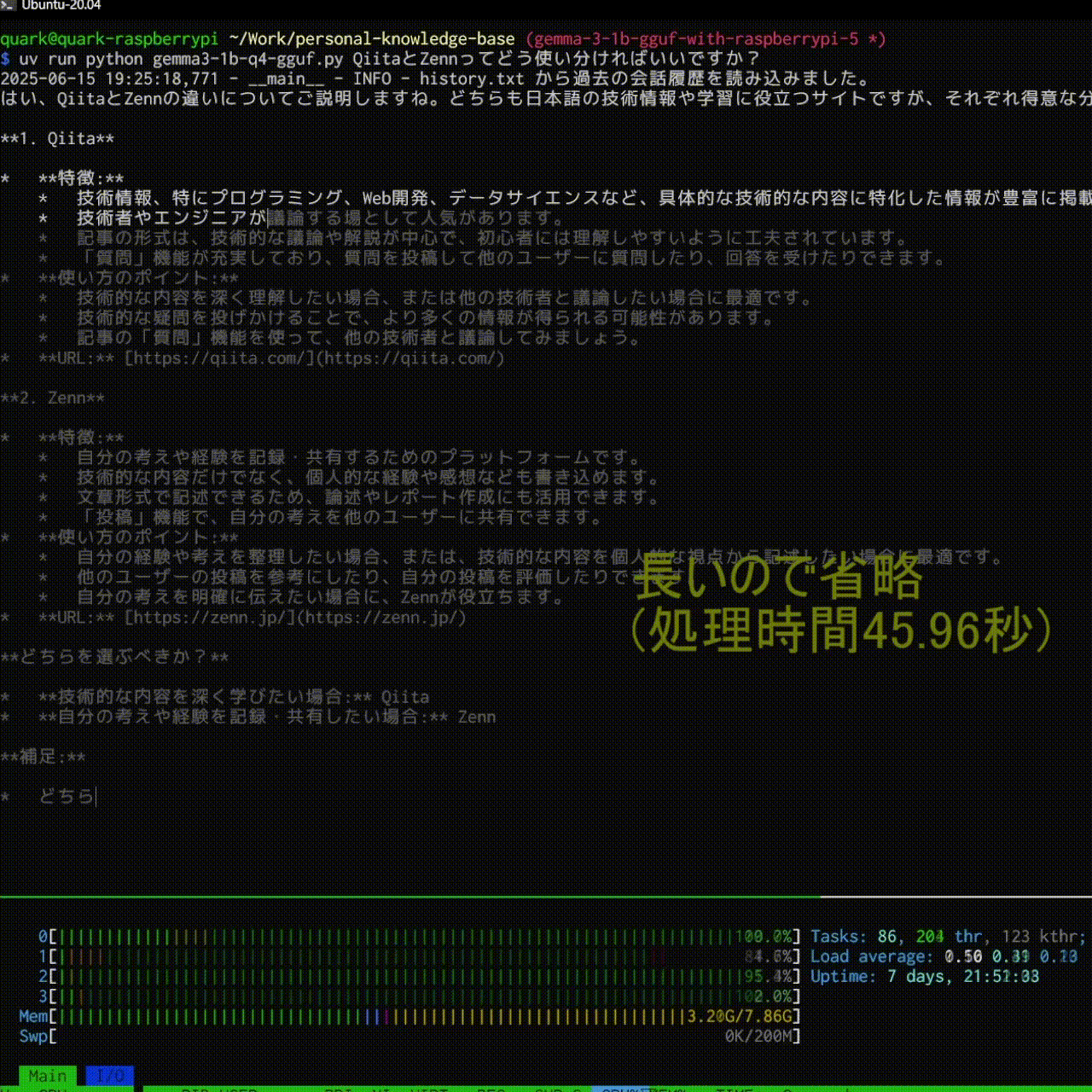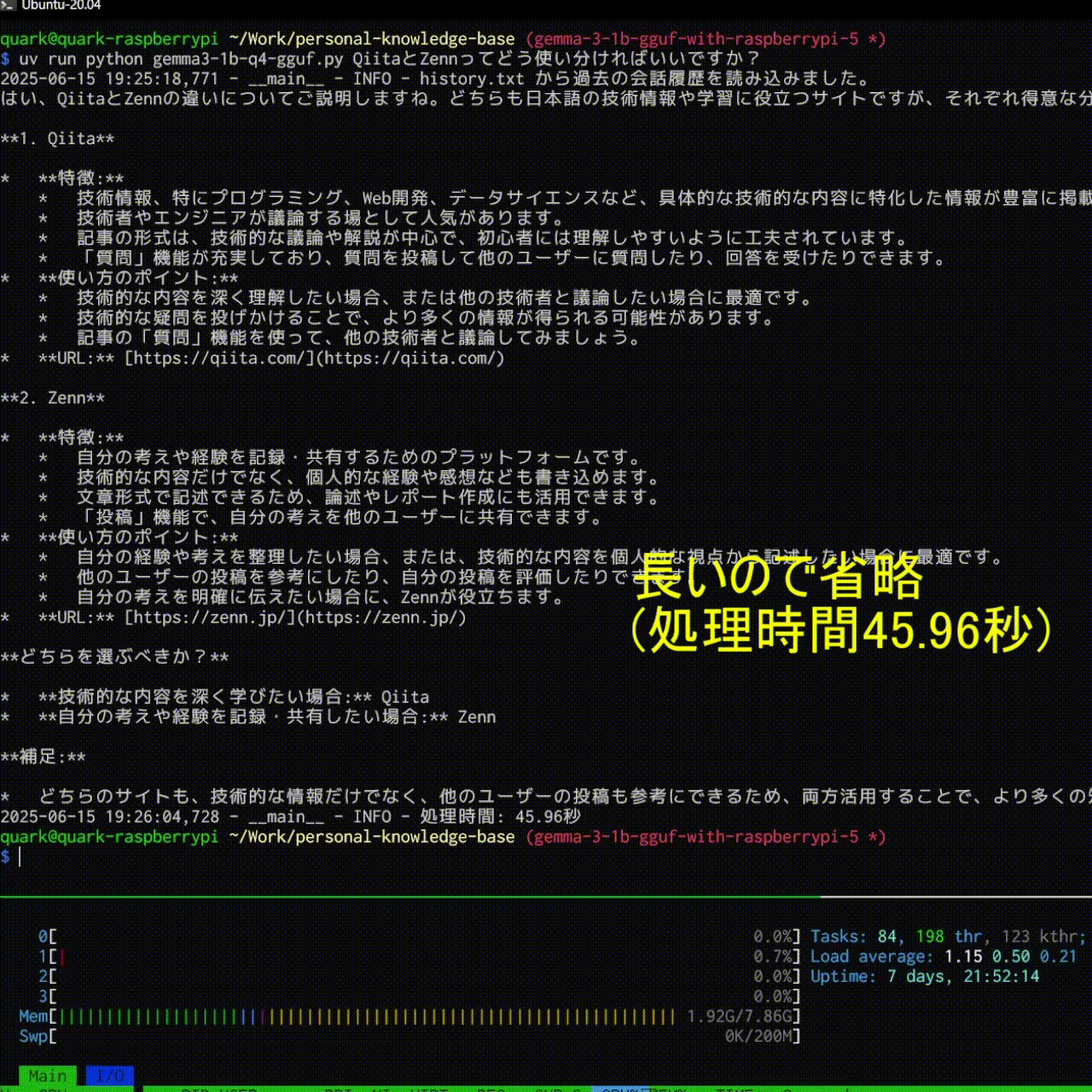
結果としては以下のような感じで大分快適に動きました!
Gemma 3 について
Googleが提供する軽量なマルチモーダルLLMで、画像やテキストを入力としてテキストを出力できます。
多言語対応もしていて、入力は4b,12b,27bモデルで128kトークン、1bは32kトークンまで対応しています。
出力はいずれも8192トークンまで対応です。
Hugging Faceではそれぞれのパラメータ数に加えてpre-trained(pt)からinstruction tuning(it)、量子化系のモデルまで公開されています。
セットアップ手順
1. Raspberry Pi 5自体のセットアップ
Raspberry Pi 5自体のセットアップを行います。詳細はこちらに記載しています。
2. uvのインストール
$ curl -LsSf https://astral.sh/uv/install.sh | sh
$ uv --version
uv 0.6.17
3. Hugging Face登録
Hugging Faceにアカウントを作ります
作成後Hugging FaceにSSH Keyを登録します
$ ssh-keygen -t rsa
$ cat id_rsa.pub
Hugging Face Settings -> SSH and GPG Keys -> Add SSH Keyからcat id_rsa.pubをコピーペーストして登録します。
4. git lfsのインストール
git lfsをインストールします。
$ curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
$ sudo apt-get update
$ sudo apt-get install git-lfs
$ git lfs install
$ git lfs --version
git-lfs/3.6.1 (GitHub; linux arm64; go 1.23.3)
5. リポジトリclone
こちらのリポジトリのgemma-3-1b-gguf-with-raspberrypi-5ブランチをcloneします
$ git clone -b gemma-3-1b-gguf-with-raspberrypi-5 git@github.com:nijigen-plot/personal-knowledge-base.git
$ cd personal-knowledge-base
$ uv sync
$ touch history.txt
6. google/gemma-3-1b-it-qat-q4_0-ggufのclone
google/gemma-3-1b-it-qat-q4_0-ggufをcloneします
$ git clone git@hf.co:google/gemma-3-1b-it-qat-q4_0-gguf
動作
$ uv run python gemma3-1b-q4-gguf.py プロンプトでAIと会話できます!
履歴保存機能
history.txtに自分の質問を保持しておき、systemに事前に入れるようにしました。
if os.path.exists(HISTORY_FILE):
with open(HISTORY_FILE, "r", encoding="utf-8") as f:
# https://gemma-llm.readthedocs.io/en/latest/colab_tokenizer.html?utm_source=chatgpt.com
# 単語でトークンカウントしているので、文字数でn_ctxの数だけ読む分にはまずオーバーしないはず
memory_file = f.read()
memory = memory_file[-n_ctx:]
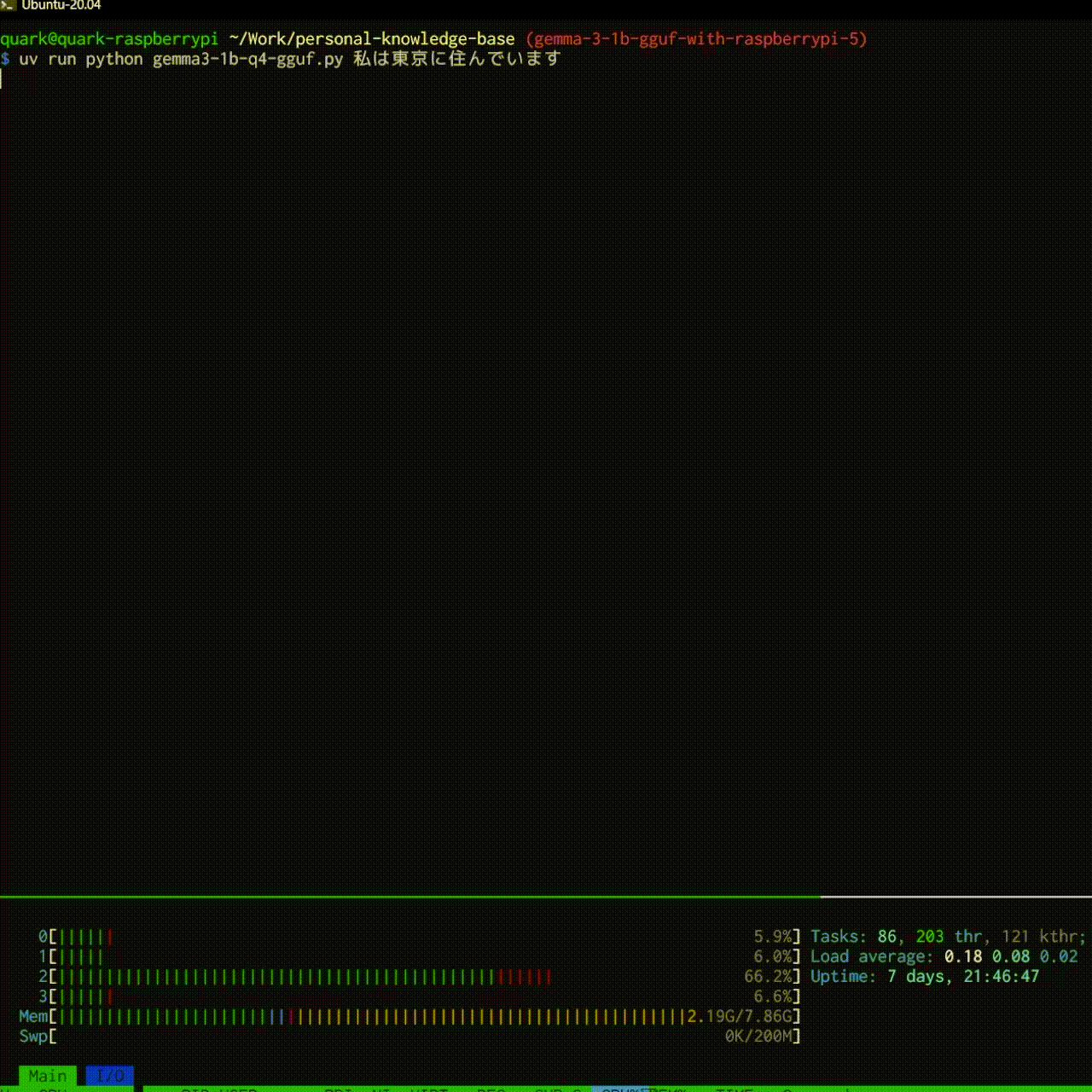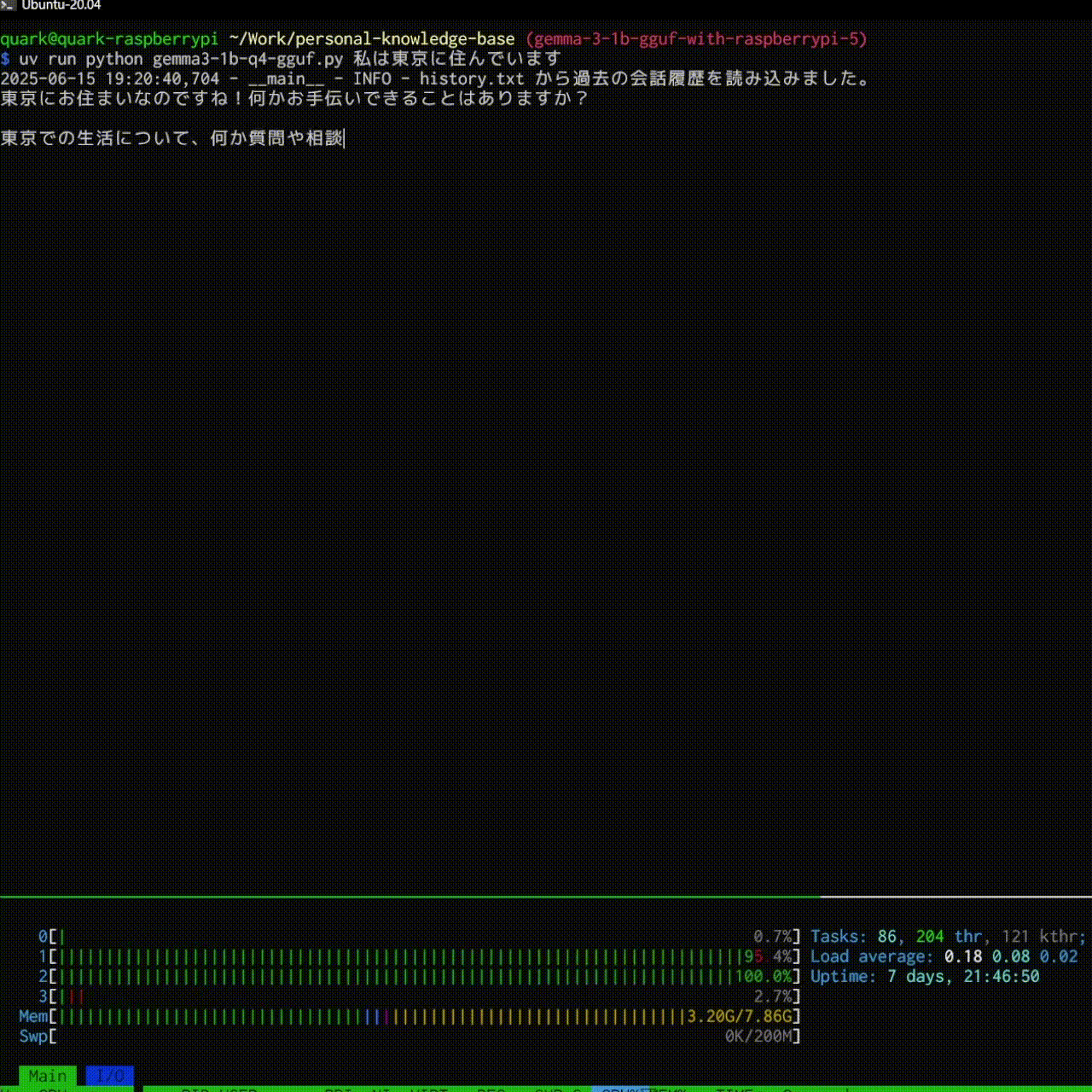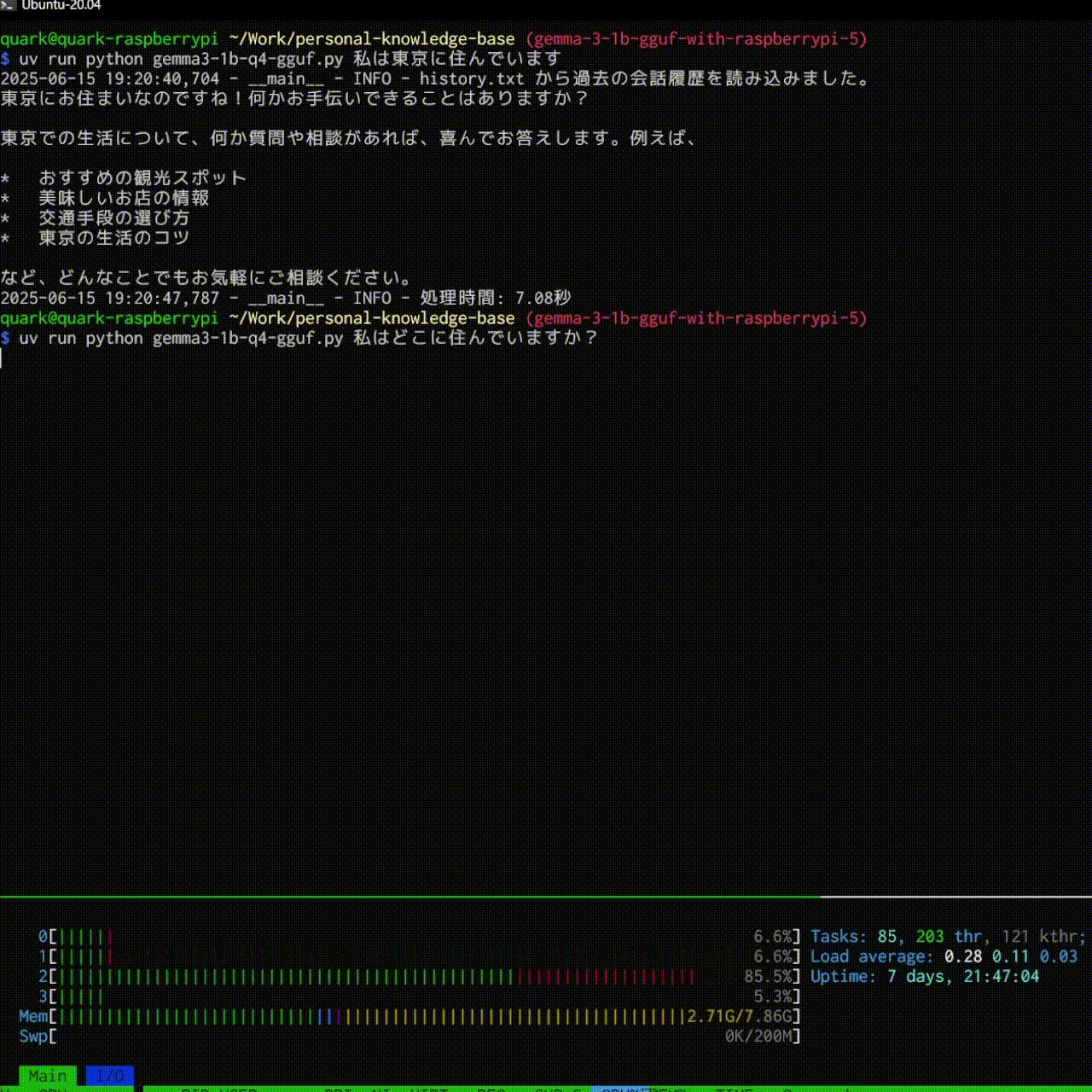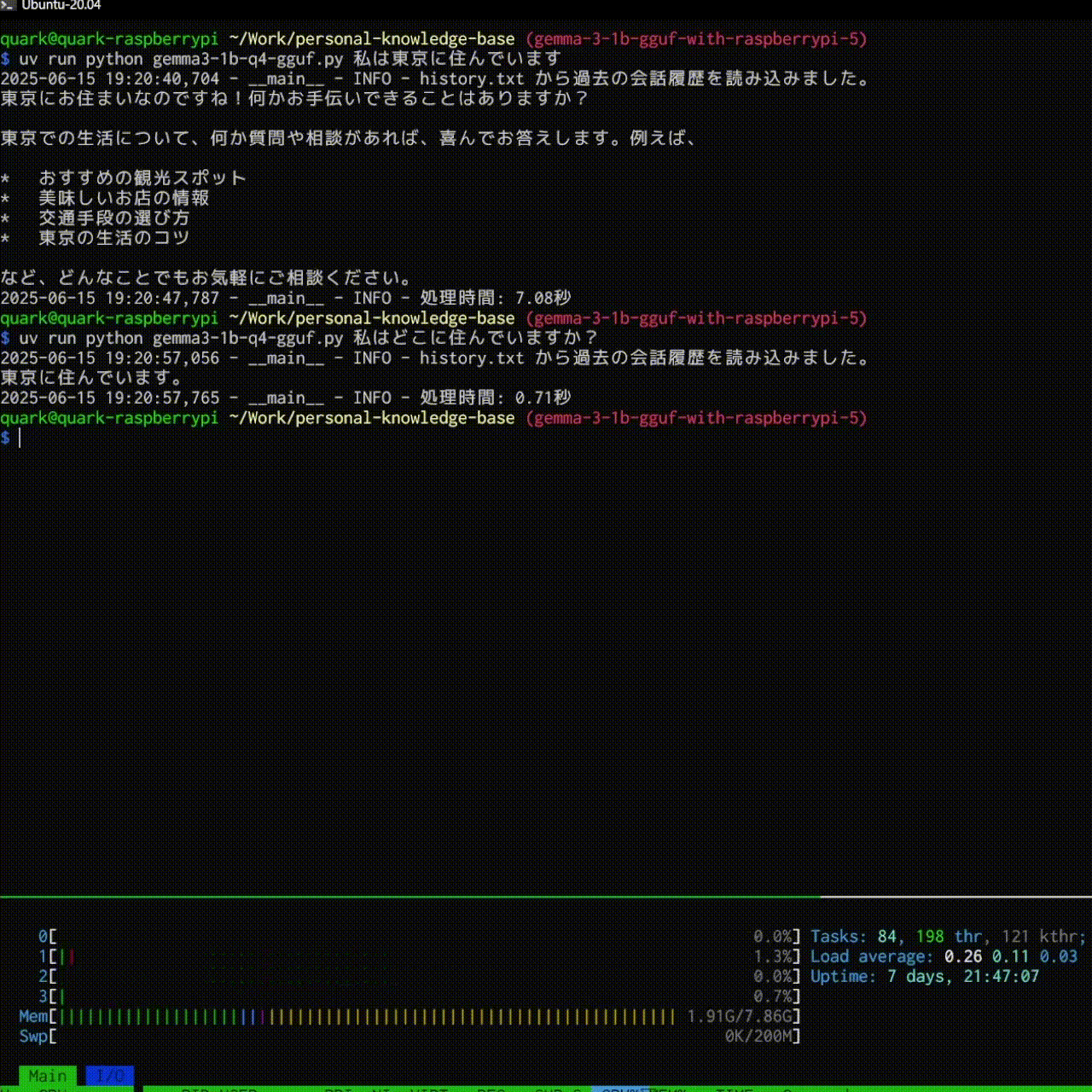
logger.info(f"{HISTORY_FILE} から過去の会話履歴を読み込みました。")
else:
logger.info(f"{HISTORY_FILE} が存在しないため、過去の会話履歴は考考されません。必要な場合は{HISTORY_FILE} を作成してください。")
memory = ""
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": f"あなたは日本語を話すAIアシスタントです。"},
{"type": "text", "text": f"以下は過去の会話情報です。必要だと思った場合は活用し、そうでない質問の場合は活用しないでください。\n {memory}"}
],
},
{
"role": "user",
"content": [
{"type": "text", "text": prompt}
]
}
]
Gemini,Gemma等GoogleのLLMはトークンのカウントが単語レベルの為、n_ctx(入力トークン)の値だけテキストから文字列を取得する分には、おそらくオーバーしないだろうと思っています。
Gemini モデルの場合、1 個のトークンは約 4 文字に相当します。100 個のトークンは、約 60 ~ 80 ワード(英語)に相当します。
これで、過去の会話をもとに返事を返してくれるようになります
ストリーミング出力
滑らかな文字の出力については、create_chat_completionメソッドのstreamをTrueにし、以下のif文のように差分をprint()しています。flush=Trueで即時出力されるためより滑らかになります。
resp = llm.create_chat_completion(
messages=messages, max_tokens=max_tokens, stream=stream, temperature=0.3
)
if stream:
partial_message = ""
for msg in resp:
message = msg["choices"][0]["delta"]
if "content" in message:
content = message["content"]
print(content, end="", flush=True)
partial_message += content
print()
else:
content = resp["choices"][0]["message"]["content"]
print(content)
end = time.perf_counter() - start
logger.info(f"処理時間: {end:.2f}秒")
save_memory(prompt)
gguf形式について
同じgemma 3 1bにgoogle/gemma-3-1b-itというモデルがありますが、今回はgoogle/gemma-3-1b-it-qat-q4_0-ggufを使っています。
これはllama.cppというLLMの推論に特化したC/C++フレームワークで、google/gemma-3-1b-itで使われているSafetensors形式よりも高速に実行できます。llama.cppで使用する形式が.ggufです
qat-q4_0の部分は量子化についての記載で、bit数と種類で細かいルールがあるようです。
とりあえずgoogle/gemma-3-1b-itより精度低下しますが、軽くて速いのでgemma-3-1b-it-qat-q4_0-ggufを使っています。
結果
想像以上に性能と速度が両立されていて、とても感動しました!
ベクトルDBと併せて完全ローカルでナレッジベースもいけそうです。
実はGemma 2の時から「Raspberry Pi 4を使って動かしてみた」系記事があったのでGemma 3で試してみたのですが、十分に使えましたね。
常に最新情報を追っているわけではないので、もし間違いやアドバイス等あればコメントいただけますと嬉しいです。
参考