こんにちはみなさん
まあ、大みそかのいい時間ですが、最近がテレビも見なくなって久しく、何か娯楽ないかなぁとうろうろしていたところ、Qiitaの記事が99だったので、せっかくだから適当なランキングでも作って、これまでを振り返ろうかなって思った次第。
データの整形はpandasとか使えばすぐなんで、ちょろちょろっとやりました。
そんなに役には立たんと思いますが、お暇な方は読んでもらえればありがたいです。
データを取得する
今回はデータの取得から整形までをするのにPythonとPandasを使うので、手っ取り早く使うには、google colaboratoryを使うことにします。こいつはWeb上で使えるJupyterなんで、お手軽にデータ処理したいなら、これを使うのが便利です。
一覧取得
まずは、自分の記事データをAPIを使って引っこ抜いてきます。
ここでは、自分の記事を一覧取得するAPIを使います。
import requests
import json
import pandas as pd
url = 'https://qiita.com//api/v2/authenticated_user/items?per_page=100'
header = {
'Content-Type': 'application/json',
'Charset': 'utf-8',
'Authorization': f'Bearer {token}'
}
res = requests.get(url=url, headers=header)
tokenは https://qiita.com/settings/applications で取得しておきます。
これを実行すると、resの中にデータjsonで詰まっています。詳しいレスポンスはAPIの仕様書を見てください。
詳細データを取得する
ところで、このAPIで自分の記事一覧を持ってきても、なぜかpage_views_countがNoneで返ってくるので、これを得るには自分の記事を個別にとって来る必要があります。
ということで、個別取得のAPIを使って各々のデータを取得します。
data = res.json()
item_list = []
url = 'https://qiita.com//api/v2/items/'
header = {
'Content-Type': 'application/json',
'Charset': 'utf-8',
'Authorization': f'Bearer {token}'
}
for item in data:
target = url + item['id']
res = requests.get(url=target, headers=header)
item_list.append(res.json())
これで、99個のデータを個別にとって来るという、若干はた迷惑な行為を経て、必要なデータをそろえることができました。
データを整形する
データがそろったので、pandasでデータを整形します。
df = pd.json_normalize(item_list)
df['view_like_rate'] = df['likes_count']/df['page_views_count']
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 1000)
df.plot.scatter(x='page_views_count', y='likes_count')
これで、以下のようなグラフがゲットできます。
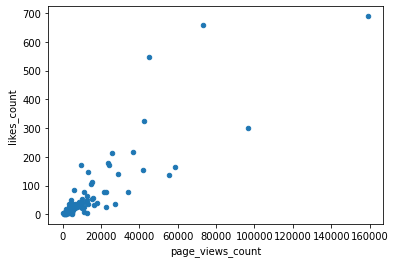
このグラフから、まあ、当たり前のことですが、page_view_count(閲覧数)とlikes_count(LGTM数)には強い相関があって、相関係数も0.855825という高い数値を出しています。
ランキング
とまあ、ここまでは本来はただのおまけで、私にとってはここからが本題なわけですが、一部の人にとってはここからがおまけとなります。
LGTM数
contributionに寄与するLTGMの数をランキングにします。
最も評価をしてもらっている記事のランキングとみてもいいでしょう。
subdf = df.sort_values('likes_count', ascending=False)
print(subdf[['id', 'title', 'likes_count']])
| 順位 | タイトル | LGTM数 |
|---|---|---|
| 1 | PHP開発でComposerを使わないなんてありえない!基礎編 | 689 |
| 2 | Docker導入のための、コンテナの利点を解説した説得資料 | 660 |
| 3 | コンテナ開発の始め方 | 547 |
| 4 | Laravelでテストコードを書くためのチュートリアル | 326 |
| 5 | ES6の新機能: 「let」「const」宣言を調べてみた | 299 |
あれ?いつの間にか「PHP開発でComposerを使わないなんてありえない!基礎編」が一位になっている。逆転したんですねぇ。
とりあえず、一個ずつふりかえります。
PHP開発でComposerを使わないなんてありえない!基礎編
composerを使っていないレガシーシステムに我慢できなかったのか、怒りのあまり書いた記事ですね。
zip解凍したコードをまるごとgitに突っ込むっていう無茶をしていたので、こういう風にやるといいんだ!って、書いて、会社に押し付けようとしていますね、これ。
一時期、googleのスニペットに出たりもしていた。
ちなみに、これの続編は全然人気ないです。
Docker導入のための、コンテナの利点を解説した説得資料
当時コンテナに凝っていた自分が、別プロジェクトの同僚にコンテナ開発・コンテナ運用をお勧めするために書いたやつです。
初日は大した反応なかったんですが、なぜか爆発的にバズっちゃった記憶があります。
説得するための資料なので、本当にまじめに書いています。
はてぶで「こんなに単純ではない」と書いていた人がいましたが、まあ、大体わかればいいという感じで書いたやつです。
コンテナ開発の始め方
またコンテナの話で、かつスライドです。
これ書いた当時も、結構vagrant + virtual box が結構あったので、コンテナでやろうぜって勉強会で発表するように資料作って、せっかくだからQiitaに乗っければいいねも稼げるやろっていうゲスな考えで書いたんじゃないかなって思います。
Laravelでテストコードを書くためのチュートリアル
Laravelのrequest-responseのテストがやりやすかったので、それを記事化したやつです。
当時は会社にテスト書く文化が全然入っていなくて、あかんなって思っていたのと、自分の案件がperlで、request-responseのテストをしていたので、似たようなものないかなって思ってたら、Laravelにあって感動したものです。
既存アプリをLaravelで全部書き直したりとアグレッシブな時期でした。
ES6の新機能: 「let」「const」宣言を調べてみた
なんでこれがランクインしたのかよくわからんです。
当時はjavascriptの勉強していて、新しい仕様での書き方を勉強していたのですが、変数の宣言が複数あるという事態に遭遇し、そも、PHPであまり変数宣言に頓着していなかったので、新鮮な気持ちになって、勉強がてら書いた記事ですね。
今でもちょいちょいLGTMがついてきます。
閲覧数
次は閲覧数を見てみます。
閲覧数は主に検索流入によって増えるものです。
つまり、記事の内容がそれだけ検索ワードに引っ掛かりやすかったということですね。
| 順位 | タイトル | 閲覧数 |
|---|---|---|
| 1 | PHP開発でComposerを使わないなんてありえない!基礎編 | 158954 |
| 2 | ES6の新機能: 「let」「const」宣言を調べてみた | 96796 |
| 3 | Docker導入のための、コンテナの利点を解説した説得資料 | 73117 |
| 4 | ES2015新機能: JavaScriptのclassとmethod | 58419 |
| 5 | 時系列予測を一次元畳み込みを使って解く with Keras | 55659 |
composer圧倒的ですね。こんなに多かったんだ。。。
JavaScriptの勉強開始時に書いた記事が結構入っていて、みんな同じように検索するのかねぇと思いました。
というわけで、初めて出てきた記事にコメントしていきましょう。
ES2015新機能: JavaScriptのclassとmethod
JavaScript系の話は結構検索流入稼げるのでは疑惑ですね。
これもLGTM数のやつで見た「ES6の新機能: 「let」「const」宣言を調べてみた」と同じ時期に書いたやつです。
当時はついにJavaScriptでclassがかけるぞ!みたいな謎テンションだったと記憶しています。
PHPと同じような感覚で書けるのかと思いきや。。。といった感じでした。
この記事からES6をES2015に言い直しています。
時系列予測を一次元畳み込みを使って解く with Keras
何とかして音の波形を学習して、音楽ジェネレータを作りたいと考えていた時に、それなりに高速で計算でき、波形をパターンで把握するという考え方で、音楽に通じるのではないかと考えて、その検証として書いたやつです。
機械学習についてはずぶのド素人が書いた記事なので、検索流入された方には申し訳なかったです。
LGTM数/閲覧数
閲覧したけどLGTMしなかったってことは、その記事にそれほど価値がなかったということかもしれません。
というわけで、閲覧して、さらにLGTMが来やすかった記事を見てみましょう。
subdf = df.sort_values('view_like_rate', ascending=False)
print(subdf[['title', 'view_like_rate', 'likes_count', 'page_views_count']])
| 順位 | タイトル | LGTM率 | LGTM数 | 閲覧数 |
|---|---|---|---|---|
| 1 | PHP7.4のpreloadいれたらLaravelは早くなるのだろうかと思って検証した | 0.017831 | 171 | 9590 |
| 2 | デバッグ用にechoやprint_rを書く代わりにテストを書こう | 0.014663 | 86 | 5865 |
| 3 | コンテナ開発の始め方 | 0.012155 | 547 | 45003 |
| 4 | [検証] コードをもとにコードを書くコードを書きたい ~ interfaceから実装を作る | 0.011628 | 3 | 258 |
| 5 | ES2015新機能:ジェネレータをマスターしたい | 0.011559 | 35 | 3028 |
意外と新顔が多い。
基本的にview数が少ないのが多いので、ターゲットが狭く絞られた結果、LGTMが付きやすくはなったといった感じでしょうか。
コンテナ開発の始め方だけ閲覧数もLGTM数も多いですが、検索で見た結果に満足してくれたのでしょうかね。
初めて出てきた記事にちょっとコメントします。
PHP7.4のpreloadいれたらLaravelは早くなるのだろうかと思って検証した
これはもう、PHP7.4を使いたかっただけですね。
preloadが入ったことで、あらかじめ指定したファイル群が読み込み済み状態になるので、ファイルを見たり、タイムスタンプでキャッシュを見たり見なかった理を判断しなくていいからきっと早いんじゃないかって思って、やったやつです。
コンテナ使っているなら、起動時に使うに限りますね。
デバッグ用にechoやprint_rを書く代わりにテストを書こう
当時の社内で、口酸っぱくテスト書けと言っていた時に、書いた記事を武器にして、さらにテストを書くように迫っていた時代の産物です。
echoとかprint_rとかvar_dumpとかするけど、それ、記録残らないんで、記録残すようにしましょうっていうやつです。
逆に言えば、デバッグやっているってことは、多かれ少なかれ、みんなテスト書いてるんですよね。
残らないだけで。
[検証] コードをもとにコードを書くコードを書きたい ~ interfaceから実装を作る
これは最近の記事ですね。
とにかくコードを書く時の物量が多くて、ロジックが面倒というよりも新機能作成時のファイル作成で時間を使いまくるのが嫌で、ジェネレータを書きたいなぁって思って作った記事ですね。
世の中いろんなアーキテクチャありますけど、ファイル量が増える場合は、ジェネレータ作っておくといいです。
単純作業になるとマジでつらいんで。
ES2015新機能:ジェネレータをマスターしたい
まだJavaScriptにジェネレータが来たばかりの頃ですね。
このころにはPHPにもジェネレータがあったとは思いますが、こいつが何者なのか理解したくて書いた記事ですね。
ES6がES2015になったとかで、地味に追随していますね。
まとめ
ということで、100記事目かつ今年最後の記事でしたので、何かしら記念ぽい雰囲気を出してみました。
これ見て役に立つかどうかはわかりませんが、自身の記事のふりかえりをやってみるのもよいのではないでしょうか。
今回はこんなところです。