もうとっく19日を過ぎていますが、空いていたのでぶっこみました(内容も詰め込みました)。
今回は、BigQueryのJSON型と検索インデックスに関して(比較的)詳細に調べたので説明していきたいと思います。
具体的には以下について説明します。
- BigQueryでJSON型を扱う方法
- 検索インデックス
-
SEARCH関数 - 検索インデックスのパフォーマンス検証
最後のパフォーマンス検証は割と必見ですが、その他の3項目については、詳細に説明していて文量が多いため、適宜興味のあるところを読んでいただけたらと思います。
要点
本記事の重要な点をかいつまむと以下のようになります。
- JSON型の操作について
- ドット演算子で簡単にフィールドにアクセスできるが、そのままではJSON型のため、他の型として扱いたい場合は、
JSON_VALUE関数などを用いて変換する - 数値は(意図せず)丸められる可能性があるため、精度を保証したい場合は、独立のカラムとして保持させる
- ドット演算子で簡単にフィールドにアクセスできるが、そのままではJSON型のため、他の型として扱いたい場合は、
- 検索インデックスと
SEARCH関数について- 検索インデックスは論理サイズで10GB以上のテーブルにしか作成されず、
SEARCH関数による検索のみを最適化する
テキストアナライザとして、'LOG_ANALYZER'を使うと、検索対象、検索文字列がトークンに分解され、トークン単位での検索となる (部分一致検索に近い) -
SEARCH関数による検索は、STRING型、ARRAY型、JSON型に対して行える。後ろ2つの検索結果は、どれかの要素で検索がヒットした場合にヒットとなる -
SEARCH関数を使う場合は、コストと処理速度の両面から、検索インデックスを作成した方が良い - 特に、様々なシステムからのログを単一のテーブルにまとめて分析するというシナリオで有用そう
- 検索インデックスは論理サイズで10GB以上のテーブルにしか作成されず、
次節以降で詳細に説明していきたいと思います。
半構造データ(JSON型)
もともと、JSONLファイルの読み込みには対応していましたが、データをJSON型としてそのまま持てるようになりました。
JSON型を扱うための関数や演算子が用意されているので、それらについて説明したいと思います。
JSON型の操作
JSONリテラル
JSONリテラル(定数)は、JSON 'JSON形式の文字列'のように指定します。
簡易的なSQLの説明で扱いやすく、今後の例で多用します。
select json '{ "key1": "value", "key2": 10 }' as json_value
+----------------------------+
| json_value |
+----------------------------+
| {"key1":"value","key2":10} |
+----------------------------+
フィールドへのアクセス (ドット演算子, 添字演算子, JSON_QUERY関数)
JSONの要素にアクセスしたい場合に、ドット演算子(フィールドアクセス演算子)もしくはJSON添字演算子を用います。
下例のように、フィールドが存在しない場合はNULLが返ってきます(エラーにはなりません)。
select json_value.class.students[0]['name'] as first_student
from
unnest([
json '{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}}'
, json '{"class" : {"students" : []}}'
]) as json_value
+---------------+
| first_student |
+---------------+
| "John" |
| NULL |
+---------------+
JSON_QUERY関数でも同様のことができ、第2引数にJSONPath形式の文字列を指定してフィールドを抽出することができます。
$がルートを表し、.もしくは[]を使ってフィールドにアクセスします。
select json_query(json_value, ‘$.class.students[0].name’) as first_student
from
unnest([
json '{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}}'
, json '{"class" : {"students" : []}}'
]) as json_value
+---------------+
| first_student |
+---------------+
| "John" |
| NULL |
+---------------+
フィールドを別の型として扱う (JSON_QUERY_ARRAY関数, JSON_VALUE関数, 明示的な型変換関数)
ドット演算子等で抽出した値はJSON型のため、抽出値を配列として扱いたい場合は、JSON_QUERY_ARRAY関数を使う必要があります。
with json_data as (
select json '{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}}' as json_value
)
select
students.name as name
from
json_data
, unnest(json_query_array(json_value.class.students)) students
+---------+
| name |
+---------+
| "John" |
| "Jamie" |
+---------+
次の例のように配列に変換しない場合では、エラーとなります。
with json_data as (
select json '{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}}' as json_value
)
select
students.name
from
json_data
, unnest(json_query_array(json_value.class.students)) students
Values referenced in UNNEST must be arrays. UNNEST contains expression of type JSON at [8:12]
同様に、配列型以外の場合も、明示的な型変換関数(私の方で勝手に呼んでいます)もしくは、JSON_VALUE関数を使う必要があります。
対応している型は、以下の通りです。
- STRING
- BOOL
- INT64 (正確にはもう少し広い)
- FLOAT64
まず、JSON_VALUE関数に関しては、以下の特徴があります。
- 数値は丸められる (整数の許容範囲を超えるとFLOAT64に丸められる) → 下の注意点を参照
- 変換元が配列またはJSON型の場合は、
NULLを返す
具体的な変換結果は、以下のようになります。
select
json_value(json_data.type) as json_value_type
, json_value(json_data.value) as json_value
from
unnest([
json '{"type" : "STRING", "value" : "BigQuery"}'
, json '{"type" : "BOOL", "value" : "TRUE" }'
, json '{"type" : "INT64", "value" : 2022 }'
, json '{"type" : "FLOAT64", "value" : 123.45 }'
, json '{"type" : "SMALL NUMBER", "value" : 1.0000000000000001 }'
, json '{"type" : "HUGE INTEGER 1", "value" : 18446744073709551615 }'
, json '{"type" : "HUGE INTEGER 2", "value" : 18446744073709551616 }'
]) as json_data
+-----------------+------------------------+
| json_value_type | json_value |
+-----------------+------------------------+
| STRING | BigQuery |
| BOOL | TRUE |
| INT64 | 2022 |
| FLOAT64 | 123.45 |
| SMALL NUMBER | 1.0 |
| HUGE INTEGER 1 | 18446744073709551615 |
| HUGE INTEGER 2 | 1.8446744073709552e+19 |
+-----------------+------------------------+
また、明示的な型変換関数では、最初にあげた型のそれぞれに対応する関数が用意されています(STRING, BOOL, INT64, FLOAT64)。
例えば、以下のように明示的にINT64型に変換することで和を取ることが可能になります。
with json_data as (
select
json '20' as a
, json '30'as b
)
select int64(a) + int64(b) as a_plus_b
from json_data
+----------+
| a_plus_b |
+----------+
| 50 |
+----------+
ただし、無効な型を指定すると以下の通りエラーとなります。
select int64(json '2022.1') as year
The provided JSON number: 2022.1 cannot be converted to an integer
FLOAT64関数のみ、名前付き引数のwide_number_modeを使用できます。
exactもしくはround(デフォルト)を指定でき、exactを指定した場合、精度を失ってしまう変換はエラーを返します(おそらく型チェックに使えると思われます)。
select float(json '123.45', wide_number_mode=>'exact') as result
+--------+
| result |
+--------+
| 123.45 |
+--------+
使い分けについて、明示的に型指定をする必要がある場合以外は、JSON_VALUE関数を使えばいいと思います(そのまんま、、、)
JSON_QUERY_ARRAY関数、JSON_VALUE関数については、ドット演算子の代わりにJSONPath形式を使うこともできます(ドット演算子との併用も可能です)。
with json_data as (
select json '{"class" : {"students" : [{"name" : "John"}, {"name": "Jamie"}]}}' as json_value
)
select
json_value(students, ‘$.name’) as name
from
json_data
, unnest(json_query_array(json_value, ‘$.class.students’)) students
JSON型を文字列に変換する (TO_JSON_STRING関数)
JSON型の変数を文字列型として扱いたい場合は、TO_JSON_STRING関数を使います。
第2引数にTRUEを指定すると、整形された形式で出力されます。
select to_json_string(json '{ "key1": "value", "key2": 10 }', true) as json_string
+--------------------+
| json_string |
+--------------------+
| { |
| "key1": "value", |
| "key2": 10 |
| } |
+--------------------+
JSON型同士の比較はできないので、比較したい場合は、文字列に変換してから行うと良いと思われます(メンバーの順序など不確定要素が多いので、推奨される方法ではありません)。
with json_data as (
select
json '20' as a
, json '20' as b
)
select to_json_string(a) = to_json_string(b) as result
from json_data
+--------+
| result |
+--------+
| true |
+--------+
JSON型を得る (PARSE_JSON関数, TO_JSON関数)
JSON形式の文字列型からJSON型に変換する場合は、PARSE_JSON関数を使います。
with json_data as (
select '{"name" : "niiiiishiii"}' as json_string
)
select
parse_json(json_string) as json_from_string
from
json_data
+------------------------+
| json_from_string |
+------------------------+
| {"name":"niiiiishiii"} |
+------------------------+
一方、SQLの結果をJSON型に変換する場合は、TO_JSON関数を用います。なお、下例のように、複数のJSONキーを指定する場合は、結果がSTRUCT型である必要があります。
select
to_json((
select as struct
'niiiiishiii' as name
, 'firefish.jp' as homepage
)) as json_from_query
+-------------------------------------------------+
| json_from_query |
+-------------------------------------------------+
| {"homepage":"firefish.jp","name":"niiiiishiii"} |
+-------------------------------------------------+
注意点
- 数値については、-9,223,372,036,854,775,808 ~ 18,446,744,073,709,551,615の範囲の整数と、FLOAT64 のドメイン内の浮動小数点を格納可能
- 数値は上記の許容範囲を超えた場合は丸められるため、正確な値を格納したい場合や数値の精度を保証したい場合は、JSON型ではなく、適切な数値型を選んだカラムとして格納すべきである(丸めのせいで想定外の誤差が生じる可能性もある)。
検索インデックス(search index)
SEARCH関数を使った検索を効率化するためのものとして、検索インデックスが使用できます。
効率化の対象はSEARCH関数による検索のみであり、=を使った検索などの通常の検索は効率化されません。
SEARCH関数は次節で説明します。
作成対象とアナライザ
検索インデックスは以下のカラムに対して作成することができます。
- STRING型
- ARRAY<STRING>型
- STRUCT<ARRAY<STRING>, INT64>型、STRUCT<ARRAY<ARRAY<STRING>, INT64>, INT64>型等、STRING型やARRAY<STRING>型を含むSTRUCT型
- ただしこの場合は、インデックスを作成したSTRUCT型のカラムではなく、構造体のフィールド内の全てのSTRING型または、ARRAY<STRING>型にインデックスが作成される
- JSON型
さらに、インデックス作成時に、以下の2つの中からテキストアナライザ(テキスト分析ツール)のタイプを指定できます。
-
'LOG_ANALYZER'(デフォルト)- テキストにトークン化・正規化が行われる(詳細は、SEARCH関数を使った検索を参照)
- トークン化・正規化が行われた後のテキストに対して検索が行われるため、たとえば完全一致文字列の他に、部分一致文字列がヒットする
-
'NO_OP_ANALYZER'- 完全一致の検索を行いたい場合に使用する
- テキストにトークン化・正規化が行われず、完全一致での検索のみ行える
インデックスの作成
CREATE SEARCH INDEXステートメントを使って作成します。
作成時に、インデックスを付与するカラムを明示的に指定するか、ALL COLUMNSを指定して、インデックスの作成が可能な全カラムにインデックスを作成します(以降のSQLでは、test_search_indexデータセットを作成済みとしています)。
create or replace table test_search_index.simple_table (
a string
, b int64
, c json
, d struct<
e int64
, f string
, g array<string>
>
)
;
create search index simple_index
on test_search_index.simple_table(a, c, d)
options (analyzer = 'NO_OP_ANALYZER')
;
インデックスの削除
DROP SEARCH INDEXステートメントを使って削除します。
テーブル名を変更することでも(自動で)削除できます。
drop search index simple_index on test_search_index.simple_table
インデックスの情報を取得する
[プロジェクト名].[データセット名].INFORMATION_SCHEMAの以下のビューで情報が確認できます。
INFORMATION_SCHEMA.SEARCH_INDEXESビュー
データセットに作成された各検索インデックスに関する情報を確認できます。
以下のSQLでは、インデックスの作成状況と課金対象の論理バイト数を確認しています。空テーブルにインデックスを作成したため、TEMPORARILY DISABLEDとなっています。
select
table_name, index_name, index_status, coverage_percentage, total_logical_bytes
from
test_search_index.INFORMATION_SCHEMA.SEARCH_INDEXES
+--------------+--------------+----------------------+---------------------+---------------------+
| table_name | index_name | index_status | coverage_percentage | total_logical_bytes |
+--------------+--------------+----------------------+---------------------+---------------------+
| simple_table | simple_index | TEMPORARILY DISABLED | 100 | 0 |
+--------------+--------------+----------------------+---------------------+---------------------+
INFORMATION_SCHEMA.SEARCH_INDEX_COLUMNSビュー
どのカラムにインデックスが作成されているかに関する情報を確認できます。
以下のSQLでは、インデックス作成時に指定されたカラムと実際にインデックスが作成されているフィールドの一覧を確認しています。
select
table_name, index_name, index_column_name, index_field_path
from
test_search_index.INFORMATION_SCHEMA.SEARCH_INDEX_COLUMNS
+--------------+--------------+-------------------+------------------+
| table_name | index_name | index_column_name | index_field_path |
+--------------+--------------+-------------------+------------------+
| simple_table | simple_index | a | a |
| simple_table | simple_index | c | c |
| simple_table | simple_index | d | d.f |
| simple_table | simple_index | d | d.g |
+--------------+--------------+-------------------+------------------+
料金・その他注意点
- アクティブなインデックスに対して、ストレージ料金(テーブルに対するものと同様)が課される
- 10GB未満のテーブル(論理バイト数換算)に対してインデックス作成(
CREATE SEARCH INDEX)を行なっても、インデックスの生成は行なわれず、テーブルサイズが10GB未満になると、インデックスが無効になる - 共有スロット(オンデマンド分析)でインデックスを作成する場合は、インデックスの作成自体に料金はかからない(おそらく)が、スループットが保証されないため、一般的にインデックス作成に時間がかかる (実際、12GB程度のテーブルのインデックス作成に30分くらいかかった)
SEARCH関数を使った検索
SEARCH関数は、検索対象データに、指定した検索キーワードが含まれているかどうかを確認する関数です。
以下のように使います。
search(search_data, search_query, [analyzer=>analyzer_name])
search_dataが検索対象データで、search_queryが検索文字列となります。
search_queryには、STRINGリテラルしか指定できず、例えば以下のようなものは指定できないことに注意してください。
- 他のSTRING型カラム
- サブクエリの結果
検索インデックスと同様に、テキストアナライザとして、'LOG_ANALYZER'または、'NO_OP_ANALYZER'を選ぶことができますが、検索インデックスに指定したアナライザと同じ必要があります。上記式のanalyzerで指定します。
'LOG_ANALYZER'では、テキスト(search_data, search_queryの両方)を以下のように変換した上で検索を行います。
- 大文字(A-Z)を小文字に変換する(a-z)
- 区切り文字(
| . @など)でトークンに分解する
具体的な分解結果は以下のようになります。
-
FIREFISH.jp→firefish,jp -
hello.world@example.com→hello,world,example,com
さらに、検索文字列(search_query)においてのみ次のルールが適用されます。
- バッククオート
`を使える。バッククオート内の区切り文字ではトークン化・小文字化はされず、1つのトークンとして扱われる。バッククオートを検索したい場合はバックスラッシュでエスケープする(\`) - バッククォート内以外では、次の予約済み文字はエスケープする必要がある(エスケープしないとSQLエラーになる)
[ ] < > ( ) { } | ! ' " * & ? + / : = - \ ~ ^
具体的な分解結果は以下のようになります。
-
`Hello World` Japan→Hellow World,japan
'NO_OP_ANALYZER'では、上述の変換・ルールが適用されません。
また、検索インデックスを作成しなくてもSEARCH関数は使用できますが、検索インデックスの作成が可能なテーブルに対してはインデックスを作成しておいた方が良いと思います(具体的な理由は、検索インデックスのパフォーマンス検証を参照)。
STRING型の検索
テキストアナライザが、'LOG_ANALYZER'の時のSTRING型に対する検索では、検索対象文字列(search_data)が検索文字列(search_query)のすべてのトークンを含んでいるときにTRUEを返します。
具体的な結果は以下の表のようになります。
| No | 関数 | 結果 | 理由 |
|---|---|---|---|
| 1 | search('firefish.jp', r'firefish.jp') |
TRUE | 完全一致 |
| 2 | search('firefish.jp/company', r'firefish.jp') |
TRUE | 部分一致 |
| 3 | search('firefish.jp', r'firefish.jp\/company') |
FALSE | companyが存在しない |
| 4 | search('firefish.jp/company', r'company.jp\/firefish') |
TRUE | 順番は無関係 |
| 5 | search('firefish.jp/company', r'company.jp.firefish') |
TRUE | 区切り文字の種類は無関係 |
| 6 | search('firefish.jp/company', r'`jp/company` firefish') |
TRUE | トークンについて完全一致 |
| 7 | search('firefish.jp/company', r'`jp/` firefish') |
FALSE | 検索対象にjp/があるが、直後が区切り文字ではない |
| 8 | search('firefish.jp/ company', r'`jp/` firefish') |
TRUE | 検索対象において、jp/の後に区切り文字がある |
特に、No.7において、検索可能な全トークンは以下のようになるため、結果はFALSEとなります(jp/と完全一致のトークンを含んでいない)。
firefish, jp, company, firefish.jp, jp/company, firefish.jp/company
一方、No.8においては以下のように、検索可能な全トークンの中に、jp/が存在するため結果はTRUEとなります。
firefish, jp, company, firefish.jp, jp/, company (半角空白 → 全角空白としている), firefish.jp/, jp/ company, firefish.jp/ company
'NO_OP_ANALYZER'を使った場合は、完全一致のときに限りTRUEとなります(=を使った場合と同じ結果)。
こちらについても結果をまとめると以下のようになります。
| No | 関数 | 結果 | 理由 |
|---|---|---|---|
| 1 | search('firefish.jp', r'firefish.jp', analyzer=>'NO_OP_ANALYZER') |
TRUE | 完全一致 |
| 2 | search('firefish.jp', r'firefish/jp', analyzer=>'NO_OP_ANALYZER') |
FALSE | 区切り文字の概念はない |
| 3 | search('firefish.jp/company', r'firefish.jp', analyzer=>'NO_OP_ANALYZER') |
FALSE | 部分一致であるが、完全一致でない |
| 4 | search('firefish.jp/company', r'company.jp/firefish', analyzer=>'NO_OP_ANALYZER') |
FALSE | 順序も一致する必要がある |
ARRAY型の検索
配列要素のいずれかの検索結果がTRUEの場合にのみ、TRUEとなります。
具体的には以下のようになります。
| No | 関数 | 結果 | 理由 |
|---|---|---|---|
| 1 | search(['firefish.jp', 'firefish.jp/company'], r'company') |
TRUE | 2個目の要素がcompanyトークンを含んでいる |
| 2 | search(['firefish', 'firefish.jp'], r'company') |
FALSE | どちらの要素もcompanyトークンを含んでいない |
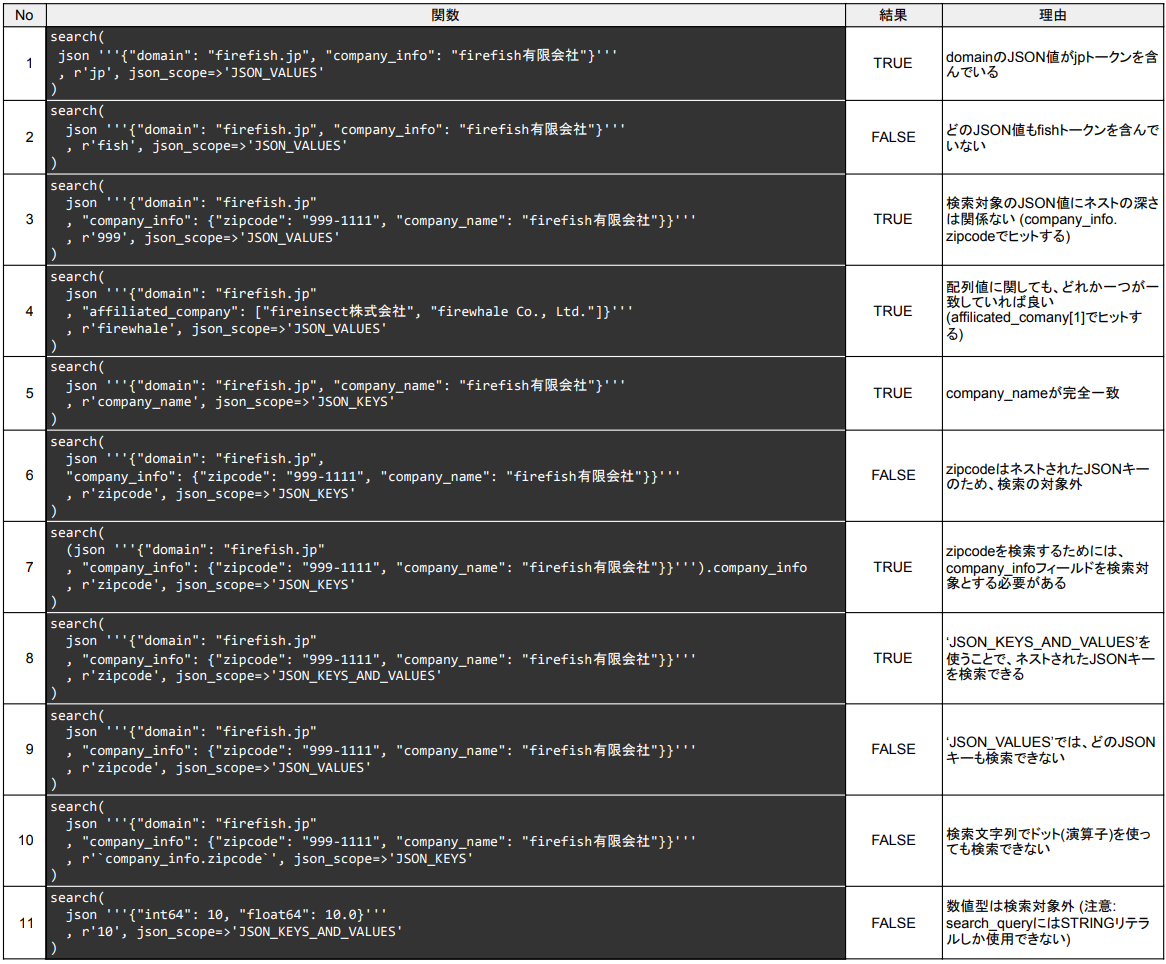
JSON型の検索
JSON型の検索の場合、以下のように名前付き引数のjson_scopeで検索範囲を指定できます。
search(search_data, search_query[, json_scope=>json_scope_value])
json_scopeには、以下の3つのうち1つを指定します。
-
'JSON_VALUES': JSON値のみを検索 (デフォルト) -
'JSON_KEYS': JSONキーのみを検索 -
'JSON_KEYS_AND_VALUES': JSONキーとJSON値の両方を検索
検索結果については、ARRAY型と同様で、どれか1つのJSON値またはJSONキー(検索範囲によって変わる)での検索結果がTRUEの場合に限り、TRUEとなります。
ただし、JSON_KEYSを選択した場合、一番外側のキーのみが検索対象となるため、ネストされたJSONキーを検索したい場合は、以下のいずれかを行う必要があります(下表No.6 ~ 10)。
- ドット演算子等を使って、ネストされたJSONキーを一番外側にする
-
'JSON_KEYS_AND_VALUES'を使う
また、数値型のJSON値(INT64, FLOAT64)は検索の対象外となります(下表No.11)。
おそらく、数値型を文字列表現にする際に曖昧さが残るからだと思われます(例: 10 = 1e2 = 10.0)。
具体的な検索結果は下表のようになります (表の中にコードブロックを埋め込めないため、画像としています)。
こちらのSQLで結果を確認できます。
検索インデックスのパフォーマンス検証
最後に、以下3つの検索に要した時間を実際に測ってパフォーマンスの検証を行ってみました。
- 単純な検索 (
=を使った検索) - SEARCH関数を使った検索
- SEARCH関数 + インデックスを使った検索
JSON型のデータとしては、システムのログが特に適していると思いますが、10GB以上のログデータがネットで見つからなかったので、以下のようなダミーデータを作って検証しました。
トピックを投稿するとそれに対するコメント、およびリアクションができるようなシステムのリクエストログを模倣しています。
| timestamp(マイクロ秒) | severity | body |
|---|---|---|
| 1670770800000000 (※日本時間で 2022-12-12 00:00:00) |
INFO | { "userId": "1234567890", "userIp": "1.1.1.1", "request": { … }, "response": { "status": "request" } } |
インデックス作成の条件を満たすために、11.8GB、1億行程度のダミーデータを作成しました。
パフォーマンス検証の結果は以下のようになりました。
それぞれ5回ずつ計測していて、時間については、平均値 (最小値 ~ 最大値) と表記しています。
作成方法はこちら
| 項目 | 単純検索 | SEARCH関数 | SEARCH関数 + インデックス |
|---|---|---|---|
| 処理時間(s) | 0.668 (0.614 ~ 0.721) |
7.225 (6.588 ~ 8.861) |
4.731 (4.141 ~ 5.411) |
| 消費したスロット時間(s) | 18.710 (17.370 ~ 21.074) |
1,542 (1,393 ~ 1,732) |
72.028 (62.505 ~ 86.002) |
| 課金対象のバイト数 | 11.806 GB | 11.806 GB | 0.616 GB |
この結果から、次のことがわかると思います。
- 単純な検索が一番早い
- インデックスを使うと検索速度が向上するのみならず、処理/課金対象のバイト数も大幅に減少している (特にスロット時間も大幅に減少しているため、インデックスを使用したほうが定額料金においてもコスト(=消費スロット数)の面で優れていると思われる)
検索の方法が、SEARCH関数と(=による)単純な検索で異なるので、比べるのはナンセンスな気もしますが、パフォーマンスの観点からのSEARCH関数の使い分けは以下のようになると思われます。
- 速度が重要な場合は、通常の検索を用いる
- なるべく安く検索したい場合は、インデックスを使った
SEARCH関数による検索を行う (インデックスに対するストレージ課金が発生するが、通常検索は何回も行われると思われるため、ストレージ課金によるデメリットをスキャンサイズ減少によるメリットが上回ると思われる)
一方、SEARCH関数の検索特性の観点からは以下のような使い分けとなりそうです。
- JSONの構造が(ほぼ)決まっていて、どのJSON値を検索したいかわかっている場合は、通常の検索を用いる
- JSONの構造が特に決まっていない、もしくは、複数のJSON値やJSONキーにわたって検索を行いたい場合は、
SEARCH関数を用いる
公式ドキュメントでは(検索インデックスの文脈ではありますが)、SEARCH関数の利用方法として以下のようなユースケースを紹介しています。
検索インデックスによって、BigQuery では、強力なカラム型ストアとテキスト検索が 1 つのプラットフォームで提供され、データの行を個別に検出する必要がある場合に効率的に行を検索できます。一般的なユースケースには、ログ分析があります。たとえば、一般データ保護規則(GDPR)の報告用に、ユーザーに関連付けられたデータの行を識別することや、テキスト ペイロード内の特定のエラーコードを検索することができます。
実際に、SEARCH関数の挙動とパフォーマンスを調べると以下のような状況でSEARCH関数(+JSON型)は特に有用と思われます。
- 一連の処理に関わる全てのログをBigQuery上の1つのテーブルにJSON型として保存する (タイムスタンプやログ取得元は別カラムとして持つ)
- 単一テーブルから以下のようなデータを抽出する
- 特定のリクエスト/処理に関わる全てのログ (リクエストIDで検索)
- 特定のユーザーに関わる全ての行動ログ (ユーザーID等で検索)
上記の状況では以下の利点が得られると思います。
- 取得元のシステムが異なるため、ログ(JSONデータ)はさまざまな構造を持つが、JSON型として、1つのテーブルの1つのカラムに保持できる
-
SEARCH関数を使えば、異なるシステム間のJSONキーの揺れ(requestId, request_id等)を気にすることなく検索ができる - 検索インデックスを付与することで、大量のログデータがあってもスキャンサイズ・使用スロット数が抑えられる
他方、条件を満たす件数を求める等の集計用途への使用にはあまり適切ではないと思われます。
最後に参考として、それぞれの検索で用いたSQLを以下に記します。
- 単純な検索 (
LIKE検索の方が、SEARCH関数による検索に近いが、処理時間に大きな差がなかったため、=を使った検索にしている)
select
*
from
test_search_index.request_log
where
json_value(body, '$.userId') = '10000001'
-
SEARCH関数を使った検索
select
*
from
test_search_index.request_log
where
search(body, r'10000001', json_scope=>'JSON_VALUES')
-
SEARCH関数 + インデックスを使った検索
select
*
from
test_search_index.request_log_index
where
search(body, r'10000001', json_scope=>'JSON_VALUES')
なお、処理時間計測前にインデックスの作成が完了していること、およびインデックスがアクティブになっていることは検証前に確認しています(インデックスを付与しているカラムと同程度のストレージ容量が課金される(total_logical_bytes)こともわかります)。
select
table_name, index_name, index_status, coverage_percentage, total_logical_bytes, total_storage_bytes
from
test_search_index.INFORMATION_SCHEMA.SEARCH_INDEXES
where
index_status = 'ACTIVE'
+-------------------+------------------------+--------------+---------------------+---------------------+---------------------+
| table_name | index_name | index_status | coverage_percentage | total_logical_bytes | total_storage_bytes |
+-------------------+------------------------+--------------+---------------------+---------------------+---------------------+
| request_log_index | performance_test_index | ACTIVE | 100 | 12957831405 | 2250901889 |
+-------------------+------------------------+--------------+---------------------+---------------------+---------------------+
最後に
BigQueryにおけるJSON型の扱い方とSEARCH関数を使った検索の挙動を説明し、インデックスのパフォーマンス検証の結果を紹介しました。
集計などの一般的な分析用途でSEARCH関数を使うことは厳しそうですが、ログ分析においては、インデックスと組み合わせて使うことで、コスト面とパフォーマンス面の両方で大きな恩恵を受けられそうです。
参考記事
- JSON型
- JSON型の演算
- インデックス
- インデックスの情報
- 検索関数