Unity上のキャラをリップシンクさせるには二通りあります。
1つ目はMMD4MecanmLipSyncPlugin、2つ目がOVRLipsyncを使う方法。
しかし、Oculusのほうが精度が高いと感じたため、今回はOVRLipsyncを使ってリップシンクさせる方法をまとめてみました。
こちらの記事を参考にさせていただいております。
http://tips.hecomi.com/entry/2016/02/16/202634
完成イメージ

用意するもの
OVRLipsyncをダウンロードして、空オブジェクトにアタッチする
OVRLipsyncをダウンロードしてインポートします。
そしたら空オブジェクトを作成しましょう。
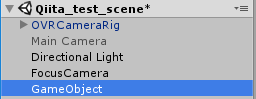
空のObjectにOVRLipSyncをアタッチ。
音声によって口の動きを変形させられるようにする
キズナアイ(3Dモデル)Objectに
OVRLipSyncContext ,
OVRLipSyncContextMorphTarget
をアタッチ。
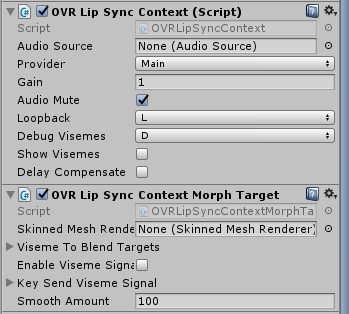
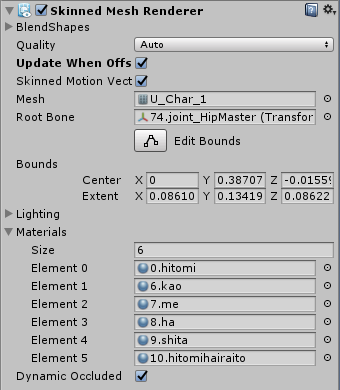
OVRLipSyncMorphTarget > Skinned Mesh Rendererに、頭のパーツを当てはめましょう。キャラによって違いますが、キズナアイの場合はU_char_1になります。
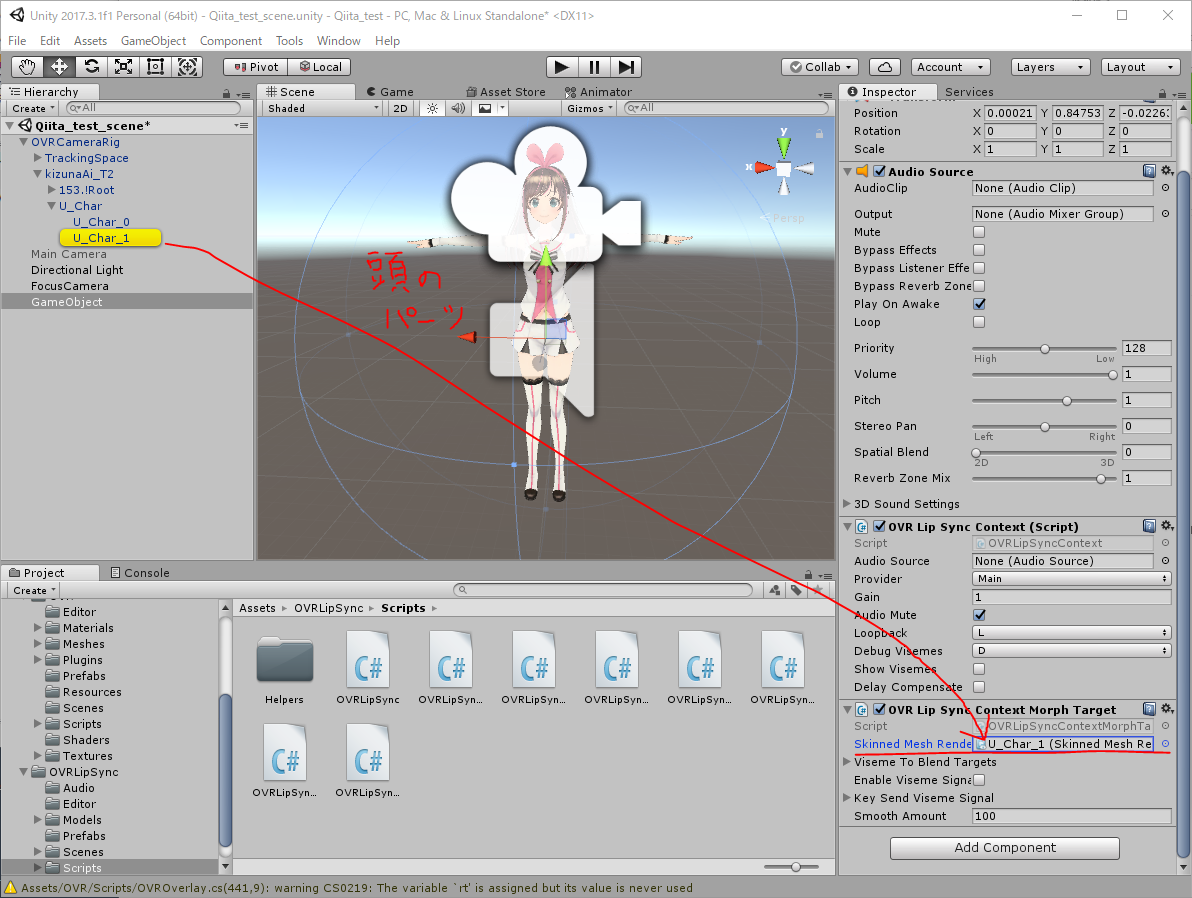
これによって、キズナアイのモーフを操れるようになりました。
もし「どれを当てはめるのか分からない!」という方は頭周辺のパーツを探りBlendShapesが付いているものを当ててみるといいかも。
次にOVRLipSyncMorphTarget > Viseme To Blend を開き、
Targetの母音部分を対象のモーフのインデックス番号を指定します。
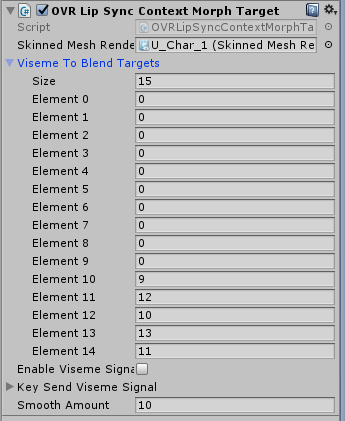
まず、Visme To Blendは15種類の口形素があります。(詳しくはこちらに載ってますが勉強する必要はありません)
0 sil(無音)
1 PP(p,m,b)
2 FF(f,v)
3 EH(@r)
4 DD(t,d)
5 kk(k,g,x)
6 CH(tS,S,Z)
7 SS(ts,s,z)
8 nn(n,l,r)
9 RR(@r)
10 aa(あ)
11 E(え)
12 ih(い)
13 oh(お)
14 ou(う)
例えば、「あ」と、発音したしたときに、Element10に当てはめたモーフのインデックス番号が反映される仕組みです。
モーフのインデックス番号はSkinned Mesh Renderer > BlendShapesから確認できます。
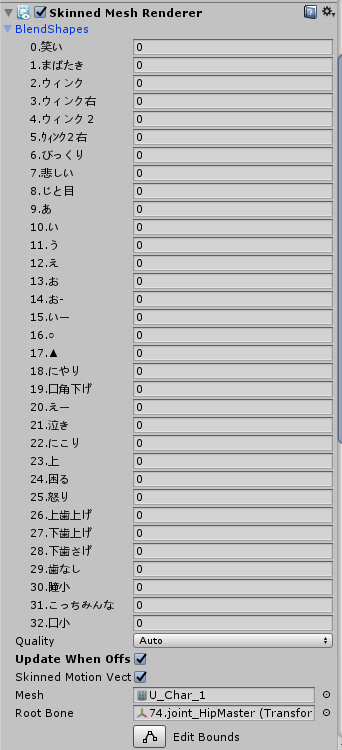
ここでは1~32がインデックス番号に当たり、その番号に対するモーフ(表情)がそれぞれ対応しています(キャラによって数が違う)
中でも、9 →「あ」、10 → 「い」 11 → 「う」12 → 「え」13 → 「お」となっていることに気づくと思います。
これらが、先程当てはめたモーフ番号になります。
つまり、現状ではこんな感じ。
| 発音 | インデックス番号 | 口の形 |
|---|---|---|
| 0 sil(無音) | 0 | |
| 1 PP(p,m,b) | 0 | |
| 2 FF(f,v) | 0 | |
| 3 EH(@r) | 0 | |
| 5 kk(k,g,x) | 0 | |
| 6 CH(tS,S,Z) | 0 | |
| 7 SS(ts,s,z) | 0 | |
| 8 nn(n,l,r) | 0 | |
| 9 RR(@r) | 0 | |
| 10 aa(あ) | 9 | あ |
| 11 E(え) | 12 | え |
| 12 ih(い) | 10 | い |
| 13 oh(お) | 13 | お |
| 14 ou(う) | 11 | う |
| 10 aa(あ)と発音したときに、9「あ」の口の形をする | ||
| 14 ou(お)と発音したときに、14「お」の口の形をする | ||
| といった感じです。 |
他にも、pp であれば「ポ」、FFなら「ファ」の発音になるので、それぞれの発音に対するモーフを当てはめていただけれければと。
次に、OVRLipSyncContextMorphTargetの**Update()をLateUpdate()**に変更しておきます。
void LateUpdate () {
if ((lipsyncContext != null) && (skinnedMeshRenderer != null)) {
// trap inputs and send signals to phoneme engine for testing purposes
// get the current viseme frame
OVRLipSync.Frame frame = lipsyncContext.GetCurrentPhonemeFrame();
if (frame != null) {
SetVisemeToMorphTarget(frame);
}
// TEST visemes by capturing key inputs and sending a signal
CheckForKeys();
}
}
マイクで入力させる
キズナアイ(モデル)にOVRLIpSyncMicInputをアタッチします。
そしたら常に音声を認識させられるように、Mic Controlの部分をConstantSpeadkにしておきます。
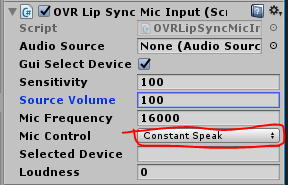
もし口の動きが小さくて分かりづらかったら、OVRLipSyncContext > Gainの値をお起きすると口が動きやすくなります。
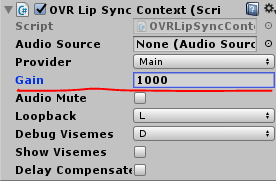
これで完成。
まとめ
Viseme To Blend Targetsでマイクから拾ってきた音を認識し、その音声に従ってSkinned Mesh Rendererのモーフが適応されているというイメージかと思います。
もし口が動かない場合は、他のデバイスが音声を拾っていないか、Gainの値が小さすぎないかを確かめていただければと。