はじめに
aucfan エンジニアの @ngok です。
aucfanでは、商品の売買データや在庫データなどを収集・分析して、保有している在庫の価値を診断しています。
数十万商品について数百店舗の情報を日次で取込み、1日当たり数千万レコードになるデータを分析するにあたって、パフォーマンスチューニング行った際の最も効果的だったものをご紹介します。
(´-`).。oO(体験談をもとに記事を記載していますので、結果だけ知りたい方は記事の後半のパーティションテーブルについて記載している辺りから読んでください。)
それは性能テスト中のこと
大量なデータにシステムが耐えうるのか、性能テストを行いました。
使用しているシステム構成は下記のようになっています。
| 構成 | 内容 |
|---|---|
| DB | PostgreSQL10系 |
| データの取込みバッチ | Java(SpringBoot2)、Amazon S3に配置したCSVを取得し、DBに格納しやすいように整形してDBにデータ投入する。 |
| 集計・分析バッチ | Java(SpringBoot2)、DBからSELECTしたデータを集計と分析を行い、別のテーブルに格納する。 |
まずは普通に性能テストしてみた
概ね下記のような実行時間となりました。
| 日数 | データの取込み時間 | 集計・分析の実行時間 | 合計時間 |
|---|---|---|---|
| 1 | 01時間04分 | 02時間24分 | 03時間28分 |
| 2 | 01時間05分 | 05時間21分 | 06時間26分 |
| 3 | 01時間05分 | 06時間46分 | 07時間51分 |
| 4 | 01時間05分 | 05時間06分 | 06時間11分 |
| 5 | 01時間06分 | 05時間50分 | 06時間56分 |
| 6 | 01時間06分 | 05時間38分 | 06時間44分 |
| 7 | 01時間04分 | 05時間53分 | 06時間57分 |
| 8 | 01時間03分 | 06時間34分 | 07時間37分 |
| 9 | 01時間05分 | 07時間59分 | 09時間04分 |
| 10 | 01時間07分 | 07時間32分 | 08時間39分 |
| 11 | 01時間10分 | 08時間25分 | 09時間35分 |
| 12 | 01時間09分 | 08時間08分 | 09時間17分 |
| 13 | 01時間10分 | 08時間39分 | 09時間49分 |
| 14 | 01時間09分 | 09時間50分 | 10時間59分 |
| 15 | 01時間10分 | 10時間00分 | 11時間10分 |
| 16 | 01時間10分 | 11時間39分 | 12時間49分 |
| 17 | 01時間12分 | 10時間56分 | 12時間08分 |
| 18 | 01時間11分 | 11時間59分 | 13時間10分 |
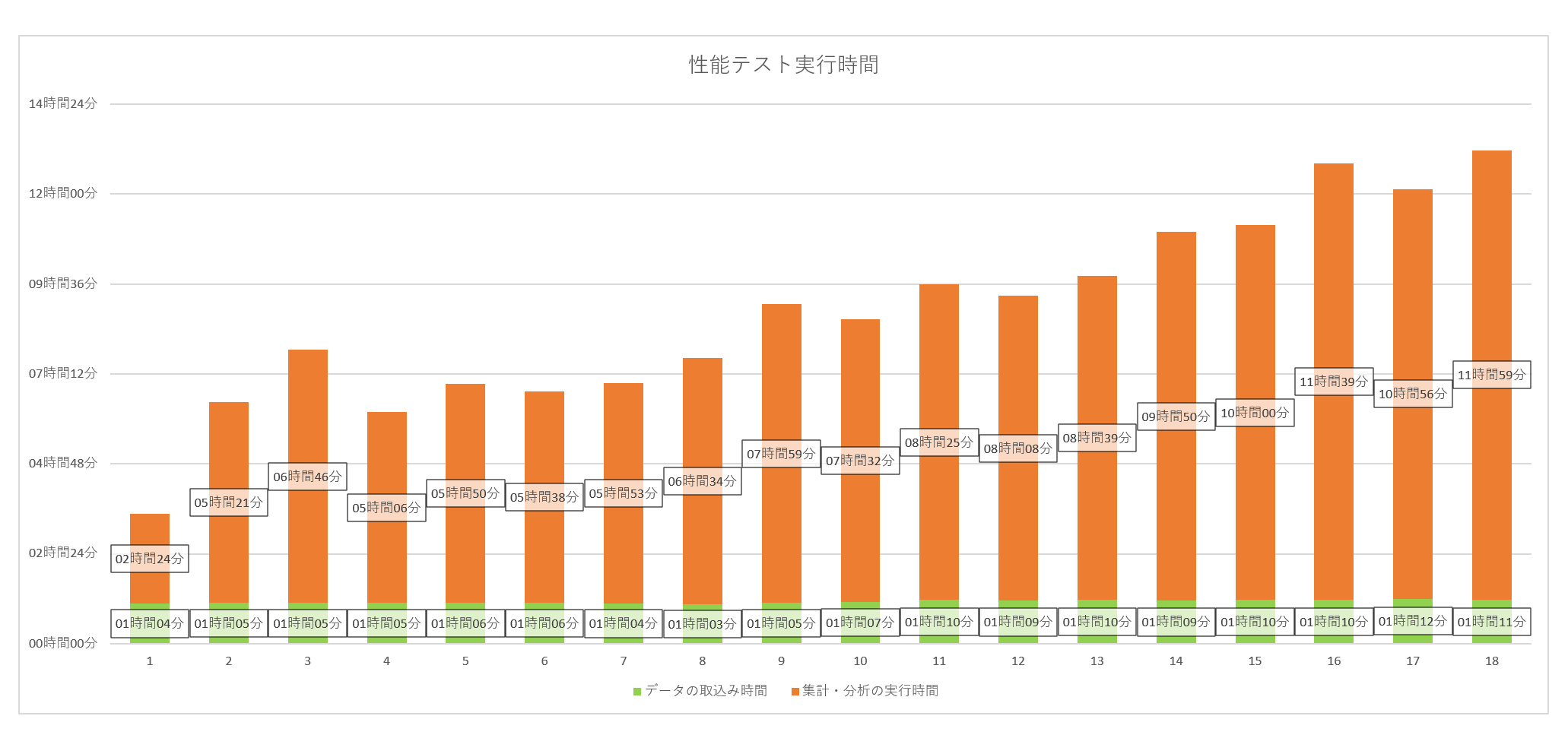
御覧の通り、日数の経過とともにデータ量が増えるのと合わせて、集計・分析の実行時間が徐々に増えています。
集計・分析には1週間や1か月といった範囲でデータ取得して分析する処理があり、1か月分に到達していない間はデータ量に応じて時間がかかるのはある程度は想定内でした。
順調♪順調♪と鼻歌交じりで眺めていました。
そして爆発
| 日数 | データの取込み時間 | 集計・分析の実行時間 | 合計時間 |
|---|---|---|---|
| 19 | 01時間22分 | 2日12時間17分 | 2日13時間39分 |
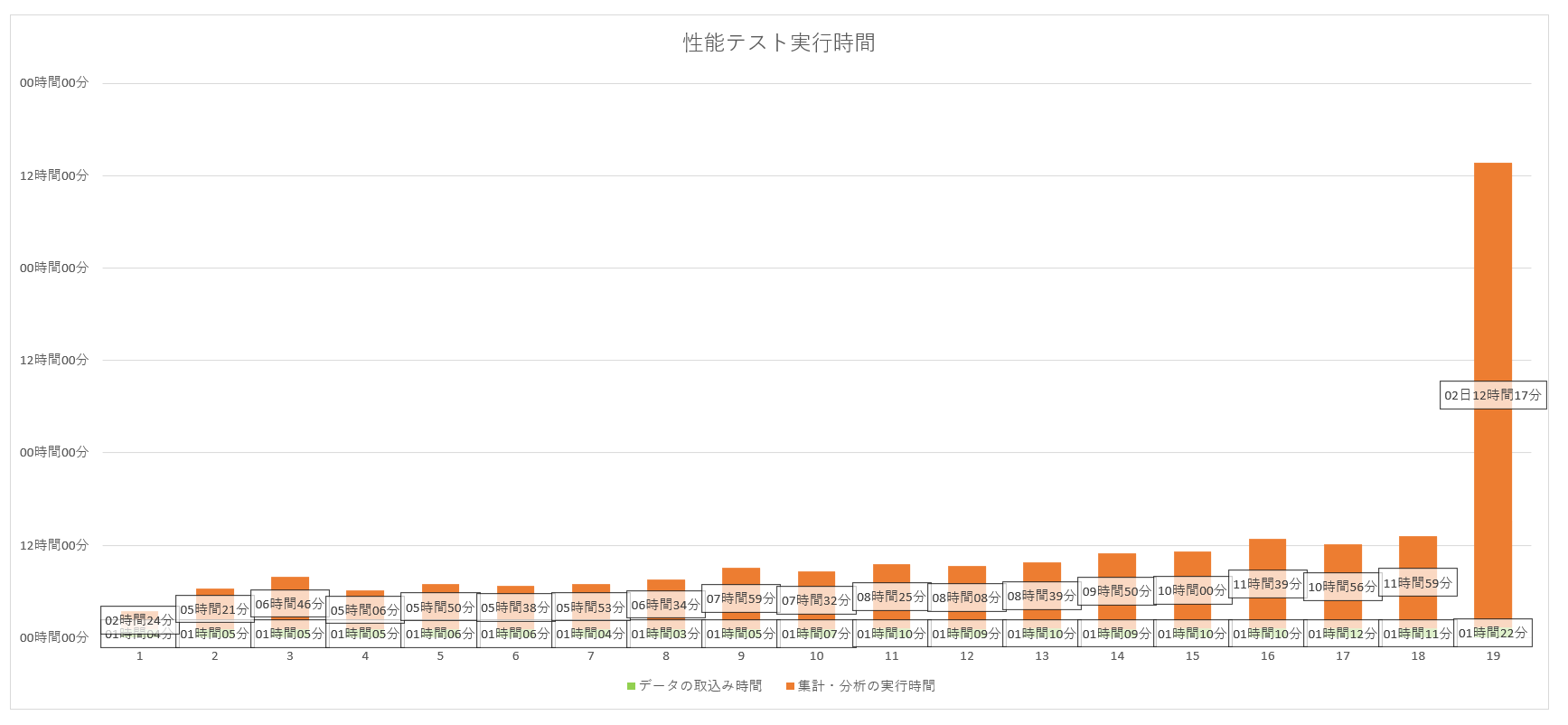
そして、19日目に爆発しました。。。
1日分の集計をするのに1日以上かかっては全く業務に耐えられないですね。
何が起きたのか
データの取り込み時間は大きく変動していないことから、原因は集計・分析にあることは明白なので、集計・分析で使用しているSQLについて調査しました。
分析対象のデータを取得するSQLの実行計画に変化が
集計・分析で使用しているSQLの実行計画を、データ量が少ないDBと問題が発生したDBで比較すると異なる結果が得られました。
データ量が少ないDBでは要所でインデックスを活用したスキャン方法や結合が想定通り機能していました。
一方で、問題の発生したDBでは、インデックスを活用したスキャンや結合が採用されず、ほぼほぼフルテーブルスキャンのような状態でデータを走査していました。
(実行計画の詳細は割愛します。)
なぜ実行計画が変化したのか
PostgreSQLの実行計画を決定する統計情報が大きく関係していました。
実行計画を決定する プランナ は、PostgreSQL内部で各テーブル毎に持つ統計情報を基にして実行計画を決定します。
統計情報と実行計画の決定方法については詳細は割愛しますが、簡単に説明すると、 各カラムでよく登場する値やその頻出率 などが統計情報にあり、それらを基にクエリが効率よくデータを取得するよう、どのインデックスを採用してスキャンするかを決定するといった動作のようです。
実行計画を決定するために使用される統計情報は、バキュームが発生するたびに更新されます。
また、統計情報を作成するために内部でサンプリングするレコードは全レコードではなく一定数でランダムです。
そのため、前述したテストでは下記のような経緯で性能が悪くなったと考えられます。
- 日数を進めている間にデータが増えた
- 自動バキュームによって統計情報が更新された
- 統計情報作成時にサンプリングしたレコードに偏りが発生した
- 実行計画が効率的に動作しなくなってしまった
パーティションテーブルを使用して膨大なデータを分散させる
前述のとおり、データ量が大量になってしまったことに起因して実行計画が悪くなってしまったため、1テーブル辺りのレコード数を抑えていく必要があります。
そこで、動作が遅くなってしまったテーブルにパーティションテーブルを使用することにしました。
パーティションテーブルに変更してからの性能テスト
パーティションテーブルについての紹介は後述しますが、まずはパーティションテーブルを使用してから再開した性能テストについてご覧ください。
履歴のように日付を持った時系列データを持つテーブルについてパーティションテーブルに置き換えました。
データの性質上、1週間おきにサイクルがあるようなデータであるため今回は1週間ごとに子テーブルを作成しました。
結果は下記のとおりです。
| 日数 | データの取込み時間 | 集計・分析の実行時間 | 合計時間 |
|---|---|---|---|
| 20 | 01時間03分 | 04時間07分 | 05時間10分 |
| 21 | 00時間59分 | 05時間58分 | 06時間57分 |
| 22 | 00時間56分 | 03時間07分 | 04時間03分 |
| 23 | 00時間58分 | 03時間41分 | 04時間39分 |
| 24 | 00時間57分 | 04時間12分 | 05時間09分 |
| 25 | 00時間57分 | 04時間36分 | 05時間33分 |
| 26 | 00時間59分 | 03時間52分 | 04時間51分 |
| 27 | 00時間57分 | 04時間07分 | 05時間04分 |
| 28 | 00時間57分 | 07時間46分 | 08時間43分 |
| 29 | 00時間55分 | 03時間59分 | 04時間54分 |
| 30 | 00時間55分 | 05時間22分 | 06時間17分 |
| 31 | 01時間00分 | 06時間37分 | 07時間37分 |
| 32 | 01時間01分 | 05時間34分 | 06時間35分 |
| 33 | 01時間03分 | 05時間59分 | 07時間02分 |
| 34 | 01時間01分 | 06時間43分 | 07時間44分 |
| 35 | 01時間02分 | 06時間06分 | 07時間08分 |
| 36 | 00時間55分 | 04時間50分 | 05時間45分 |
| 37 | 00時間57分 | 06時間03分 | 07時間00分 |
| 38 | 00時間57分 | 06時間10分 | 07時間07分 |
| 39 | 01時間00分 | 06時間14分 | 07時間14分 |
| 40 | 01時間02分 | 06時間04分 | 07時間06分 |
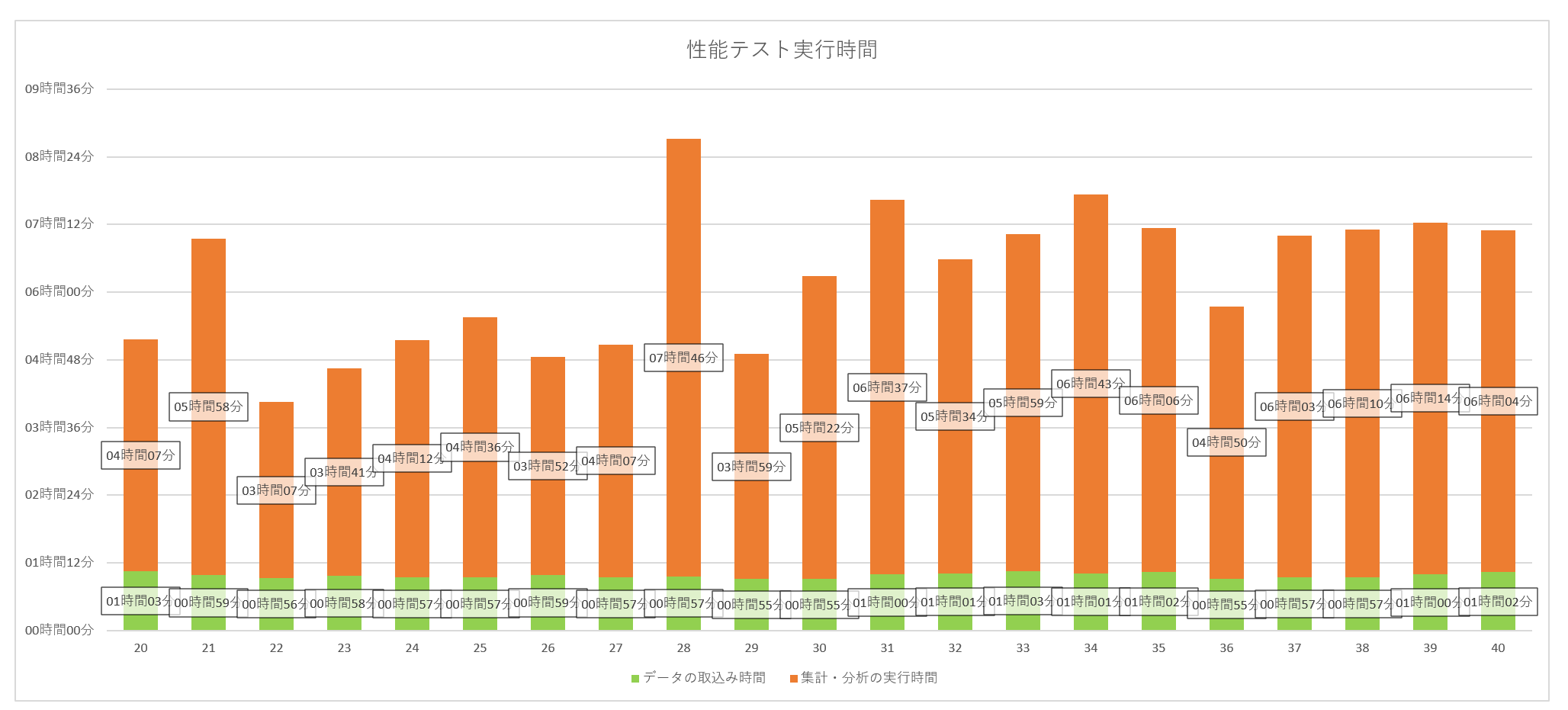
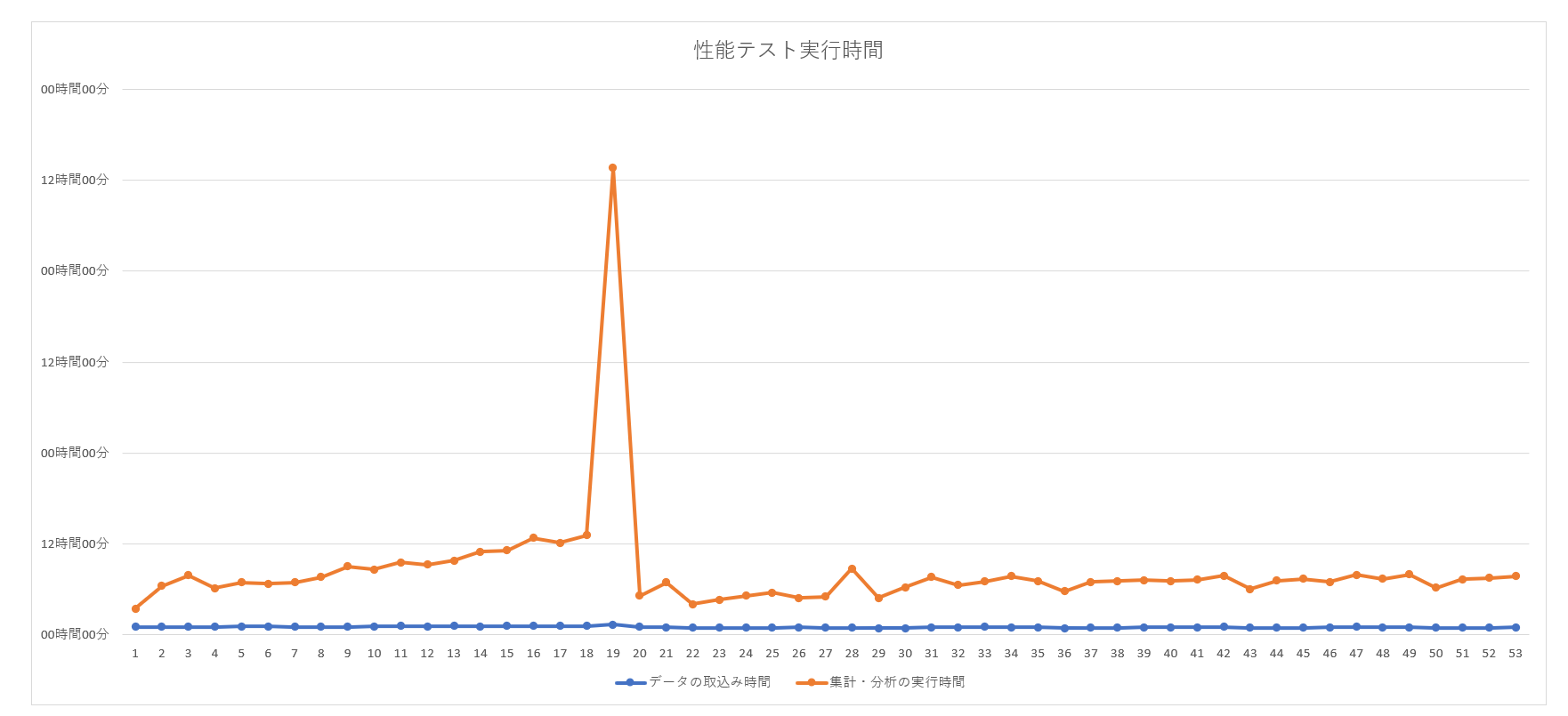
パーティションテーブル導入前のバッチの実行時間よりも早くすることが出来ました。
また、20日目移行、右肩上がりにならなずに安定しており、日数が経って総データ量が増えてもバッチの動作時間はある程度の範囲で安定させることが出来ました。
パーティションテーブルの紹介
パーティションテーブルは、親子関係のあるテーブルを作成し、親テーブルへの問い合わせが子テーブルに分散されるというテーブル構造になっています。
子テーブルもそれぞれ通常のテーブルと同様に存在するため、インデックスや統計情報などもそれぞれに持つことが出来ます。
問い合わせ時には各テーブルへの問い合わせが分散され、それぞれのテーブルにて並列に実行計画が実行されます。
下記のようなイメージです。
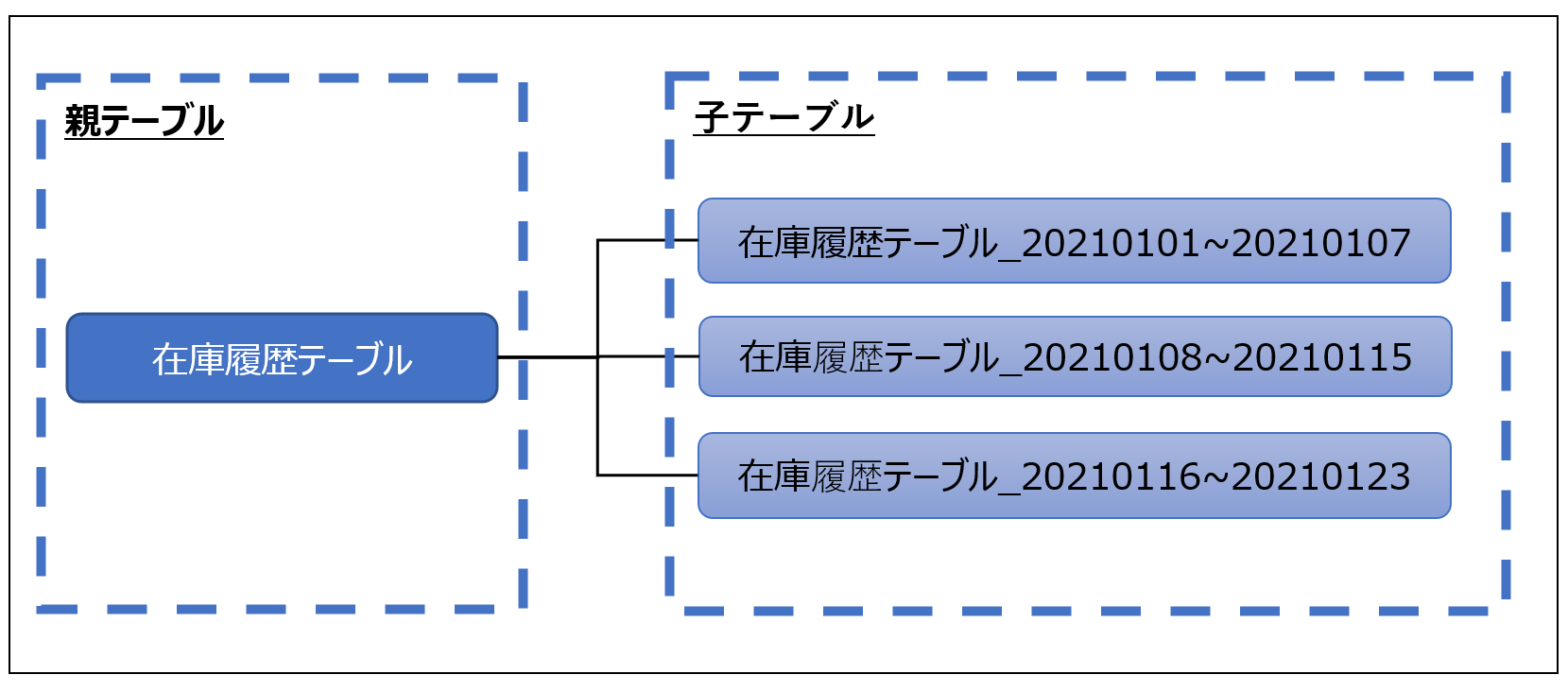
パーティションテーブル作成のSQLの例です。
-- 親テーブル作成
CREATE TABLE item_stock_history (
id bigserial not null
, retailer_id integer not null
, warehouse_id integer not null
, history_date date not null
, packing_type_id integer not null
, item_code varchar(256) not null
, item_name varchar(1024)
, jan13 char(13)
, jan8 char(8)
, expiration_date date
, available_stock_num integer
, book_value decimal(20,2)
, purchase_cost decimal(20,2)
, created_by varchar(128)
, created_at timestamp with time zone not null
, updated_by varchar(128)
, updated_at timestamp with time zone
, deleted_by varchar(128)
, deleted_at timestamp with time zone
) PARTITION BY RANGE (history_date) ;
-- 子テーブル作成
CREATE TABLE
item_stock_history_20210101
PARTITION OF
item_stock_history
FOR VALUES FROM ('2021-01-01') TO ('2021-01-08');
CREATE TABLE
item_stock_history_20210108
PARTITION OF
item_stock_history
FOR VALUES FROM ('2021-01-08') TO ('2021-01-16');
CREATE TABLE
item_stock_history_20210101
PARTITION OF
item_stock_history
FOR VALUES FROM ('2021-01-16') TO ('2021-01-23');
-- インデックス作成(子テーブルごとに必要)
CREATE INDEX
item_stock_history_20210101_ix1 ON item_stock_history_20210101 (item_code);
CREATE INDEX
item_stock_history_20210101_ix2 ON item_stock_history_20210101 (history_date);
CREATE INDEX
item_stock_history_20210101_ix3 ON item_stock_history_20210101 (retailer_id);
CREATE INDEX
item_stock_history_20210108_ix1 ON item_stock_history_20210108 (item_code);
CREATE INDEX
item_stock_history_20210108_ix2 ON item_stock_history_20210108 (history_date);
CREATE INDEX
item_stock_history_20210108_ix3 ON item_stock_history_20210108 (retailer_id);
CREATE INDEX
item_stock_history_20210116_ix1 ON item_stock_history_20210116 (item_code);
CREATE INDEX
item_stock_history_20210116_ix2 ON item_stock_history_20210116 (history_date);
CREATE INDEX
item_stock_history_20210116_ix3 ON item_stock_history_20210116 (retailer_id);
上記テーブルに対してSQLを発行し、その実行計画を出してみました。
SELECT
*
FROM item_stock_history
WHERE
retailer_id = 1
AND history_date >= '2021-01-03'
AND history_date < '2021-01-20'
;
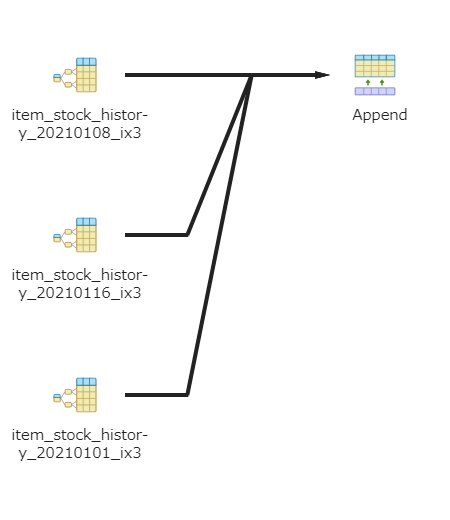
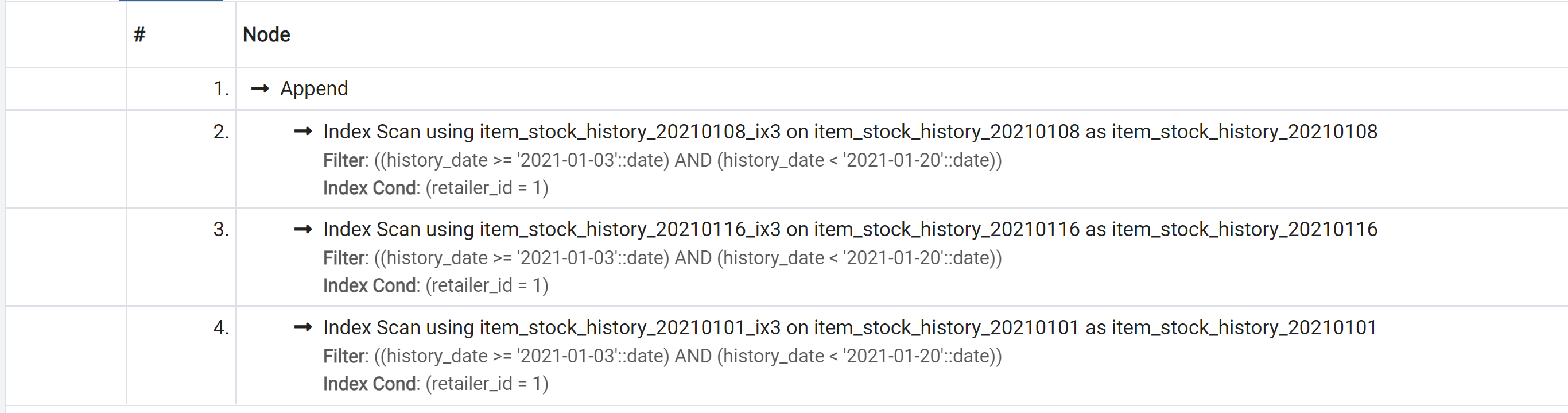
このように、実行計画が分散、並列化されています。
パーティションテーブルの詳細な作成方法等はPostgreSQLのドキュメントを参照ください。
https://www.postgresql.jp/document/10/html/ddl-partitioning.html
パーティションテーブルによって結果的に性能の改善を図ることができましたが、使用してみてよかった点と悪かった点がそれぞれ見えましたのでご紹介します。
良い点
1. 親テーブルへの問い合わせで全ての子テーブルへ問い合わせできる
親テーブルへの問い合わせで全ての子テーブルへの問い合わせになるため、既存のSQLへの影響が少なく済みます。
既に構築・稼働済みのシステムでもをSQL等を変更しなくても導入が可能です。
2. 子テーブルも普通のテーブルとして問い合わせ出来る
子テーブルも実態を持つテーブルであるため、通常のテーブル同様問い合わせ可能です。
必要に応じてテーブルへの問い合わせ(SQL)自体を分けることでDBへの負荷も調整できます。
(親テーブルへの問い合わせをすると、子テーブル全てに問い合わせしてしまうため、負荷がかかる場合があります。)
3. 親テーブルへの問い合わせは子テーブルごとに並列処理される
親テーブルへの問い合わせは子テーブルごとに並列処理されるため、実行計画等もも子テーブルごとに作成されます。
並列に実行計画が動作するのでクエリの実行速度が向上する場合があります。
4. テーブルの統計情報は子テーブルごとに作成される
実行計画の作成に使用される統計情報は、子テーブルごとにそれぞれ作成されます。
そのためデータ量による統計情報の偏りを防げます。
5. 一部の子テーブルのみをテーブルごと削除できる
一部の子テーブルを削除してもパーティションテーブル全体には影響がありません。
一定期間過ぎたデータを削除する運用などに使いやすいです。
悪い点
1. 振り分け条件に合致するテーブルがない場合には保存できない
PostgreSQL10系では、デフォルトの子テーブルを作成することが出来ません。
そのため、登録したいデータに応じて子テーブルを作成しておく必要があります。
※ PostgreSQL11系から作成できるようになったようです。
2. 子テーブルは自動作成されない
子テーブルは自動では作成されません。
上記の悪い点1と同様、都度必要に応じて作成する必要があります。
3. インデックスは子テーブルごとに作成する必要がある
インデックスは子テーブルごとに作成する必要があり、手動での作成が必要となります。
※ PostgreSQL11系からは、親テーブルに設定したインデックスを引き継いで子テーブル作成時に自動作成できるようになったようです。
3. 子テーブルをまたぐようなクエリは遅くなる場合がある
子テーブルをまたぐような条件での集計(GROUP BY)やソート(ORDER BY)のクエリは遅くなる場合があります。
子テーブルから必要なレコードを取得してから、作業領域上で操作するというように段階を踏んだプロセスが内部で実行されるためです
まとめ
下記のような場合にはまずパーティションテーブルの採用を検討した方が良いと感じました。
- 履歴のような時系列にデータが増え続けていくデータ
- 1テーブルが膨大な量になる想定のデータ
ただし、パーティションテーブルを採用した場合にはテーブルを管理する運用コストも増えてしまうため、その辺りを上手いこと折り合いを付ける必要があるため要注意です。
参考資料
- PostgreSQL 10.5文書
あとがき
aucfanではElasticsearchなどの分散型のNoSQLデータベースを使用したシステムもありノウハウもあります。
今回のようなデータはES向きだったんだろうなーorz