Aidemy 2020/11/21
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、深層強化学習の一つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・(復習)強化学習について
・強化学習の手法
・DQN
(復習)強化学習について
・強化学習__は機械学習の一手法である。
・強化学習の構成要素としては次のようなものがある。行動する主体である__エージェント、行動の対象である__環境__、環境に対する働きかけを__行動__、それにより変化する環境の各要素が__状態__である。また、行動により即時に得られる評価のことを__報酬__、最終的に合計でどれぐらいの報酬を得られたのかを示すのが__収益__である。
・強化学習の目的は、この__収益の総和を最大化すること__である。
・強化学習のモデルとしては、エージェントの行動選択の__方策__について、「現在の環境の状態を入力」、__「行動を出力」として表現する。そしてこの行動は、より高い報酬が得られるようなものを選択する。
・この「より高い報酬」について、報酬の内容が全て既知だったら、その中から最も報酬が高いものを選べば良いが、実際にはこれが事前に与えられているケースは少ない。このような時は「探索」を行うことで選択したことのない行動も行って情報を収集することが必要である。これにより情報を集めたら、その中から最も報酬が高いと推測した行動を選択すると良い。これを「利用」__という。
強化学習の方策
(復習)greedy手法
・上記で示した探索と利用をどのように行っていくかという__方策__について、その問題に即した方策をとることが重要になってくる。
・例えば報酬の期待値が全て既知である場合は、期待値の最も大きい行動のみを選択するという__「greedy手法」を選択するのが最も良い方策となる。
・しかし先述の通り、一般的には報酬が全て既知であるケースは少ないため、このような時は、得られる報酬が少ないと分かっていても別の行動を選択する必要がある。この方策の一つに「ε-greedy手法」がある。これは__確率εで探索を行い、__1-εで利用を行う__というものである。__試行回数に基づいてεの値を小さくする__ことで、利用の割合が増えていくため、効率よく探索できるようになる。
ボルツマン選択
・ε-greedy手法は__ある程度確率的に行動を選択する__方策であった。これと同じようなものとして__「ボルツマン選択」__という方策がある。
・ボルツマン選択は選択確率が以下の__ボルツマン分布__に従うためこのように呼ばれる。
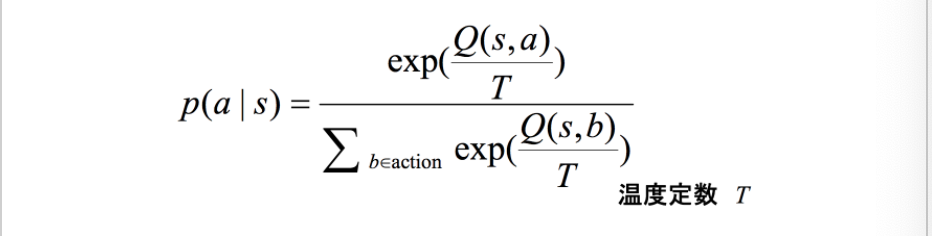
・この式のうち__「T」は__温度関数__と呼ばれるもので、「時間経過とともに0に収束する関数」__のことである。この時、__T→無限の極限__で全ての行動を__同じ確率で選択__し、__T→0の極限__で__報酬の期待値が最大のものを選びやすくなる__というものである。
・つまり、__初めのうちはTが大きいため行動選択がランダム__であるが、時間経過により__Tが0に近づくとgreedy手法のように選択する__ようになる。
DQN
・__DQN__とは、Q学習の__Q関数を深層学習で表したもの__である。Q関数__とは「行動価値関数」__のことであり、__Q学習__はこれを推定する強化学習のアルゴリズムである。
・行動価値関数__は「状態sと行動a」__を入力として、__最適方策を行った時の報酬の期待値__を計算する関数である。行われることとしては、試しに__ある行動を行って得られた行動価値__と、__一つ先の状態で可能な行動を行って得られた行動価値__を__合算__して、今の行動価値との__差__をとって、少しだけ(学習率を調整して)関数を更新する、ということ行われる。
・実際には状態sと行動aは全ての組み合わせについて__テーブル関数__で表されるが、問題によってはこの__組み合わせの量が膨大になる__という恐れがある。
・このような場合に、DQNで、このQ関数を深層学習によって関数近似することで解決できる。
・DQNの特徴__としては、以下のようなものがある。詳しくは次のChapterでみる。
・Experience Replay:データの時系列をシャッフル__して時系列の相関に対処する
・Target Network:正解との誤差を計算し、モデルが正解に近くなるように調整する。データからランダムにバッチを作成し、バッチ学習を行う。
・CNN:畳み込み__によって画像にフィルタをかけ変換する。
・clipping:報酬について、負なら-1、正なら+1__、なしなら__0__とする。
Experience Replay
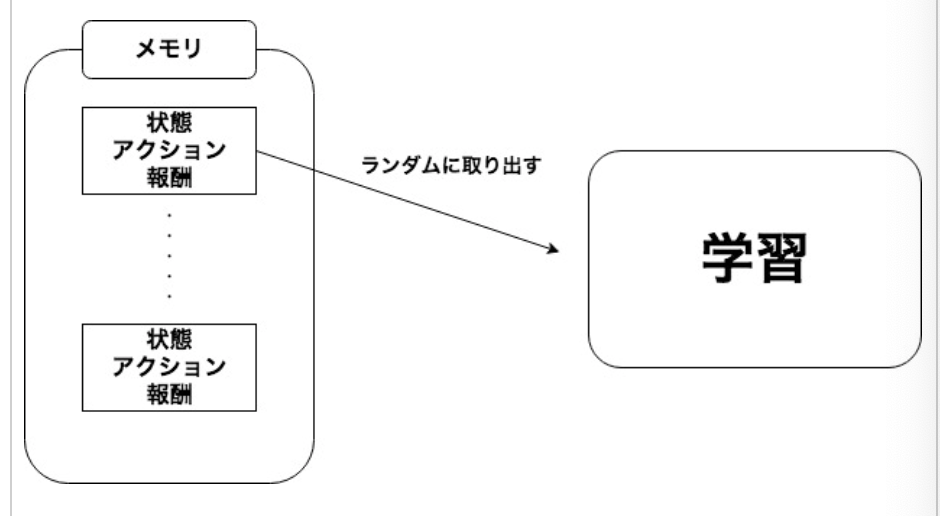
・例えばゲームをプレイしているエージェントが得られる入力には、時系列の性質がある。時系列の入力には__強い相関がある__ため、学習に時系列の入力をそのまま使うと、学習結果に偏りが生じ、収束性が悪くなる。これを解決するのが、__Experience Replay__と呼ばれるものである。これは、__状態や行動、報酬__を入力として、全て、あるいは一定個数記録しておき、そこから__ランダムに呼び出して学習させる__手法である。
まとめ
・強化学習では__収益の総和を最大化する__ために、探索__と__利用__が行われる。これをどのように行なっていくか、というのが__方策__である。
・この方策について、報酬の期待値がわかっている状態の時に有効なのが「greedy手法」__である。これは、最も期待値の高い行動のみを選択する__というものである。
・報酬の期待値が全て既知でない場合にも対応したものが「ε-greedy手法」__である。この方策は確率εで探索を、1-εで利用を行うというものである。
・同様の方策として、__ボルツマン選択__というものがある。時間経過で値が0に収束していく__温度関数T__を使ったボルツマン分布に従って選択されるため、最初はランダムに行動が選ばれるが、時間経過につれて最も期待値の高い行動を選択するようになる。
・__DQN__は__Q関数(行動価値関数)を__深層学習__で表したものである。行動価値関数は状態sと行動aを入力として報酬の期待値を算出するのであるが、sとaは全ての組み合わせをテーブル関数で表すと量が膨大になってしまうため、この手法が使われる。
・DQNの特徴の一つに「Experience Replay」__というものがある。これは、入力データの__時系列の性質を除去する__ために、状態、行動、報酬について、__ランダムに取り出す__ということを行う。
今回は異常です。ここまで読んでいただきありがとうございました。