はじめに
勉強中のPysparkについて、勉強したとこまでメモ。
実際にクラスタを構築して実装してみたかったが、若干敷居が高く感じられたので今回は楽にできるローカル(クラスタを構築しないモード)で行う。PySparkの文法練習自体はこれでも十分可能だった。
Pysparkバージョン:3.2.0
実行環境:Google Colab
Sparkの概要
●Hadoopについて
Hadoopを構成する要素をかなり大雑把に書くとこんな感じになる。
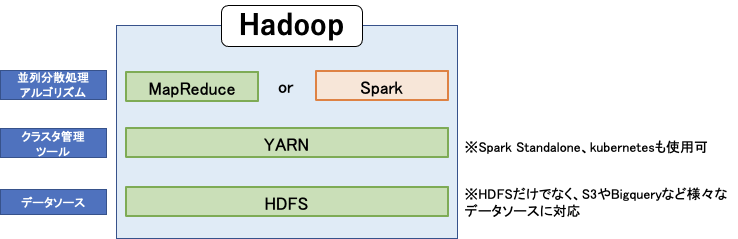
Hadoopは、分散処理技術によって大規模データの扱いに長けたオープンソースのフレームワークである。テラバイトとかペタバイトあるデータを扱うことができる。
Hadoopを特徴づける最も重要なコンポーネントが、**HDFS(Hadoop Distributed File System)**と呼ばれる分散ファイルシステムである。HDFSは複数のサーバーのストレージを一つのファイルシステムとして運用できるシステムであり、下記のような利点がある。
・スケーラビリティ:一つのストレージを扱うのと比べて容量や性能の向上が容易
・耐障害性:複数のストレージに同じデータがレプリケーションされるため、耐障害性が高い
●分散処理アルゴリズムについて(SparkとMapReduce)
では、複数ストレージに分散したデータにアクセスし処理するには?
HDFSにアクセスしデータを処理するためのアルゴリズムとして、SparkとMapReduceがある。元々はMapReduceのみだったが、後から出てきたSparkの利便性によってかなり追いやられているらしい。
MapReduceに対してSparkの優位な点としてざっくりと以下のような点がある。
・処理が早い:調べた感じだとこれが一番の優位点になっている。一度処理したデータをメモリ上にキャッシュするため、繰り返し処理を行う機械学習などの処理に適している。
・扱いやすい:SQLだけでなく、PythonやR、ScalaやJavaなどで実装できる。
・様々な処理を実行できる:データの加工から分析まで幅広い工程の処理をオールインワンで実現できる。
このSparkをPythonで実装できるのがPysparkである。
Spark概要に関するより詳しい内容についてはこちらの記事がわかりやすかったです。
Pysparkの実装
●RDD構文とDataFrame構文
SparkにはRDDとDataFrameという二つのプログラミング構文がある。
大きな違いとして、「スキーマ」の有無がある。DataFrameにはスキーマがあるが、RDDにはスキーマがない。そのためDataFrameではカラム名を利用した列指向の処理を行うことができるが、RDDではできない。またSQLライクに処理を記述できるなど、DataFrameの方がかなり扱いやすい模様。Pythonで比較した場合、DataFrameの方がパフォーマンスも良くなるらしい。RDDにも非構造化データに対する柔軟な処理が行えるといったメリットはあるようだが、基本的にDataFrameを使用するので大丈夫そうなので、今回はDataFrameを使用する。
ただ、DataFrameとRDDの立ち位置は並列なものではなく、RDDを使いやすくするため高級なAPIとして作られたのがDataFrameである。つまりDataFrameの構文を使うときに、ベースではRDDの処理が動いている。
●Pyspark実装
Sparkはローカルの単一のコンピュータでも実装できる。実際に現場で使う際は基本的にクラスターを構築して使用することになると思うが、文法の理解やテストをする分には一つのコンピュータで実装できるのは楽で便利。デフォルトでローカルモードになっているので、そのまま使うことができる。
今回は一番簡単にできそうなGoogle Colab proで実装した。Google Colab proでの実装はめちゃくちゃ簡単で下記を実行するだけでPysparkを扱うことができるようになる。
!pip install pyspark
titanicデータ分析
kaggleのtitanicデータで分類した。実際やってみて、SQLやpythonを使い慣れていると文法自体はかなりわかりやすいことがわかった。
●SparkSessionの立ち上げ
最初にSparkSessionを立ち上げ、データを読み込む。データを読み込む際inferSchemaをTrueにすることで、それぞれのカラムのデータ型をいい感じにしてくれる。
# SparkSessionの立ち上げ
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('titanic').getOrCreate()
# ファイルの読み込み
df = spark.read.csv('ファイルのパス',header=True, inferSchema=True)
●EDA
データの色々表示してみる。
まずはデータ自体を表示。
# データの表示
df.show()
>>>
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
|PassengerId|Survived|Pclass| Name| Sex| Age|SibSp|Parch| Ticket| Fare|Cabin|Embarked|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
| 1| 0| 3|Braund, Mr. Owen ...| male|22.0| 1| 0| A/5 21171| 7.25| null| S|
| 2| 1| 1|Cumings, Mrs. Joh...|female|38.0| 1| 0| PC 17599|71.2833| C85| C|
| 3| 1| 3|Heikkinen, Miss. ...|female|26.0| 0| 0|STON/O2. 3101282| 7.925| null| S|
| 4| 1| 1|Futrelle, Mrs. Ja...|female|35.0| 1| 0| 113803| 53.1| C123| S|
| 5| 0| 3|Allen, Mr. Willia...| male|35.0| 0| 0| 373450| 8.05| null| S|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+
only showing top 5 rows
データの構造、データ型を確認する。
# dfの構造を表示
df.printSchema()
>>>
root
|-- PassengerId: integer (nullable = true)
|-- Survived: integer (nullable = true)
|-- Pclass: integer (nullable = true)
|-- Name: string (nullable = true)
|-- Sex: string (nullable = true)
|-- Age: double (nullable = true)
|-- SibSp: integer (nullable = true)
|-- Parch: integer (nullable = true)
|-- Ticket: string (nullable = true)
|-- Fare: double (nullable = true)
|-- Cabin: string (nullable = true)
|-- Embarked: string (nullable = true)
統計量を確認する。
# 統計量の表示
df.describe().show()
>>>
+-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+
|summary| PassengerId| Survived| Pclass| Name| Sex| Age| SibSp| Parch| Ticket| Fare|Cabin|Embarked|
+-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+
| count| 891| 891| 891| 891| 891| 714| 891| 891| 891| 891| 204| 889|
| mean| 446.0| 0.3838383838383838| 2.308641975308642| null| null| 29.69911764705882|0.5230078563411896|0.38159371492704824|260318.54916792738| 32.2042079685746| null| null|
| stddev|257.3538420152301|0.48659245426485753|0.8360712409770491| null| null|14.526497332334035|1.1027434322934315| 0.8060572211299488|471609.26868834975|49.69342859718089| null| null|
| min| 1| 0| 1|"Andersson, Mr. A...|female| 0.42| 0| 0| 110152| 0.0| A10| C|
| max| 891| 1| 3|van Melkebeke, Mr...| male| 80.0| 8| 6| WE/P 5735| 512.3292| T| S|
+-------+-----------------+-------------------+------------------+--------------------+------+------------------+------------------+-------------------+------------------+-----------------+-----+--------+
●前処理
・欠損値の処理
上記のdescribe()のcountの値が他のカラムの891より少ないことから、Age、Cabin、Embarkedの列に欠損値があることがわかる。
列ごとの欠損値の数を確認するには以下を実行する。
df.filter(df['Age'].isNull()).count()
>>>
177
欠損値の補完を行う。Age列は中央値で補完、Cabinは欠損が多いので列ごと削除(というか使わないので放置で良い)、Embarkedは量が少ないので欠損がある行を削除する。
まず、Age列の補完を行う。二通りのやり方でやってみる。
# 中央値の算出
from pyspark.sql.functions import percentile_approx
age_med = df.select(percentile_approx('Age', 0.5)).collect()[0][0] #28
# 中央値で補完
df_fill = df.na.fill({'Age':age_mod})
または、Imputerを用いる方法がある。Pipeline使ったりする場合はこっちになる。
outputColの名前は何でも良い。こっちの方法でやると、outputColで指定した"Age_impute"という新しいカラムが増えることになる。
from pyspark.ml.feature import Imputer
imputer = Imputer(strategy='median', inputCol='Age', outputCol='Age_impute')
model = imputer.fit(df)
df_fill2 = model.transform(df)
次にEmbarked列の欠損がある列を削除する。
df_fill = df_fill.na.drop(subset=['Embarked'])
・カテゴリ変数の処理
Sex列とEmbarked列に対してOne-Hotエンコードを行う。SparkのOneHotEncoderは数値しか扱うことができないため、StringIndexerでString列をラベルエンコードした後OneHotエンコードを行う。
OneHotして最終的に出てくるカラムはベクトル列になっている。
from pyspark.ml.feature import OneHotEncoder, StringIndexer
# 先にラベルエンコードを行う
indexer = StringIndexer(inputCols=['Sex', 'Embarked'],
outputCols=['Sex_index','Embarked_index'])
index_model = indexer.fit(df_fill)
df_fill = index_model.transform(df_fill)
# One-Hotエンコードを行う
onehot = OneHotEncoder(inputCols=['Sex_index', 'Embarked_index'],
outputCols=['Sex_vec','Embarked_vec'])
df_fill = onehot.fit(df_fill).transform(df_fill)
df_fill.show()
>>>
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+---------+--------------+-------------+-------------+
|PassengerId|Survived|Pclass| Name| Sex| Age|SibSp|Parch| Ticket| Fare|Cabin|Embarked|Sex_index|Embarked_index| Sex_vec| Embarked_vec|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+---------+--------------+-------------+-------------+
| 1| 0| 3|Braund, Mr. Owen ...| male|22.0| 1| 0| A/5 21171| 7.25| null| S| 0.0| 0.0|(1,[0],[1.0])|(2,[0],[1.0])|
| 2| 1| 1|Cumings, Mrs. Joh...|female|38.0| 1| 0| PC 17599|71.2833| C85| C| 1.0| 1.0| (1,[],[])|(2,[1],[1.0])|
| 3| 1| 3|Heikkinen, Miss. ...|female|26.0| 0| 0|STON/O2. 3101282| 7.925| null| S| 1.0| 0.0| (1,[],[])|(2,[0],[1.0])|
| 4| 1| 1|Futrelle, Mrs. Ja...|female|35.0| 1| 0| 113803| 53.1| C123| S| 1.0| 0.0| (1,[],[])|(2,[0],[1.0])|
| 5| 0| 3|Allen, Mr. Willia...| male|35.0| 0| 0| 373450| 8.05| null| S| 0.0| 0.0|(1,[0],[1.0])|(2,[0],[1.0])|
+-----------+--------+------+--------------------+------+----+-----+-----+----------------+-------+-----+--------+---------+--------------+-------------+-------------+
●ロジスティック回帰分析
・特徴量列をまとめる
前処理が終わったのでロジスティック回帰を行う。しかしその前に、現状複数列ある特徴量列を一つのベクトル列にまとめる必要がある。Pysparkでは最終的にモデルに入れる時の形が、「特徴量のベクトル列」と「ラベル列」の二列になるためである。
特徴量列はVectorAssemblerを用いて「features」という名前のベクトル列にまとめ、最終的に特徴量列とラベル列(今回はSurvived)を取り出す。
from pyspark.ml.feature import VectorAssembler
usecol = ['Pclass', 'Age','SibSp','Parch','Fare', 'Sex_vec','Embarked_vec']
assembler = VectorAssembler(inputCols = usecol,
outputCol = 'features')
output = assembler.transform(df_fill)
final_data = output.select('features', 'Survived')
final_data.show(5)
>>>
+--------------------+--------+
| features|Survived|
+--------------------+--------+
|[3.0,22.0,1.0,0.0...| 0|
|[1.0,38.0,1.0,0.0...| 1|
|(8,[0,1,4,6],[3.0...| 1|
|[1.0,35.0,1.0,0.0...| 1|
|[3.0,35.0,0.0,0.0...| 0|
+--------------------+--------+
only showing top 5 rows
・trainデータとtestデータに分ける
このデータをtrainデータとtestデータに分ける。
seedに数字を入れることで、RandomSeedを指定することができる。
train_data, test_data = final_data.randomSplit([0.7,0.3], seed=1)
ロジスティック回帰で学習
あとは学習機にかけるだけでできる。ちなみに今回データに対する標準化を行っていないが、Sparkのロジスティック回帰はデフォルトで標準化処理を勝手に行ってくれるので、別で行う必要がない。
パラメータとかについては[こちら]
(https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.ml.classification.LogisticRegression.html? highlight=logistic#pyspark.ml.classification.LogisticRegression)のドキュメントを参照。
学習したモデルでtransformを実行すると、予測値(prediction)やその確率(probability)を得ることができる。
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol='features', labelCol='Survived', predictionCol='prediction')
lr_model = lr.fit(train_data)
test_pred = lr_model.transform(test_data)
test_pred.show(5)
>>>
+--------------------+--------+--------------------+--------------------+----------+
| features|Survived| rawPrediction| probability|prediction|
+--------------------+--------+--------------------+--------------------+----------+
|(8,[0,1,2,4],[3.0...| 1|[-0.4218296937258...|[0.39607900350312...| 1.0|
|(8,[0,1,4],[2.0,2...| 1|[-1.9299810466149...|[0.12675267798995...| 1.0|
|(8,[0,1,4],[3.0,1...| 1|[-1.1683177702197...|[0.23715918980462...| 1.0|
|(8,[0,1,4],[3.0,2...| 1|[-1.0367914153313...|[0.26176956678286...| 1.0|
|(8,[0,1,4],[3.0,2...| 0|[-0.7744001109292...|[0.31552804343796...| 1.0|
+--------------------+--------+--------------------+--------------------+----------+
only showing top 5 rows
最後に結果の評価を行う。分類問題の評価には、BinaryClassificationEvaluatorまたはMulticlassClassificationEvaluatorを使用する。ちなみにaccuracyはmulticlassの方にしかない。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
multi_eval = MulticlassClassificationEvaluator(metricName='accuracy',predictionCol='prediction',labelCol='Survived')
multi_eval.evaluate(test_pred)
>>>
0.7969348659003831
取り敢えず、Pysparkのみで前処理や分類予測ができた。