はじめに
- 前回に続いてまたパクってます。パクってますが、結構作り変えてます。
- ディープラーニングの基礎知識が皆無です。動かしたい欲望だけで作りましたので、ご了承ください。
- 開発期間は約1週間くらいです。
- Pythonわかりません。TensorFlow初めてです。とかいうレベルです。
- 株の知識ないです。
- 精度は全然高くありません。
- 精度以前に中身のつくりの理解が乏しく、何度も何度も作り直して一旦力尽きたので、学習までしか行ってません。
- ぐるなび。
- 途中経過なので理解しきれていない(間違っている)場合があります。
- きちんとやりきった後、ページを整理するかもしれません。
パクリ元
- 日経平均の終値が前日より上がるか下がるかをTensorFlowで予測する(1)
- Machine Learning with Financial Time Series Data on Google Cloud Platform
- [TensorFlowで株価予想] 0 - Google のサンプルコードを動かしてみる
説明
ぐるなびの株価の終値が前日より上がったか下がったか予測します。
環境構築
前回のものを使用します。
また、この他にグラフを表示(実際の予測とは関係ないです)するためにmatplotlibを入れております。
pip install matplotlib
データ収集
株価データの元は以下から入手しました。
株式投資メモ・株価データベース
また、銘柄毎に3ファイルに分け、年毎に分かれているファイルを結合しました。
最後にヘッダカラムを調整しました。
ファイルは載せられないみたいなので、以下例とします。
例) Gurunavi.csv
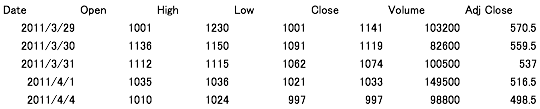
結果
ソースコード
stock_price_prediction.py
# !/usr/local/bin/python
# ! -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
flags = tf.app.flags
FLAGS = flags.FLAGS
# CSVデータを置いてあるフォルダ
flags.DEFINE_string('csv_dir', '{ディレクトリパス}', 'Directory to put the csv data.')
# 学習データを置いてあるフォルダ
flags.DEFINE_string('train_dir', '{ディレクトリパス}', 'Directory to put the training data.')
# 終値のカラム名称
flags.DEFINE_string('close_column', 'Close', 'Close column name.')
# AIの学習モデル部分(ニューラルネットワーク)を作成する
def inference(num_predictors, num_classes, stock_placeholder):
# 重みを標準偏差0.1の正規分布で初期化する
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.0001)
return tf.Variable(initial)
# バイアスを標準偏差0.1の正規分布で初期化する
def bias_variable(shape):
initial = tf.ones(shape)
return tf.Variable(initial)
with tf.name_scope('fc1') as scope:
weights = weight_variable([num_predictors, num_classes])
biases = bias_variable([num_classes])
# ソフトマックス関数による正規化
# ここまでのニューラルネットワークの出力を各ラベルの確率へ変換する
with tf.name_scope('softmax') as scope:
model = tf.nn.softmax(tf.matmul(stock_placeholder, weights) + biases)
# 各ラベルの確率(のようなもの?)を返す
return model
# 予測結果と正解にどれくらい「誤差」があったかを算出する
def loss(logits, labels):
# 交差エントロピーの計算
cross_entropy = -tf.reduce_sum(labels*tf.log(logits))
# TensorBoardで表示するよう指定
tf.summary.scalar("cross_entropy", cross_entropy)
# 誤差の率の値(cross_entropy)を返す
return cross_entropy
# 誤差(loss)を元に誤差逆伝播を用いて設計した学習モデルを訓練する
def training(labels_placeholder, model):
# この関数がその当たりの全てをやってくれる様
cost = -tf.reduce_sum(labels_placeholder*tf.log(model))
training_step = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(cost)
return training_step
# inferenceで学習モデルが出した予測結果の正解率を算出する
def accuracy(model, labels_placeholder):
# 予測(model)と実際の値(actual)が一致(equal)した場合の配列を取得する
# 結果の例: [1,1,0,1,0] 1が正解
correct_prediction = tf.equal(
tf.argmax(model, 1),
tf.argmax(labels_placeholder, 1)
)
# 結果(例:[1,1,0,1,0] 1が正解)を float にキャストして
# 全ての平均(reduce_mean)を得る
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# TensorBoardで表示する様設定
tf.summary.scalar("accuracy", accuracy)
return accuracy
if __name__ == '__main__':
stocks = [
'Gurunavi',
'Recruit',
'Kakakucom',
]
closing_data = pd.DataFrame()
for stock in stocks:
# Pandas DataframeにCSVを読み込みます。
data = pd.read_csv(FLAGS.csv_dir + stock + '.csv', index_col='Date').sort_index()
# 終値を1日前との比率の対数をとって正規化する。
# 前日よりも上がっていればプラス、下がっていればマイナスになる
closing_data[stock] = np.log(data[FLAGS.close_column] / data[FLAGS.close_column].shift())
# 欠損値の行を除きます。
closing_data = closing_data.dropna()
# 対数リターンをフラグに変換します。
# 正の場合
closing_data["Gurunavi_Positive"] = 0
closing_data.ix[closing_data["Gurunavi"] >= 0, "Gurunavi_Positive"] = 1
# 負の場合
closing_data["Gurunavi_Negative"] = 0
closing_data.ix[closing_data["Gurunavi"] < 0, "Gurunavi_Negative"] = 1
training_data = pd.DataFrame(
# column name is "<index>_<day>".
columns= ["Gurunavi_Positive", "Gurunavi_Negative"] + [s + "_1" for s in stocks[1:]]
)
for i in range(7, len(closing_data)):
data = {}
# We will use today's data for positive/negative labels
data["Gurunavi_Positive"] = closing_data["Gurunavi_Positive"].ix[i]
data["Gurunavi_Negative"] = closing_data["Gurunavi_Negative"].ix[i]
# Use yesterday's data for world market data
for col in stocks[1:]:
data[col + "_1"] = closing_data[col].ix[i - 1]
training_data = training_data.append(data, ignore_index=True)
# 予測するのに用いるデータ
# Gurunavi_Positive, Gurunavi_Negative
predictors_tf = training_data[training_data.columns[2:]]
# 正解データ
classes_tf = training_data[training_data.columns[:2]]
# トレーニングとテストデータを分割します。
training_set_size = int(len(training_data) * 0.8)
test_set_size = len(training_data) - training_set_size
training_predictors_tf = predictors_tf[:training_set_size]
training_classes_tf = classes_tf[:training_set_size]
test_predictors_tf = predictors_tf[training_set_size:]
test_classes_tf = classes_tf[training_set_size:]
# コードからマジックナンバーを削除するためのプレディクタ数とクラス数の変数を定義します。
num_predictors = len(training_predictors_tf.columns)
num_classes = len(training_classes_tf.columns)
# TensorBoardのグラフに出力するスコープを指定
with tf.Graph().as_default():
#
stock_placeholder = tf.placeholder("float", [None, num_predictors])
#
labels_placeholder = tf.placeholder("float", [None, num_classes])
# inference()を呼び出してモデルを作る
model = inference(num_predictors, num_classes, stock_placeholder)
# loss()を呼び出して損失を計算
loss_value = loss(model, labels_placeholder)
# training()を呼び出して訓練して学習モデルのパラメーターを調整する
training_step = training(labels_placeholder, model)
# 精度の計算
accuracy = accuracy(model, labels_placeholder)
# 保存の準備
saver = tf.train.Saver()
# Sessionの作成(TensorFlowの計算は絶対Sessionの中でやらなきゃだめ)
sess = tf.Session()
# 変数の初期化(Sessionを開始したらまず初期化)
sess.run(tf.global_variables_initializer())
# TensorBoard表示の設定(TensorBoardの宣言的な?)
summary_op = tf.summary.merge_all()
# train_dirでTensorBoardログを出力するpathを指定
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
for step in range(1, 10000):
sess.run(
training_step,
feed_dict={
stock_placeholder: training_predictors_tf.values,
labels_placeholder: training_classes_tf.values.reshape(len(training_classes_tf.values), 2)
}
)
if step % 100 == 0:
train_accuracy = sess.run(
accuracy,
feed_dict={
stock_placeholder: training_predictors_tf.values,
labels_placeholder: training_classes_tf.values.reshape(len(training_classes_tf.values), 2)
}
)
print "step %d, training accuracy %g"%(step, train_accuracy)
# 1step終わるたびにTensorBoardに表示する値を追加する
summary_str = sess.run(
summary_op,
feed_dict={
stock_placeholder: training_predictors_tf.values,
labels_placeholder: training_classes_tf.values.reshape(len(training_classes_tf.values), 2)
}
)
summary_writer.add_summary(summary_str, step)
# 訓練が終了したらテストデータに対する精度を表示する
print "test accuracy %g"%sess.run(
accuracy,
feed_dict={
stock_placeholder: test_predictors_tf.values,
labels_placeholder: test_classes_tf.values.reshape(len(test_classes_tf.values), 2)
}
)
実行結果
python stock_price_prediction.py
2017-06-06 15:26:17.251792: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
2017-06-06 15:26:17.251816: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2017-06-06 15:26:17.251824: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2017-06-06 15:26:17.251831: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2017-06-06 15:26:17.251838: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
step 100, training accuracy 0.504931
step 200, training accuracy 0.504931
step 300, training accuracy 0.504931
step 400, training accuracy 0.504931
step 500, training accuracy 0.504931
step 600, training accuracy 0.504931
step 700, training accuracy 0.502959
step 800, training accuracy 0.504931
step 900, training accuracy 0.510848
step 1000, training accuracy 0.510848
step 1100, training accuracy 0.510848
step 1200, training accuracy 0.512821
step 1300, training accuracy 0.510848
step 1400, training accuracy 0.508876
step 1500, training accuracy 0.510848
step 1600, training accuracy 0.510848
step 1700, training accuracy 0.510848
step 1800, training accuracy 0.512821
step 1900, training accuracy 0.510848
step 2000, training accuracy 0.508876
step 2100, training accuracy 0.502959
step 2200, training accuracy 0.499014
step 2300, training accuracy 0.500986
step 2400, training accuracy 0.502959
step 2500, training accuracy 0.504931
step 2600, training accuracy 0.506903
step 2700, training accuracy 0.506903
step 2800, training accuracy 0.514793
step 2900, training accuracy 0.512821
step 3000, training accuracy 0.508876
step 3100, training accuracy 0.504931
step 3200, training accuracy 0.508876
step 3300, training accuracy 0.506903
step 3400, training accuracy 0.510848
step 3500, training accuracy 0.510848
step 3600, training accuracy 0.512821
step 3700, training accuracy 0.512821
step 3800, training accuracy 0.508876
step 3900, training accuracy 0.510848
step 4000, training accuracy 0.512821
step 4100, training accuracy 0.510848
step 4200, training accuracy 0.510848
step 4300, training accuracy 0.512821
step 4400, training accuracy 0.512821
step 4500, training accuracy 0.512821
step 4600, training accuracy 0.512821
step 4700, training accuracy 0.514793
step 4800, training accuracy 0.512821
step 4900, training accuracy 0.512821
step 5000, training accuracy 0.514793
step 5100, training accuracy 0.514793
step 5200, training accuracy 0.514793
step 5300, training accuracy 0.512821
step 5400, training accuracy 0.514793
step 5500, training accuracy 0.514793
step 5600, training accuracy 0.518738
step 5700, training accuracy 0.516765
step 5800, training accuracy 0.518738
step 5900, training accuracy 0.518738
step 6000, training accuracy 0.516765
step 6100, training accuracy 0.514793
step 6200, training accuracy 0.518738
step 6300, training accuracy 0.52071
step 6400, training accuracy 0.518738
step 6500, training accuracy 0.52071
step 6600, training accuracy 0.522682
step 6700, training accuracy 0.522682
step 6800, training accuracy 0.522682
step 6900, training accuracy 0.52071
step 7000, training accuracy 0.52071
step 7100, training accuracy 0.518738
step 7200, training accuracy 0.514793
step 7300, training accuracy 0.516765
step 7400, training accuracy 0.516765
step 7500, training accuracy 0.514793
step 7600, training accuracy 0.512821
step 7700, training accuracy 0.512821
step 7800, training accuracy 0.514793
step 7900, training accuracy 0.514793
step 8000, training accuracy 0.518738
step 8100, training accuracy 0.516765
step 8200, training accuracy 0.516765
step 8300, training accuracy 0.514793
step 8400, training accuracy 0.516765
step 8500, training accuracy 0.518738
step 8600, training accuracy 0.516765
step 8700, training accuracy 0.516765
step 8800, training accuracy 0.516765
step 8900, training accuracy 0.516765
step 9000, training accuracy 0.516765
step 9100, training accuracy 0.516765
step 9200, training accuracy 0.516765
step 9300, training accuracy 0.516765
step 9400, training accuracy 0.516765
step 9500, training accuracy 0.514793
step 9600, training accuracy 0.512821
step 9700, training accuracy 0.512821
step 9800, training accuracy 0.512821
step 9900, training accuracy 0.512821
test accuracy 0.464567
TensorBoard
出したかったのですが、ちょっと正常な状態ではなさそうなので上げません。
補足
- accuracy 0.464567ということは上がるか下がるか当たるのが約4割ということで全然あてにならない(?)
- ここまで行き着く以前に学習が固定の数字だったのがやっと変動してきたところ。
- 精度を上げるためにはデータが少ないのか、調整が必要なのか、学習要素が少ないのか、それとも理解が誤っているのかといった状態です。
グラフを出したい時
# pd.DataFrame()を折れ線グラフにします。
data.plot(figsize = (10, 5), linewidth = 0.5)
# グラフを描画します
plt.show()