はじめに
前回、顔分類器を畳み込みニューラルネットワーク (CNN)を使って作成しましたが、実はこれはまだ初歩の初歩に過ぎなく機械学習の世界はとてつもないスピードで進歩していることを知りました。
命がけで倒したボスが実は1万以上いる敵の中で最弱なのだと知りました。
毎年のように新しいアルゴリズムが論文発表されたり、認識精度を競い合う大会などが行われているようで、進歩している理由としては、認識精度と処理速度の向上が主な目的なようです。
その中で、今回一番最新のアルゴリズムであるSingle Shot MultiBox Detector(SSD)のチュートリアルとなるものを動かしてみました。
詳しい業界内の進歩を読みたい方は以下のページがとてもわかりやすいです。
SSD: Single Shot MultiBox Detector (ECCV2016)
要約すると
CNN → R-CNN → FAST R-CNN → FASTER R-CNN → SSD(今ここ)
今回投稿までに時間がかかった経緯
5日くらいハマりっぱなしで、結果解決の糸口が見いだせませない問題がありました。
というのも、実装自体はPythonを用いるのですが、実はそれを実装する上で必要なライブラリの選択肢が非常に多いということです。
当初は、Tesnorflowを用いた実装しているものをと思いましたが、あまりにも理解ができなさそうなコードなのもあり、ただ無心に動かす目的だと面白くないため、まだコードがミニマムなKerasで実装したものを動かすことにしました。
参考コード
Kurasは問題なかったのですが、こちらは動画を直接認識するような仕組みであり、OpenCV、FFmpeg、GTK2が必要なものでした。
結論から申しますと、Homebrewを使ってOpenCVとFFmpegまでは入れられたもの、GTK2がOpenCVにビルドされず、動画読み込みが行われない状態に陥ってしまいました。
brew editして色々書き換えたり、ビルドオプションやこれいれればいいよみたいなもの色々いれてためしましたが、結論HomebrewのOpenCVはGTKをビルドできない設定になっているようでした。
諦めの結論に至った記事
ちなみに、ビルドから試みかけましたが、やはり前評判通りFFmpegのビルドがとても面倒くさかったので途中で諦めました。
試行錯誤の結果
上記の元、Chainerを使ったものを試してみることにしました。こちらは動画でなく、静止画を検出できます。
chainer-SSD
環境
Git
brew install git
Python3.6.1
brew install python3
PATHの設定
if [ -d $(brew --prefix)/lib/python3.6/site-packages ];then
export PYTHONPATH=$(brew --prefix)/lib/python3.6/site-packages:$PYTHONPAT
fi
Cython
pip3 install cython
Numpy
pip3 install numpy
Chainer
pip3 install chainer
Matplotlib
pip3 install matplotlib
git clone
cd {ワークスペース}
git clone https://github.com/ninhydrin/chainer-SSD.git
準備
cd {ワークスペース}/chainer-SSD/util
python3 setup.py build_ext -i
※ warningが出ますが、終了していれば問題なく動くはずです。
実行
実行用の画像が2枚入れてくれているので、まずはこちらを実行してみましょう。
cd {ワークスペース}/chainer-SSD
python3 demo.py img/dog.jpg
/usr/local/lib/python3.6/site-packages/skimage/transform/_warps.py:84: UserWarning: The default mode, 'constant', will be changed to 'reflect' in skimage 0.15.
warn("The default mode, 'constant', will be changed to 'reflect' in "
※ エラーが出ますが、終了していれば問題なく動くはずです。
結果
犬と車と自転車

魚型の自転車と人

色々試してみた
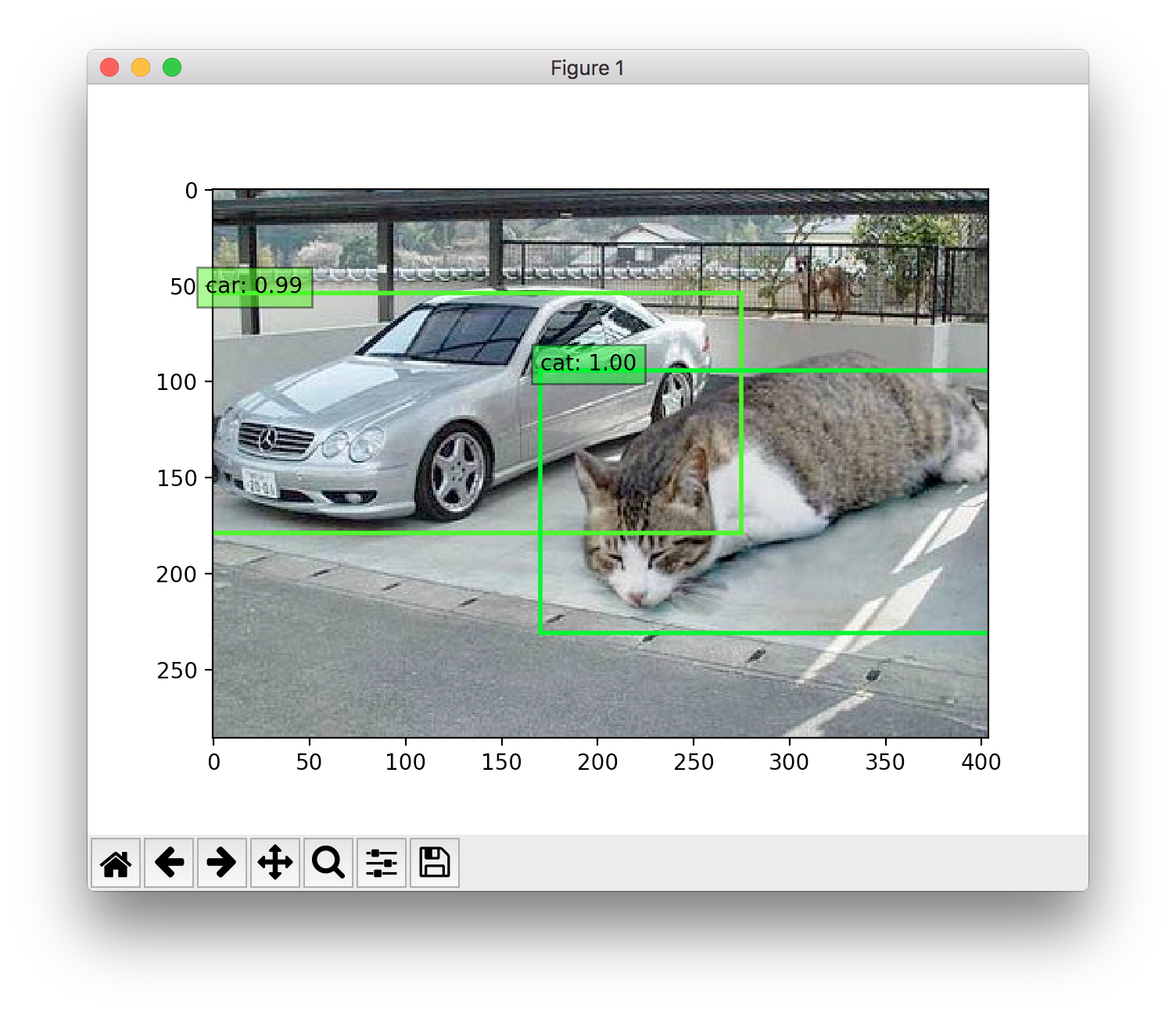
車と猫
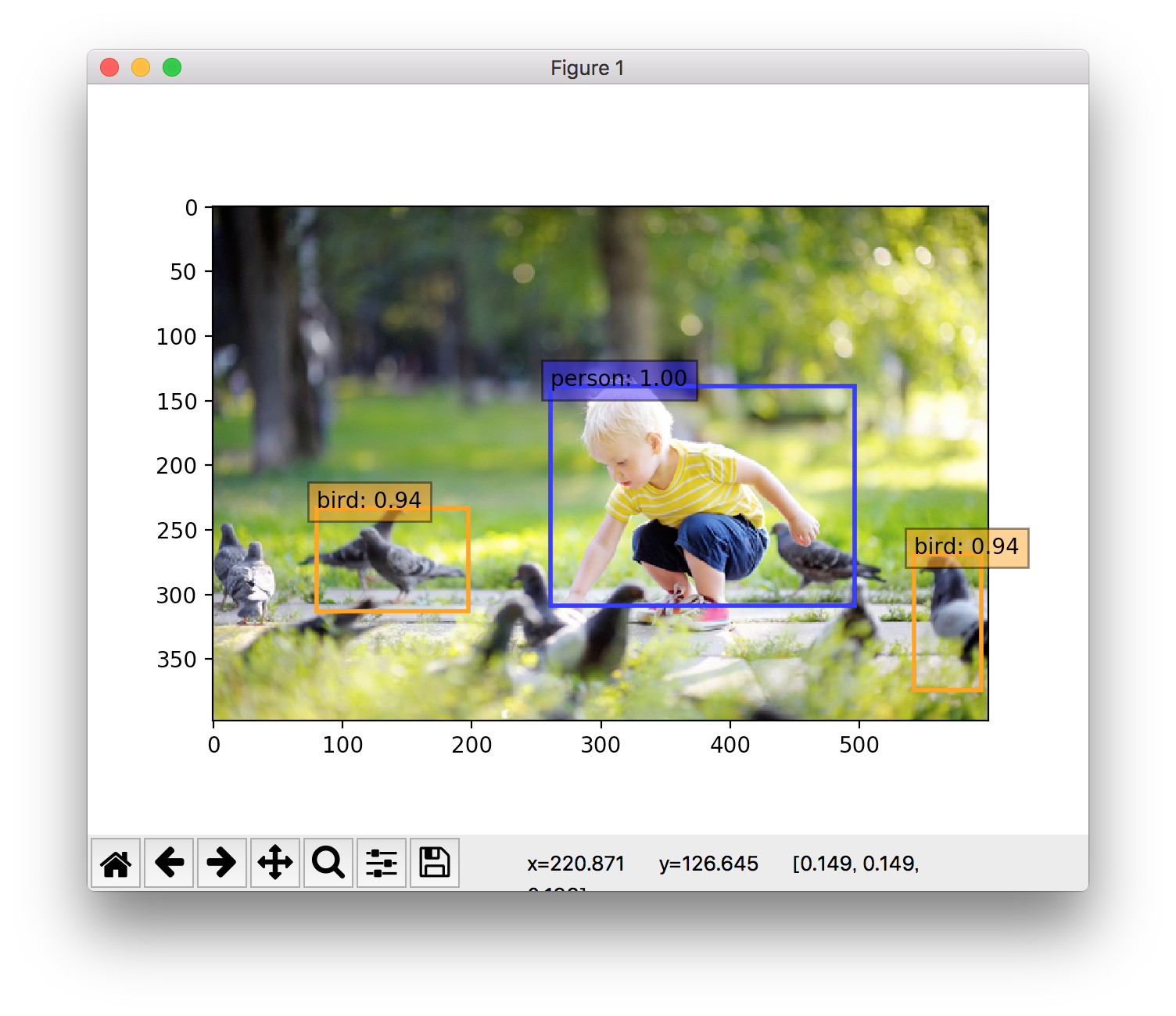
人と鳥
アライグマ
 ※ 見事(?)認識せず
※ 見事(?)認識せず
車椅子の犬

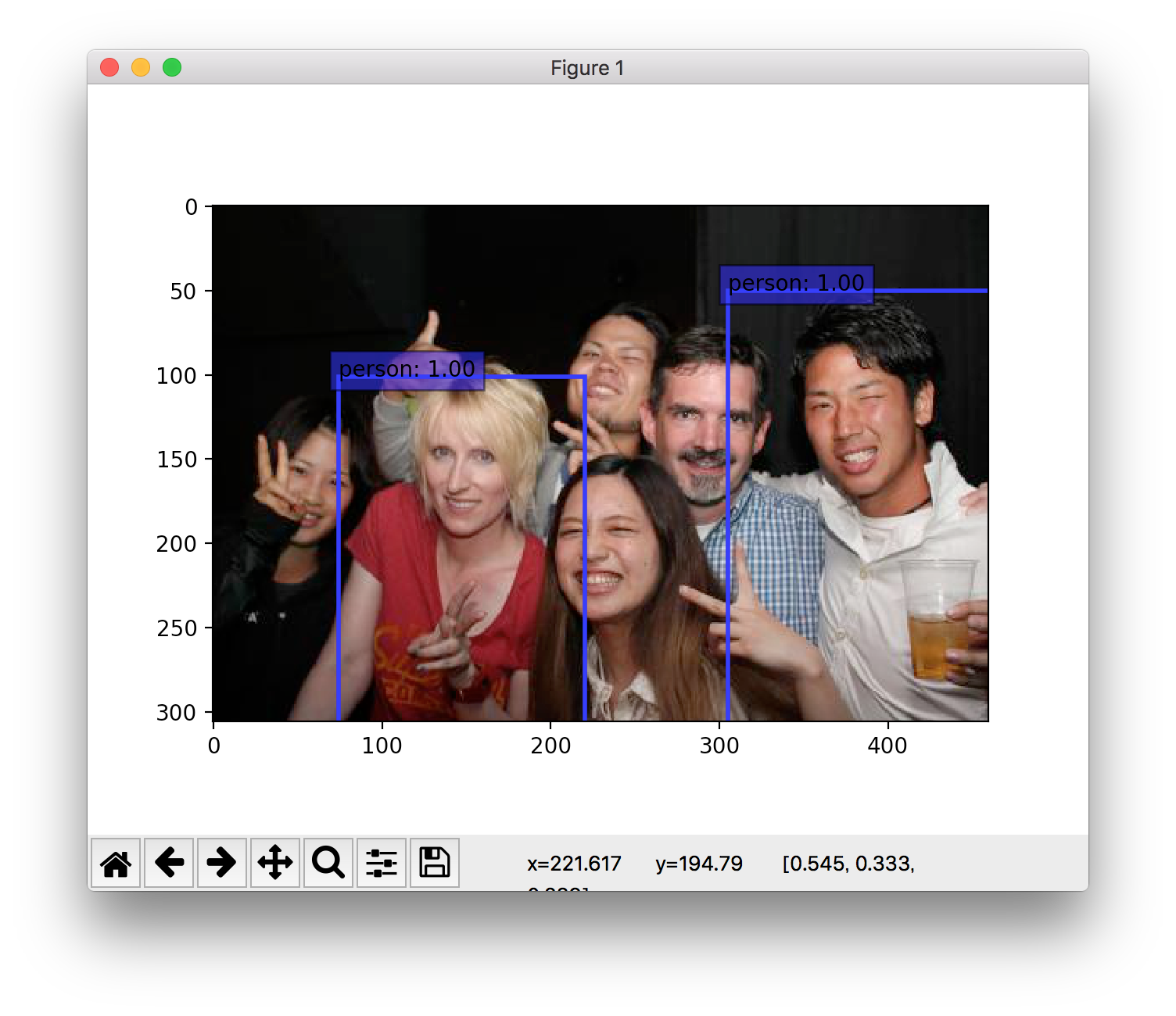
大勢の人
感想
- 1画像に対して3物体くらいが検出精度としては限界な感じがあった。
- 画像に写っている物体が小さすぎると検出されない。(リサイズしているからかと思う)
- 背面や横向きやぶれているいるものの精度はまだあまり高くなさそう。(学習が足りないのかもしれない)
- 速度はもともと1画像に対してそこまで遅いと感じてはいなかったので変わらない。(体感で5秒程度)
まとめ
- ソースコードを読んでオリジナルの画像データを学習させて再度試してみたいなと思います。
- 動画やカメラから直接認識をやってみたいです。(MacかCentOSで簡単な構築方法あれば)
- 日本人または日本語訳された情報が少なすぎる。先生かお互いに教えられるコミュニティがほしいところです。