#概要
動画像における超解像手法であるDeepSRを参考に実装したので、それのまとめの記事です。
論文の概要をメモした記事もあるのでそちらも是非!
【論文メモ】超解像手法/DeepSRの論文まとめ
今回紹介するコードはGithubにも載せています。
#目次
- 実装したアルゴリズム
- 論文との相違点
- 使用したデータセット
- 画像評価指標PSNR
- コードの使用方法
- 結果
- コードの全容
- 参考文献
1. 実装したアルゴリズム
今回、実装したアルゴリズムは以下の図の通りです。(図は論文から引用)
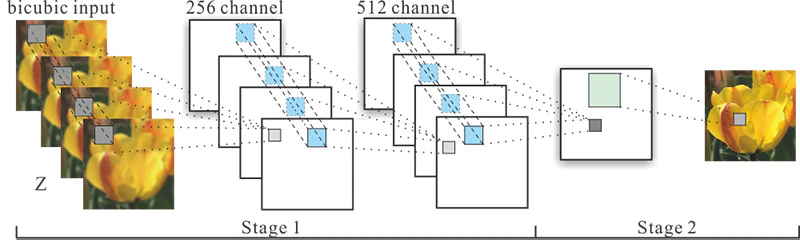
深層学習のモデルは、提案された論文と同じです。
3 Convolutin + 1 Deconvolutionとなっています。
コマンドラインで出力したモデルはこんな感じになっています。
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_0 (InputLayer) [(None, None, None, 0
__________________________________________________________________________________________________
input_1 (InputLayer) [(None, None, None, 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, None, None, 0
__________________________________________________________________________________________________
input_3 (InputLayer) [(None, None, None, 0
__________________________________________________________________________________________________
concatenate (Concatenate) (None, None, None, 4 0 input_0[0][0]
input_1[0][0]
input_2[0][0]
input_3[0][0]
__________________________________________________________________________________________________
conv2d (Conv2D) (None, None, None, 2 124160 concatenate[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, None, None, 5 131584 conv2d[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, None, None, 1 4609 conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_transpose (Conv2DTranspo (None, None, None, 1 626 conv2d_2[0][0]
==================================================================================================
Total params: 260,979
Trainable params: 260,979
Non-trainable params: 0
__________________________________________________________________________________________________
2. 論文との相違点
論文では、学習データに対しては、計算量が増大してしまうので簡略化していますが、
実際の高解像度化では、SR Draftとして高解像度画像の候補をいくつか生成して、それを入力画像とします。
そのうちの1枚はBicubicで補間した画像を使用します。
今回は、テストデータに対しても簡略化して実装を行いました。
具体的には、HR(正解画像)をガウシアンフィルタでぼかすことで、擬似的にSR Draftとしました。
これは、論文の学習データ生成方法と同じです。
3. 使用したデータセット
今回は、データセットにREDSを使用しました。
このデータセットは、動画像の超解像用のデータセットで、240種類の学習用データ、30種類の検証用データ、30種類のテスト用データの計300種類のデータセットです。
最近はこのデータセットを多用しています。
パスの構造はこんな感じ。
train_sharp - 001 - フレーム100枚
- 002 - フレーム100枚
- ...
val_sharp - 001 - フレーム100枚
- 002 - フレーム100枚
- ...
このデータをぼかしたりBicubicで縮小したりしてデータセットを生成しました。
4. 画像評価指標PSNR
今回は、画像評価指標としてPSNRを使用しました。
PSNR とは Peak Signal-to-Noise Ratio(ピーク信号対雑音比) の略で、単位はデジベル (dB) で表せます。
PSNR は信号の理論ピーク値と誤差の2乗平均を用いて評価しており、8bit画像の場合、255(最大濃淡値)を誤差の標準偏差で割った値です。
今回は、8bit画像を使用しましたが、計算量を減らすため、全画素値を255で割って使用しました。
そのため、最小濃淡値が0で最大濃淡値が1です。
dB値が高いほど拡大した画像が元画像に近いことを表します。
PSNRの式は以下のとおりです。
PSNR = 10\log_{10} \frac{1^2 * w * h}{\sum_{x=0}^{w-1}\sum_{y=0}^{h-1}(p_1(x,y) - p_2(x,y))^2 }
なお、$w$は画像の幅、$h$は画像の高さを表しており、$p_1$は元画像、$p_2$はPSNRを計測する画像を示しています。
5. コードの使用方法
① 学習データ生成
まず、Githubからコードを一式ダウンロードして、カレントディレクトリにします。
Windowsのコマンドでいうとこんな感じ。
C:~_keras_DeepSR>
次に、main.pyから生成するデータセットのサイズ・大きさ・切り取る枚数、ファイルのパスなどを指定します。
train_height = 50 #学習用データのサイズ
train_width = 50
test_height = 720 #テスト用データのサイズ
test_width = 1280
cut_num = 10 #1枚の画像から生成するデータ数
train_dataset_num = 10000 #生成するデータ数
test_dataset_num = 5
train_movie_path = "../../reds/train_sharp" #動画のフレームが入っているパス
test_movie_path = "../../rede/val_sharp"
指定したら、コマンドでデータセットの生成をします。
C:~_keras_DeepSR>python main.py --mode train_datacreate
これで、train_data_list.npzというファイルのデータセットが生成されます。
ついでにテストデータも同じようにコマンドで生成します。コマンドはこれです。
C:~_keras_DeepSR>python main.py --mode test_datacreate
② 学習
次に学習を行います。
設定するパラメータの箇所は、epoch数と学習率とかですかね...
まずは、main.pyの32~33行目
BATSH_SIZE = 128
EPOCHS = 300
後は、学習のパラメータをあれこれ好きな値に設定します。85~94行目です。
optimizers = tf.keras.optimizers.Adam(learning_rate=1e-4)
train_model.compile(loss = "mean_squared_error",
optimizer = optimizers,
metrics = [psnr])
train_model.fit({"input_0":train_x[0], "input_1":train_x[1], "input_2":train_x[2], "input_3":train_x[3]},
train_y,
epochs = EPOCHS,
verbose = 2,
batch_size = BATSH_SIZE)
optimizerはAdam、損失関数は最小二乗法を使用しています。
入力画像は今回は4枚で出力は1枚です。
学習はデータ生成と同じようにコマンドで行います。
C:~_keras_DeepSR>python main.py --mode train_model
これで、学習が終わるとモデルが出力されます。
③ 評価
最後にモデルを使用してテストデータで評価を行います。
これも同様にコマンドで行いますが、事前に①でテストデータも生成しておいてください。
C:~_keras_DeepSR>python main.py --mode evaluate
このコマンドで、PSNRの差分に応じて画像を出力してくれます。
6. 結果
出力した画像はこのようになりました。
なお、今回は輝度値のみで学習を行っているため、カラー画像には対応していません。
対応させる場合は、modelのInputのchannel数を変えたり、データセット生成のchannel数を変える必要があります。
元画像

低解像度画像(Bicubicで4倍縮小して元の画像サイズに拡大)
PSNR:25.04

生成画像
PSNR:34.06

凄く精細な画像が出力されましたが、実際はこんなに綺麗に出力されない気はします。
低解像度画像をガウシアンフィルタで生成しましたが、パラメータを調整したりしてより現実的な超解像モデルにするべきです。
4倍拡大のSR Draftは、ガウシアンフィルタのぼかしでは再現できないと思うんですよね...
論文は4倍もしっかりとできてましたけど、パラメータが公開されていないのでそこらへんは憶測でしている部分もあります。
自分のコードだと2倍だったらもう少し現実的かも、という感じです。
後はモデルのパラメータチューニングも必要かもです。
また、実際の動画像に処理をかける場合は、動画像をフレームに分解して、1枚ずつ処理を行う必要があります。
OpenCVで動画像をフレームごとに取得して、って感じですかね。
7. コードの全容
前述の通り、Githubに載せています。
思ったより記事が長くなったので、全部載せるのはやめておきます。
8. まとめ
今回は、最近読んだ論文のDeepSRを元に実装してみました。
結果見ても分かるように、いい結果になりすぎているので参考くらいがちょうどいいと思います笑
超解像の論文実装記事全然ないからもっと増えてくれ...!!!
参考文献
・Video Super-Resolution via Deep Draft-Ensemble Learning
今回参考にした論文。
・REDSのデータセット
今回使用したデータセット