![]() この記事は Recruit Engineers Advent Calendar 2016 の22日目の記事です。
この記事は Recruit Engineers Advent Calendar 2016 の22日目の記事です。![]()
昨日はmookjpさんのLet It Crashとは何かでした!ゴイスー!
本日はサーバサイドエンジニアとして従事している私がAWSでインフラ構築をした記事となります。
この記事を書く1週間程前はそろそろ記事の下書きをしておくかー。
と、やる気に満ち溢れていたのですが、悲しきかな・・・PS4 proが届き当時の気持ちはどこかに置いてきてしまったようで、急いで先程記事を書き終えました。
はじめに
日々やらねばいけないことが満ち溢れている中、運用やサーバトラブルに対して時間は割きたくないものです。例えば、EC2の突然死やメンテナンスです。
限られた時間の中でより効率的に時間を使いたいという欲求を皆様お持ちではないでしょうか。
そこで楽をしようと思い立ち、本エントリーの構成にしたのです。
使うツール
細かいものは省略して大枠だけ。
AWSで利用したサービス
細かいものは省略します。
- ALB
- AutoScaling
- EC2
- CloudWatch Events
- Lambda
- SNS
Immutable deployment
デプロイにおいてTerraformでやっていること
結論だけ先に書くと、
- DataSourceを使って最新版のAMIを取得
- ASGのLaunchConfigurationを作成
- ASGの更新
その他は基本Lambdaに任せています。
AMIの作成はDroneを使ってPackerを実行しています。
デプロイフロー
まずはアプリケーションリリースまでのデプロイフローを見てみましょう。
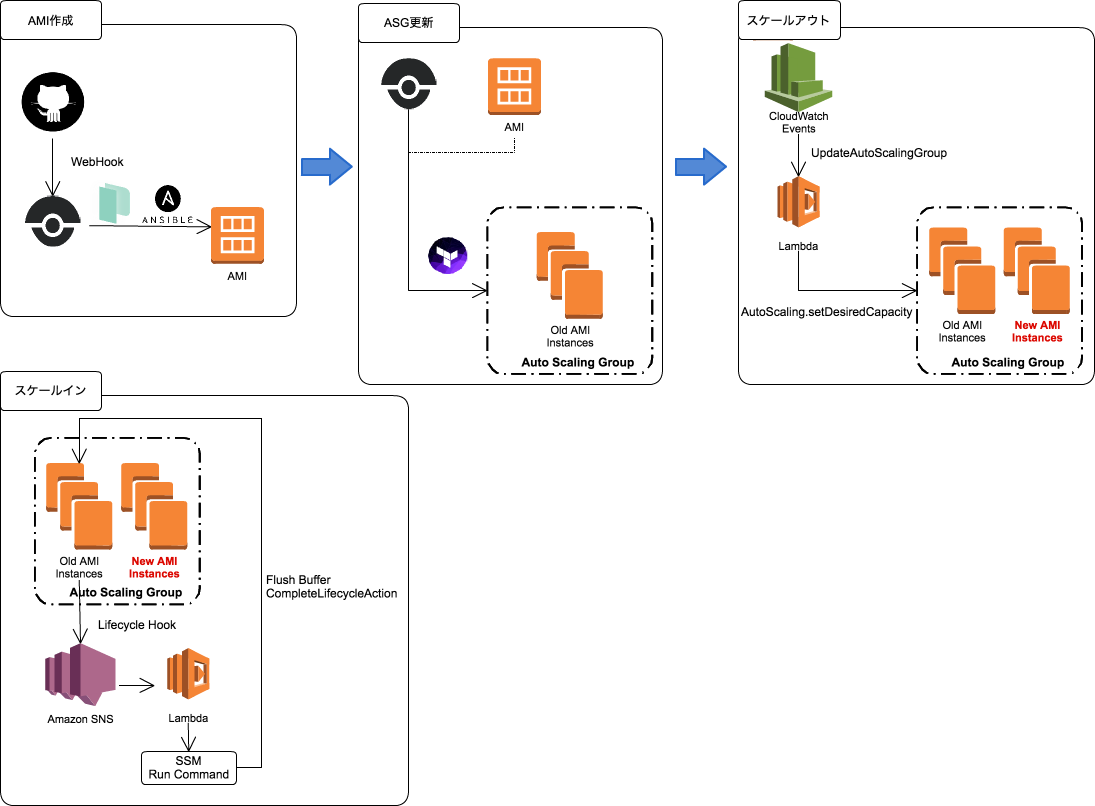
あまり複雑にならないよう心がけたつもりで、それぞれのSTEPで見たときにシンプルになれば良いかなと思いこのフローにしています。
ステップごとに見るフロー
1. AMI作成
CIサーバ
弊社ではGitHub Enterpriseを使っているので、今までJenkins2を使ってCIを回していましたが、やはりコンテナベースでテストを回さないとジョブがconflictするわけです。
一々レポジトリごとにDockerfile用意するのも面倒だったので、OSS版のDroneに切り替えました。
Droneを一言で表すなら「最高」。
DroneからAMIをビルドする
PackerとAnsibleを使ってAMIを作成しています。
後述しますが、この時新しいAMIを作るうえで利用するAMIは、予め用意しておいたベースのAMIで、そこから新しいバージョンのシステムをデプロイ & ビルド(npm install / bundle install...)してAMIを作成しています。
2. ASG更新
Terraformを使ってASGを更新する
LaunchConfigurationの更新は行えないため、Terraformを使ってLaunchConfigurationを作成し、既存のASGに紐付けています。
3. スケールアウト
新しいAMIを利用したEC2インスタンスを立ち上げ
ASGの更新をトリガーにCloudWatch EventsからLambdaを起動しています。
このLambdaでは下記を実行しています。
- 更新したAutoScalingGroupの
DesiredCapacityを取得 -
setDesiredCapacity(DesiredCapacity * 2)を実行して、新しいAMIのインスタンスを立ち上げる
ここまでで新しいバージョンのシステムをリリースすることが出来ました。
4. スケールイン
古いAMIインスタンスの破棄方法
スケールインは、CloudWatchとLambdaを使ってdesired capacityを元に戻しています。
とはいえ、いきなりTerminateされても困る
Fluentdを使っているので、いきなりTerminateされてバッファがflushされないまま破棄されても困ります。
なので、Lifecycle Hookを使って下記を実行します。
- スケールイン前にSNSへ通知を送る
- SNS通知をトリガーにLambdaを実行する
- LambdaからSSMのRun Commandを実行
- Fluentdのバッファをflush
- CompleteLifecycleActionを実行
これでFluentdのバッファをflushさせつつ、スケールインさせることが出来ました。
それぞれ工夫したところ
ゴールデンイメージの作成
デプロイの度に1からAnsibleのプロビジョニングを実行していると、とても時間がかかります。
なのでAMIをbase / application_base / applicationと分けていて、アプリケーションの更新だけであれば、baseから作成したapplication_baseを使って新しいAMIを作っています。
それぞれのAMIは、下記の役割で作っています。
- base
- 基本的にOSの設定(Timezone / Kernel parameters...)であったり、インタプリタのインストールであったり頻繁に変更が行われないものをプロビジョニングしています。
- application_base
- アプリケーションが依存するLinuxライブラリのインストール等を行っています。
- application
- アプリケーションのデプロイとビルドを行います。`npm install`や`npm run hoge`であったり`bundle install`はここで行っています。
システムの更新であればapplicationのビルドしか行いませんが、他のレポジトリで管理しているbaseもしくはapplication_baseの構成が変わった場合は、そちらのビルドが走ります。
Packer / Ansible
ディレクトリ構成
実際のものとは異なりますが、共通で読み込む変数とそうでないものでgroup_varsを使って切り替えています。
├── provisioners
│ ├── ansible.cfg
│ ├── base.yml
│ ├── group_vars
│ │ ├── all
│ │ │ ├── secrets.yml
│ │ │ └── vars.yml
│ │ ├── base
│ │ │ ├── secrets.yml
│ │ │ └── vars.yml
│ │ ├── development
│ │ │ ├── secrets.yml
│ │ │ └── vars.yml
│ │ ├── production
│ │ │ ├── secrets.yml
│ │ │ └── vars.yml
│ │ └── staging
│ │ ├── secrets.yml
│ │ └── vars.yml
│ ├── requirements.yml
│ ├── roles
│ └── site.yml
├── packer.json
└── variables
├── base.json
├── common.json
ファイル名がsecrets.ymlになっているものはAnsible Vaultで暗号化したファイルです。
復号化はプロビジョニング実行時にtemporaryのpasswordファイルを用意してansibleに読み込ませています。
こんな感じです。
"extra_arguments": [
"--tags",
"{{user `tags`}}",
"--vault-password-file",
".vault"
]
Ansible Galaxy
極力Ansibleのroleは、Ansible Galaxyのroleとして使えるように書いて、GitHub EnterpriseにあるAnsible Galaxy organizationにレポジトリを作っています。
なので、provisioners/requirements.ymlが置いてあります。
site.yml
実際のものとは異なりますが、こんな感じにしてtagでincludeするymlファイルを制御しています。
---
- include: base.yml tags=base
- include: hoge.yml tags=hoge
site.ymlは極力シンプルに。includeしている各ymlからroleを読み込んでいます。
Terraform
ディレクトリ構成
こちらも実際のものとは異なりますが、PackerやAnsible同様、共通で読み込む変数とそうでないものでこんな感じにしています。
また、Stageごとにtfstateを分けています。
├── environments
│ ├── common.tfvars
│ ├── development
│ │ ├── ami.tf
│ │ ├── main.tf
│ │ ├── provider.tf
│ │ ├── terraform.tfvars
│ │ └── variables.tf
│ └── production
│ ├── ami.tf
│ ├── main.tf
│ ├── provider.tf
│ ├── terraform.tfvars
│ └── variables.tf
├── provider.tf
├── vpc.tf
├── terraform.tfvars
└── variables.tf
Terraform Modules
Ansible Galaxy同様、こちらもorganizationを用意しレポジトリを作っています。
なので上のenvironments以下のディレクトリにあるmain.tfはmoduleを読み込み変数をセットするだけに留めています。
Lambda
Runtime
利用しているLambdaは全てnodejs4.3で記述していて、AWSリソースの操作はAWS SDKを利用しています。
デプロイ
apexを利用してLambdaのデプロイを行っています。
基本はapexのMultiple Environmentsに従った構成にしています。
├── functions
│ ├── hoge1
│ │ ├── function.development.json
│ │ ├── function.production.json
│ │ ├── index.js
│ │ └── package.json
│ └── hoge2
│ ├── function.development.json
│ ├── function.production.json
│ ├── index.js
│ └── package.json
├── project.development.json
└── project.production.json
project.jsonはこんな感じにして、
"nameTemplate": "{{.Project.Name}}_{{ .Project.Environment }}_{{.Function.Name}}",
同一ソースで異なるfunction名かつ、それぞれが異なる環境変数の値を保持することが出来ました。
最後に
AMIのビルドまでをアプリケーションのパッケージングに見立て構築しています。
本来、この思想であればコンテナを使うほうが楽だと思っていますが、アプリケーションのcontainerizedが出来ていなかったのでこうなっています。
また、当初はALBのリスナー付け替えでBlue-Green Deploymentにしようか悩んでいたのですが、富豪じゃないし結局Immutable deploymentを選択しました。
全体的にざっくりとしか書いていません。本当は短い時間の中で紆余曲折あり今の形になっているのですが、それぞれのもっと細かい話は別の記事で書こうと思います。![]()
次の記事は、kadoppeさんです!よろしくお願いします!