はじめに
毎日流れてくるIT業界の最新ニュースやAWSアップデート情報などのトレンドを効率的に捕捉するために、これまで、RSSをMicrosoft Teamsのスレッドに自動的に配信する仕組みを作ったり、Amazon Bedrock Agentを活用して記事を要約させたりと、様々なアプローチを試してきました。
おそらく、同じようなことをされている方も多いのではないかと思われます。
さて、これまでは、Teamsの機能を駆使しながら、生成AIによる推論やその他最小限の処理だけをAWS側のサービスに任せてきました。
しかし、ある時、それまでのアーキテクチャで出来ることの限界を悟り、本腰を入れて全体を改修するに至りました。
本記事では、この活動の成果として出来上がった、Google Newsの豊富な情報源から自動的にニュース記事を取得し、Amazon Bedrockで扱える生成AIのモデルを活用して記事の要約と解説を行い、Webhookを利用して配信する仕組みを紹介します。
今回は、AWSのサーバレスアーキテクチャ(Lambda、Step Functions、DynamoDB)を採用することで、運用負荷を最小限に抑えながらスケーラブルかつ柔軟なシステムを実現しています。
何が限界だったのか
これまでは、ほぼ以下の記事の内容に近いアプローチで、Power Automateのコネクタを使い、Lambda関数を介してAmazon Bedrockに接続し、推論の結果得られた解説の文章を受信し、Teamsに書き込むという方式を実装していました。
しかし、このアプローチでは、Amazon Bedrock側で推論に時間がかかった場合に、Azure Logic Appsの制限によって強制的にタイムアウトする可能性があります。
以下のリンク先を読むと送信要求のタイムアウトは120秒(2分)で、推論が長くなった場合には、タイムアウトしてしまうことが分かります。
最近、Amazon BedrockでClaude 3.7 Sonnetがリリースされ、特に解説などの構造化された文章の生成については非常に論理的で解像度の高い結果を得られることが分かってきましたが、それ故に人気も高いのか利用者が多いようで、時間帯によっては推論に2分以上かかることが増えていました。
Power Automateの標準コネクタによってRSS自体は配信されますが、その後の記事の解説が続かないということで、エクスペリエンスが著しく下がっていました。
もしかすると、今回の事象はClaude 3.7 Sonnetの利用が落ち着くことによって、つまり時間の経過によって解決されるかもしれませんが、今後はより大きなモデルへの対応や、より時間のかかるReasoningやThinkingに対応する必要性が一層高まると予想し、本腰を入れて対処するなら今このタイミングであろうと考えました。
改修後のアーキテクチャ
Webhook以外の全ての機能をAWSに移行し、アーキテクチャの最終形は以下のようになりました。
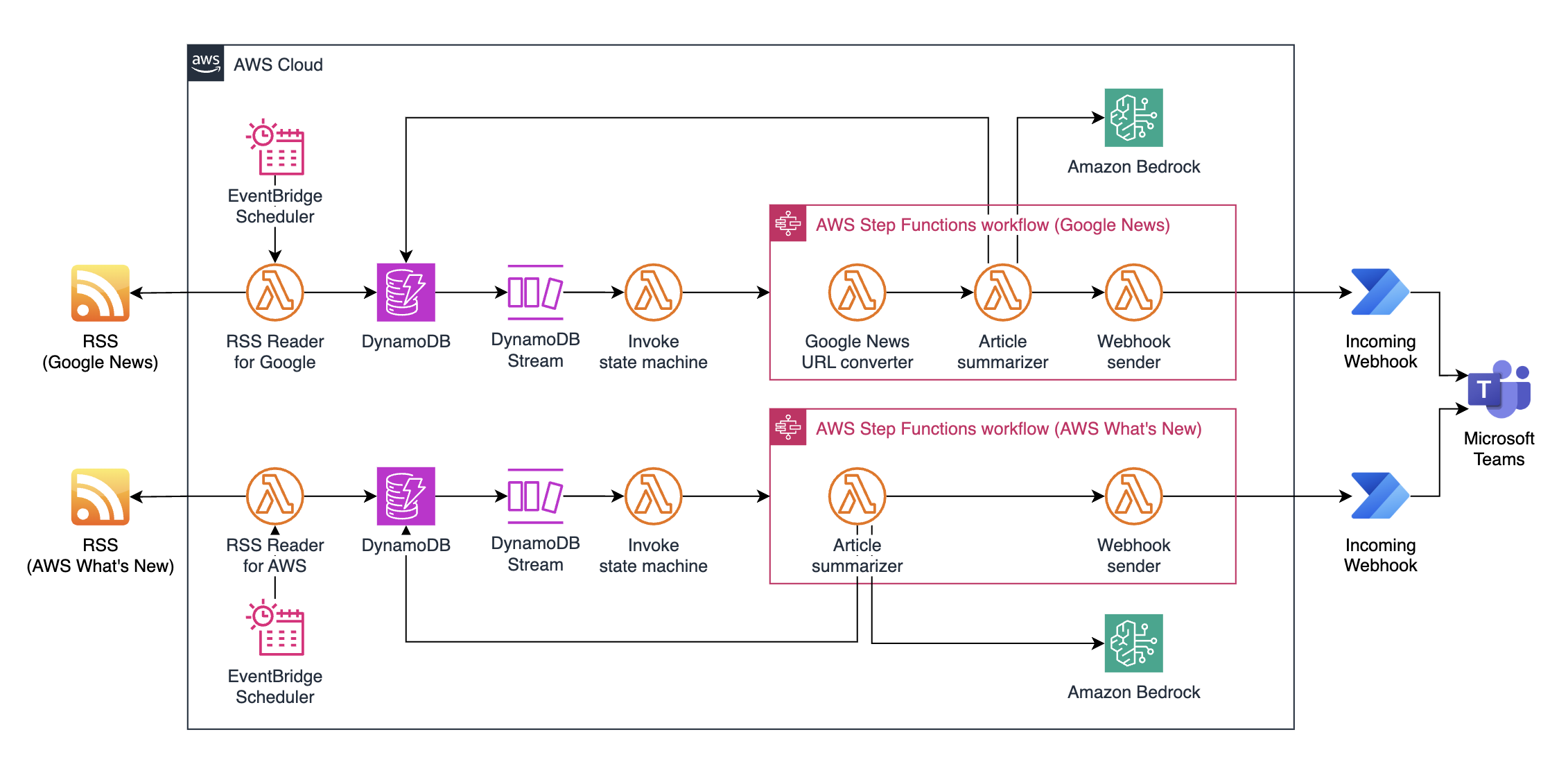
以降は、本アーキテクチャのポイントを解説していきます。
1. RSS Reader
一連の処理は、EventBridgeによって定期的に起動するLambda関数からスタートします。
このLambda関数は、EventBridgeによって定期的に実行され、RSSを取得し、本日かつ新しい(未登録の)ニュースであるかどうかを確認し、条件に合致したニュースのデータをDynamoDBに保存します。
RSSのデータは、非常に原始的な手法で取得しています。
try:
response = urllib.request.urlopen(rss_url)
xml_data = response.read()
except Exception as e:
logger.error(f"RSSフィードの取得エラー: {e}")
return {"statusCode": 500, "body": "RSSフィードの取得に失敗しました。"}
try:
root = ET.fromstring(xml_data)
except Exception as e:
logger.error(f"XMLパースエラー: {e}")
return {"statusCode": 500, "body": "RSSフィードXMLのパースに失敗しました。"}
channel = root.find("channel")
if channel is None:
logger.error("RSSフィードにchannelが存在しません")
return {"statusCode": 500, "body": "RSSフィードエラー: channelが見つかりません。"}
items = channel.findall("item")
上記の処理でRSSフィードに含まれるアイテムは全件取得するものの、当日のニュースのみをDynamoDBに問い合わせて存在確認し、さらに存在した場合のアップデートはしないことにしており、クエリ回数を減らしてコストが高騰しないように工夫しています。
for item in items:
title_elem = item.find("title")
link_elem = item.find("link")
pubDate_elem = item.find("pubDate")
description_elem = item.find("description")
title = title_elem.text if title_elem is not None else ""
link = link_elem.text if link_elem is not None else ""
pubDate = pubDate_elem.text if pubDate_elem is not None else ""
summary = description_elem.text if description_elem is not None else ""
# 公開日時を "YYYY-MM-DD" 形式に変換
if pubDate:
try:
parsed_time = email.utils.parsedate(pubDate)
published_date = datetime.datetime(*parsed_time[:6]).strftime("%Y-%m-%d")
except Exception as e:
logger.error(f"pubDateのパースエラー: {pubDate} - {e}")
published_date = pubDate
else:
published_date = ""
# 「本日更新」かどうかチェック
if published_date != today_str:
logger.info(f"アイテム {link} は本日({today_str})ではないためスキップ: {published_date}")
continue
# DynamoDB登録用のアイテムデータ
item_data = {
"id": link,
"title": title,
"link": link,
"published": published_date, # GSI用に日付形式で保存
"summary": summary
}
# 既存アイテムの存在確認
try:
existing = table.get_item(Key={"id": link})
existing_item = existing.get("Item")
except Exception as e:
logger.error(f"DynamoDBからの取得エラー: {e}")
continue
if not existing_item:
# 新規アイテムの場合は挿入するのみ
try:
table.put_item(Item=item_data)
logger.info(f"新規アイテム挿入: {link}")
except Exception as e:
logger.error(f"新規アイテム挿入エラー: {link} - {e}")
else:
# 既にアイテムが存在する場合は何もしない
logger.info(f"アイテムは既に存在: {link}")
2. DynamoDB Streamsによるトリガー
DynamoDBにアイテムが登録された時に、DynamoDB StreamsによってアイテムのデータをイベントとしたLambda関数をトリガーできます。
今回はこのDynamoDB Streamsを活用して、DynamoDBに保存したデータを非同期で生成AIによる記事の解説(要約)処理と、Webhookに対する要約の送信を行う処理に渡していきます。
記事の解説を行うには、URLを開いて記事の中身を読み込むことと、生成AIに対する推論のリクエストを連続して実行するため、Step Functionsを使用します。
しかし、記事執筆時点(2025年3月)において、DynamoDB StreamsはStep Functionsのステートマシンを直接実行することができません。
そこで、DynamoDB Streamsは「Step Functionsステートマシンを呼び出すLambda関数」を実行することになります。
ステートマシンのARNは環境変数に渡しておきます。
# Step Functionsのクライアントを初期化
sf_client = boto3.client('stepfunctions')
def lambda_handler(event, context):
try:
# DynamoDB StreamイベントそのままをStep Functionsに渡す
if not event.get('Records'):
return {
'statusCode': 400,
'body': json.dumps('No records found in the event')
}
# 'eventName'が'INSERT'の場合のみ処理を行う
for record in event['Records']:
if record.get('eventName') == 'INSERT':
# Step Functionsステートマシンに渡す入力データ
input_data = event # そのままのイベントデータを渡す
# 環境変数からステートマシンのARNを取得
state_machine_arn = os.environ.get('STATE_MACHINE_ARN')
if not state_machine_arn:
return {
'statusCode': 400,
'body': json.dumps('STATE_MACHINE_ARN environment variable not set')
}
# Step Functionsステートマシンを開始
response = sf_client.start_execution(
stateMachineArn=state_machine_arn,
input=json.dumps(input_data) # イベントデータをそのまま渡す
)
# 実行結果を返す
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Step Function started successfully',
'executionArn': response['executionArn']
})
}
# 'INSERT'でない場合は何もしない
return {
'statusCode': 200,
'body': json.dumps('Event is not an INSERT, no action taken')
}
except Exception as e:
logging.error(f"Error occurred: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps(f"Error occurred: {str(e)}")
}
3. Step Functions ステートマシン
ステートマシン内では、以下の処理を連続して実行します。
(1) Google NewsのURLを解析
RSSのソースがGoogle Newsである場合のみ実行します。
この処理の解説は非常に長くなり、かつディープなものになりますので、以下の記事に分けています。
詳細は以下の記事をご覧ください。
(2) ニュース記事の内容を読み込む
ニュース記事を読み込むための処理は、以下のコードで実行できます。
この関数をLambda関数で呼び出し、結果を得て、次の要約処理を実行します。
従来、Teamsのコネクタだけの処理では難しかった、リトライの機構も指数バックオフを活用して導入しています。
def scrape_article(url):
max_retries = 10
attempt = 0
html = ""
# ヘッダーを設定
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "ja,en-US;q=0.9,en;q=0.8"
}
while attempt < max_retries:
try:
response = requests.get(url, timeout=10, headers=headers)
if response.status_code == 200:
html = response.text
break # 正常に取得できたのでループを抜ける
else:
print(f"Attempt {attempt+1}: Failed to fetch url: {url} with status code: {response.status_code}")
except Exception as e:
print(f"Attempt {attempt+1}: Exception occurred while fetching url: {url} - {str(e)}")
attempt += 1
if attempt < max_retries:
# 指数バックオフ+ジッター:基本待機時間10秒×2^attemptに0~5秒のランダムを加える
wait_time = 10 * (2 ** attempt) + random.uniform(0, 5)
print(f"Waiting for {wait_time:.2f} seconds before retrying...")
time.sleep(wait_time)
if not html:
return ""
try:
soup = BeautifulSoup(html, 'html.parser')
# script, styleタグを削除
for tag in soup(["script", "style"]):
tag.decompose()
# <article>タグがあれば優先的に抽出、それ以外は<body>内の<p>タグを連結
article_tag = soup.find("article")
if article_tag:
text = article_tag.get_text(separator="\n", strip=True)
else:
body_tag = soup.find("body")
if body_tag:
paragraphs = body_tag.find_all("p")
texts = [p.get_text(separator=" ", strip=True) for p in paragraphs]
text = "\n".join(texts)
else:
text = soup.get_text(separator="\n", strip=True)
# 不要な空白を除去し、約4000文字に切り詰める
text = " ".join(text.split())
if len(text) > 4000:
text = text[:4000]
return text
except Exception as e:
print("Error processing HTML:", str(e))
return ""
(3) ニュース記事の要約
以下のような、Amazon Bedrockに問い合わせて回答を得るための処理をする関数を用意しておきます。
タイムアウトはLambda関数の設定で15分まで伸ばし、従来の制限であった2分を大幅に超える長さの推論にも対応できるようになりました。
# Lambdaコンテナの再利用を考慮して、グローバルにクライアントを生成
bedrock_client = boto3.client('bedrock-runtime')
def lambda_handler(event, context):
# HTTPメソッドの取得: "httpMethod" または requestContext/http/method を利用
http_method = event.get("httpMethod")
if not http_method:
http_method = event.get("requestContext", {}).get("http", {}).get("method")
if http_method != "POST":
return {
"statusCode": 405,
"body": json.dumps({"error": "Method not allowed. Use POST."}, ensure_ascii=False)
}
# リクエストボディのパース
try:
body = json.loads(event.get("body", "{}"))
except Exception as e:
return {
"statusCode": 400,
"body": json.dumps({"error": "Invalid JSON in request body."}, ensure_ascii=False)
}
# "prompt" と "model_id"(もしくは "modelId")を取得
prompt = body.get("prompt")
model_id = body.get("model_id") or body.get("modelId")
if not prompt or not model_id:
return {
"statusCode": 400,
"body": json.dumps({"error": "Both 'prompt' and 'model_id' are required."}, ensure_ascii=False)
}
try:
# Amazon Bedrockへ渡すメッセージを構築
messages = [
{
"role": "user",
"content": [
{"text": prompt}
]
}
]
# converse APIの呼び出し
response = bedrock_client.converse(
modelId=model_id,
messages=messages
)
# UTF-8としてシリアライズし、レスポンスヘッダーにも charset を指定
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json; charset=utf-8"
},
"body": json.dumps(response, default=str, ensure_ascii=False)
}
except Exception as e:
return {
"statusCode": 500,
"body": json.dumps({"error": str(e)}, ensure_ascii=False)
}
この関数に対して、モデルをClaude 3.7 Sonnet (us.anthropic.claude-3-7-sonnet-20250219-v1:0) に指定し、以下のようにプロンプトを与えることで、非常に詳細な記事の解説を得ることができます。
prompt = (
f"以下は記事本文です:\n{text}\n\n"
"オタクの話は長いし、細かいし、早口ですが、説得力が高くて聞きごたえがあります。"
"あんな感じでオタクになりきって、緻密かつ高度で細かすぎるけど楽しく面白い記事の解説を書き、その文章のみを構造化して出力してください。"
"但し、解説中ではオタクではなく専門家と名乗ってください。また、社内で読まれるため、文章には絵文字でポイントを強調しながら、丁寧語を使用するようにしてください。"
"見出しには#を使用してください。"
"また、説明文中に不正確な、または想像上のリンク(架空のURL)が含まれないように注意してください。"
"実際に存在する信頼できるURLのみを使用するか、リンクが不要な場合はリンクを省略してください。"
)
なお、このプロンプトを作成するにあたっては、以下のポストで紹介されていたTIPSを参考にしています。
様々に試行錯誤した結果、このプロンプトを使用して物事の理解の解像度を高めつつ、さらにドラマ「地面師たち」で話題のオープニングから着想を得た 「緻密かつ高度な」 の表現を組み合わせることによって、非常に詳細な解説を生成できることが分かりました。
今回の処理には、この試行で得られた経験を取り入れています。
(4) Webhookにデータを送信する
要約されたデータをWebhookに送信します。
def lambda_handler(event, context):
"""
ペイロードをWebhook URLに送信するLambda関数。
期待される入力イベントの構造:
{
"title": "...",
"url": "...",
"published": "...",
"summary": "...",
"webhook_url": "https://..."
}
この情報からwebhook_url フィールドを除いたペイロードを作成し、指定されたURLにPOSTリクエストを送信する。
"""
# webhook_urlの存在チェック
webhook_url = event.get("webhook_url")
if not webhook_url:
return {
"statusCode": 400,
"body": "Missing webhook_url in input."
}
# webhookに送信するデータを整形
payload = {
"title": event.get("title", ""),
"url": event.get("url", ""),
"published": event.get("published", ""),
"summary": event.get("summary", ""),
}
# JSONエンコード
data = json.dumps(payload).encode("utf-8")
# HTTPヘッダーの設定
headers = {
"Content-Type": "application/json"
}
# POSTリクエストの作成と送信
req = urllib.request.Request(url=webhook_url, data=data, headers=headers, method="POST")
try:
with urllib.request.urlopen(req) as response:
status_code = response.getcode()
response_body = response.read().decode("utf-8")
except urllib.error.HTTPError as e:
# HTTPエラーの場合
return {
"statusCode": e.code,
"body": e.read().decode("utf-8")
}
except Exception as e:
# その他の例外の場合
return {
"statusCode": 500,
"body": str(e)
}
return {
"statusCode": status_code,
"body": response_body
}
4. Microsoft Teamsで受信したデータを解析する
Teamsでは受信したデータを直接ポストしようとするとエラーになりますが、下図の通り「JSONの解析」コネクタを挟むことにより、事実上JSONであればフリーフォーマットでデータを受け取ることが可能になっています。
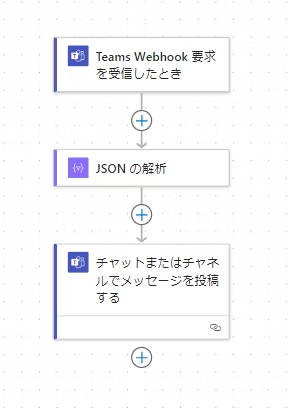
これは2024年に発表されたTeamsのWebhookに関する仕様変更の際、代替手段として誕生した「Teams Webhook 要求を受信したとき」というトリガーコネクタが、カード形式のデータの受信を必須としていないことによるものですが、このトリガーは非常に柔軟性が高く、役に立ちます。
Webhookで受信したデータをTeamsのコネクタでパースすると、以下のように表示できます。
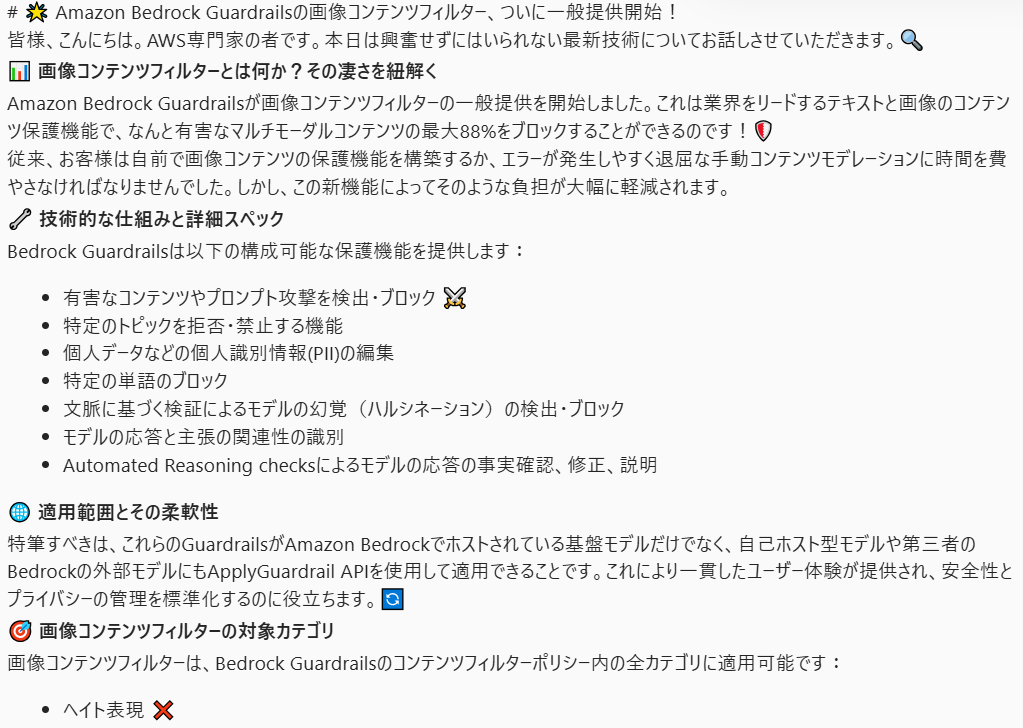
なお、この解説は以下の記事に基づいています。
今回はTeamsで受信していますが、もちろんSlackなどにも応用が可能です。
終わりに
本記事では、Amazon Bedrockの生成AIモデルとAWSのサーバレスアーキテクチャを組み合わせることで、ニュース記事を効率的かつ詳細に要約・解説し、自動的に配信する仕組みを紹介しました。
これまで直面していたタイムアウトやスケーラビリティの問題は、システム全体をAWSに移行し、Lambda、Step Functions、DynamoDBを活用することで大幅に改善されました。
また、Claude 3.7 Sonnetのような高度で人気の高いモデルを安心して利用できるようになったことも大きな成果と言えます。
本記事の内容が少しでもお役に立ち、今後のAmazon Bedrockを活用した生成AIによる業務効率化の参考になれば幸いです。