Amazon Kinesis
公式サイト
概要
- Amazon Kinesis は、大規模なストリーミングデータをリアルタイムで処理する完全マネージド型サービスです
利用可能なリージョンと利用料金(2014/06/08 現在)
- リージョン
** 米国東部(バージニア北部)のみ - 利用料金
** 時間単位のシャード速度(取得速度は 1 MB/秒、送信速度は 2 MB/秒): 0.015 USD
** PUT 取引 1,000,000 個あたり: 0.028 USD
簡単な使い方
- レコードを登録する (PutRecord http://docs.aws.amazon.com/kinesis/latest/APIReference/API_PutRecord.html)
- レコードを取得する (GetRecord http://docs.aws.amazon.com/kinesis/latest/APIReference/API_GetRecords.html)
コードサンプル (Ruby)
- レコードを登録する
put.rb
require 'aws-sdk'
print "Enter target stream name: "
stream_name = gets.chomp
begin
client = AWS::Kinesis.new(
access_key_id: ENV['AWS_ACCESS_KEY_ID'],
secret_access_key: ENV['AWS_SECRET_ACCESS_KEY']).client
categories = %w{Foods Books Toys Electronics Sports Clothing Shoes Music Movies Games}
loop do
now = Time.now.to_s
partition_key = categories.sample
response = client.put_record(
stream_name: stream_name,
data: now,
partition_key: partition_key)
puts "Data : #{now}, Partition Key : #{partition_key}, Shard Id : #{response.shard_id}, Sequence Number : #{response.sequence_number}"
sleep(1)
end
rescue => e
puts "Error: #{e.message}"
abort
end
- レコードを取得する
get.rb
require 'aws-sdk'
require 'parallel'
print "Enter target stream name: "
stream_name = gets.chomp
if stream_name.empty?
puts "target stream name is required"
abort
end
begin
client = AWS::Kinesis.new(
access_key_id: ENV['AWS_ACCESS_KEY_ID'],
secret_access_key: ENV['AWS_SECRET_ACCESS_KEY']).client
shards = client.describe_stream(stream_name: stream_name).stream_description.shards
shard_ids = shards.map(&:shard_id)
Parallel.each(shard_ids, in_threads: shard_ids.count) do |shard_id|
shard_iterator_info = client.get_shard_iterator(
stream_name: stream_name,
shard_id: shard_id,
shard_iterator_type: 'TRIM_HORIZON')
shard_iterator = shard_iterator_info.shard_iterator
loop do
records_info = client.get_records(
shard_iterator: shard_iterator,
limit: 100)
records_info.records.each do |record|
puts "Data : #{record.data}, Partition Key : #{record.partition_key}, Shard Id : #{shard_id}, Sequence Number : #{record.sequence_number}"
end
shard_iterator = records_info.next_shard_iterator
sleep(1)
end
end
rescue => e
puts "Error: #{e.message}"
abort
end
その他
- fluentd と用途が近いけれど、Amazon Kinesis では ThroughPut を向上させたい場合は、Shared の数を増加させるだけでよい
- MultiStep Processing も可能
- Shared 上限デフォルト数が 10
参考資料
- API リファレンス http://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html
- Amazon Kinesis ことはじめ http://www.slideshare.net/iktakahiro/amazon-kinesis-32428443
- Ruby から Amazon Kinesis を操作する http://tech-sketch.jp/2014/04/aws-kinesis-ruby.html
- [aws]ストリームデータ処理サービスAmazon Kinesisについて調べた結果 http://d.hatena.ne.jp/kimutansk/20131225/1387925700
- Kinesis Wordcount サンプル https://github.com/kimutansk/storm-example-wordcount
- Amazon Kinesis: Real-time Streaming Big data Processing Applications (BDT311) | AWS re:Invent 2013 http://www.slideshare.net/AmazonWebServices/amazon-kinesis-realtime-streaming-big-data-processing-applications-bdt311-aws-reinvent-2013
Apache Kafka
- 公式サイト http://kafka.apache.org/
概要
- publish-subscribe 型のメッセージングシステム
- 用途としては、オフライン・オンライン両方のメッセージ取得に適している
- 当初は LinkedIn で開発された メッセージングシステムでだったが、Apache プロジェクトのトップレベルプロジェクトになっている
- 最近は Tumblr、DataSift といった企業でも使用されているとのこと
システム概念イメージ
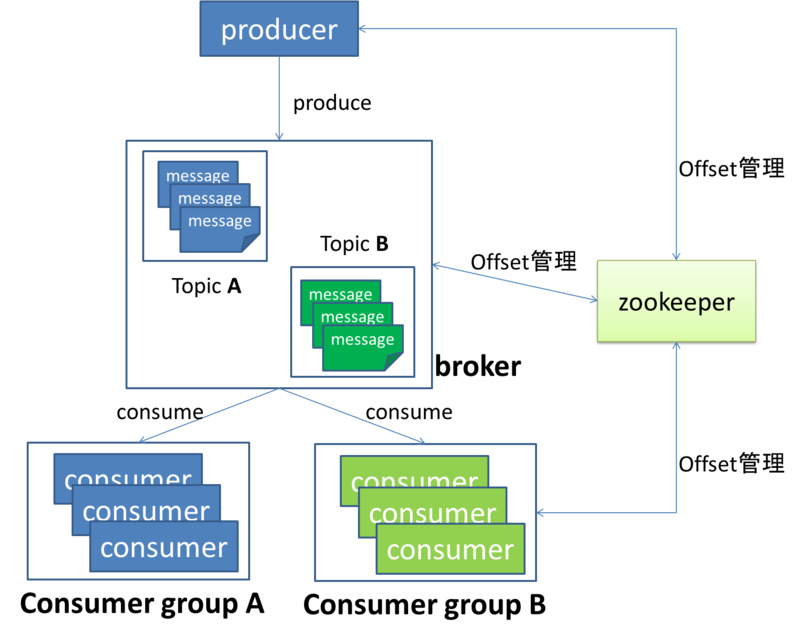
※ http://fuji-151a.hatenablog.com/entry/2014/02/23/231639 より
クライアント
- Java, Ruby など多数あり https://cwiki.apache.org/confluence/display/KAFKA/Clients
インストール方法
- quick start ガイド http://kafka.apache.org/documentation.html#quickstart
コンポーネント
- message 流すデータ
- topic messageのカテゴリのこと、topicは自分で名前を決めれる
- broker Kafkaにおいてmessageを貯めるところ
- producer brokerにmessageを送信するcomponent
- consumer brokerからmessageを読むcomponent
- consumer group 言葉通り,consumerをグルーピングしたもの.
- offset consumerと密接に関わってくる単語
その情報を管理しているのはZookeeperというまた別のOSSである.
参考資料
- Apache Kafka, 他とは異なるメッセージングシステム http://www.infoq.com/jp/news/2014/01/apache-afka-messaging-system
- Apache Kafka 入門 (kindle) http://www.amazon.co.jp/exec/obidos/ASIN/B00JU43ONW/
- Kafkaによるリアルタイム処理 http://www.slideshare.net/yanaoki/kafka-10346557
- Apache Kafkaってそもそも何か確認してみます http://d.hatena.ne.jp/kimutansk/20120411/1334070679
- Apache Kafka で何をするか他 http://open-groove.net/tag/kafka/
- Apache Kafka について http://fuji-151a.hatenablog.com/entry/2014/02/23/231639
- Apache Kafka RPM Spec ファイル https://github.com/kimutansk/kafka-installer
Storm
概要
- Apache Storm is a free and open source distributed realtime computation system.
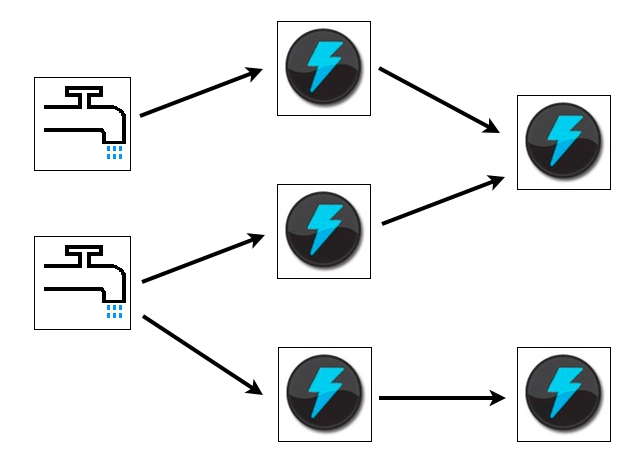
- リアルタイムでの分散処理の実行のみに特化
- 基本的なユースケースとしては、ストリーム処理、継続的な計算、分散 RPC
コンポーネント
- Tuple Storm で処理されるメッセージを保持するデータ
- Stream 途切れずに連続する Tuple
- Spout Storm のストリーム処理の起点となる
- Bolt Stream の変換処理を行う
- Topology Spult, Bolt からなるネットワーク構造のこと
参考資料
- Twitterのリアルタイム分散処理システム「Storm」入門 http://www.slideshare.net/AdvancedTechNight/twitterstorm
- 記者の眼 - 激速インフラ作るネット企業の秘密基地に潜入:ITpro http://itpro.nikkeibp.co.jp/article/Watcher/20140403/548350/
** マイクロアドで Storm が導入されているとのこと
その他
Apache Samza
- Apache Samza is a distributed stream processing framework. It uses Apache Kafka for messaging, and Apache Hadoop YARN to provide fault tolerance, processor isolation, security, and resource management.
- http://samza.incubator.apache.org/
その他のメモ
- ログ収集について(kibana、elasticsearch、logstash、Fluentd、Apache Flume、Splunk) - ぺーぺーSEの日記 http://d.hatena.ne.jp/tanakakns/20140306/1394099168