1. はじめに
「この備品の在庫ってどこにありますか?」
「博多から大阪への出張って、飛行機で行ってもいいですか?」
社内問い合わせには、規程のように文書から意味を探す「文書検索」と、在庫のように「事実(数値)」で確定するデータが混在しています。
これらを一律にLLMへ任せてしまうと、正確な在庫数を推測で答えてしまうようなハルシネーションのリスクが排除できず、業務システムとして求められる正確性を担保できません。
そこで、規程などの柔軟な文書検索にはRAG(Dialogflow CX)を、正確性が必要な在庫検索にはBigQueryへのSQL直接検索を採用。両者を適材適所で使い分ける「ハイブリッド型」の社内ナレッジAIボットを実装しました。
イメージ

※ダミーデータ使用
2. アーキテクチャ
システム構成はシンプルです。ユーザーの入力をStreamlitで受け取り、ルーティング処理で在庫か規程かを判定して、適切なバックエンドへ振り分けています。
システム構成図
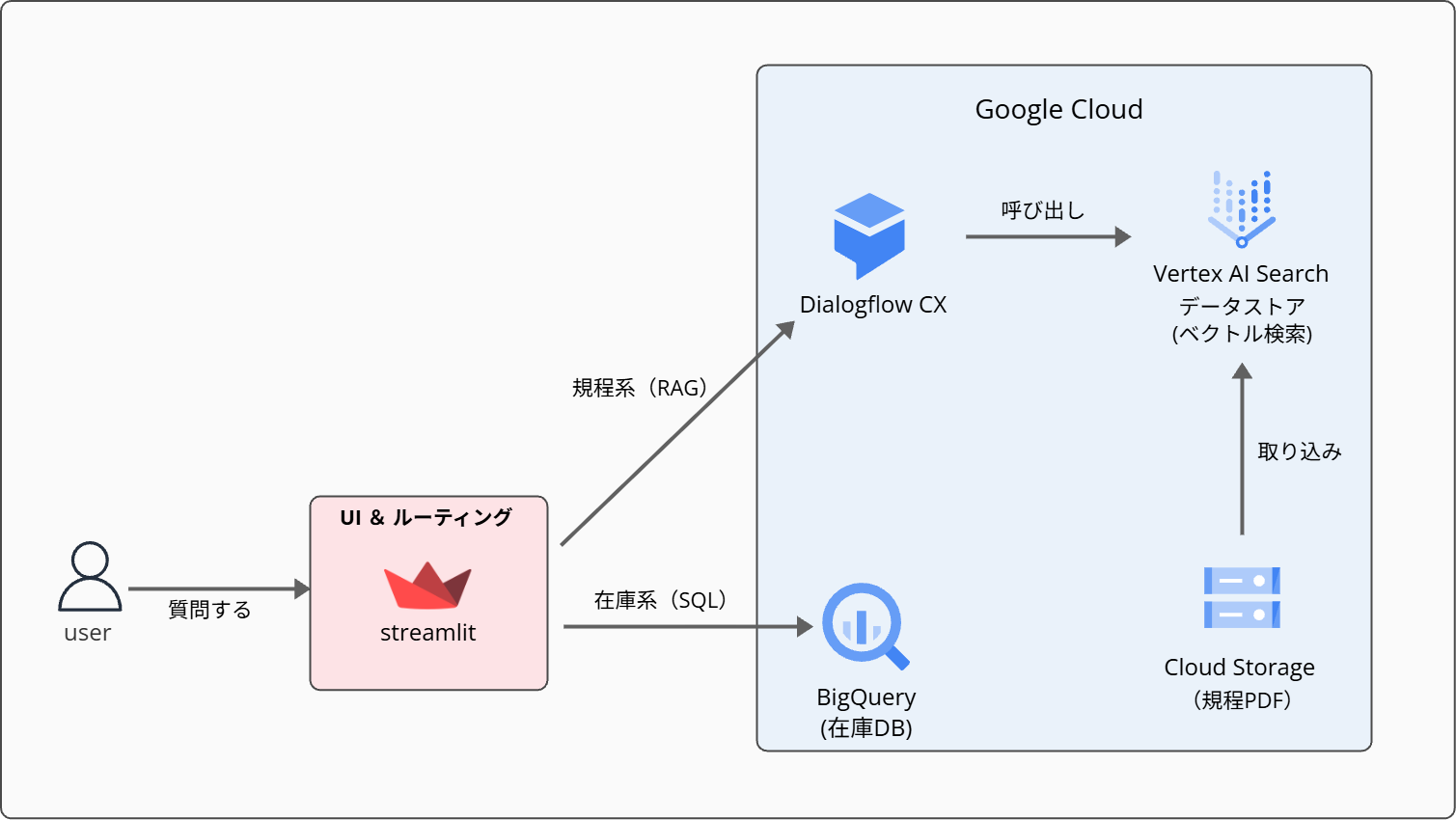
■ Streamlit(UI / ルーティング)
ユーザーとのインターフェース。チャット形式で質問を受け付け、回答を表示します。入力テキストはキーワードベースで規程系か在庫系かを判定・ルーティングしています。
■ Dialogflow CX (Conversational Agents)
規程PDFの検索と回答生成を担うRAGパート。Dialogflowが対話を制御し、裏側では Vertex AI Search を利用して、根拠(参照元)付きの回答を生成します。
■ BigQuery
在庫データの「正」となるデータ基盤。LLMを介さず、SQLによる直接検索を行うことで、ハルシネーションのない正確な値を返します。
■ Cloud Storage(GCS)
規程PDFはVertex AI Search(Data Store)のデータソースとして配置し、あわせてユーザーが原本を確認できる参照用リンク(公開ファイル)も提供します。
Vertex AI Searchによる高い検索性能と拡張性
今回のRAG実装で、検索精度と開発スピードの両立を支えたのが Vertex AI Search です。
ベクトルデータベースの複雑な設計や個別チューニングを意識することなく、PDF等の非構造化データを投入するだけで即座に実用レベルの検索基盤が立ち上がります。
また、特筆すべきは対応データソースの広さです。今回はPDFを採用しましたが、将来的にはSharePointやConfluenceといった社内Wiki、さらにはBigQuery上の構造化データまで、同一のインターフェースで統合できる高い拡張性を備えています。
Dialogflow CXとの親和性も高く、Data Storeを指定するだけで根拠(引用)付きの回答を一気通貫で生成可能です。フルマネージドなインフラにより、パフォーマンスを気にせずアプリケーション側の体験設計に注力できる点が最大の魅力でした。
3. ハルシネーション対策
業務システムで最も避けるべきは、AIが「もっともらしい誤回答」を返すことです。本アプリでは、以下の3点でそのリスクを低減しています。
ルーティング : あえてLLMを使わない
質問が「在庫」か「規程」かの判定をLLMに任せると、プロンプト次第で挙動が揺らぎ、レスポンスも遅くなります。今回は「在庫」「備品」など明確なキーワードが存在するため、Pythonによるルールベース判定を採用しました。シンプルなロジックで安定した振り分けを実現しています。
在庫検索 : 事実は「生成」せず「検索」する
「在庫数はいくつ?」にLLMで数値を語らせるのはリスクがあります。本アプリでは、ユーザー入力から検索語を抽出し、BigQueryへパラメータ化SQLを発行。取得結果をそのまま表形式で表示することで、正確な値を返しています。
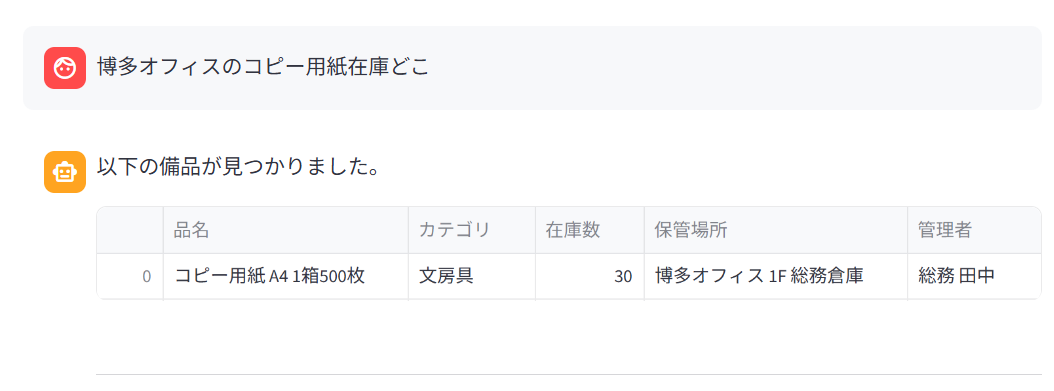
規程検索 : 根拠なき回答は遮断(引用ゲート)
対話制御にDialogflow CXを採用。Dialogflow CXは回答生成時に参照元(Citations)を返してくれます。アプリ側に「回答があっても根拠がなければ表示しない」という引用ゲートを実装し、AIの推測や勝手な回答をユーザーに見せない設計にしました。
4. 対話のハードルを下げるUI設計
業務向けチャットボットは「正しく答える」だけでは定着しません。「何を聞けばいいか分からない」「入力が面倒」といった心理的ハードルを下げる導線設計が不可欠です。
本アプリでは、ユーザーが迷わず対話を始められ、自然に深掘りできる仕組みを実装しました。
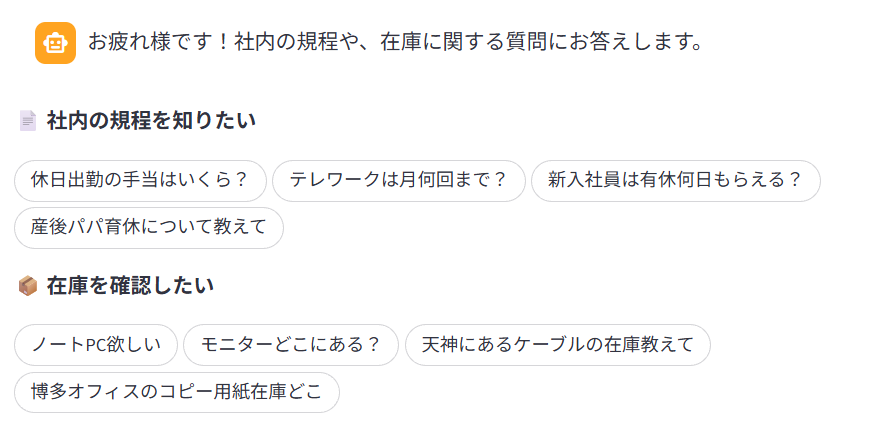
カンバセーションスターター
トップ画面に質問例をボタン形式で配置し、ワンクリックで質問を開始できるようにしました。初めてのユーザーでも迷わず使い始められます。
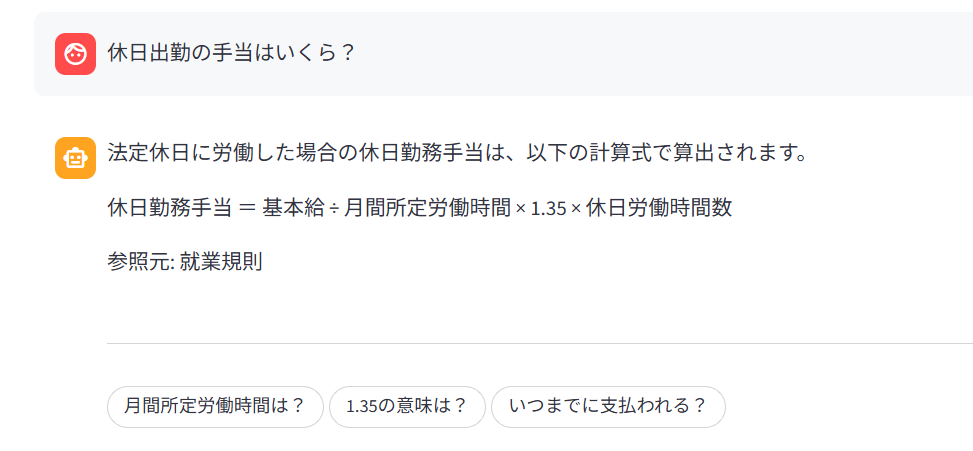
フォローアップ質問(サジェスト)
規程の回答後、関連する質問候補をGemini APIで自動生成して表示。回答を見て終わりではなく、自然と次の質問へ繋がる導線を意識しました。
5. 開発プロセス(SDD × TDD)
RAGは出力が揺れやすく、UIの状態遷移も複雑なため、仕様の曖昧さがそのまま品質低下に直結します。本プロジェクトでは、仕様駆動開発(SDD)とテスト駆動開発(TDD)を軸に進めました。
■ 仕様書を「唯一の真実」に
実装前に詳細な仕様書(spec.md)を作成し、画面仕様・状態管理・固定文言・エラー時の挙動などを細かく定義。
ChatGPT・Gemini・Claudeを並行して開き、設計のレビューを依頼。3者の提案を突合し、矛盾点を潰したうえで最終判断を仕様に反映しました。
IDEに対しても、この仕様書を「信頼できる唯一の情報源(SSOT)」として参照させたことで、迷いのない開発を実現しました。
■ TDDで品質を担保
機能実装の際は、まず失敗するテストを書き(Red)、最小限の実装で成功させ(Green)、その後コードを整理・最適化する(Refactor)というサイクルを徹底。
また、外部API(BigQuery/Dialogflow CX)の応答をモック化し、136件のテストでルーティング判定や例外系をカバーしました。
大胆にリファクタを実施しても、変更直後にテストで回帰を確認できるため、安心して開発を進めることができました。
6. おわりに
本記事では、RAGとSQL直接検索を組み合わせた社内ナレッジAIボットの設計を紹介しました。
LLMは強力ですが、万能ではありません。データの性質を見極め、適材適所で使い分けることが、業務システムとしての信頼性につながると感じています。
本記事が、社内の情報共有やAI活用に課題を抱える方の参考になれば幸いです。