はじめに
あのRIAAにDMCAされたyoutube-dlです。
これのextractor(動画情報を抽出する部分)の書き方を適当に書きます。適当なので分からないところがあったらごめんなさい。
最終目標
youtube-dlの大まかなアーキテクチャ
youtube-dlは大きく分けて3段構成で、次のような感じになっています。
今回扱うextractorは動画情報を抽出するだけ。downloaderは動画を実際にダウンロードするだけ。postprocessorはダウンロードした動画に後処理を行います。1
downloaderやpostprocessorは動画配信プロトコルの大御所はほぼ全て実装しているので、あまり手を付ける必要はありません。
+-----------+ +------------+ +---------------+
| extractor | --> | downloader | --> | postprocessor |
+-----------+ +------------+ +---------------+
ステップ0: どこにするか決める
とりあえず無難そうなwhowatch2にします。配信は適当にトップページから選択。
ステップ1: Webサイトの観察
適当な配信を持ってきました。クリックすれば再生できそうです。
とりあえず再生してみましょう。
再生できたので大丈夫でしょう。3
ステップ2: 開発者ツールを開く
開発者ツールを開き、どこに動画データがあるか見てみましょう。
FirefoxならCtrl+Shift+Iで開きます。4
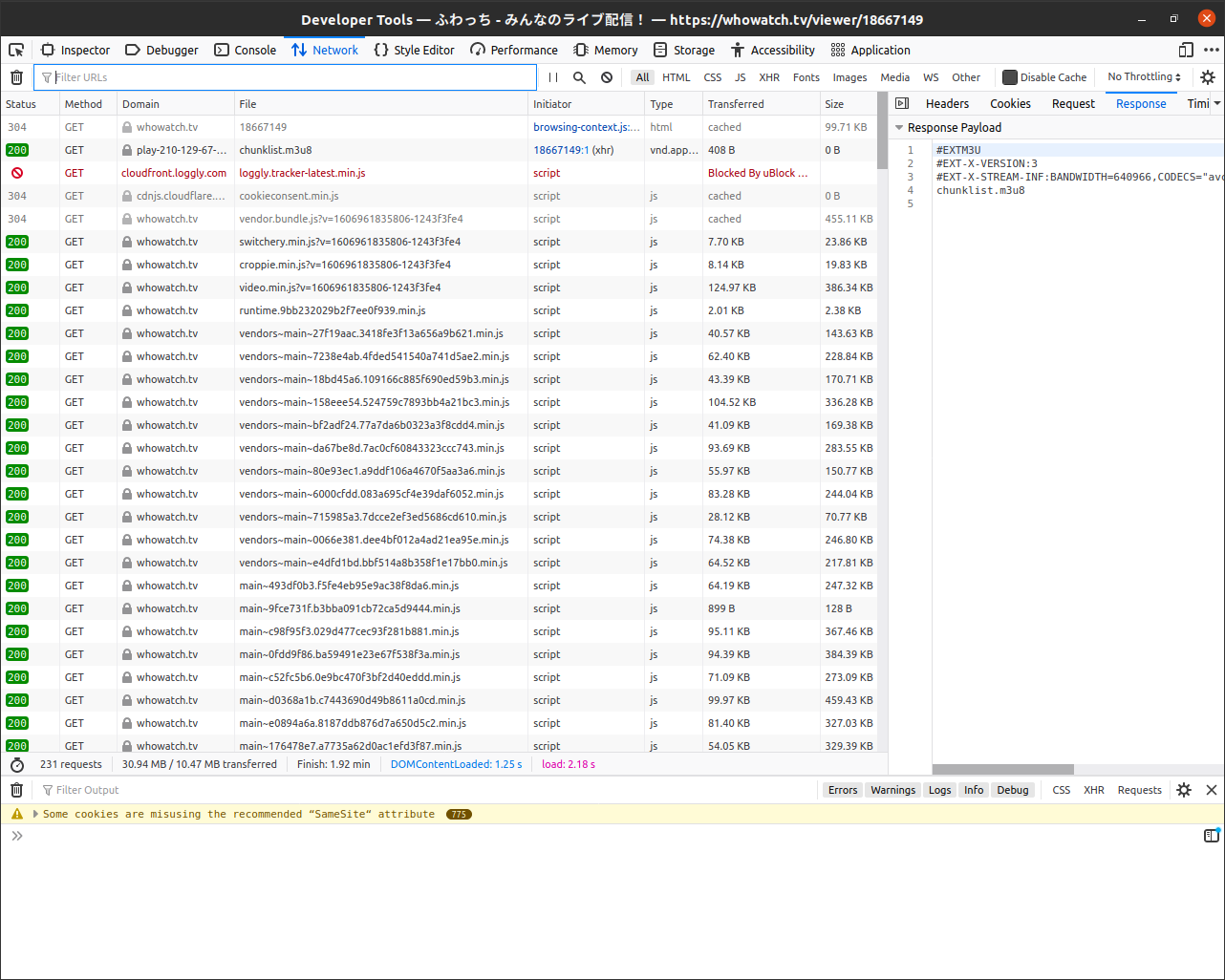
開いたウィンドウのネットワーク(Network)タブを開くと、こうなります。
ところで、HTML5での生配信はどのような形式で行われるのでしょう? 実は大体はHLSで行われています。
HLSのプレイリスト5は.m3u8という拡張子なので、これで検索してみます。
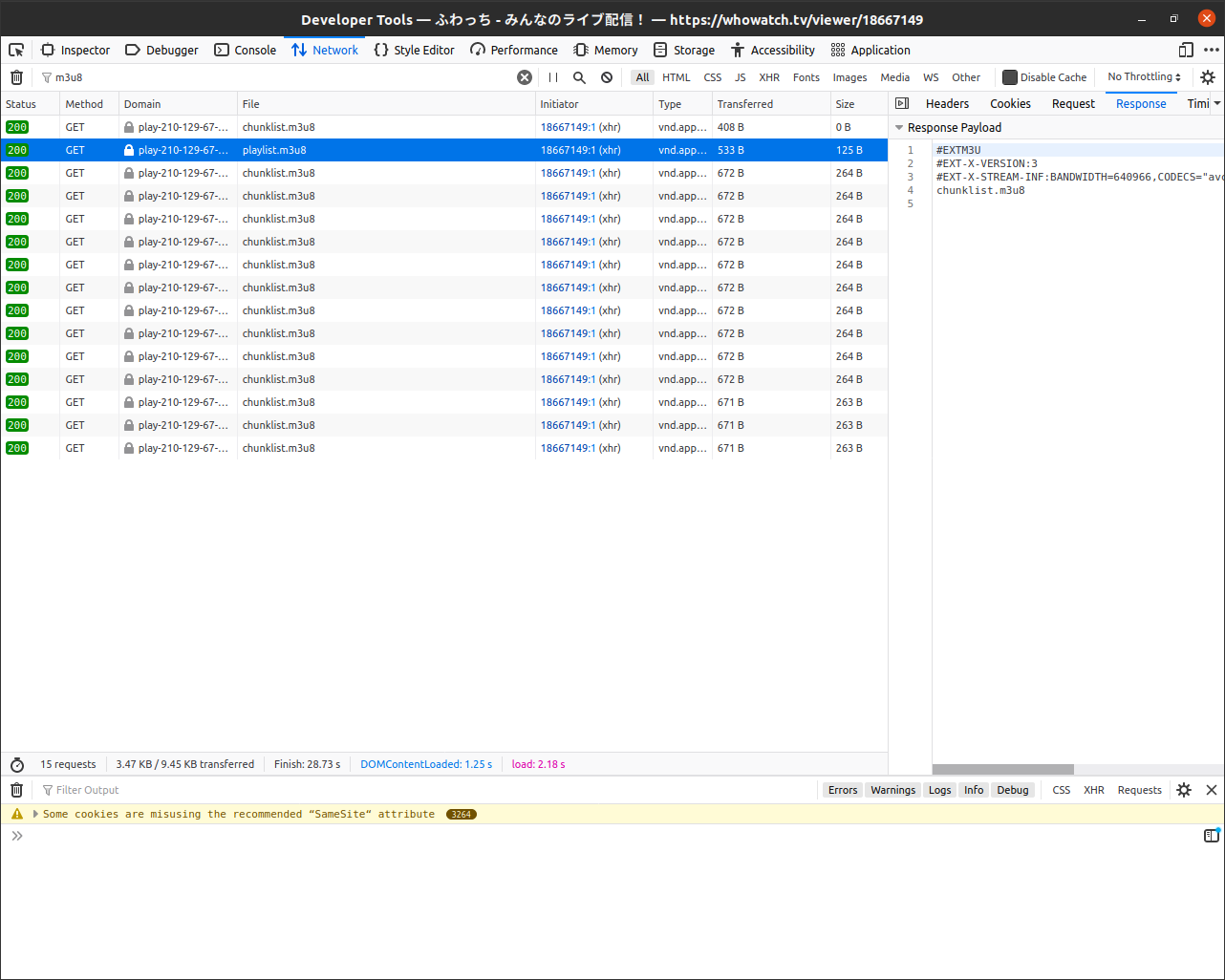
なんか意味深なファイル名がありました。このplaylist.m3u8をyoutube-dlに投げ込んでみましょう。6
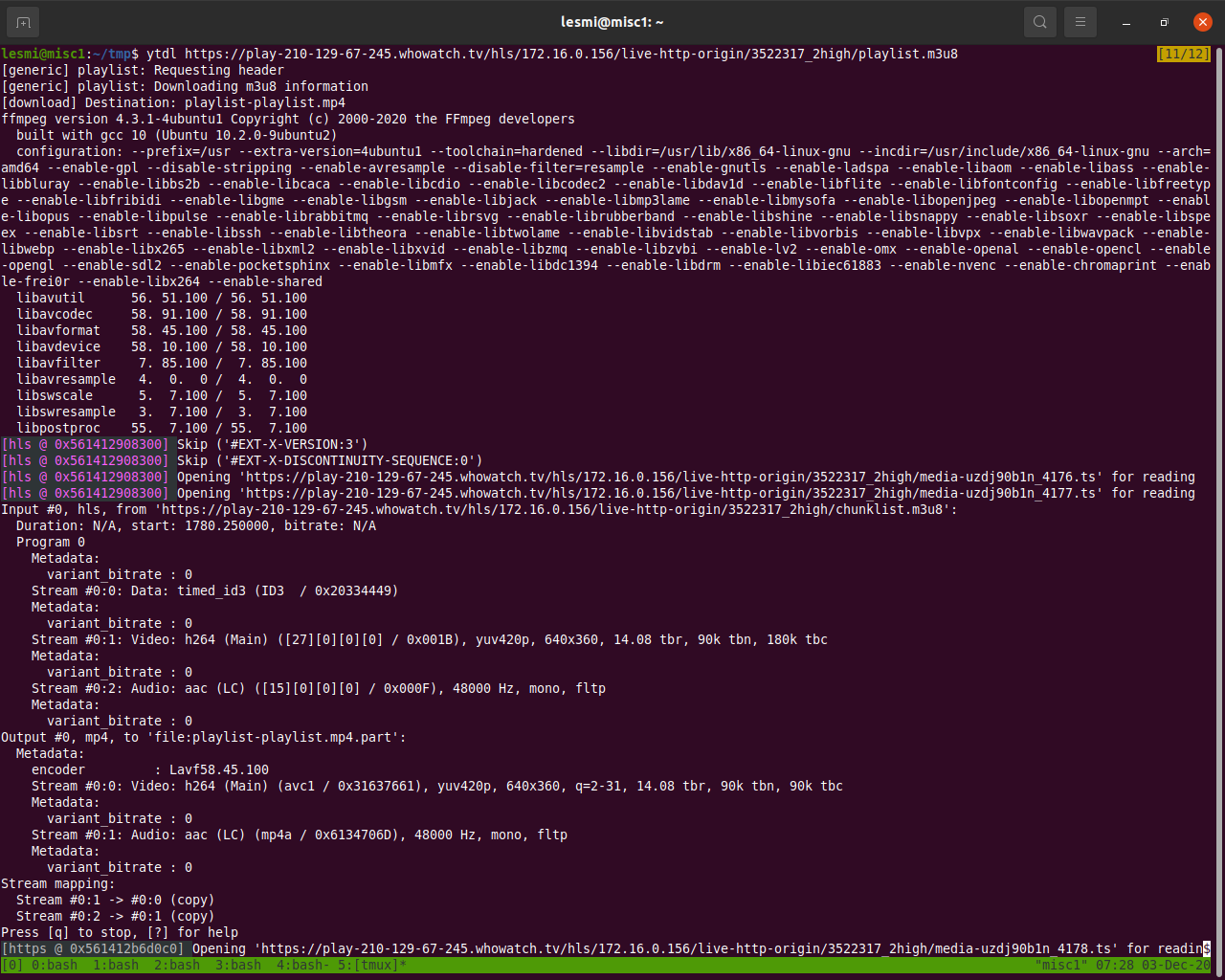
ffmpegが起動してダウンロードが始まりました。
ということは、このURLを生配信視聴ページから取り出す/導くことができれば勝ち、ということになります。
ステップ3: 導出方法を検討する
でも、これを毎度毎度人手で取り出すのは本末転倒です。自動化しなければなりません。
Firefoxでは便利なことに7、ダウンロードされたリソースの中からテキストを検索する機能があります。
先程の検索欄の右側の虫眼鏡をクリックするとこうなります。
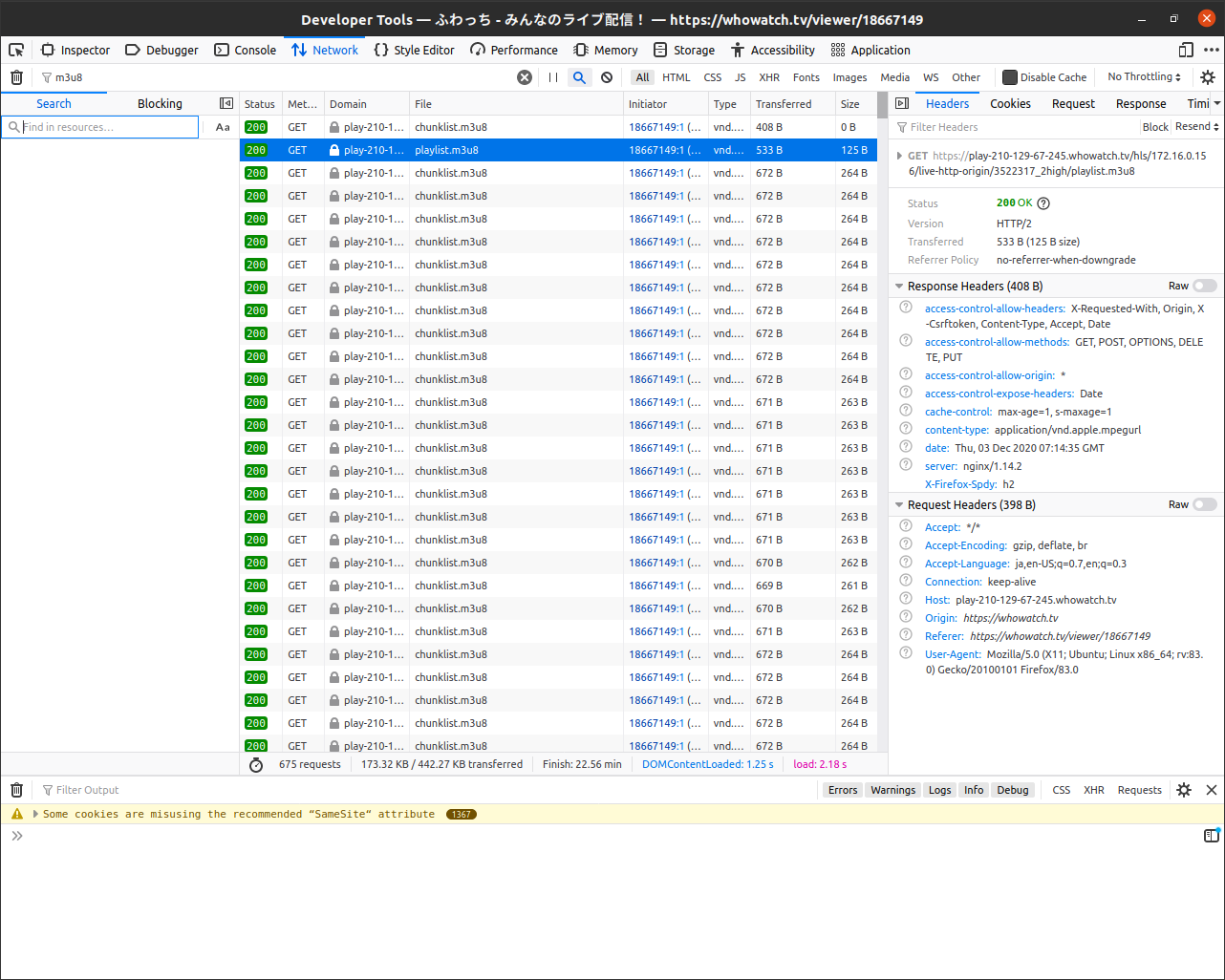
左側に出現した検索欄に何かを入力すると、ダウンロードされたリソースから検索出来てしまうのです。便利。
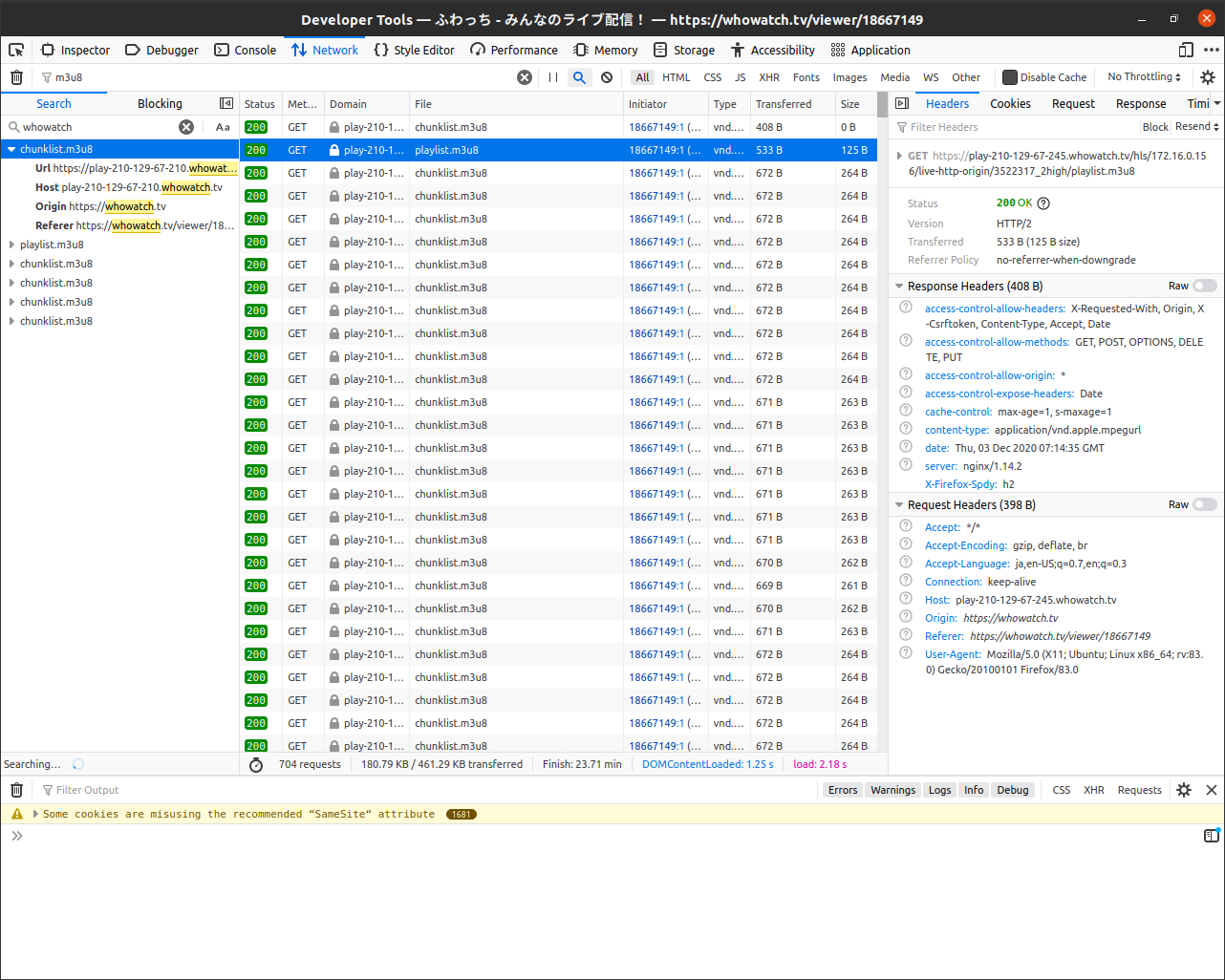
では、先程のm3u8のファイル名を入れてみましょう。

それっぽいのが出てきました。
上から、
- Web AppのJavascriptファイル
- APIリクエスト
- playlist.m3u8
の順番で並んでいることが分かります。
APIリクエストが一番怪しいので、中身を見てみましょう。
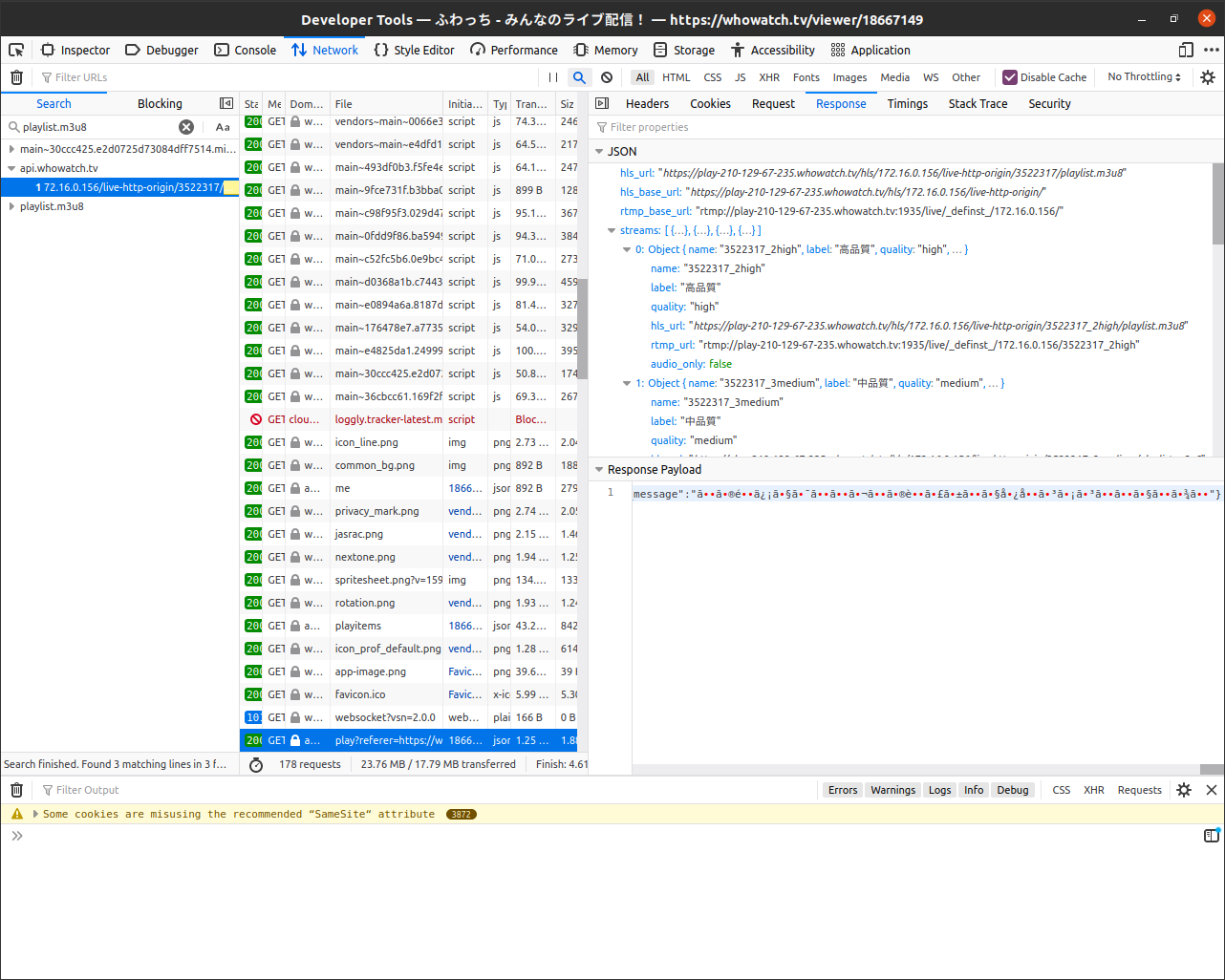
当たりを引きました。これを取り出しましょう。
URLはhttps://api.whowatch.tv/lives/18667149/play?referer=https%3A%2F%2Fwhowatch.tv%2Fでした。
ステップ4: youtube-dlに実装する
forkやらcloneやらは全て飛ばします。本題ではないので。
まず、適当にファイル名を決めて、youtube-dl/extractor/[ファイル名].pyに次の内容をとりあえずコピペします。
# coding: utf-8
from __future__ import unicode_literals
# 最低限のimport
from .common import InfoExtractor
# ClassNameは置き換えること
class ClassNameIE(InfoExtractor):
# このextractorが受け付けるURLの正規表現
_VALID_URL = r''
# 実際の抽出コードを_real_extractに書く
def _real_extract(self, url):
# 正規表現のIDパートを取り出す。
video_id = self._match_id(url)
return {}
ファイル名はwhowatch.pyにして、ClassNameIEはWhoWatchIEと置き換えることとします。
まず、正規表現を考える必要があります。しかし、このタイプのURLは非常に単純なので簡単にできますが、次のような条件を満たす必要があります。
- 必ず
idという名前のついたグループを作る- URLにあるIDをキャプチャさせます
- 不必要なグループは入れない
- 複数文字の任意部分を指定したい時は、
(?:test/)?のようにグループにならないようにします
- 複数文字の任意部分を指定したい時は、
とりあえずこんな感じで良さそうです。
# coding: utf-8
from __future__ import unicode_literals
from .common import InfoExtractor
class WhoWatchIE(InfoExtractor):
_VALID_URL = r'https?://whowatch\.tv/viewer/(?P<id>\d+)/?'
def _real_extract(self, url):
video_id = self._match_id(url)
return {}
正規表現も細かくはやりません。本題ではないので。
正しくidという名前のついたグループを作れば、self._match_id(url)はグループidを持ってきてくれます。
ステップ 4.1: 試してみる
このコードで検証してみましょう。
youtube_dl/extractor/extractors.pyに先程のWhoWatchIEを参照できるようにimportを追加して、
from .whowatch import WhoWatchIE
youtube-dlに与えてみます。
$ python3 -m youtube_dl https://whowatch.tv/viewer/18667149
ERROR: Missing "id" field in extractor result; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
エラーが出てきましたが、genericとはなっていないので成功です。
ステップ 4.2: IDとタイトルを返す
InfoExtractor(extractor)の_real_extractはdictで情報を返します。IDは先程self._match_idで取り出しましたが、タイトルはそうは行きません。
ステップ3のAPIリクエスト中にm3u8のURLの他にタイトルが入っていたのを覚えていますか? あったんです。
なので、このJSONをダウンロードして取得しましょう。
APIリクエストのURLはhttps://api.whowatch.tv/lives/18667149/play?referer=https%3A%2F%2Fwhowatch.tv%2Fで、視聴URLのIDパートは18667149でした。共通部分に気づきましたか?
そうですね。'https://api.whowatch.tv/lives/' + video_id + '/play?referer=https%3A%2F%2Fwhowatch.tv%2F'で全く同じURLが再現できます。
また、youtube-dlにはJSONダウンロードとデシリアライズを一度にやってくれる便利メソッド_download_jsonがあるので、これでダウンロードします。
api_url = 'https://api.whowatch.tv/lives/' + video_id + '/play?referer=https%3A%2F%2Fwhowatch.tv%2F'
# URL、IDの順で指定する
live_data = self._download_json(api_url, video_id)
return {
'id': video_id,
# 鉤括弧があったので同時に外してしまう
'title': live_data['share_info']['live_title'][1:-1]
}
ステップ 4.3: m3u8から情報を取り出す
次に、m3u8から情報を取り出してダウンロードに必要な最低限の情報を揃えます。ここでも_extract_m3u8_formatsというそのままの名前の便利メソッドが活躍します。
# HLSのURL
hls_url = live_data['hls_url']
# とりあえずHLSのフォーマットを検索する
formats = self._extract_m3u8_formats(
hls_url, video_id, ext='mp4', entry_protocol='m3u8_native',
m3u8_id='hls')
# 並び替える。これによって何も設定しない状態で最高画質をダウンロードするようにする
self._sort_formats(formats)
return {
'id': video_id,
'title': live_data['share_info']['live_title'][1:-1],
# フォーマット一覧
'formats': formats
}
ステップ 4.4: 生放送であることを宣言する
return {
'id': video_id,
'title': live_data['share_info']['live_title'][1:-1],
'formats': formats,
# これは生放送です
'is_live': True,
}
これで最低限まともに動きます。試してみましょう。
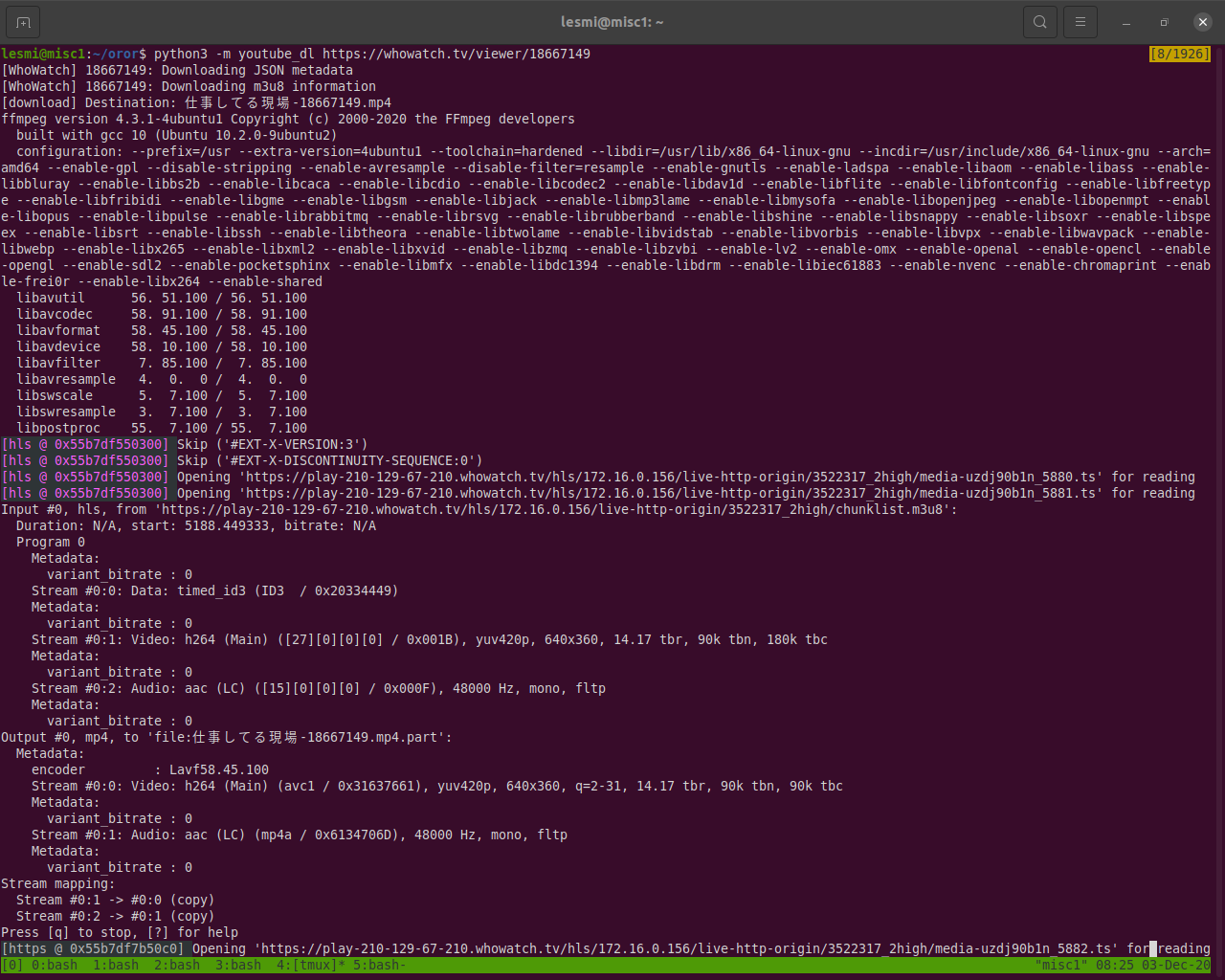
ステップ 5: Let's Try
できました。ダウンロード出来ています。
おわりに
今回は、youtube-dlのextractor書き方の超基本的な所を書きました。
次に、エラーハンドリングやユーザーに対してエラーや警告をどうやって表示するのかをやっていきたいと思います。
適当かつ大急ぎで書いたので結構荒削りになってしまったことをお許し下さい。
ここまでご覧いただきありがとうございました。
次: 第2巻
付録: 今回のコード
# coding: utf-8
from __future__ import unicode_literals
from .common import InfoExtractor
class WhoWatchIE(InfoExtractor):
_VALID_URL = r'https?://whowatch\.tv/viewer/(?P<id>\d+)/?'
def _real_extract(self, url):
video_id = self._match_id(url)
api_url = 'https://api.whowatch.tv/lives/' + video_id + '/play?referer=https%3A%2F%2Fwhowatch.tv%2F'
# URL、IDの順で指定する
live_data = self._download_json(api_url, video_id)
# HLSのURL
hls_url = live_data['hls_url']
# とりあえずHLSのフォーマットを検索する
formats = self._extract_m3u8_formats(
hls_url, video_id, ext='mp4', entry_protocol='m3u8_native',
m3u8_id='hls')
# 並び替える。これによって何も設定しない状態で最高画質をダウンロードするようにする
self._sort_formats(formats)
return {
'id': video_id,
# 鉤括弧があったので同時に外してしまう
'title': live_data['share_info']['live_title'][1:-1],
# フォーマット一覧
'formats': formats,
# これは生放送です
'is_live': True,
}
今回のコードはここにも置いておきます。
-
よく目にするのは映像+音声の結合ですが、これに限りません。例えば、
--execオプションはpostprocessorで扱います。 ↩ -
正式な名前はふわっちです。なお以降内部名で書きます。 ↩
-
分からなければ右クリックメニューに
要素を検査があるので、それでも構いません。 ↩ -
ここでは、細切れにした動画のファイル名が示されたファイルのことです。YouTubeなどのプレイリストは一旦忘れて下さい。 ↩
-
スクリーンショット内では
ytdlとaliasを張っています。同名のコマンドを提供するytdl-pafyとは無関係です。 ↩ -
Chromeにも同様の機能はあると思いますが、もう何年も触ってないので知りません。適当なので。 ↩