「続【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイル、いやHTMLにしてしまおう。」
https://qiita.com/Cartelet/items/a00d4cec8216d04f9274
を試してみました。
環境
- Ubuntu 18.04
- Python 3.6.9
- コード:
記事にはいくつかのバージョンが示されてますが、今回は8/11追記分の「文章分解強化版コード」を使用しました。
Word通さずともある程度段落を分解できるようにしました。
(だいたい)段落ごとに翻訳するため、1文ずつに比べ翻訳速度もだいぶマシになりました。
このコードを pdftrans.py として保存しました。
ライブラリ設定など
$ python3 pdftrans.py
として実行すると
Traceback (most recent call last):
File "pdftrans.py", line 1, in <module>
from selenium import webdriver
ModuleNotFoundError: No module named 'selenium'
と出たので
$ sudo pip3 install selenium
としてインストール。pyperclip も同様に必要だったので、
$ sudo pip3 install pyperclip
としてインストール。
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/common/service.py", line 76, in start
stdin=PIPE)
File "/usr/lib/python3.6/subprocess.py", line 729, in __init__
restore_signals, start_new_session)
File "/usr/lib/python3.6/subprocess.py", line 1364, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
FileNotFoundError: [Errno 2] No such file or directory: 'chromedriver.exe': 'chromedriver.exe'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "pdftrans.py", line 165, in <module>
TranslateFromClipboard(*args)
File "pdftrans.py", line 75, in TranslateFromClipboard
chrome_options=options)
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/chrome/webdriver.py", line 73, in __init__
self.service.start()
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/common/service.py", line 83, in start
os.path.basename(self.path), self.start_error_message)
selenium.common.exceptions.WebDriverException: Message: 'chromedriver.exe' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
となったので、
https://sites.google.com/a/chromium.org/chromedriver/homeから
chromedriver_linux64.zip
をダウンロードして展開。
$ ls -alh
合計 16M
drwxrwxr-x 2 nanbuwks nanbuwks 4.0K 8月 17 21:07 .
drwxrwxr-x 91 nanbuwks nanbuwks 56K 8月 17 21:06 ..
-rwxr-xr-x 1 nanbuwks nanbuwks 11M 5月 29 06:05 chromedriver
-rw-rw-r-- 1 nanbuwks nanbuwks 5.1M 8月 17 21:06 chromedriver_linux64.zip
-rw-r--r-- 1 nanbuwks nanbuwks 8.0K 8月 17 16:53 pdftrans.py
として、pdftrans.py と同じディレクトリに配置しました。
その上で pdftrans.py の9行目
DRIVER_PATH = 'chromedriver.exe'
となっているところを以下のように変更。
DRIVER_PATH = './chromedriver'
PATHの 設定を簡略化してとりあえず pdftrans.py はスクリプトのあるディレクトリで実行することにしました。
Traceback (most recent call last):
File "pdftrans.py", line 165, in <module>
TranslateFromClipboard(*args)
File "pdftrans.py", line 75, in TranslateFromClipboard
chrome_options=options)
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/chrome/webdriver.py", line 81, in __init__
desired_capabilities=desired_capabilities)
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/webdriver.py", line 157, in __init__
self.start_session(capabilities, browser_profile)
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/webdriver.py", line 252, in start_session
response = self.execute(Command.NEW_SESSION, parameters)
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/webdriver.py", line 321, in execute
self.error_handler.check_response(response)
File "/usr/local/lib/python3.6/dist-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 84
と出たので Chromeは Version 83 を使用していたのですが、最新版にアップデートしてバージョン: 84.0.4147.125(Official Build) (64 ビット)としました。
実行
$ python3 pdftrans.py
1. 英語 → 日本語 2. 日本語 → 英語 1
1. DeepL 2.GoogleTranslate 1
翻訳結果を書き出しますか? y/n y
1. txt 2. HTML 3. both 2
出力ファイルにつける名前を入力してください(デフォルトは'translated_text.html')
(論文の)タイトルを入力してください zigbeebdb
翻訳経過をここに表示しますか? y/n n
準備ができたらEnterを押してください
1/900 0% done
2/900 0% done
3/900 0% done
4/900 0% done
・
・
・
結果
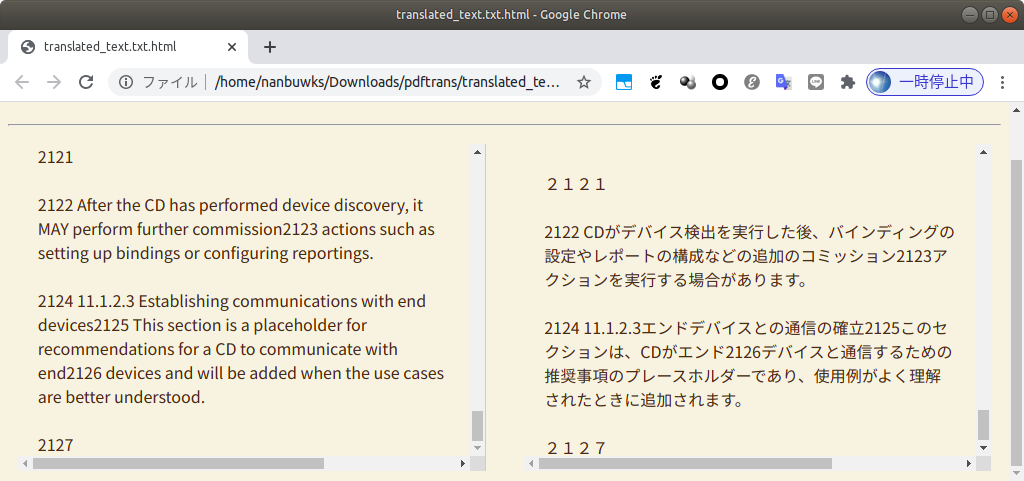
使ってみて
- 今回は87ページのPDFを試してみました。
- 上記例ではGoogle ChromeでPDFを開きクリップボードにコピーした所900センテンスで処理されました。後ほどevinceでPDFを開きクリップボードにコピーしたところ1249センテンスで処理されました。
- 1249センテンス処理で約30分。
- DeepLだと全体の1/20ぐらいでTimeUpぽくGoogleTranslateで実行しました。
- どうせGoogleTranslateにするなら8/16版の高速版で試した方が方が良かったかも。
8/16追記
マルチスレッドで大量にChromeを開く力技高速化を施しました。
こちらは書き出しはHTMLのみとなっています。
またDeepLの場合、多く開きすぎると制限がかかって翻訳止まりますのでご注意ください。
- 時間かかっても他の作業すればまあいいかと思っていましたが、クリップボードがコントロールされるので並行作業はコツがいる感じ。
- 参照した記事の更に元になった記事に使い方が書いてあったのですが、ちゃんと読まずに使おうとして、あれれーとなりました。
ちゃんと読んで事前にPDF文字情報をクリップボードにコピーしておけばちゃんと動きました!
「【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイルにしてしまおう。」
https://qiita.com/Cartelet/items/c56477033cda17a2a28a
追記 8/16版の高速版で試してみた
同時並行30にしたら、上記と同じ87ページ1249センテンスの文書が10分程度で翻訳できましたが、ロードアベレージがえらいことになりました。
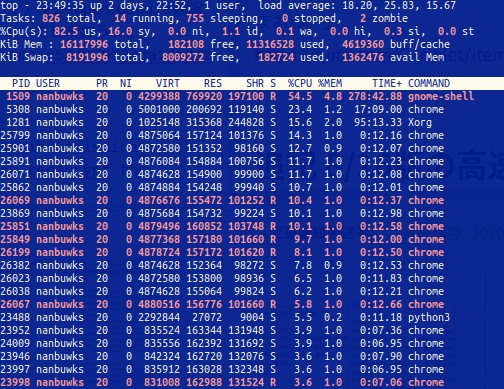
オーバーヘッドのロスがかからないように環境に応じて工夫するのが良さそうです。
実際に、同時並行10にしてみたら6分程度で処理できました。