どういった話かというと,GoogleNetやVGG16を使えば物体認識の性能は良いんだろうけど,携帯とかはメモリも計算速度もあんまりないので使いづらい.
こういう問題の解決方法の一つとして計算時間やメモリと性能のトレードオフを取れるようなネットワークMobileNet1をGoogleが作ったらしいので調べてみたという話です.
MobileNetとは
特徴
- ネットワークのサイズが小さい
- 学習時間が短い
- そこそこ性能が良い
- 入力データの画像サイズが32以上なら大丈夫
- 計算量と性能のトレードオフとなるハイパーパラメータ$\alpha$が用意されている.
- Keras2で実装済み
- Kerasでは画像サイズが224か192, 160, 128で$\alpha$が1.0か0.75, 0.5, 0.25の計16パターンのImageNetでの学習済みモデルを用意
仕組み
- 従来の畳込みフィルターの代わりにDepthwise畳み込みフィルターと1x1の畳み込みフィルターを組み合わせることで計算量を削減.
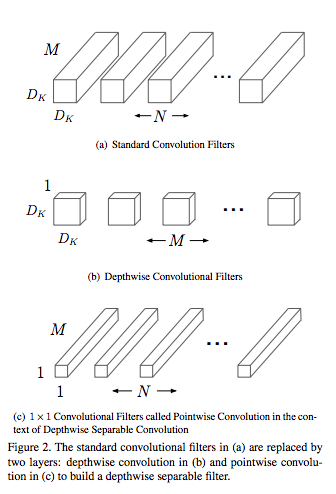
-
従来はカーネルサイズxカーネルサイズxチャネル数(入力)で畳み込みフィルターをチャネル数(出力)分用意するけど,畳み込みを行う.
-
MobileNetでは,カーネルサイズxカーネルサイズx1の畳み込みフィルターをチャネル数(入力)分用意して畳み込みを行う.
-
つぎに1x1xチャネル数(入力)の畳み込みフィルターをチャネル数(出力)分用意して畳み込む.
-
これで,従来の畳込みと似たような処理を実現.

MobileNets1より引用
ネットワーク構造
CIFAR10で$\alpha=0.5$とした場合の構造.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv1 (Conv2D) (None, 16, 16, 16) 432
_________________________________________________________________
conv1_bn (BatchNormalization (None, 16, 16, 16) 64
_________________________________________________________________
conv1_relu (Activation) (None, 16, 16, 16) 0
_________________________________________________________________
conv_dw_1 (DepthwiseConv2D) (None, 16, 16, 16) 144
_________________________________________________________________
conv_dw_1_bn (BatchNormaliza (None, 16, 16, 16) 64
_________________________________________________________________
conv_dw_1_relu (Activation) (None, 16, 16, 16) 0
_________________________________________________________________
conv_pw_1 (Conv2D) (None, 16, 16, 32) 512
_________________________________________________________________
conv_pw_1_bn (BatchNormaliza (None, 16, 16, 32) 128
_________________________________________________________________
conv_pw_1_relu (Activation) (None, 16, 16, 32) 0
_________________________________________________________________
conv_dw_2 (DepthwiseConv2D) (None, 8, 8, 32) 288
_________________________________________________________________
conv_dw_2_bn (BatchNormaliza (None, 8, 8, 32) 128
_________________________________________________________________
conv_dw_2_relu (Activation) (None, 8, 8, 32) 0
_________________________________________________________________
conv_pw_2 (Conv2D) (None, 8, 8, 64) 2048
_________________________________________________________________
conv_pw_2_bn (BatchNormaliza (None, 8, 8, 64) 256
_________________________________________________________________
conv_pw_2_relu (Activation) (None, 8, 8, 64) 0
_________________________________________________________________
...
_________________________________________________________________
conv_dw_13 (DepthwiseConv2D) (None, 1, 1, 512) 4608
_________________________________________________________________
conv_dw_13_bn (BatchNormaliz (None, 1, 1, 512) 2048
_________________________________________________________________
conv_dw_13_relu (Activation) (None, 1, 1, 512) 0
_________________________________________________________________
conv_pw_13 (Conv2D) (None, 1, 1, 512) 262144
_________________________________________________________________
conv_pw_13_bn (BatchNormaliz (None, 1, 1, 512) 2048
_________________________________________________________________
conv_pw_13_relu (Activation) (None, 1, 1, 512) 0
_________________________________________________________________
global_average_pooling2d_1 ( (None, 512) 0
_________________________________________________________________
reshape_1 (Reshape) (None, 1, 1, 512) 0
_________________________________________________________________
dropout (Dropout) (None, 1, 1, 512) 0
_________________________________________________________________
conv_preds (Conv2D) (None, 1, 1, 10) 5130
_________________________________________________________________
act_softmax (Activation) (None, 1, 1, 10) 0
_________________________________________________________________
reshape_2 (Reshape) (None, 10) 0
=================================================================
Total params: 834,666
Trainable params: 823,722
Non-trainable params: 10,944
_________________________________________________________________
検証環境
- Keras 2.0.6
サンプルコード
- $\alpha=1.0$でval_acc=87%
- $\alpha=0.5$でval_acc=81%
といったところでした.
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.applications import MobileNet
batch_size = 32
classes = 10
epochs = 200
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
Y_train = keras.utils.to_categorical(y_train, classes)
Y_test = keras.utils.to_categorical(y_test, classes)
img_input = keras.layers.Input(shape=(32, 32, 3))
model = MobileNet(input_tensor=img_input, alpha=0.5, weights=None, classes=classes)
model.compile(loss='categorical_crossentropy', optimizer="nadam", metrics=['accuracy'])
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=0, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size),
steps_per_epoch=X_train.shape[0] // batch_size,
epochs=epochs,
validation_data=(X_test, Y_test))
注意事項
- 現状だとBackendをTensorFlowにする必要あり.
- 引数にinput_shapeもあるがコードを見る限り,224か192, 160, 128じゃないと動かないので,おとなしくinput_tensorを使ったほうが良さそう.
ImageNetでの実験結果
----------------------------------------------------------------------------
Width Multiplier (alpha) | ImageNet Acc | Multiply-Adds (M) | Params (M)
----------------------------------------------------------------------------
| 1.0 MobileNet-224 | 70.6 % | 529 | 4.2 |
| 0.75 MobileNet-224 | 68.4 % | 325 | 2.6 |
| 0.50 MobileNet-224 | 63.7 % | 149 | 1.3 |
| 0.25 MobileNet-224 | 50.6 % | 41 | 0.5 |
----------------------------------------------------------------------------
- $\alpha$を小さくすることで,格段にパラメータを落とすことが可能.
------------------------------------------------------------------------
Resolution | ImageNet Acc | Multiply-Adds (M) | Params (M)
------------------------------------------------------------------------
| 1.0 MobileNet-224 | 70.6 % | 529 | 4.2 |
| 1.0 MobileNet-192 | 69.1 % | 529 | 4.2 |
| 1.0 MobileNet-160 | 67.2 % | 529 | 4.2 |
| 1.0 MobileNet-128 | 64.4 % | 529 | 4.2 |
------------------------------------------------------------------------
- 画像サイズが変わってもパラメータ数は変わらない.
まとめ
- MobileNetは性能と計算量のトレードオフを取れるネットワーク.
References
-
Howard et al., MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, 2017. ↩ ↩2