更新
- 2022/09/12
- Google Colab はこちら!(若干修正が入ってます)
- https://gist.github.com/naruya/c801197e4902bbb4a81a599a3b55ad25
関連研究
- Learning Cross-modal Embeddings for Cooking Recipes and Food Images (CVPR2017) (Slide Share)
- A whole brain probabilistic generative model: Toward realizing cognitive architectures for developmental robots (link)
- fig.8, fig.9あたり
- Joint embedding / Cosine similarity / Cosine Loss / Triplet Loss / KL Divergence も同じor近い
環境
- keras (2.1.4)
- tensorflow-gpu (1.3.0)
joint embedding
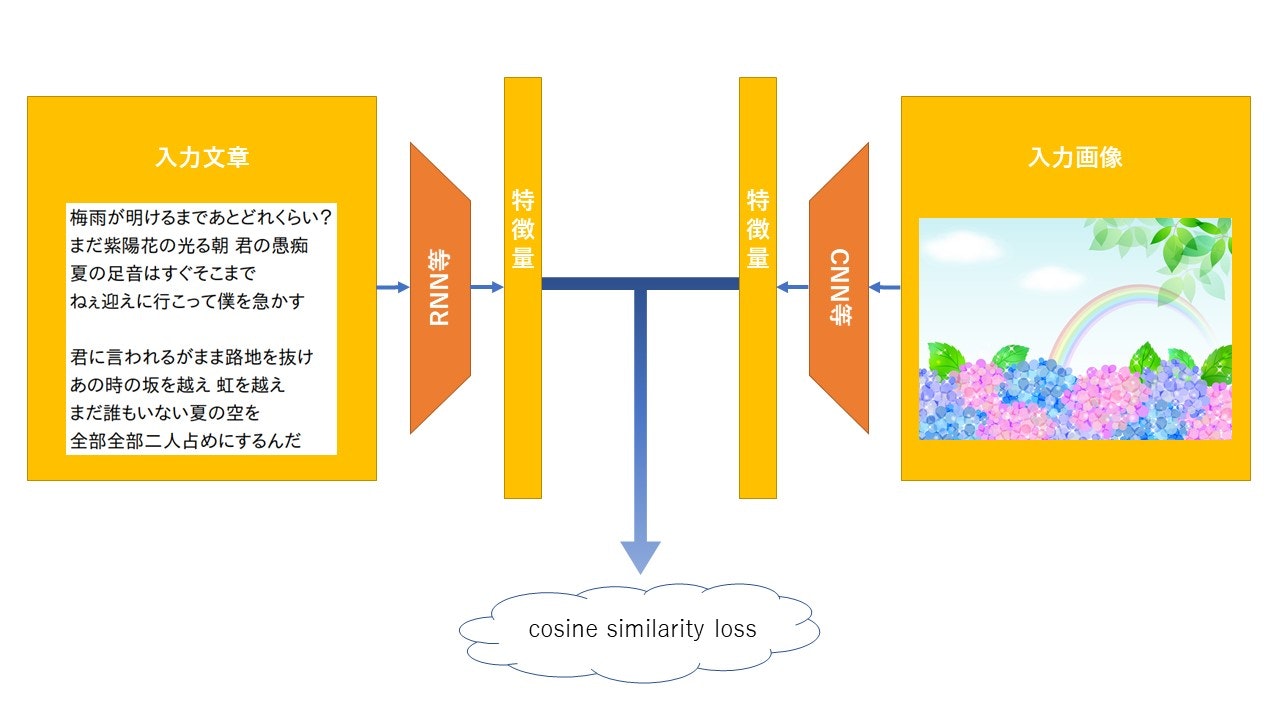
(ちょっと画像の選定が雑ですが・・・)
- 素敵な歌詞は Orangestar様『快晴』から拝借しました。
- http://www.nicovideo.jp/watch/sm31840221
- https://www5.atwiki.jp/hmiku/pages/36625.html
- 画像
- http://01.gatag.net/img/201505/18l/gatag-00004538.jpg
複数の異なるタスクから導かれる 特徴量/分散表現/潜在変数 を共通化させることで、
タスクに依存しない、より上位の概念を得ようとする手法(っていう個人的解釈…())
画像や文章、機械学習のタスクや取りうる行動などなどを分散表現したものでjoint embeddingすると面白いよね!(いやホントに)
課題設定
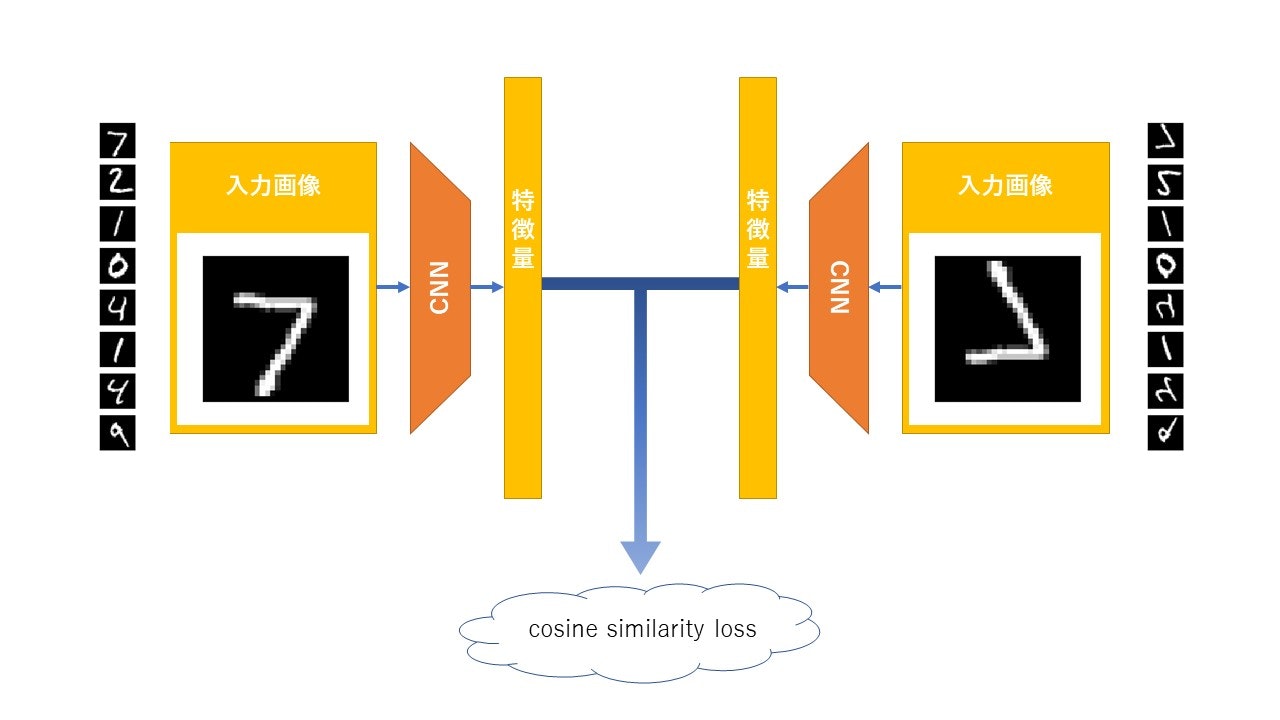
今回、上図のように、MNIST分類器を2つ用意し、joint embeddingっぽいことをしてみました。
同じモデルを2つ構築しても意味がないので、左側は普通の分類器、右側はMNISTの鏡文字を分類するモデルにしました。
ここで鏡数字データx_train等を作る際、データの順番は変えません。
(つまり、歌詞と紫陽花の画像の例のように、同じオブジェクトに対し2種類の観測データが得られているという状態)
また、左側のモデルには事前学習として明示的なタスク(0~9のクラス分類)を与えます。事前学習では普通にy_train等を与えて学習を行います。
で、右側のモデルには、明示的なタスクを与えません。y_train等も渡しません。
代わりに左側のモデルから得られた最終層の特徴量を共有することで分類器としての能力をつけます。
特徴量を共有するというのは、具体的には2つのモデルから得られるcos類似度を最小化することで実現できます。
(やってみて思ったんですが、今回簡単のためクラス分類でjoint embeddingっぽいことをしているので、
右側のモデルにはほとんどy_trainと同じ値をとるデータが渡されていて、うまくいくのはそれはそうって感じです、、。
クラス分類ではなく分散表現系でやると本領発揮って感じだとは思いますがそこはご愛嬌)
コードは結構なんとなくで書きました・・・(王道じゃないかも的な)
事前学習
先に片方のMNIST分類モデルをチューニングして、
これに後から別のMNIST(鏡文字)分類モデルと組み合わせてjoint embeddingします
import keras
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import numpy as np
import matplotlib.pyplot as plt
num_classes = 10
img_rows, img_cols = 28, 28
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
inputs = Input(shape=input_shape)
x = Conv2D(32, (3, 3), activation='relu', name="layer1")(inputs)
x = Conv2D(64, (3, 3), activation='relu', name="layer2")(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
x = Flatten()(x)
x = Dense(128, activation='relu', name="layer3")(x)
x = Dropout(0.5)(x)
outputs = Dense(10, activation='softmax', name="layer4")(x)
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=128,
epochs=12,
verbose=1,
validation_data=(x_test, y_test))
model.save_weights('my_model_weights.h5')
普通に分類してみる
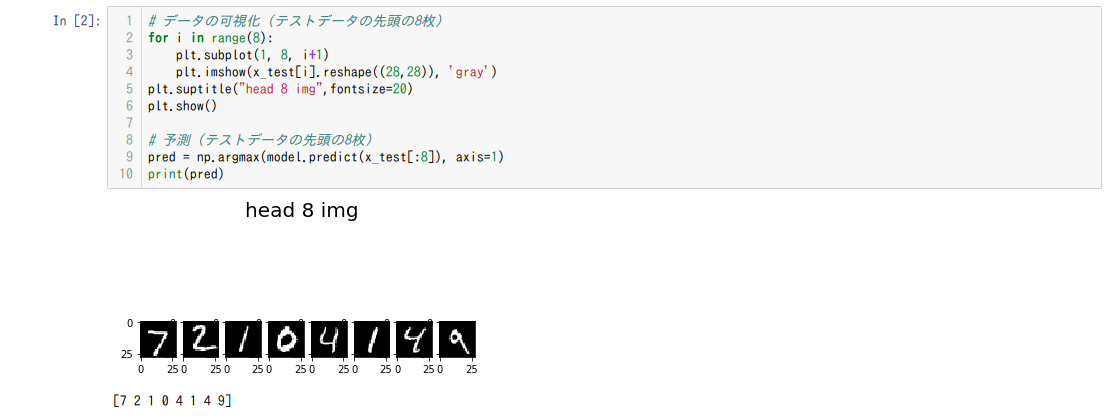
メインモデルの構築、学習
上のmodelとその瓜二つのモデルっぽいものをMergeレイヤーでjointさせたmodelを作っていきます
上のmodelはもう学習させる必要がないので、ここでは(簡単のために)trainable=Falseにします
↓上下逆さまの数字データセット(順番は変えない)
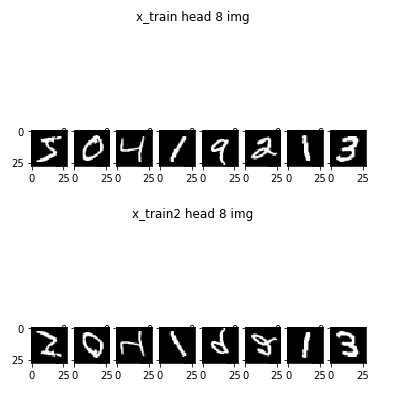
import keras
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Input, Dot, Reshape, Lambda
from keras import backend as K
import numpy as np
import matplotlib.pyplot as plt
num_classes = 10
img_rows, img_cols = 28, 28
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 鏡文字データの生成
x_train2 = x_train[:,::-1]
x_test2 = x_test[:,::-1]
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
x_train2 = x_train2.reshape(x_train2.shape[0], img_rows, img_cols, 1)
x_test2 = x_test2.reshape(x_test2.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
x_train2 = x_train2.astype('float32')
x_test2 = x_test2.astype('float32')
x_train2 /= 255
x_test2 /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# --------------------------------------------------------------
# ここでMNIST分類モデル(事前学習で使ったモデル)を定義しています
# --------------------------------------------------------------
inputs = Input(shape=input_shape)
x = Conv2D(32, (3, 3), activation='relu', trainable=False, name="layer1")(inputs)
x = Conv2D(64, (3, 3), activation='relu', trainable=False, name="layer2")(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Dropout(0.25)(x)
x = Flatten()(x)
x = Dense(128, activation='relu', trainable=False, name="layer3")(x)
x = Dropout(0.5)(x)
y = Dense(10, activation='softmax', trainable=False, name="layer4")(x)
# --------------------------------------------------------------
# ここでMNIST(鏡文字)分類モデルを定義しています
# --------------------------------------------------------------
inputs2 = Input(shape=input_shape)
x2 = Conv2D(32, (3, 3), activation='relu')(inputs2)
x2 = Conv2D(64, (3, 3), activation='relu')(x2)
x2 = MaxPooling2D(pool_size=(2, 2))(x2)
x2 = Dropout(0.25)(x2)
x2 = Flatten()(x2)
x2 = Dense(128, activation='relu')(x2)
x2 = Dropout(0.5)(x2)
y2 = Dense(10, activation='softmax', name="pred2")(x2)
# --------------------------------------------------------------
# ここでjoint embeddingっぽいことをしています
# --------------------------------------------------------------
cos_sim = Dot(axes = 1, normalize=True)([y, y2])
cos_sim = Reshape((1,))(cos_sim)
cos_sim = Lambda(lambda x: 1-x)(cos_sim)
model = Model(inputs=[inputs, inputs2], outputs=cos_sim)
# --------------------------------------------------------------
# 事前学習の結果を反映
# --------------------------------------------------------------
model.load_weights('my_model_weights.h5', by_name=True)
model.compile(loss="mean_absolute_error",
optimizer=keras.optimizers.Adadelta())
model.fit(x=[x_train, x_train2], y=[np.zeros(x_train.shape[0])], batch_size=128, epochs=2, verbose=1)
このmodelの最終出力は2つの特徴量?のcos類似度ですが、
model.fitさせるとき、引数yには何を与えればいいかわかんなかった(常ににy=0になってほしい)んですが、適当にnp.zerosを使いました(できたからよし)
最後に右側のモデルで数字を予測してみますっ
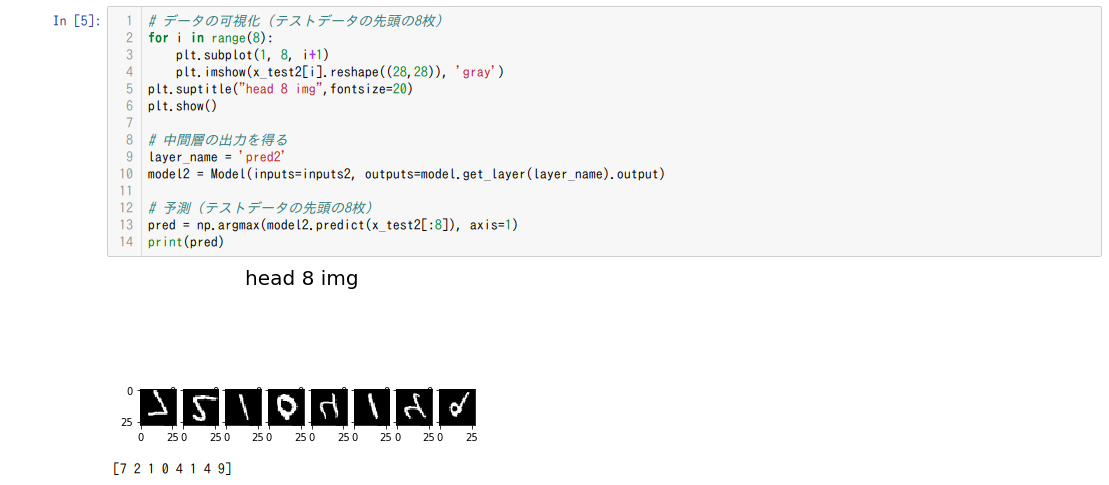
って感じで、MNIST(鏡文字)分類モデルは、教師ラベルを使わずに、左側のモデルと特徴量?を共有することで正しく分類できるようになりました
補足
それはそうって結果になりましたが、
どちらの分類器もtrainable=Trueにしたり、分類器として学習しながら並行してjoint embeddingを行ったりすればより深みのあるモデルになるんだと思います
以上
最後まで読んでくださってありがとうございました!
(よかったらいいねくださいっ!励みになります!!!!!)
twitter: https://twitter.com/namahoge