1. はじめに
EconMLは、機械学習を応用して因果効果を推定するためのPythonパッケージです。この記事では、EconMLユーザガイドの一部を和訳・要約しています。EconMLの特徴や用途をざっと確認したい方の参考になれば幸いです。
2. EconMLの概要
EconMLは、機械学習を応用し、データから因果効果を推定するためのPythonパッケージであり、機械学習と因果推論の様々な推定手法を提供しています。これらの手法は、解釈しやすい因果関係のモデルを仮定し、そのモデルにおける個々の変数を機械学習を応用して推定することで、予測の信頼性を向上させ、幅広いユーザーにとって因果分析をより迅速かつ容易なものにします。
企業が製品価格を変更するケースや、医師が新しい治療法を採用するケースなど、何か方策を変更するとき、反事実的な質問「もし方策を変更したらどうなるだろうか?」に答えるためには、因果関係の影響を推定する必要があります。現在の機械学習ツールのほとんどは、現在とっている戦略や方策の下で次に何が起こるかを予測するように設計されており、特定の方策や行動の変化の影響を予測・解釈することは難しいといえます。一方EconMLは、因果関係に関する質問に答えるために設計されています。言い換えると、現在の機械学習ツールのほとんどは、「今まで通りであれば、次に何が起こるか」という予測的な質問に答えるように設計されているのに対し、EconMLは、「行動や価格、条件の変化に応じて何が起こるか」という因果関係に関する質問に答えるために設計されています。
EconMLは、マイクロソフトリサーチのALICEチームによって開発されたオープンソースソフトウェアであり、以下のような特徴を持ちます。
- 柔軟性
- 個々のサンプルに対する処置1効果(HTE: Heterogeneous Treatment Effects)を表現するモデルを含む、強い仮定を課さない柔軟なモデル設定が可能
- 統一性
- 計量経済学と機械学習の最新の研究成果を用いた幅広い分析手法を統一されたAPIで提供
- 使い慣れたインターフェース
- 機械学習とデータ分析のための標準的なPythonパッケージをベースに構築
3. EconMLの適用例
ユーザーガイドでは、EconMLを活用できる場面として、
- A/Bテストが難しい場合の効果検証
- 顧客のセグメンテーション
- 複数の処置効果の推定
をしたいケースが挙げられています。以下では、それぞれのケースについて簡単に紹介します。
Case 1. A/Bテストが難しい場合の効果検証
A/Bテストが難しい場合の処置の因果的効果を解釈します。
課題:
ある旅行ウェブサイトにおいて、ユーザーが会員制プログラムに参加することで、ウェブサイトの滞在時間が長くなるかどうか知りたいと考えています。
問題点:
既存のログデータをもとに、会員と非会員を直接比較することで、会員制プログラムの効果を検証することは適切ではありません。会員になることを選択したユーザーは、他のユーザーよりもすでにエンゲージメントが高い可能性があるためです。また、ユーザーに会員登録を強制することはできないため、A/Bテストを実施することもできません。
解決策:
この旅行ウェブサイトを運営する会社は、新しい会員登録プロセスの価値を検証するために、以前実験を行ったことがありました。EconMLのDRIV推定器では、この実験的な入会への後押しを、入会するか否かをランダム化させる操作変数2として用います。DRIVモデルは、新しい会員登録プロセスを提供された顧客すべてが会員になるわけではないということを加味し、新しい会員登録プロセスを提供された効果ではなく、会員になったことによる効果を推定することができます。(より詳細な説明はこちらのnotebook を参照してください。)
Case 2. 顧客のセグメンテーション
インセンティブに対する各々の顧客の反応を推定します。
課題:
あるメディア購読サービスでは、顧客ごとにパーソナライズされた料金プランによって、ターゲットを絞った割引を提供したいと考えています。
問題点:
顧客の様々な特徴量をデータとして取得できますが、どの顧客がより安い価格に反応するかを判断することができません。
解決策:
EconMLのDML推定器は、顧客の特徴量とともに既存データにおける価格の変動を利用し、顧客によって異なる価格への感度を推定することができます。木構造のモデルは、割引に対する感度における大きな差異を説明する主要な特徴量を、プレゼンテーションに適した形式に要約して提供してくれます。(より詳細な説明はこちらのnotebook を参照してください。)
Case 3. 複数の処置効果の推定
複数のアウトリーチ活動の効果を区別して推定します。
課題:
ある新興企業は、新規顧客を獲得するための最も効果的な方法として、料金の割引、サービスの導入を容易にする技術サポート、あるいはその2つの組み合わせのいずれがよいかを知りたいと考えています。
問題点:
顧客を失うリスクがあるため、アウトリーチ活動全般にわたる実験にはコストがかかりすぎます。そのため、これまでは大企業ほど技術サポートを受けやすいなど、戦略的に顧客にインセンティブを提供してきました。
解決策:
EconMLのDoubly Robust Learnerモデルは、複数の処置の効果を推定することができます。このモデルは、観測された顧客の特徴量を柔軟にモデル化することで、既存データにおける交絡を除外し、各取り組みが収益に与える因果効果を推定します。(より詳細な説明はこちらのnotebook を参照してください。)
4. EconMLの使い方
4-1. EconMLの主眼はHTE推定
機械学習技術に期待されることの一つは、多くの業務領域における意思決定の自動化です。データを活用することで個人や属性によって意思決定をパーソナライズしたい、そんなときに焦点となる課題は、HTE (Heterogeneous Treatment Effects) を推定することです。つまり、処置が結果に与える効果を、観察可能な特徴量の関数として表現し、その効果はどの程度なのかを推定することが問題になります。たとえば、価格設定を顧客ごとにパーソナライズしたいとき、顧客の特徴量の関数として、需要に対する割引の効果を推定することが目標になります。同様に、医療における治験では、患者の特徴量の関数として、患者の臨床反応に対する薬物治療の効果を推定することが目標になります。そのようなシチュエーションでは、観察データは豊富にある一方で、処置するか否かを決定する方策が明確でなかったり、A/Bテストを実施することが難しかったりします。
EconMLパッケージは、計量経済学と機械学習を掛け合わせた最新技術を実装し、機械学習ベースのアプローチによるHTE推定の問題に取り組んでいます。これらの分析手法は、ランダムフォレスト、ブースティング、ラッソ、ニューラルネットなどの手法により、処置効果の不均一性を柔軟にモデル化することができます。それと同時に、因果推論と計量経済学の手法を活用し、学習したモデルの因果的解釈を可能とし、多くの場合、信頼区間を算出することで統計的妥当性を提供します。
4-2. HTE推定の定式化
EconMLでは、潜在アウトカムフレームワーク(Potential Outcome Framework)にもとづく定式化をもとに、HTE推定を行います。本節では、EconMLが扱っているHTE推定を数式を用いて説明します。
使用する記法は以下の通りです。
- $T$:処置を表す変数(ベクトル)
- $t$:$T$の実現値
- $Y$:結果変数
- $Y(t)$:処置 $t$ に対する結果
- $X$:共変量3のうち、結果に与える影響として関心があるもの
- $x$:$X$ の実現値
- $W$:共変量のうち、結果に与える影響として関心がないもの
- $Z$:操作変数
- $\epsilon, \eta$:誤差
HTEは、$T$ が離散値をとるか連続値をとるかによって定義が異なります4。まず $T$ が離散値をとる場合、異なる処置 $t_0, t_1$ に対する結果変数の差分をもとに、HTE: $\tau(t_0, t_1,x)$ を以下のように定義します。
\tau(t_0, t_1,x)=E[Y(t_1)-Y(t_0)|X=x]
一方、$T$ が連続値をとる場合、$T=t$ 周辺における勾配 $\nabla_t$ をもとに、周辺効果: $\partial\tau(t,x)$ を以下のように定義します。
\partial\tau(t,x)=E[\nabla_t Y(t)|X=x]
また、$T$ および $Y$ が、$T=f(X, W, Z, \eta), Y=g(T, X ,W, \epsilon)$ と表されると仮定し、$Y(t)=g(t, X ,W, \epsilon)$ としたうえで改めて $\tau(t_0, t_1,x)$ と $\partial\tau(t,x)$ を書き直すと、以下のようになります。
\tau(t_0, t_1,x)=E[g(t_1, X ,W, \epsilon)-g(t_0, X ,W, \epsilon))|X=x] \\
\partial\tau(t,x)=E[\nabla_t g(t, X ,W, \epsilon)|X=x]
$\tau(t_0, t_1,x)$ は CATE (Conditional Average Treatment Effect)、$\partial\tau(t,x)$ はmarginal CATEと呼ばれます。
さらに、$Y$ が $T$ に対し線形である、つまり、$Y=H(X ,W)\cdot T + h(X ,W, \epsilon)$ で表される5場合、先ほどのCATE, marginal CATEは
\tau(t_0, t_1,x)=E[H(X ,W)|X=x](t_1-t_0) \\
\partial\tau(t,x)=E[H(X ,W)|X=x]
と表されます。また、$T$ ではなく関数 $\phi()$ により変換した $\phi(T)$ に対して線形である場合は、$t_1, t_0, t$ がそれぞれ $\phi(t_1), \phi(t_0), \phi(t)$ に置き換わります6。
4-3. EconMLのAPI
EconMLは、マイクロソフトリサーチのALICEプロジェクトで内製した分析手法をはじめ、この分野の主要なグループによる最新技術を実装しています。例えば、
- Double Machine Learning([Chernozhukov2016], [Chernozhukov2017], [Mackey2017], [Nie2017], [Chernozhukov2018], [Foster2019] を参照)
- Causal Forests([Wager2018]、[Athey2019], [Oprescu2019] を参照)
- Deep Instrumental Variables([Hartford2017] を参照)
- Non-parametric Instrumental Variables([Newey2003] を参照)
- Meta-learners([Kunzel2017] を参照)
を実装しています。
EconMLは、これら様々な手法を共通のPython APIの下にまとめています。EconMLのAPIでは、ベースとなる推定器のクラスとして、BaseCateEstimatorクラスを定義・実装しており、様々な推定器で共通して利用できる関数は、fit(), effect(), marginal_effect(), effect_interval(), marginal_effect_interval()の5つです7。
class BaseCateEstimator
def fit(self, Y, T, X=None, W=None, Z=None, inference=None):
''' CATE τ(·, ·, ·) およびmarginal CATE ∂τ(·, ·)を推定する
(詳細は割愛)
'''
def effect(self, X=None, *, T0, T1):
''' 2つの処置 T0, T1 間のCATE τ(·, ·, ·)を算出する
(詳細は割愛)
'''
def marginal_effect(self, T, X=None):
''' 処置 T におけるmarginal CATE ∂τ(·, ·)を算出する
(詳細は割愛)
'''
def effect_interval(self, X=None, *, T0=0, T1=1, alpha=0.05):
''' CATE τ(·, ·, ·)の信頼区間の上限・下限を算出する
(詳細は割愛)
'''
def marginal_effect_interval(self, T, X=None, *, alpha=0.05):
''' marginal effect ∂τ(·, ·)の信頼区間の上限・下限を算出する
(詳細は割愛)
'''
EconMLを利用する場合は、CATEおよびmarginal CATEを推定するための分析手法を以降のフローチャート等を参考に決定したうえで、$Y$ および $T$ のモデルをscikit-learnにおいて実装されているものをベースに指定する必要があります。具体的な実装例は、例えばDMLの使用例のnotebookを参照してください。
4-4. 分析手法の選択フロー
ユーザーガイドでは、EconMLに実装されている様々な分析手法の中から、分析対象のデータに合わせた手法を選択するフローがまとめられています。
フローを説明する前に、EconMLで仮定している状況と、フローにおいて扱われている判断基準を整理します。EconMLでは、基本的に以下の3つの条件のいずれかが満たされていることを仮定しています。
1.処置がランダムである
2.共変量がすべて観測できている
3.操作変数が観測できている
言い換えると、処置がランダムでなく、かつ未観測の共変量が存在し、かつ操作変数が観測できていない場合は想定していません。一般的にこのような場合は因果効果の推定時のバイアスを取り除くのが困難になるため、EconMLで妥当な推定を行うことは難しいといえます。
次に、フローにおいて扱われている判断基準は以下の8つです。
- A/Bテストなどの実験を行っており、処置がランダムであるか(Did you run an EXPERIMENT?)
- ノンコンプライアンス8が起きているか(Was COMPLIANCE Incomplete?)
- 交絡因子となる共変量はすべて観測できているか(Do you MEASURE all the confounding drivers of TREATMENT ASSIGNMENT?)
- 操作変数は存在するか(Is treatment assignment driven by an INSTRUMENT that does not directly affect your outcome?)
- 処置効果は線形か(LINEAR TREATMENT EFFECTS?)
- 処置に影響を与えている変数は少ないか(Few features affect TREATMENT RESPONSIVENESS?)
- 処置効果の異質性は線形的か(LINEAR HETEROGENEITY?)
- 関心があるのは信頼区間とモデル選択のどちらか(CONFIDENCE INTERVALS or MODEL SELECTION)
おおまかな基準で分けると、1.と2.が成立している、もしくは4.が成立している場合は操作変数ベースの手法、他の場合は共変量ベースの手法とに分けられます。そこから、5.~8.の基準をもとに線形・非線形の処置効果などさらに分けられます。
基準自体は8つですが、フローチャート上で紹介されている手法は6種類に分類されています。先ほど説明した操作変数ベースの手法の場合、5.を満たすなら2SLS IV・IntentToTreatDRIV・LinearIntentToTreatDRIV、反対に5.を満たさないならDeep IV・NonParamDMLIVが候補となります9。また、共変量ベースの手法の場合、6.を満たさない場合SparseLinearDML・SparseLinearDRLearner、6., 7.を満たすならLinearDML・LinearDRLearner、8.で信頼区間に関心があるならDMLOrthoForest・DROrthoForest・ForestDRLearner・CausalForestDML、8.でモデル選択に関心があるならMetaLearners・DRLearner・DML・NonParamDMLが候補となります10。
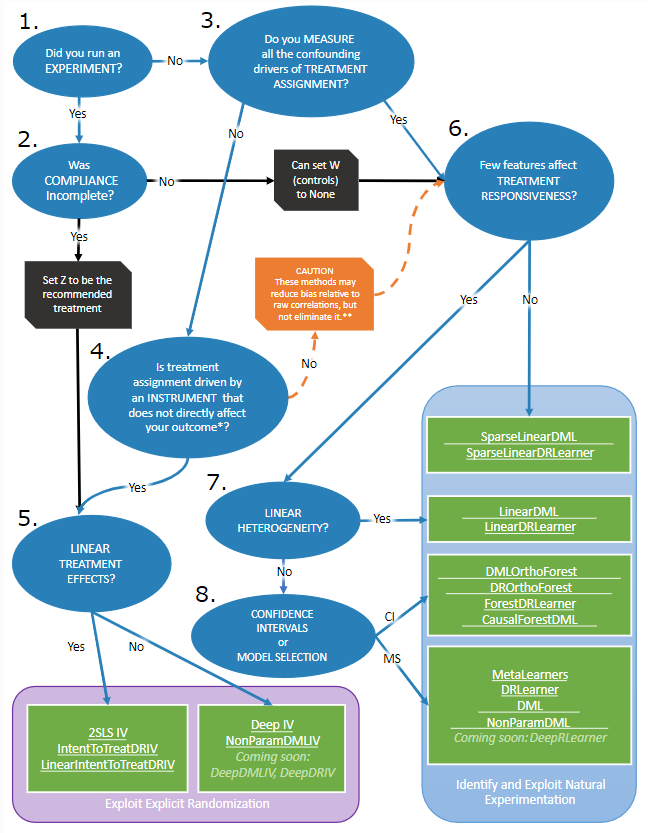
図1:分析手法の選択フロー(ユーザーガイドより抜粋。図中の番号は執筆者が記載)
5. EconMLを活用する際に注意すべきこと
本節では、ユーザーガイドのFAQから抜粋した、EconMLを活用する際の注意点をご紹介します。
推定結果が理にかなっているかどうかはどうすればわかるか?
因果関係における線形性など、データにおける仮定が異なる複数のモデル間で推定値の一貫性を比較してみてください。推定値のばらつきも解釈する必要があるので、点推定値だけでなく、標準誤差にも注意を払いましょう。分析対象としている業務領域特有の知識をもとに評価・解釈することも重要です。たとえば、価格を5%下げると売上が5000%増加するというありえないような推定をした場合、コードを注意深く見直す必要があります。
理にかなっていない推定結果が得られた場合、次はどうすればいい?
まず、コードに誤りがないか注意深くチェックし、いくつかの推定モデルを試してみてください。推定値が一貫しているが、不自然な推定結果が得られている場合は、データが取得できていない交絡因子がある可能性があります。データソースについて再考しましょう。たとえば
- データ収集期間に何か異常なことが起きていなかったか(例:休日・景気後退)
- サンプルに何か異常はないか(例:すべてのデータが心臓に持病のある男性)
A/Bテストなどの実験ができず、すべての交絡因子を観察できない場合はどうすればいい?
この場合、どんな統計手法も処置が結果に与える因果関係を完全に分離することはできません。DML, OrthoForest, MetaLearnersは、観測できるすべての交絡因子を含めて、交絡因子によるバイアスを最小にする因果効果の近似値を推定します。これらの推定値を使用する際には、若干のバイアスが残っていることに留意してください。
因果効果を特定できているかどうか、どのように検証すればいい?
分析手法が仮定している因果関係のモデルが正しい場合にのみ、妥当な因果効果を特定することができますが、その仮定を検証することは難しいことが多いです(DoWhyパッケージが役に立つ可能性はありますが)。EconMLパッケージは、その仮定が正しい前提で、できる限り最良の因果関係のモデルを構築します。多くのモデルはモデルの性能指標を保持しており、因果関係のモデルがホールドアウトデータをどの程度精度よく予測するかを検証するために使用することができます。これは、モデルの品質を検証する良い手段の一つです。
6. おわりに
この記事ではEconMLユーザガイドの一部をまとめました。EconMLを使ってみたい方の参考となれば幸いです。本文中では因果推論の詳細説明は割愛しましたが、そちらに興味がある方はこちらの記事などを参照してください。
7. 参考文献
-
処置(treatment)とは、ビジネスにおいては施策やアクション(例:割引クーポンを送付する)のことを指します。介入とも呼びます。 ↩
-
操作変数とは「共変量と独立であり、かつ処置を介してのみ結果に影響を与える変数」のことです。 ↩
-
共変量とは「処置と結果の両方に影響を与える変数」のことです。 ↩
-
処置が連続的である場合、厳密には連続的な確率変数がただ1つの値をとる確率は0なので、処置を表す変数がある値近辺をとるときの効果(周辺効果)を扱います。 ↩
-
ユーザーガイドでは $h()$ ではなく $g()$ を用いて表記していますが、この記事では $Y=g(T, X ,W, \epsilon)$ における $g()$ との混同を避けるため分けて表記しています。 ↩
-
なお、この場合のmarginal CATEは、$\phi(t)$ に対するヤコビアン行列 $\nabla \phi(t)$ を用いて $\partial\tau(t,x)=E[H(X ,W)|X=x]\nabla \phi(t)$ と表されます。 ↩
-
具体的なCATE/marginal CATE推定器の実装は、個々の推定器によって変わる点にご注意ください。実装に興味がある方は、例えばEconMLの_OrthoLernerクラスが参考になると思います。 ↩
-
ノンコンプライアンスとは、処置の割り当て通りに処置が適用されていない状態を指します。 ↩
-
執筆時点では新たにDeepDMLIV・DeepDRIVが実装予定とされています。 ↩
-
執筆時点では新たにDeepRLearnerが実装予定とされています。 ↩