この投稿はこのノートブックの和訳です。

顧客セグメンテーション -- インセンティブに対する個別の反応を推定する
現在、ビジネスの意思決定者は、特定の製品を割引で宣伝する、ウェブサイトに新機能を追加する、営業チームからの投資を増やすなど、戦略のシフトに関するWhat-ifの質問(もし〜したらどうなるか?)に答えるために、介入の因果関係を推定することに頼っています。しかし、すべてのユーザーに関して特定の介入に対して行動を起こすかどうかを知るよりも、2つの選択肢に対する異なるユーザーの異なる反応を理解することに関心が高まっています。介入に対して最も強い反応を示すユーザーの特徴を特定することは、将来のユーザーを異なるグループにセグメントするためのルール作りに役立つ可能性があります。これは、最小のリソースを使用し、最大の利益を得るために政策を最適化するのに役立つ可能性があります。
このケーススタディでは、パーソナライズされた価格設定の例を用いて、EconMLライブラリがこの問題にどのように適合し、堅牢で信頼性の高い因果関係の解決策を提供できるかを説明します。
概要
- 背景
- データ
- EconMLで因果関係を取得する
- EconMLで処置効果を理解する
- EconMLで方針決定を行う
- 結論
背景

世界のオンラインメディア市場は、年々急速に成長しています。メディア企業は、より多くのユーザーを市場に呼び込み、より多くの曲を購入してもらったり、会員になってもらったりすることに常に関心を持っています。この例では、あるメディア企業が行っている実験の一つとして、現在のユーザーの所得レベルに応じて小額の割引(10%、20%、または0)を与えて購入の可能性を高めるというシナリオを考えてみましょう。その目的は、所得水準の異なる人々の需要の異質な価格弾力性を理解し、どのユーザーが少額割引に最も強く反応するかを知ることです。さらに、最終的な目標は、一部の消費者の価格を下げても、全体の収益を上げるのに十分な需要があることを確認することである。
EconMLの DMLCateEstimator ベースの推定器は、既存のデータに含まれる割引のばらつきを、豊富なユーザ特徴のセットとともに利用して、複数の顧客特徴に応じて変化する不均一な価格感応度を推定するために使用することができます。次に、SingleTreeCateInterpreterは、割引に対する反応性の最大の違いを説明する主要な特徴の要約をプレゼンテーションに対応して提供し、SingleTreePolicyInterpreterは、(需要だけでなく)収益を増加させるために誰が割引を受けるべきかについてのポリシーを推奨し、企業が将来、これらのユーザーに対して最適な価格を設定するのに役立ちます。
# Some imports to get us started
# Utilities
import os
import urllib.request
import numpy as np
import pandas as pd
# Generic ML imports
from sklearn.preprocessing import PolynomialFeatures
from sklearn.ensemble import GradientBoostingRegressor
# EconML imports
from econml.dml import LinearDMLCateEstimator, ForestDMLCateEstimator
from econml.cate_interpreter import SingleTreeCateInterpreter, SingleTreePolicyInterpreter
import matplotlib.pyplot as plt
%matplotlib inline
データ
データセット* には10,000件の観測値があり、年齢、ログ収入、前回の購入履歴、1週間の前回のオンライン時間など、ユーザーの特性とオンライン行動履歴を表す9つの連続変数とカテゴリカル変数を含んでいます。
以下の変数を定義しています。
| 特徴量名 | タイプ | 詳細 |
|---|---|---|
| account_age | W | ユーザーのアカウント年齢 |
| age | W | ユーザーの年齢 |
| avg_hours | W | 過去にユーザーが1週間にオンラインで過ごした平均時間 |
| days_visited | W | 過去の1週間の平均訪問日数 |
| friend_count | W | アカウントに接続されている友達の数 |
| has_membership | W | ユーザーがメンバーシップを持っていたかどうか |
| is_US | W | ユーザーが米国からウェブサイトにアクセスしているかどうか |
| songs_purchased | W | 過去にユーザーが1週間に購入した平均曲数 |
| income | X | ユーザーの収入 |
| price | T | 割引期間中にユーザーが見た価格 (baseline price * samll discount) |
| demand | Y | ユーザーが割引期間中に購入した曲 |
*企業のプライバシー保護のため、ここではシミュレーションデータを例にしています。データは合成的に生成されたものであり、特徴の分布は実際の分布とは一致しませんが、特徴量名は名前と意味を保持しています。
処置と結果は以下の関数を用いて生成されます。

# Import the sample pricing data
file_url = "https://msalicedatapublic.blob.core.windows.net/datasets/Pricing/pricing_sample.csv"
train_data = pd.read_csv(file_url)
# Data sample
train_data.head()
| account_age | age | avg_hours | days_visited | friends_count | has_membership | is_US | songs_purchased | income | price | demand | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 53 | 1.834234 | 2 | 8 | 1 | 1 | 4.903237 | 0.960863 | 1.0 | 3.917117 |
| 1 | 5 | 54 | 7.171411 | 7 | 9 | 0 | 1 | 3.330161 | 0.732487 | 1.0 | 11.585706 |
| 2 | 3 | 33 | 5.351920 | 6 | 9 | 0 | 1 | 3.036203 | 1.130937 | 1.0 | 24.675960 |
| 3 | 2 | 34 | 6.723551 | 0 | 8 | 0 | 1 | 7.911926 | 0.929197 | 1.0 | 6.361776 |
| 4 | 4 | 30 | 2.448247 | 5 | 8 | 1 | 0 | 7.148967 | 0.533527 | 0.8 | 12.624123 |
# Define estimator inputs
Y = train_data["demand"] # outcome of interest
T = train_data["price"] # intervention, or treatment
X = train_data[["income"]] # features
W = train_data.drop(columns=["demand", "price", "income"]) # confounders
# Get test data
X_test = np.linspace(0, 5, 100).reshape(-1, 1)
X_test_data = pd.DataFrame(X_test, columns=["income"])
EconMLで因果関係を取得する
需要の価格弾力性を所得の関数として学習するために、以下のようにモデルを当てはめます。
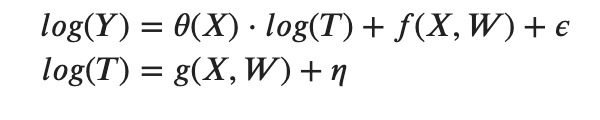
where $\epsilon, \eta$ are uncorrelated error terms.
ここでフィットさせたモデルは、上記のデータ生成関数と完全に一致するものではないですが、良い近似値であれば、良い割引政策を作成することができるでしょう。 モデルは不特定ではありますが、私たちの DMLCateEstimator ベースの estimators がまだ $\theta(X)$ の正しい傾向を捉えることができ、推奨されたポリシーが他のベースライン・ポリシー(常に割引を与えるなど)よりも収益に勝ることを期待しています。 データの生成過程とモデルのミスマッチのため、単一の真の$\theta(X)$は存在しない(真の弾力性はXだけでなく、TとWによっても変化する)ですが、上記のデータの生成方法を考えると、比較するための真の$\theta(X)$の範囲を計算することは可能です。
# Define underlying treatment effect function given DGP
def gamma_fn(X):
return -3 - 14 * (X["income"] < 1)
def beta_fn(X):
return 20 + 0.5 * (X["avg_hours"]) + 5 * (X["days_visited"] > 4)
def demand_fn(data, T):
Y = gamma_fn(data) * T + beta_fn(data)
return Y
def true_te(x, n, stats):
if x < 1:
subdata = train_data[train_data["income"] < 1].sample(n=n, replace=True)
else:
subdata = train_data[train_data["income"] >= 1].sample(n=n, replace=True)
te_array = subdata["price"] * gamma_fn(subdata) / (subdata["demand"])
if stats == "mean":
return np.mean(te_array)
elif stats == "median":
return np.median(te_array)
elif isinstance(stats, int):
return np.percentile(te_array, stats)
# Get the estimate and range of true treatment effect
truth_te_estimate = np.apply_along_axis(true_te, 1, X_test, 1000, "mean") # estimate
truth_te_upper = np.apply_along_axis(true_te, 1, X_test, 1000, 95) # upper level
truth_te_lower = np.apply_along_axis(true_te, 1, X_test, 1000, 5) # lower level
パラメトリック異質性
まず、処置効果の線形射影を、$\theta(X)$の多項式を仮定して学習してみます。推定にはLinearDMLCateEstimatorを用います。これらのモデルには前例がないので、一般的な勾配ブースティング木推定器を用いて、データから期待価格と需要を学習します。
# Get log_T and log_Y
log_T = np.log(T)
log_Y = np.log(Y)
# Train EconML model
est = LinearDMLCateEstimator(
model_y=GradientBoostingRegressor(),
model_t=GradientBoostingRegressor(),
featurizer=PolynomialFeatures(degree=2, include_bias=False),
)
est.fit(log_Y, log_T, X, W, inference="statsmodels")
# Get treatment effect and its confidence interval
te_pred = est.effect(X_test)
te_pred_interval = est.effect_interval(X_test)
# Compare the estimate and the truth
plt.figure(figsize=(10, 6))
plt.plot(X_test.flatten(), te_pred, label="Sales Elasticity Prediction")
plt.plot(X_test.flatten(), truth_te_estimate, "--", label="True Elasticity")
plt.fill_between(
X_test.flatten(),
te_pred_interval[0],
te_pred_interval[1],
alpha=0.2,
label="90% Confidence Interval",
)
plt.fill_between(
X_test.flatten(),
truth_te_lower,
truth_te_upper,
alpha=0.2,
label="True Elasticity Range",
)
plt.xlabel("Income")
plt.ylabel("Songs Sales Elasticity")
plt.title("Songs Sales Elasticity vs Income")
plt.legend(loc="lower right")
<matplotlib.legend.Legend at 0x2b59979a588>

上のプロットから、真の処置効果は所得の非線形関数であり、所得が1より小さい場合は弾力性が-1.75前後で、所得が1より大きい場合は小さな負の値であることがわかります。 このモデルは2次処置効果にフィットしますが、あまりフィットしていません。しかし、それでも全体的な傾向を捉えています:弾力性は負であり、人々は所得が高いほど価格の変化に敏感ではありません。
# Get the final coefficient and intercept summary
est.summary(feat_name=X.columns)
| point_estimate | stderr | zstat | pvalue | ci_lower | ci_upper | |
|---|---|---|---|---|---|---|
| income | 2.451 | 0.065 | 37.659 | 0.0 | 2.344 | 2.558 |
| income^2 | -0.443 | 0.022 | -20.517 | 0.0 | -0.479 | -0.408 |
| point_estimate | stderr | zstat | pvalue | ci_lower | ci_upper | |
|---|---|---|---|---|---|---|
| intercept | -3.04 | 0.042 | -72.165 | 0.0 | -3.109 | -2.97 |
またLinearDMLCateEstimator estimatorは、点推定値、p値、信頼区間を含む、最終モデルの係数と切片の要約を返すことができます。上の表から、$income$は正の効果を持ち、${income}^2$は負の効果を持ち、どちらも統計的に有意であることがわかります。
ノンパラメトリック異質性
真の処置効果関数が非線形であることはすでにわかっているので ForestDMLCateEstimatorを使用して別のモデルを当てはめます。これは、完全に処置効果のノンパラメトリック推定を前提としています。
# Train EconML model
est = ForestDMLCateEstimator(
model_y=GradientBoostingRegressor(), model_t=GradientBoostingRegressor()
)
est.fit(log_Y, log_T, X, W, inference="blb")
# Get treatment effect and its confidence interval
te_pred = est.effect(X_test)
te_pred_interval = est.effect_interval(X_test)
# Compare the estimate and the truth
plt.figure(figsize=(10, 6))
plt.plot(X_test.flatten(), te_pred, label="Sales Elasticity Prediction")
plt.plot(X_test.flatten(), truth_te_estimate, "--", label="True Elasticity")
plt.fill_between(
X_test.flatten(),
te_pred_interval[0],
te_pred_interval[1],
alpha=0.2,
label="90% Confidence Interval",
)
plt.fill_between(
X_test.flatten(),
truth_te_lower,
truth_te_upper,
alpha=0.2,
label="True Elasticity Range",
)
plt.xlabel("Income")
plt.ylabel("Songs Sales Elasticity")
plt.title("Songs Sales Elasticity vs Income")
plt.legend(loc="lower right")
<matplotlib.legend.Legend at 0x2b59987ee48>

このモデルはLinearDMLCateEstimatorよりも適合性が高く、90%信頼区間は真の処置効果の推定値を正しくカバーし、所得が1前後の場合の変動を捉えていることに気づきました。 全体的に、このモデルは、低所得者が高所得者よりも価格変動に敏感であることを示しています。
EconMLで処置効果を理解する
EconMLには、処置効果をよりよく理解するための解釈可能なツールが含まれています。処置効果は複雑なものですが、多くの場合、提案された変更に対して肯定的に反応するユーザ、中立的に反応するユーザ、否定的に反応するユーザを区別できる単純なルールに私たちは興味があります。
EconMLの SingleTreeCateInterpreter は、EconMLの推定量のいずれかによって出力された処置効果について単一の決定木を学習することで、相互適用性を提供します。下の図では、暗赤色のユーザは割引に対して強く反応し、白色のユーザは割引に対して軽く反応していることがわかります。
intrp = SingleTreeCateInterpreter(include_model_uncertainty=True, max_depth=2, min_samples_leaf=10)
intrp.interpret(est, X_test)
plt.figure(figsize=(25, 5))
intrp.plot(feature_names=X.columns, fontsize=12)

EconMLで方針決定を行う
需要ではなく収益を最大化するように方針を決定したいと考えています。 このシナリオでは、

価格が下がっても、$\theta(X)+1<0$でなければ、収益は増えません。そこで、ここでは sample_treatment_cast=-1 とすることで、どのような顧客に少し値引きをすれば収益が最大になるのかを知ることができます。
EconMLライブラリには、SingleTreePolicyInterpreterのようなポリシー解釈ツールが含まれており、処置コストと処置効果を考慮して、どの顧客をターゲットにして利益を上げるべきかを簡単に学習することができます。下の図では、所得が$0.985$以下の人には割引を行い、それ以外の人には元の価格を与えることを推奨していることがわかります。
intrp = SingleTreePolicyInterpreter(risk_level=0.05, max_depth=2, min_samples_leaf=1, min_impurity_decrease=0.001)
intrp.interpret(est, X_test, sample_treatment_costs=-1, treatment_names=["Discount", "No-Discount"])
plt.figure(figsize=(25, 5))
intrp.plot(feature_names=X.columns, fontsize=12)

では、私たちの方針を他のベースライン方針と比較してみましょう。我々のモデルでは、どの顧客に小額の割引をするかを指定しており、この実験では、それらのユーザーに10%の割引レベルを設定します。モデルが不正確なので、大きな割引では良い結果は期待できません。ここでは、根拠がわかっているので、この方針の価値を評価することができます。
# define function to compute revenue
def revenue_fn(data, discount_level1, discount_level2, baseline_T, policy):
policy_price = baseline_T * (1 - discount_level1) * policy + baseline_T * (1 - discount_level2) * (1 - policy)
demand = demand_fn(data, policy_price)
rev = demand * policy_price
return rev
policy_dic = {}
# our policy above
policy = intrp.treat(X)
policy_dic["Our Policy"] = np.mean(revenue_fn(train_data, 0, 0.1, 1, policy))
## previous strategy
policy_dic["Previous Strategy"] = np.mean(train_data["price"] * train_data["demand"])
## give everyone discount
policy_dic["Give Everyone Discount"] = np.mean(revenue_fn(train_data, 0.1, 0, 1, np.ones(len(X))))
## don't give discount
policy_dic["Give No One Discount"] = np.mean(revenue_fn(train_data, 0, 0.1, 1, np.ones(len(X))))
## follow our policy, but give -10% discount for the group doesn't recommend to give discount
policy_dic["Our Policy + Give Negative Discount for No-Discount Group"] = np.mean(revenue_fn(train_data, -0.1, 0.1, 1, policy))
## give everyone -10% discount
policy_dic["Give Everyone Negative Discount"] = np.mean(revenue_fn(train_data, -0.1, 0, 1, np.ones(len(X))))
# get policy summary table
res = pd.DataFrame.from_dict(policy_dic, orient="index", columns=["Revenue"])
res["Rank"] = res["Revenue"].rank(ascending=False)
res
| Revenue | Rank | |
|---|---|---|
| Our Policy | 14.686241 | 2.0 |
| Previous Strategy | 14.349342 | 4.0 |
| Give Everyone Discount | 13.774469 | 6.0 |
| Give No One Discount | 14.294606 | 5.0 |
| Our Policy + Give Negative Discount for No-Discount Group | 15.564411 | 1.0 |
| Give Everyone Negative Discount | 14.612670 | 3.0 |
ベースラインの方針に勝ちました!
私たちの方針は、割引なしグループの価格を引き上げたものを除いて、最も高い収益を得ています。これは、現在のベースライン価格が低いことを意味しますが、ユーザーをセグメント化する方法は、収益を増加させるのに役立ちます。
結論
このノートブックでは、EconMLを用いることで、以下のようなことが可能であることを示しました。
- モデルの仕様が間違っていても処置効果を正しく推定する
- 結果として得られる個人レベルの処置効果を解釈する
- 以前の方針とベースラインの方針に勝る方針決定をする
EconMLがあなたのためにできることの詳細については、ウェブサイト、GitHubページ、ドキュメントを参照してください。