はじめに
「プロジェクトAにあるBigQueryのデータをプロジェクトBに週次で同期を取ってほしい」という要望が発生しました。
手作業で毎週行うのはキツいため、自動化できないか検証を行いこのデータ移行アプリを作成しました。
本記事では備忘も兼ねて、対応した内容・ハマったポイントなどを記載します。
事前に知っておけば調査の手間が減る内容もあるため、参考になればと思います。
本記事で主に扱うGCPサービス
- BigQuery
- Google Cloud Storage(GCS)
- Google App Engine(GAE)
本記事ではBigQueryとGCSについてがメインになります。
その他サービスでの対応内容
他のサービスで対応した内容については、以下の記事にまとめています。
異なるプロジェクト間のBigQueryデータ同期アプリ構築時のハマりポイントまとめ 【GAE編】
要件
- プロジェクトAのBigQueryテーブルデータをプロジェクトBに定期的に同期したい
- 対象のテーブル数は30弱
プロジェクトAには外部システムから数分間隔でファイル連携され、毎日大量のデータが新しくBigQueryに取り込まれる仕様でした。
「プロジェクトBでプロジェクトAと同等のデータを扱いたい」という要望がありこのような仕組みが必要になりました。
ただし、プロジェクトAほどリアルタイム性は求められないため、週次での更新としました。
制約
- プロジェクトAとプロジェクトBではVPCが異なるため、直接テーブルのコピー操作はできない
- 新規に専用インスタンスは立てられない
BigQueryにはGCPコンソールの操作でテーブルをコピーする機能があるのですが、VPCが異なる場合はエラーとなりました。
おそらくアクセス権限周りの制御により発生するエラーだと思います。
また、案件都合で専用のGCEインスタンスの作成にはNGが出たため、今回は新規GCEインスタンスを作らずに実現する必要がありました。
これらの問題を突破しつつ、テーブルデータを移行しなければいけませんでした。
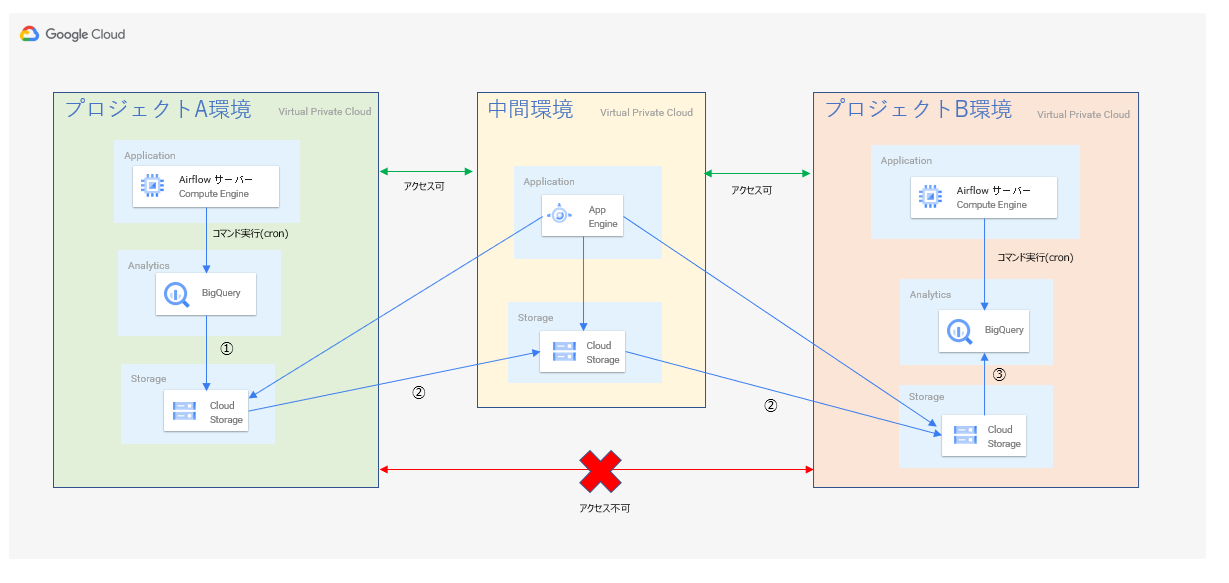
できあがった構成
プロジェクトAとB両方にアクセスできる中間環境を用意して、最終的には下記のような構成と処理になりました。
- 処理内容
- プロジェクトAのAirflowサーバー内シェルでbq extractコマンドを実行(cron実行)
- 中間環境のGAEでファイル移動処理を実行(GAEのcron実行)
- プロジェクトBのAirflowサーバー内シェルでbq load処理を実行(cron実行)
BigQueryでの対応内容・注意点
bqコマンドでのインポート・エクスポート操作
BigQueryはテーブルの内容をjsonファイル等にエクスポート(bq extract)、逆にファイルからインポート(bq load)する処理がコマンドで実行できます。
以下のコマンドはgzip形式でテーブルデータのエクスポートとインポートを実行するコマンドです。
bq extract --compression GZIP --destination_format NEWLINE_DELIMITED_JSON sample_dataset_a.sample_table gs://sample-backet-a/sample_table_*.gz
bq load --replace --source_format NEWLINE_DELIMITED_JSON --encoding=UTF-8 sample_dataset_a.sample_table gs://sample-backet-a/sample_table_*.gz
bq load では --replace オプションを付与し、テーブルの中身を洗い替えするようにしています。
指定したテーブルが数億のレコードを持っていても、コマンド実行は5分以内には完了しました。
これと同等の動きをするGAE向けの書き方がありますが、課題にぶつかったため採用できませんでした。
パーティション設定が有効なテーブルのbq extract結果
bq extract で出力されるファイル数と1ファイルごとのサイズには毎回差異がありました。
今回対象としたテーブルはパーティーション設定が有効だったため、パーティーション単位で区切られ出力されるようです。
コマンド実行をshell化
プロジェクトAとBにはそれぞれにAirflow(バッチ処理管理ツール)用のGCEインスタンスが存在したため、
エクスポートとインポートはそこにbqコマンドを実行するシェルを作成し配置することにしました。
(Airflowについてもいろいろ苦労させられたため、そちらについては別途記事にしたいと思います。。。)
GCSでの対応内容・注意点
GCSの利用用途
BigQueryデータのエクスポート先と、環境間のファイル移動の保存先としてGCSを利用しました。
また対象テーブルは後で追加されることが想定できたため、テーブルの一覧をjson形式の定義ファイルとしてGCSに配置し、GAEアプリが参照する構成としました。
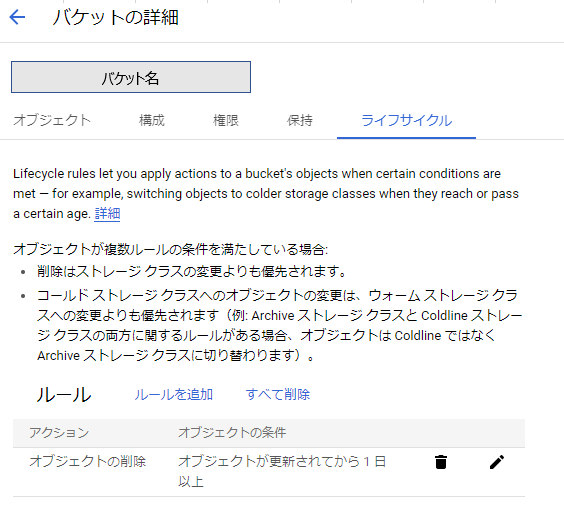
ライフサイクルポリシーの設定
bq extractが実行毎に結果ファイル件数が異なる関係で前回実行時のファイルが残っていると邪魔なので、今回はGCSバケットのライフサイクルポリシーを「1日経過でファイルを削除」するように設定し、次回処理起動時にはバケット内が空になるようにしました。
最後に
bq extractの結果ファイル数が毎回違っていたのは想定外でした。
ライフサイクルポリシーの設定ができたお陰で、かなり運用の手間が省けたのは良かったです。
GCPについては日本語の記事が少ないなと感じるので、この記事が少しでもGCPについて困っている方の役にたてば幸いです。