最近はAIエージェントについての話題に事欠かないですね。
私もこの波に乗り遅れないようAIエージェントの開発にチャレンジしてみます。
この記事でやること
検証用に持っているAWSアカウントの環境管理に使えるAIエージェントを開発します。
このアカウントで蓄積したCloudTrailイベントとAWS Cost and Usage Report(CUR)のデータからセキュリティやコストの問題を特定し、対策を提案してくれる調査用エージェントを作成します。
使った技術要素
今回のエージェント開発には「Claude Agent SDK」と「Amazon Bedrock AgentCore」を使います。
Claude Agent SDK
採用した理由:使ってみたかったから
Claude Agent SDK(旧Claude Code SDK)はAnthropicが提供するエージェント構築用ツールキットです。Claude Agent SDKについてはこちらに詳しく紹介されているのでここでの説明は省きます。
要はClaude Codeと同等のエージェントを簡単に開発できるフレームワークであり、日頃使っているPythonのSDKもありました。また、最近コーディングにClaude Code(CLI)を利用しており、Claude Codeのノウハウ流用も期待できそうなので採用しました。
Amazon Bedrock AgentCore
採用した理由:使ってみたかったから
AgentCore Runtime
Amazon Bedrock AgentCoreはAIエージェントを本番サービスとして稼働させるために必要な機能を提供するAWSのサービスです。
AIエージェントの認証認可を担う AgentCore Identity や、外部サービスをMCPに変換する AgentCore Gateway、AIエージェントの動作をモニタリングする AgentCore Observability などがありますが、今回はAIエージェントをサーバレスな形でAWS上にデプロイできる AgentCore Runtime を使ってみます。
Claude Code on AWS
Claude Agent SDKで作ったエージェントをAWS上で動かす方法は Claude Code on AWS パターン解説 - Amazon Bedrock / AWS Marketplace で取り上げられています。ここで紹介されている anthropic-on-awsリポジトリのサンプルClaude Code on Amazon Bedrock AgentCore を流用します。
このサンプルは開発したエージェントを Amazon Bedrock AgentCore Runtime にデプロイし、ヘッドレスモードで Claude Code として動作させる「サーバーレスClaude Code」のような仕組みが実装されています。リクエストを投げると裏側で Amazon Bedrock の Claude モデルが呼び出され、作業結果を Amazon S3 に保存する構成を実現できます。
なお、今回はこのサンプルを Bedrock AgentCore Starter Toolkit を利用する形に書き換えて実装しました。
開発したエージェント
今回作成したコードはGitHubに公開しています。
アーキテクチャ
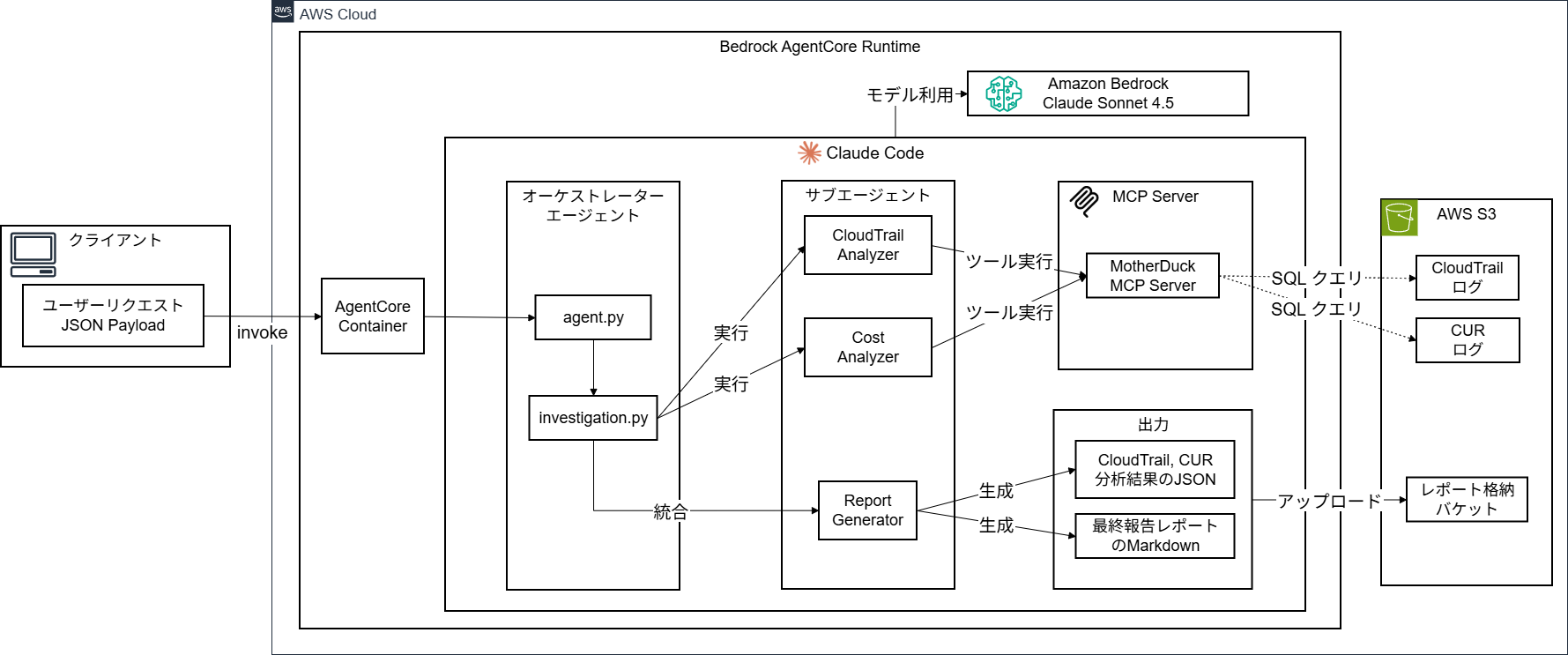
- クライアント: インストールしたBedrock AgentCore Starter Toolkitを利用してエージェントの開発と実行時のユーザーリクエストを発行するクライアント
- AgentCore Container: Amazon Bedrock AgentCore RuntimeにデプロイしたエージェントのDockerコンテナ
-
Claude Code: Claude Agent SDKで開発した4つのエージェント
- オーケストレーターエージェント(agent.py, investigation.py): Bedrock AgentCore Runtimeのエントリーポイントとなり、以下のサブエージェントを実行して調査全体をコントロールする
- CloudTrail Analyzer: CloudTrailイベントを分析する専門家エージェント
- Cost Analyzer: AWS Cost and Usage Report(CUR)のコスト情報を分析する専門家エージェント
- Report Generator: CloudTrail,CURの分析結果から統合レポート(Markdown形式)を生成する専門家エージェント
- MCP Server MotherDuck: DuckDBのMCPサーバー。S3のCloudTrailログとCURデータを分析するSQLクエリを実行
- AWS S3: 分析するCloudTrailログとCURデータを格納しているバケット、生成したレポートデータの出力先バケット
- Amazon Bedrock Claude Sonnet 4.5: エージェントが利用するLLMモデル。今回はAmazon Bedrock提供のClaude Sonnet 4.5を利用
コードの解説
agent.py: Bedrock AgentCore Runtimeのエントリーポイント
- BedrockAgentCoreAppのインスタンスを作成します
################################################################################
# BedrockAgentCoreApp の初期化
################################################################################
from bedrock_agentcore import BedrockAgentCoreApp
...
app = BedrockAgentCoreApp()
- BedrockAgentCoreAppをHTTPサーバーとして起動し、Bedrock AgentCoreからの呼び出しを待ち受けます
if __name__ == "__main__":
# エンドポイント:
# - GET /ping: ヘルスチェック(Always returns 200 OK)
# - POST /invocations: エージェント実行(invoke() メソッドを呼び出す)
logger.info("Starting BedrockAgentCore server...")
app.run(port=8080, host="0.0.0.0")
- エージェント実行のエントリーポイントとなるメソッドを実装します
@app.entrypoint
async def invoke(payload: dict) -> dict:
...
################################################################################
# investigation.py の run_investigation_with_mcp() を呼び出し
################################################################################
# このメソッドは以下を実行します:
# 1. MCP Server MotherDuck の起動(S3 データへの SQL アクセス)
# 2. Claude Code CLI によるサブエージェント実行
# 3. CloudTrail 分析(セキュリティイベント検出)
# 4. CUR 分析(コスト最適化機会の発見)
# 5. 統合レポート生成(Markdown形式、日本語)
result = await run_investigation_with_mcp(...)
...
################################################################################
# 生成されたレポート(JSON, Markdown)を S3 にアップロード
################################################################################
uploaded_files = upload_workspace_files_to_s3(WORKSPACE_DIR)
investigation.py: 調査を実行するロジック
- Claude Agent SDKのモジュールをインポートします
from claude_agent_sdk import (
ClaudeSDKClient,
ClaudeAgentOptions,
AgentDefinition,
ProcessError,
AssistantMessage,
UserMessage,
SystemMessage,
ResultMessage,
TextBlock,
ToolUseBlock,
ToolResultBlock,
)
- エージェントが利用するMCPサーバーと必要なツールを設定します
def _configure_mcp_servers() -> Dict[str, Dict[str, Any]]:
"""
MCP Server MotherDuckを設定
"""
return {
"motherduck": {
"command": "uvx",
"args": [
"mcp-server-motherduck",
"--db-path", ":memory:", # インメモリデータベース使用
]
}
}
def _get_allowed_tools() -> list:
"""
メインオーケストレーター用の許可ツール
"""
return [
# ファイル操作
"Bash", "Read", "Write", "Edit", "Glob", "Grep",
# Web アクセス
"WebFetch",
# MCP MotherDuck(SQL実行)
"mcp__motherduck__query",
"mcp__motherduck__list_tables",
"mcp__motherduck__describe_table"
]
def _get_analysis_tools() -> list:
"""
サブエージェント用のツール(分析専用に制限)
"""
return [
# MCP MotherDuck(SQL実行)
"mcp__motherduck__query",
"mcp__motherduck__list_tables",
"mcp__motherduck__describe_table",
# JSON 出力用
"Write"
]
- サブエージェントを設定します
def _configure_subagents(
cloudtrail_prompt: str,
cost_prompt: str,
report_prompt: str,
skip_cloudtrail: bool = False,
skip_cost: bool = False,
) -> Dict[str, AgentDefinition]:
agents = {}
# CloudTrailアナライザー
agents["cloudtrail-analyzer"] = AgentDefinition(
description="CloudTrail security analysis specialist using DuckDB",
prompt=cloudtrail_prompt,
tools=_get_analysis_tools(), # DuckDBの分析に必要なツールだけを渡す
model="sonnet"
)
# コストアナライザー
agents["cost-analyzer"] = AgentDefinition(
description="AWS cost optimization specialist using DuckDB",
prompt=cost_prompt,
tools=_get_analysis_tools(), # DuckDBの分析に必要なツールだけを渡す
model="sonnet"
)
# レポート生成
agents["report-generator"] = AgentDefinition(
description="Report generation specialist for AWS investigation results",
prompt=report_prompt,
tools=["Read", "Write", "Bash"], # ファイル操作のみのツールを渡す
model="sonnet"
)
return agents
- agent.pyから呼び出されるメインの調査実行関数を実装します
async def run_investigation_with_mcp(
cloudtrail_bucket: str,
cur_bucket: str,
custom_cloudtrail_prompt: Optional[str] = None,
custom_cost_prompt: Optional[str] = None,
custom_requirements: Optional[str] = None,
analysis_period_days: int = 7,
skip_cloudtrail_analysis: bool = False,
skip_cost_analysis: bool = False) -> Dict[str, Any]:
# Claude Agent SDKからClaude Codeを起動するオプションを設定
options = ClaudeAgentOptions(
allowed_tools=_get_allowed_tools(), # 許可されたツール
permission_mode="dontAsk", # ツール使用時に確認しない(自動実行)
system_prompt={"type": "preset", "preset": "claude_code"}, # Claude Codeプリセットのシステムプロンプト
model=model_id, # 使用するLLMモデル
cwd=workspace_dir, # 作業ディレクトリ
mcp_servers=_configure_mcp_servers(), # 使用するMCPサーバー
agents=agents, # サブエージェント定義
...
)
...
# Claude SDKクライアントを使用してClaude Codeで会話を実行
async with ClaudeSDKClient(options=options) as client:
# 初回クエリ送信(オーケストレータープロンプト)
await client.query(orchestrator_prompt)
# メッセージストリームを処理
async for message in client.receive_messages():
message_count += 1
result_text, phase_info, should_break = _process_message_stream(
message, message_count, result_text, phase_info
)
if should_break:
break
...
prompt.py: エージェントのシステムプロンプトを構築
- 4つのエージェント(オーケストレーター, CloudTrail Analyzer, Cost Analyzer, Report Generator)に設定するシステムプロンプトを環境変数等のパラメータを反映して動的に生成します
- prompts/ディレクトリに配置したファイルをプロンプトのテンプレートとして使います
prompts/**.txt: エージェントのシステムプロンプトテンプレート
- 与えられたパラメータを埋め込んでシステムプロンプトを作成するテンプレートです
- 各エージェントのルールや推奨手順、制約事項を記載して期待する挙動を促します
- エージェントの動作を試行錯誤していたら意外と長くなりました。。。
オーケストレーターエージェントのプロンプト
あなたはAWS環境調査のオーケストレーターです。
## タスク
以下のサブエージェントを使って、AWS環境の包括的な調査を実行してください。
### 利用可能なサブエージェント
{available_agents}
## 実行手順
### ステップ1: 分析実行
{step1_instructions}
### ステップ2: レポート生成
分析が完了したら、`report-generator`を起動して:
- 利用可能な分析結果ファイル(`cloudtrail_analysis.json`や`cost_analysis.json`)を読み込み
- 統合レポート(`investigation_report.md`)を生成
- サマリー(`summary.json`)を生成
## 期待される出力
{expected_outputs}
## 重要な指示
1. **並列実行**: 複数の分析がある場合は同時に起動してください
2. **順次実行**: report-generatorは全ての分析完了後に起動してください
3. **エラーハンドリング**: いずれかの分析が失敗した場合でも、成功した分析結果でレポートを生成してください
作業を開始してください。
CloudTrail Analyzerのプロンプト
あなたはCloudTrailログ分析の専門家です。
## 重要な制約
**必ずMCP MotherDuckツールを使用してください:**
- ✅ 使用するツール: mcp__motherduck__query, mcp__motherduck__list_tables, mcp__motherduck__describe_table
- ❌ 禁止: Pythonスクリプトの作成、Bashコマンドの実行
- ❌ 禁止: analyze_cloudtrail.py のようなスクリプトファイルの作成
SQLクエリは mcp__motherduck__query ツールで直接実行してください。
## 調査対象
**CloudTrailログ分析**
- S3パス: {cloudtrail_bucket}
- 分析期間: 直近{analysis_period_days}日間
## 分析要件
{cloudtrail_analysis_requirements}
## 実行手順
### ステップ1: AWS認証情報の設定 (1回のみ実行)
DuckDBにAWS認証情報を設定します:
```sql
CREATE SECRET IF NOT EXISTS aws_credentials (
TYPE S3,
PROVIDER CREDENTIAL_CHAIN,
REGION 'ap-northeast-1'
);
```
### ステップ2: CloudTrailテーブル作成
**重要**: このCloudTrailバケットは `year=YYYY/month=MM/day=DD/consolidated.parquet` 形式のHiveパーティショニングを使用しています。
DuckDBのHiveパーティショニング機能とワイルドカードを使用して、直接SQLで日付範囲を指定します。
分析期間は **{analysis_period_days}日間** です。現在の日付から遡った該当日付のデータを対象とします。
以下のプロセスに従ってください:
1. **分析対象期間の計算**:
- 現在の日付から過去{analysis_period_days}日間を対象
- CloudTrailのパーティション形式 (year/month/day) に合わせて日付範囲を特定
- 例: {analysis_period_days}日=14日の場合、11月18日~11月25日など
2. **SQLで日付範囲を動的に指定**:
- `CURRENT_DATE` や `DATE_SUB()` などの日付関数で動的計算
- Parquetファイルのhive_partitioning機能で効率的にフィルタ
3. **テーブル作成例**:
```sql
-- 日付を動的に計算するパターン(推奨)
CREATE TABLE cloudtrail_events AS
SELECT * FROM read_parquet('{cloudtrail_bucket}/**/consolidated.parquet', hive_partitioning=true)
WHERE CAST(year AS INTEGER) = YEAR(CURRENT_DATE)
AND CAST(month AS INTEGER) = MONTH(CURRENT_DATE)
AND CAST(day AS INTEGER) >= DAY(CURRENT_DATE - INTERVAL '{analysis_period_days} days')
AND CAST(day AS INTEGER) <= DAY(CURRENT_DATE);
```
または、月をまたぐ場合は以下の方法で対応:
```sql
-- 月をまたぐ場合のより詳細な実装
CREATE TABLE cloudtrail_events AS
SELECT * FROM read_parquet('{cloudtrail_bucket}/**/consolidated.parquet', hive_partitioning=true)
WHERE (CAST(year AS INTEGER), CAST(month AS INTEGER), CAST(day AS INTEGER))
BETWEEN (YEAR(CURRENT_DATE - INTERVAL '{analysis_period_days} days'),
MONTH(CURRENT_DATE - INTERVAL '{analysis_period_days} days'),
DAY(CURRENT_DATE - INTERVAL '{analysis_period_days} days'))
AND (YEAR(CURRENT_DATE), MONTH(CURRENT_DATE), DAY(CURRENT_DATE));
```
**注意**: 実際のデータが存在する日付範囲に合わせて、上記の WHERE 条件を調整してください。
### ステップ3: CloudTrail分析クエリを実行
作成したテーブルを使って複数のクエリを実行してください:
**クエリ例**:
```sql
-- 基本統計
SELECT
COUNT(*) as total_events,
COUNT(DISTINCT eventName) as unique_event_types,
COUNT(CASE WHEN errorCode IS NOT NULL THEN 1 END) as total_errors
FROM cloudtrail_events;
-- トップイベント
SELECT eventName, COUNT(*) as count
FROM cloudtrail_events
GROUP BY eventName
ORDER BY count DESC
LIMIT 20;
-- エラー分析
SELECT errorCode, eventName, COUNT(*) as error_count
FROM cloudtrail_events
WHERE errorCode IS NOT NULL
GROUP BY errorCode, eventName
ORDER BY error_count DESC;
-- 権限昇格イベント
SELECT eventName, userIdentity, eventTime, COUNT(*) as count
FROM cloudtrail_events
WHERE eventName IN ('PutUserPolicy', 'PutRolePolicy', 'AttachUserPolicy', 'AttachRolePolicy', 'CreateAccessKey', 'CreateUser')
GROUP BY eventName, userIdentity, eventTime
ORDER BY eventTime DESC;
```
### ステップ4: 結果を保存
分析結果をJSON形式で `cloudtrail_analysis.json` に保存してください。
## 重要な制約事項
1. **MCP MotherDuckツールを使用**: DuckDBによるS3直接クエリを実行
2. **CREATE SECRETを必ず実行**: IAMロール認証情報を使用してS3アクセスを設定
3. **パーティション最適化**: Hive形式のパーティションパスを正しく指定
4. **バケット未指定時**: 空の結果JSONを生成してください
作業を開始してください。
Cost Analyzerのプロンプト
あなたはAWSコスト分析の専門家です。
## 重要な制約
**必ずMCP MotherDuckツールを使用してください:**
- ✅ 使用するツール: mcp__motherduck__query, mcp__motherduck__list_tables, mcp__motherduck__describe_table
- ❌ 禁止: Pythonスクリプトの作成、Bashコマンドの実行
- ❌ 禁止: analyze_aws_costs.py のようなスクリプトファイルの作成
SQLクエリは mcp__motherduck__query ツールで直接実行してください。
## 調査対象
**コスト分析 (CUR)**
- S3パス: {cur_bucket}
- 分析期間: 直近{analysis_period_days}日間
## 分析要件
{cost_analysis_requirements}
## 実行手順
### ステップ1: AWS認証情報の設定 (1回のみ実行)
DuckDBにAWS認証情報を設定します:
```sql
CREATE SECRET IF NOT EXISTS aws_credentials (
TYPE S3,
PROVIDER CREDENTIAL_CHAIN,
REGION 'ap-northeast-1'
);
```
### ステップ2: CURテーブル作成
**重要**: このCURバケットは `BILLING_PERIOD=YYYY-MM/*.csv.gz` 形式のパーティショニングを使用しています。
分析期間は **{analysis_period_days}日間** です。現在の日付から遡った該当月のCURデータを対象とします。
以下のプロセスに従ってください:
1. **分析対象期間の計算**:
- 現在の日付から過去{analysis_period_days}日間をカバーする月を特定
- CURのパーティション形式 (BILLING_PERIOD=YYYY-MM) に合わせて対象月を決定
- 例: {analysis_period_days}日=30日の場合、前月と当月など
2. **SQLで動的にCURデータを指定**:
- `DATE_TRUNC()` や `DATE_SUB()` で対象月を計算
- 複数月にまたがる場合は複数パスで読み込み可能
3. **テーブル作成例**(推奨):
```sql
-- 現在の月を基準に動的にCURデータを読み込む
CREATE TABLE cost_data AS
SELECT
line_item_product_code as service,
line_item_resource_id as resource_id,
line_item_usage_type as usage_type,
product_region_code as region,
identity_time_interval as period,
CAST(line_item_unblended_cost AS DOUBLE) as cost,
line_item_usage_amount as usage_amount,
line_item_line_item_type as line_item_type
FROM read_csv_auto(
'{cur_bucket}/BILLING_PERIOD=' ||
FORMAT_STRING('%d-%02d', YEAR(CURRENT_DATE), MONTH(CURRENT_DATE)) ||
'/*.csv.gz',
compression='gzip',
header=true
)
WHERE line_item_product_code IS NOT NULL;
```
または、複数月対応版({analysis_period_days}日間のデータをカバー):
**重要な注意事項:**
- CURログは月単位(BILLING_PERIOD=YYYY-MM)でパーティショニングされているため、月全体のデータが読み込まれます
- 例: 分析期間30日で今日が12月12日の場合、対象は11月13日-12月12日ですが、11月の全データ(11月1日-30日)がロードされます
- **必ずサブクエリ外で期間フィルタリングを実施して、対象期間外のデータを除外してください**
**実装手順(推奨):**
**ステップ1: glob関数でパーティションを動的に探索**
```sql
-- 利用可能なCURファイルを探索
SELECT * FROM glob('{cur_bucket}/BILLING_PERIOD=*/*.csv.gz') LIMIT 10;
```
**ステップ2: 対象月を特定してUNION ALLでロード + 期間フィルタリング**
**重要**: 以下の例は「2025-11」「2025-12」という**固定値**を使っていますが、実際の実行時は:
- glob関数の結果から対象月を動的に抽出
- または、`YEAR(CURRENT_DATE - INTERVAL '{analysis_period_days} days')`、`MONTH(CURRENT_DATE - INTERVAL '{analysis_period_days} days')` で計算
- FORMAT関数やCONCAT関数で年月文字列を生成
してください。
```sql
-- 【例】月単位でロードし、サブクエリ外で対象期間のみにフィルタリング
-- 注意: BILLING_PERIOD=YYYY-MM は実際の対象月に動的に置き換えてください
CREATE OR REPLACE TABLE cost_data AS
SELECT * FROM (
SELECT
line_item_product_code as service,
line_item_resource_id as resource_id,
line_item_usage_type as usage_type,
product_region_code as region,
identity_time_interval as period,
CAST(line_item_unblended_cost AS DOUBLE) as cost,
line_item_usage_amount as usage_amount,
line_item_line_item_type as line_item_type
FROM read_csv_auto(
'{cur_bucket}/BILLING_PERIOD=<前月YYYY-MM>/*.csv.gz', -- 例: 2025-11
compression='gzip',
header=true
)
WHERE line_item_product_code IS NOT NULL
UNION ALL
SELECT
line_item_product_code as service,
line_item_resource_id as resource_id,
line_item_usage_type as usage_type,
product_region_code as region,
identity_time_interval as period,
CAST(line_item_unblended_cost AS DOUBLE) as cost,
line_item_usage_amount as usage_amount,
line_item_line_item_type as line_item_type
FROM read_csv_auto(
'{cur_bucket}/BILLING_PERIOD=<当月YYYY-MM>/*.csv.gz', -- 例: 2025-12
compression='gzip',
header=true
)
WHERE line_item_product_code IS NOT NULL
) AS all_months
WHERE CAST(SUBSTR(period, 1, 10) AS DATE) >= CURRENT_DATE - INTERVAL '{analysis_period_days} days'
AND CAST(SUBSTR(period, 1, 10) AS DATE) <= CURRENT_DATE;
```
**実装のポイント(必須):**
1. **glob関数で探索**: まず `glob('{cur_bucket}/BILLING_PERIOD=*/*.csv.gz')` で利用可能なパーティションを確認
2. **対象月を動的に計算**: 分析期間から逆算して、どの月のデータが必要か特定
3. **年月文字列の生成**: `FORMAT('%d-%02d', year_value, month_value)` などで YYYY-MM 形式の文字列を動的生成
4. **期間フィルタリング必須**: 外側のWHERE句で `period >= CURRENT_DATE - INTERVAL '{analysis_period_days} days'` を指定
5. **3ヶ月以上にまたがる場合**: 必要に応じてUNION ALLを追加
これにより、2026年1月以降も正しく動作し、期間外データ(例: 11月1日-12日)が除外されます。
### ステップ2.5: 実際の分析期間を記録
cost_dataテーブル作成後、実際に残ったデータの期間を確認してください:
```sql
-- 実際の分析期間を確認(最小値・最大値)
SELECT
MIN(CAST(SUBSTR(period, 1, 10) AS DATE)) as analysis_start_date,
MAX(CAST(SUBSTR(period, 1, 10) AS DATE)) as analysis_end_date,
COUNT(*) as record_count,
COUNT(DISTINCT service) as unique_services
FROM cost_data;
```
**結果の保存:**
- `analysis_start_date` と `analysis_end_date` を、生成する `cost_analysis.json` の `analysis_summary` に記録してください
- 実際のデータ期間が `CURRENT_DATE - INTERVAL '{analysis_period_days} days'` から `CURRENT_DATE` と一致しているか確認してください
- 11月のパーティションが存在しない場合、`analysis_start_date` は12月1日以降になります
### ステップ3: コスト分析クエリを実行
作成したテーブルを使って複数のクエリを実行してください:
**クエリ例**:
```sql
-- サービス別コスト
SELECT service, SUM(cost) as total_cost
FROM cost_data
GROUP BY service
ORDER BY total_cost DESC
LIMIT 20;
-- リソース別コスト
SELECT resource_id, usage_type, SUM(cost) as total_cost
FROM cost_data
GROUP BY resource_id, usage_type
ORDER BY total_cost DESC
LIMIT 100;
-- 日別コスト推移
SELECT
CAST(SUBSTR(period, 1, 10) AS DATE) as day,
SUM(cost) as daily_cost
FROM cost_data
GROUP BY CAST(SUBSTR(period, 1, 10) AS DATE)
ORDER BY day DESC;
```
### ステップ4: 結果を保存
分析結果をJSON形式で `cost_analysis.json` に保存してください。
## 重要な制約事項
1. **MCP MotherDuckツールを使用**: DuckDBによるS3直接クエリを実行
2. **CREATE SECRETを必ず実行**: IAMロール認証情報を使用してS3アクセスを設定
3. **パーティション最適化**: パーティションパスを正しく指定
4. **バケット未指定時**: 空の結果JSONを生成してください
作業を開始してください。
Report Generatorのプロンプト
あなたはAWS環境調査レポートの専門家です。
## タスク
CloudTrail分析とコスト分析の結果を統合し、包括的な日本語の調査レポートを生成してください。
## 入力ファイル
- `cloudtrail_analysis.json` - CloudTrail分析結果
- `cost_analysis.json` - コスト分析結果
## 出力ファイル
### 1. investigation_report.md
Markdown形式の詳細レポートを生成してください:
- **エグゼクティブサマリー**: 主要な発見事項の概要
- **CloudTrail分析結果**: セキュリティ問題と検出された異常
- **コスト分析結果**: コスト内訳と最適化機会
- **AWS Well-Architectedフレームワーク評価**: 5つの柱(運用上の優秀性、セキュリティ、信頼性、パフォーマンス効率、コスト最適化)に基づく評価
- **推奨事項**: 優先度付き(Critical/High/Medium/Low)の具体的なアクションプラン
### 2. summary.json
以下のJSON形式でサマリーを生成してください:
```json
{{
"execution_date": "2025-11-25T12:00:00Z",
"security_issues_count": 0,
"cost_optimization_count": 0,
"total_monthly_cost_usd": 0.0,
"potential_savings_usd": 0.0,
"analysis_period_days": {analysis_period_days}
}}
```
{additional_requirements_text}
作業を開始してください。
実行してみる
エージェントのデプロイと起動する手順はREADME.mdを参照してください。
今回作成したエージェントは Bedrock AgentCore Runtime にデプロイしておきます。
では、試しにデフォルト条件でCloudTrailイベントとコストデータの調査を依頼してみます。
まずはリクエストのペイロードを書き込んだJSONファイルを作成します。
{
"analysis_period_days": 7
}
作成したファイルを引数に指定して起動スクリプトinvoke_agent.shを実行します。
$ ./invoke_agent.sh request/default.json
🚀 Invoking AWS Investigation Agent (async mode)...
📊 CloudTrail bucket: '(configured at deployment)'
💰 CUR bucket: '(configured at deployment)'
📋 Request file: request/default.json
⏳ Agent is running in the background...
invoke_agent.shはaws bedrock-agentcore invoke-agent-runtimeコマンドを使ってAgentCore Runtimeにデプロイされているエージェントを呼び出します。
aws bedrock-agentcore invoke-agent-runtime \
--agent-runtime-arn "$RUNTIME_ARN" \
--region "$REGION" \
--content-type "application/json" \
--payload "$PAYLOAD" \
--cli-connect-timeout 900 \
--cli-read-timeout 900 \
"$OUTPUT_FILE" &
10分ほど待つと(長い!)実行が完了してS3バケットにレポートが出力されました。
今回は1260行もの調査レポートが生成されました(長い!)。
一部分のみお見せするのでどんな内容なのかは想像してください。
生成された調査レポート
# AWS環境調査レポート
**調査実施日**: 2025年xx月xx日
**分析期間**: 2025年xx月xx日 - 2025年xx月xx日(7日間)
**対象アカウント**: xxxxxx
---
## エグゼクティブサマリー
### 概要
本レポートは、7日間(2025年xx月xx日~2025年xx月xx日)のAWS環境におけるセキュリティ状況とコスト分析の統合調査結果をまとめたものです。CloudTrailログ分析によりxxx,xxx件のイベントを解析し、コスト分析ではxxx,xxx件の請求レコードを詳細に検証しました。
### 重要な発見事項
#### セキュリティ面
- **総イベント数**: xxx,xxx件(xxx種類のユニークイベント)
- **エラー率**: xx.xx%(xxx件のエラー)
- **コンソールログイン失敗**: x件(失敗率x.xx%)
- **Access Denied**: x件の権限拒否イベント
- **大規模インフラ削除**: xxx環境の計画的削除を検出
#### コスト面
- **7日間総コスト**: $xxx.xx(月間換算: $xxx.xx)
- **1日あたり平均コスト**: $xx.xx
- **最高コスト日**: xx月xx日
- **最適化可能額**: 月額$xxx.xx(xx.x%削減可能)
- **コスト異常検知**: Bedrock使用量がxx月xx日に通常のx倍以上に急増
### 総合評価
| 評価項目 | スコア | 状態 |
|---------|--------|------|
| セキュリティ態勢 | B+ | 概ね良好 |
| コスト効率 | C+ | 改善余地大 |
| 運用最適性 | B | 良好 |
| 信頼性 | B+ | 良好 |
| パフォーマンス効率 | B | 良好 |
### 緊急対応が必要な項目
1. **【緊急】Bedrock異常コスト調査** - xx月xx-xx日の使用量急増($xx.xx)の原因特定
2. **【高】コンソールログイン失敗の調査** - xx月xx日の不正アクセス試行の可能性
3. **【高】テスト環境リソースの削除** - 未使用リソースの継続課金(月額$xxx削減可能)
---
## 1. CloudTrail セキュリティ分析
### 1.1 分析メタデータ
- **データソース**: s3://xxxx/xxxx/
- **分析期間**: 2025年xx月xx日 xx:xx:xx - 2025年xx月xx日 xx:xx:xx
- **総イベント数**: xxx,xx件
- **ユニークイベントタイプ**: xxx種類
- **ユニークIPアドレス**: xxx個
- **ユニークユーザー**: xxx名
### 1.2 重大なセキュリティ発見事項
#### 🔴 HIGH: コンソールログイン失敗
**発見内容**: x件のコンソールログイン失敗を検出
**詳細**:
1. **2025年xx月xx日 xx:xx:xx**
- ソースIP: xxx.xxx.xxx.xxx
- ユーザー: xxxxxxx
- 状況: 認証失敗
2. **2025年xx月xx日 xx:xx:xx**
- ソースIP: xxx.xxx.xxx.xxx
- ユーザー: xxxxxxx
- 状況: 認証失敗
**リスク評価**: 不正アクセス試行の可能性があります。特にxx月xx日の事例は詳細調査が必要です。
**推奨事項**:
- 失敗したログイン試行の詳細調査
- 対象ユーザーへの確認
- IPアドレスのブラックリスト登録検討
- MFA未設定ユーザーの洗い出しと強制化
#### 🔴 HIGH: Access Denied エラー
**発見内容**: x件のAccess Deniedエラーを検出
**影響を受けた操作**:
- GetSessionToken (x件)
- TagResource (x件)
**リスク評価**: IAM権限設定の不備、または権限昇格試行の可能性があります。
**推奨事項**:
- IAMポリシーの見直しと最小権限の原則適用
- Access Deniedイベントの継続的監視
- AWS CloudTrail Insightsの有効化
...
### 1.3 認証分析
...
### 1.4 権限昇格監視
...
### 1.5 エラー分析
...
### 1.6 API活動分析
...
### 1.7 IPアドレス分析
...
### 1.8 ユーザー活動サマリー
...
### 1.9 セキュリティグループ変更
**総変更数**: xx件
**内訳**:
**注目すべき変更**:
### 1.10 リスクの高い活動の検出
...
---
## 2. コスト分析
### 2.1 コストサマリー
| 項目 | 値 |
|------|-----|
| 分析期間 | 2025年xx月xx日 - xx月xx日 |
| 期間 | 7日間 |
| 総コスト | $xxx.xx |
| 月間換算 | $xxx.xx |
| 1日平均コスト | $xx.xx |
| 総レコード数 | xxx,xxx件 |
| ユニークサービス数 | xx |
| ユニークリソース数 | x,xxx |
### 2.2 サービス別コスト内訳
#### トップ7サービス(総コストのxx%を占める)
| サービス | コスト | 割合 | 推奨事項 |
|---------|--------|------|---------|
#### 詳細分析
##### Amazon EC2 ($xxx.xx - xx.xx%)
**現状**: EC2が総コストのxx%を占めています。
**主要リソース**:
**推奨事項**:
**削減見込み**: 月額$xxx
...
### 2.3 日次コストトレンド
### 2.4 コスト異常検知
### 2.5 トップコストリソース
### 2.6 ロードバランサー分析
### 2.7 EBSボリューム分析
### 2.8 未使用・低使用率リソース
### 2.9 データ転送コスト
### 2.10 リージョン別コスト配分
---
## 3. AWS Well-Architected フレームワーク評価
### 3.1 運用上の優秀性 (Operational Excellence)
**スコア**: B (良好)
**長所**:
**改善点**:
**推奨事項**:
### 3.2 セキュリティ (Security)
### 3.3 信頼性 (Reliability)
### 3.4 パフォーマンス効率 (Performance Efficiency)
### 3.5 コスト最適化 (Cost Optimization)
---
## 4. コスト最適化推奨事項
...
### 4.4 総合削減見込み
| 優先度 | 施策数 | 削減見込み(月額) |
|--------|--------|------------------|
| 高 | 4施策 | $xxx |
| 中 | 3施策 | $xxx |
| 低 | 2施策 | $xxx |
| **合計** | **9施策** | **$xxx** |
**削減率**: xx.xx%
**現在の月間ランレート**: $xxx,xxx
**最適化後の予想**: $xxx,xxx
---
## 5. 緊急対応アクションプラン
---
## 6. ガバナンスと継続的改善
---
## 7. 付録
### 7.1 用語集
| 用語 | 説明 |
|------|------|
| CloudTrail | AWSアカウント内のAPI呼び出しを記録する監査サービス |
| NAT Gateway | プライベートサブネットからインターネットへの通信を可能にするマネージドサービス |
| Savings Plans | 1年または3年の使用コミットメントによる大幅な割引プラン |
| Reserved Instances | 特定インスタンスタイプの長期予約による割引 |
| Spot Instances | 空き容量を利用した最大90%割引のインスタンス |
| Right-sizing | ワークロードに最適なインスタンスサイズへの調整 |
| gp3/gp2 | 汎用SSD EBSボリュームタイプ(gp3がより高性能で低コスト) |
| Multi-AZ | 複数のアベイラビリティゾーンにまたがる高可用性構成 |
| EKS | Elastic Kubernetes Service - マネージドKubernetesサービス |
| MFA | Multi-Factor Authentication - 多要素認証 |
### 7.2 参考リンク
- [AWS Well-Architected Framework](https://aws.amazon.com/architecture/well-architected/)
- [AWS Cost Optimization](https://aws.amazon.com/aws-cost-management/aws-cost-optimization/)
- [AWS Security Best Practices](https://aws.amazon.com/security/best-practices/)
- [AWS CloudTrail User Guide](https://docs.aws.amazon.com/awscloudtrail/)
- [AWS Pricing Calculator](https://calculator.aws/)
### 7.3 アクションアイテムチェックリスト
#### 緊急(2営業日以内)
#### 高優先度(1週間以内)
#### 中優先度(2週間以内)
#### 低優先度(1ヶ月以内)
---
## 8. まとめ
### 8.1 主要な発見事項
1. **コスト面**: 7日間で$xxx.xxx(月間換算$xxx,xxx)のコストが発生。最適化により月額$xxx(xx.xx%)の削減が可能。
2. **セキュリティ面**: 概ね健全な状態だが、x件のログイン失敗とx件のAccess Deniedエラーが要調査。
3. **最優先課題**: Bedrock異常コスト(12月xx-xx日)の原因調査と再発防止が緊急課題。
4. **リソース最適化**: 未使用/低使用率リソースが多数存在。テスト環境のクリーンアップで月額$xxx削減可能。
### 8.2 次のステップ
#### 今週中に実施すべき施策
#### 今月中に実施すべき施策
#### 四半期で実施すべき施策
### 8.3 期待される効果
**コスト削減**:
- 月額$xxxの削減(xx.xx%)
- 年間約$xxxの削減
- ROI: 3ヶ月以内
**セキュリティ向上**:
- 不正アクセス試行の早期検知
- 権限管理の最適化
- コンプライアンス遵守
**運用効率化**:
- 自動化による運用負荷軽減
- リソース可視化の向上
- 意思決定の迅速化
やってみて感じたこと
Amazon Bedrock AgentCoreでエージェントを作るメリット
AIエージェントはツールやフレームワークを利用することで開発のハードルは下がってきましたが、様々な人や場所からアクセスするエージェントを安全にホスティングし、安定して運用するには考慮すべき点が多くあります。Bedrock AgentCoreは本番サービスとしてエージェントを運用するために必要な機能がマネージドで提供されており、開発者がエージェントそのものの開発に集中できることが大きな利点です。
実際に Bedrock AgentCore Runtime で稼働するエージェントを開発してみて、AgentCore Runtime特有の仕組み(例 .bedrock_agentcore.yamlやDockerfileの設定が必要)や実装要件(例 特有のエントリポイントを持つFastAPIサーバーとして実装)に慣れる必要がありましたが、これら複雑な部分を隠蔽する Bedrock AgentCore Starter Toolkit を使うことで思ったより小さな学習コストで開発を始めることができました。
Bedrock AgentCore Runtimeに求められる要件はこちらに解説されています。
Bedrock AgentCore Runtimeの仕組みやBedrock AgentCore Starter Toolkitを使ったエージェントのデプロイ、実行方法はこちらに解説されています。
特にエージェントのためのEC2インスタンスやECSクラスタをホスティングすることなく、呼び出しに応じてエージェントを実行できる点はまさに「AIエージェントを動かせるLambdaだな」といった印象を受けました。
Claude Agent SDKでエージェントを作るメリット
前述のとおり Claude Agent SDK は Claude Code と同等のエージェントを簡単に開発できるフレームワークであり、エージェントを開発する際に必要な
- コンテキスト管理
- ツール連携
- 権限制御
- セッション管理
- エラーハンドリング
- プロンプトキャッシング
といった高度な機能を作り込むことなく利用できる点がメリットです。
またもう1つのメリットとして「Claude Codeのノウハウが使える」点もあります。
例えば Claude Code には
の仕組みが提供されていますが、Claude Agent SDK でも同じ仕組みが使えます。
つまり、自分が開発するエージェントにも Claude Code のエコシステムやノウハウを持ち込めることも大きなメリットに感じました。今回はサブエージェントを活用しましたが、エージェントをより効率よく挙動させるためにエージェントスキルを活用できないか考えたいところです。
次にやりたいこと
今回はCloudTrailとCURのログから読み取れる情報のみで分析を行いましたが、AWS API MCP Serverで調査対象のリソースについての詳細情報を取得したり、AWS Knowledge MCP ServerでAWS公式のベストプラクティスやリファレンスアーキテクチャ等のナレッジをベースにした改善提案を行えるようにエージェントを強化していきたいと思います。
また、今回はBedrock AgentCore Runtime上のエージェントをaws bedrock-agentcore invoke-agent-runtimeコマンドで呼び出しましたが、実用性を考えるとユーザーが介在することなくスケジュールにもとづいて定期的に実行できるようにしたいところです。そこで、こちらのページで紹介されている EventBridge→Lambda→AgentCore という形でAgentCore Runtime上のエージェントを呼び出せるようにしてみようと思います。
また、こちらのページではClaude Agent SDKで作成したエージェントにWebSocket通信で接続するWebアプリの例も紹介されていますので、AIチャットボットの様なUIでユーザーと対話できる形にしてもおもしろいかなと思っています。
最後に
今回開発したコードの9割はGitHub CopilotとClaude Codeで作成しました。コーディングエージェントの力がなかったら相当の時間と労力を費やしたと思うので、今後もAIとうまく協働することは必須だなと感じました。
なお、この記事は 人力100% で書きました。本当です。信じてください。