こんにちは!画像認識において、モデルがどこに注目したのかを可視化することは正しくそのモデルを解釈するために大切です。今回はその判断根拠の可視化手法について4つ取り上げて説明します。
使うデータセット
- HAM10000(出典:HARVARD DATABASE)
- 内容:皮膚がんのダーモスコピー画像
- タスク:7クラスのマルチクラス分類
準備
- 可視化にあたっては、推論のみ行います
- まずは、推論結果から正解と不正解をそれぞれ抽出していきます
変換を定義
from timm.data import create_transform
val_transform = create_transform(
input_size=224,
is_training=False # 検証時はデータ拡張なし
)
モデルの定義
- timmからモデルを取得して使います
- 今回は別途pretrain済みの
vit_base_patch16_224で学習 →best_loss_modelを保存し重みをロードします
import timm
def build_model(model_name, pretrained, num_classes):
model = timm.create_model(model_name, pretrained=pretrained, num_classes=num_classes)
return model
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = build_model(model_name="vit_base_patch16_224", pretrained=True, num_classes=7).to(device)
model_save_path = "/works/pathtoweight.pth"
model.load_state_dict(torch.load(model_save_path))
model.to(device)
画像の取得
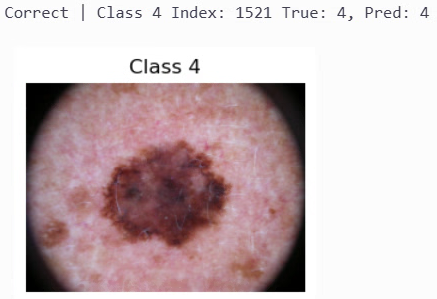
- 各クラスについて、1枚ずつ「正解の画像」と「不正解の画像」を1枚ずつ保存していきます
-
val_idxには推論に使うデータのindex番号が格納されています -
image_idには全画像のファイル名が格納されています
正解画像の取得
correct_samples = dict() # {class_id: (image_path, true_label, pred_label)}
model.eval()
for idx in val_idx:
true_label = dataset.labels[idx]
if true_label in correct_samples:
continue # 正解画像をすでに記録していたらスキップ
# 元画像取得
image_id = [f if f.endswith('.jpg') else f + ".jpg" for f in image_id]
image_full_path = os.path.join(image_path, image_id[idx])
pil_image = Image.open(image_full_path).convert("RGB")
# 前処理→テンソルにして推論
image_tensor = val_transform(pil_image).unsqueeze(0).to(device)
with torch.no_grad():
output = model(image_tensor)
pred_label = torch.argmax(output, dim=1).item()
# 正解していたら辞書に保存
if pred_label == true_label:
# デバッグ出力
print(f"correct [idx {idx}] True: {true_label}, Pred: {pred_label}")
# キーはクラスID(true_label)、値は (画像, 正解ラベル, 予測ラベル)
correct_samples[true_label] = (pil_image, idx, true_label, pred_label)
if len(correct_samples) == 7:
break
不正解画像の取得
wrong_samples = dict()
for idx in val_idx:
true_label = dataset.labels[idx]
if true_label in wrong_samples:
continue # 不正解画像をすでに記録していたらスキップ
# 元画像取得
image_id = [f if f.endswith('.jpg') else f + ".jpg" for f in image_id]
image_full_path = os.path.join(image_path, image_id[idx])
pil_image = Image.open(image_full_path).convert("RGB")
# 前処理→テンソルにして推論
image_tensor = val_transform(pil_image).unsqueeze(0).to(device)
with torch.no_grad():
output = model(image_tensor)
pred_label = torch.argmax(output, dim=1).item()
# 不正解の場合に辞書に保存
if pred_label != true_label:
# デバッグ出力
print(f"wrong [idx {idx}] True: {true_label}, Pred: {pred_label}")
# キーはクラスID(true_label)、値は (画像, 正解ラベル, 予測ラベル)
wrong_samples[true_label] = (pil_image, idx, true_label, pred_label)
if len(wrong_samples) == 7:
break
出力結果は以下となります。

可視化前の前提
Vitについて
- Vitでは、Input Layerを通った後、複数のEncoder Blockを通っていきますが、その中には Self-Attention(自己注意) という機構が用いられています
- このSelf-Attentionによりすべてのパッチ間の関係を学習することができ、それぞれの関係は Attention Weight という行列積で表されます
- このAttention Weightが複数あれば、その個数分だけ各パッチ間の関係を学習できるため、Self-Attentionに複数のAttention Weightを持たせるための仕組みが Multi-Head Self-Attention となります
⇒ Attention mapとはこのAttention Weightをヒートマップで可視化したものになります。
Vitの構造についてはこちらもご参考くださいませ。
Attention weightの取得について
- 例えば、224×224の画像を16×16パッチで分割すると、トークン数は224/16×224/16=14×14=196パッチトークンになり、CLSトークン(画像全体の情報をまとめる役割をパッチトークンの先頭に一つ追加)を加えると 197個 になります
- 今回の一番最後のblockにある
attn_layerの構造をprint(model.blocks[-1])で確認します

⇒ Attention 層の中には、qkvという Linear 層で Query/Key/Value をまとめて作り、softmax した結果は forward 内で一時的に計算した後、attn_drop に通してすぐ捨てていることが分かります。
つまり、forwardの戻り値はvalueに重みづけしてprojectionした出力埋め込みだけであり、attn行列は外から取得できないことになります。
そのため、forwardメソッドの上書き(モンキーパッチ)をして、内部で計算された中間変数を保存することが必要です!
- 補足1
上記は、timmにあるモデルを使った場合の流れで、huggingFaceを使うとforwardの引数でoutput_attentions=Trueを指定すれば、各層のattention mapを得ることができます。
with torch.no_grad():
out = model(**inputs, output_attentions=True)
A_last = out.attentions[-1] # [B,H,L,L]
A_last_mean = A_last.mean(1) # [B,L,L]
cls_row = A_last_mean[0, 0, :] # [L]
- 補足2
torchvisionを使う場合は、timmと同様にパッチにして取り出すことが必要です
可視化① Attention map(層別)
やりたいこと
- 各ブロック内のMulti-Head Self-Attentionで得られる複数ヘッドのAttentionを平均し、CLSトークンが各パッチへどの程度注目しているかをヒートマップにする
実装
- Attention weightを取り出す流れ
-
blocks[-1].attn.forwardを最小限パッチして、softmax後のattnを取得 -
blocks[-1]のCLS行ベクトルを取得する - ベクトルを2Dに整形しヒートマップへ重ねて可視化する
上記を順番に実装していきます。
blocks[-1].attn.forward を最小限パッチして、softmax後の attnを取得
import torch
from types import MethodType
def patch_attention(attn_module):
""" Attentionモジュールのforwardメソッドを書き換え、Attention行列を保存する """
def new_forward(self, x):
B, N, C = x.shape
# [B, N, 3, num_heads, C // num_heads] → [3, B, num_heads, N, C // num_heads]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2,0,3,1,4)
q, k, v = qkv[0], qkv[1], qkv[2] # すべて[B, H, N, D]
# Attention計算
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
self.last_attn = attn # ← これを保存したい!
# Attention出力
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # [B,H,N,D] -> [B,N,H,D] -> [B,N,C]
x = self.proj(x)
x = self.proj_drop(x)
return x
# new_forward はattn_moduleインスタンスにバインドされる→selfはAttentionモジュールのインスタンスになる
attn_module.forward = MethodType(new_forward, attn_module)
blocks[-1] のCLS行ベクトルを取得する
def get_cls_attn_vector(model, x, block_idx, head_fuse):
"""指定したブロックのCLS行ベクトルを取得する"""
model.eval()
attn_layer = model.blocks[block_idx].attn
patch_attention(attn_layer)
with torch.no_grad():
_ = model(x) # forward 1回
A = attn_layer.last_attn # [B,H,L,L] = [1,]
if head_fuse == "mean":
A = A.mean(dim=1) # [B,L,L]
elif head_fuse == "max":
A = A.max(dim=1).values
else:
raise ValueError("head_fuse must be 'mean' or 'max'.")
cls_row = A[0, 0, :] # [L] ← CLS「行」
return cls_row.detach() # [197]
Attention行列は[B,H,L,L](パッチ×ヘッド×トークン数×トークン数)を持っており、トークン数はCLSトークン1つ+パッチ数(14×14=196)です。
また、CLS行とはAttention行列の0行目です。
⇒ CLS行ベクトル(cls_row)とは、CLSがどのパッチにどれぐらい注目しているかが並んだ1次元のベクトルになります。
ベクトルを2Dに整形しヒートマップに重ねて可視化する
import numpy as np, cv2, matplotlib.pyplot as plt
def show_map(img_pil, attn_vec, save_path=None):
"""Attentionマップを表示する"""
W, H = img_pil.size
num_patches = attn_vec.numel() - 1 # 197 → 196(最初の1要素はCLS自身への注意なので捨てる)
p = int(np.sqrt(num_patches)) # 14
cam = attn_vec[1:].reshape(p, p).cpu().numpy()
cam = cv2.resize(cam, (W, H), interpolation=cv2.INTER_NEAREST)
# min-max normalize
mn, mx = cam.min(), cam.max()
cam = (cam - mn) / (mx - mn + 1e-8)
heatmap = cv2.applyColorMap((cam * 255).astype(np.uint8), cv2.COLORMAP_JET)
image_np = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
overlay = cv2.addWeighted(image_np, 0.6, heatmap, 0.4, 0)
plt.figure(figsize=(5,5))
plt.imshow(cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB))
plt.axis("off")
if save_path:
save_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(str(save_path), bbox_inches="tight", pad_inches=0)
plt.show()
plt.close()
上記の関数を最後に呼び出します。
def visualize_samples(samples_dict, model, image_tensor):
for class_id, (img, idx, true_label, pred_label) in samples_dict.items():
attn_vec = get_cls_attn_vector(model, image_tensor, block_idx=-1, head_fuse="mean") # ベクトル
show_map(img, attn_vec, save_path=None)
↓
上記のように可視化するとヒートマップの色が見えづらいため、全層を可視化してみます。可視化する対象として、分かりやすさのためメラノーマを採用します。
なお、今まで冗長に書いていたところはまとめて関数化します。
import numpy as np, cv2, torch, math, matplotlib.pyplot as plt
def minmax(x: np.ndarray, eps=1e-8):
"""Min-Max Normalization"""
mn, mx = float(x.min()), float(x.max())
return (x - mn) / (mx - mn + eps)
def cls_row_from_last_attn(attn_last: torch.Tensor) -> torch.Tensor:
"""
- attn_last: [B,H,L,L] → ヘッド平均 → CLS行ベクトル[L]を返す
"""
A = attn_last.mean(dim=1) # [B,L,L]
cls_row = A[0, 0, :] # [L]
return cls_row.detach()
def cls_row_to_cam(cls_row: torch.Tensor, model) -> np.ndarray:
"""
- CLS行ベクトル[L=197] → パッチ部分を2D(gh,gw)に並べる
"""
# grid_size
gh, gw = model.patch_embed.grid_size
n_patch = gh * gw
L = cls_row.numel()
assert L >= n_patch + 1, f"L={L}, gh*gw+1={n_patch+1}"
patch_part = cls_row[-n_patch:] # 末尾n_patchをパッチとみなす
cam = patch_part.reshape(gh, gw).cpu().numpy()
return minmax(cam)
def visualize_all_blocks(img_pil, model, x_tensor):
"""
各ブロック(Encoder Block)のCLS→パッチ注意ヒートマップを 3x4 に並べて表示する
"""
model.eval()
# 全ブロックのAttentionをパッチ(差し替え)する
for blk in model.blocks:
patch_attention(blk.attn)
# forward を1回だけ回して、全層の attn を確定させる
with torch.no_grad():
_ = model(x_tensor)
# 可視化の準備
n_blocks = len(model.blocks)
rows = math.ceil(n_blocks / 4)
fig, axes = plt.subplots(rows, 4, figsize=(4*4, 3*rows))
axes = np.array(axes).reshape(-1) # flatten
W, H = img_pil.size
base_bgr = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
for b in range(n_blocks):
attn_last = model.blocks[b].attn.last_attn # [B,H,L,L]
assert attn_last.ndim == 4, f"unexpected shape at block {b}: {attn_last.shape}"
cls_row = cls_row_from_last_attn(attn_last) # [L]
cam2d = cls_row_to_cam(cls_row, model) # [gh,gw] (min-max済)
cam_resz = cv2.resize(cam2d, (W, H), interpolation=cv2.INTER_NEAREST)
heat = cv2.applyColorMap((cam_resz * 255).astype(np.uint8), cv2.COLORMAP_JET)
overlay = cv2.addWeighted(base_bgr, 0.6, heat, 0.4, 0)
axes[b].imshow(cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB))
axes[b].set_title(f"Block {b}", fontsize=10)
axes[b].axis("off")
# 余白の空き軸を消す
for k in range(n_blocks, len(axes)):
axes[k].axis("off")
plt.tight_layout()
plt.show()
# save_file = Path("../outputs/attention_map/vit") / \
# f"cls{class_id}_idx{idx}_true{true_label}_pred{pred_label}_allblock.png"
結果はこのようになります。

最初は全体を見ていましたが、後半の層になるにつれてだんだんとパターン化してくることが分かります。
この層ごとに見るというやり方は実務ではあまり行われず、次に説明する Attention Rollout のほうがメジャーだと思います。
可視化② Attention Rollout
やりたいこと
- 各層のAttentionに単位行列を加えて正規化し、それを層ごとに乗算することでCLSトークンからパッチへの「全層を通した関係」を可視化する
実装
- 特定の層のAttention行列を取得するために作成した
patch_attention関数を使って、各層のattention行列を取得する - ヘッドごとの融合
- 単位行列を加算し、行正規化
- 層順に行列積を取りCLS行を2Dに並べてヒートマップで可視化する
各層のattention行列を取得しヘッドごとに融合
import torch
@torch.no_grad()
def collect_attn_per_layer(model, x_tensor, fuse="mean"):
"""
各ブロックの attn([B,H,L,L])を forward 1回で集め、ヘッド融合して [B,L,L] のリストで返す。
- fuse: "mean" or "max"
"""
model.eval()
# すべてのブロックをパッチ(差し替え)
for blk in model.blocks:
patch_attention(blk.attn)
_ = model(x_tensor) # 1回だけ forward
A_list = []
for blk in model.blocks:
A = blk.attn.last_attn # [B,H,L,L]
if fuse == "max":
A = A.max(dim=1).values # [B,L,L]
else:
A = A.mean(dim=1) # [B,L,L]
A_list.append(A.detach())
return A_list # list[[B,L,L]]は各ブロックから得られた多ヘッド平均済みのattention行列のリスト
単位行列を加算し、行正規化
def add_residual_and_row_norm(A, alpha=0.5, eps=1e-6):
"""
attentionに残差を混ぜて行正規化する
- A: [B,L,L](ヘッド融合済み)
- 返り値: [B,L,L]
"""
B, L, _ = A.shape
I = torch.eye(L, device=A.device).expand(B, L, L)
A = alpha * I + (1.0 - alpha) * A
A = A / (A.sum(dim=-1, keepdim=True) + eps) # 行ごとに確率化
return A
@torch.no_grad()
def attention_rollout(A_list, alpha=0.5):
"""
A_list: list of [B,L,L](層順)
返り値: R [B,L,L]
"""
assert len(A_list) > 0
B, L, _ = A_list[0].shape
R = torch.eye(L, device=A_list[0].device).expand(B, L, L).clone()
# CLSから各パッチに最終的にどれだけ情報が届くかを累積していく
for A in A_list:
A_tilde = add_residual_and_row_norm(A, alpha=alpha)
# これまでの到達確率を次の層のAttentionと掛け合わせて更新
R = torch.bmm(R, A_tilde)
return R # [B,L,L]の行列で、行iがCLS、列jがパッチjへの最終的な到達確率を表す
-
torch.bmm():バッチごとに独立した行列積を計算する
層順に行列積を取りCLS行を2Dに並べてヒートマップで可視化する
import numpy as np, cv2, matplotlib.pyplot as plt
def visualize_rollout(img_pil, model, x_tensor, fuse="mean", alpha=0.5,
use_pct=True, gamma=0.9):
"""
Rolloutのヒートマップを1枚表示する
- fuse: ヘッド融合("mean" or "max")
- alpha: 残差の混合率(0.5)
- use_pct: 5-95パーセンタイルでクリップするか(外れ値を無視)
- gamma: ガンマ補正(1.0で補正なし、<1で強調、>1で弱調整)
"""
# 各層の [B,L,L] を収集
A_list = collect_attn_per_layer(model, x_tensor, fuse=fuse) # 層順
# ロールアウト
R = attention_rollout(A_list, alpha=alpha) # [B,L,L]
cls_row = R[0, 0, :] # [L]
# 2D化
cam2d = cls_row_to_cam(cls_row, model) # [gh,gw]
if use_pct:
a, b = np.percentile(cam2d, [5, 95])
cam2d = np.clip((cam2d - a) / (b - a + 1e-8), 0, 1)
if gamma != 1.0:
cam2d = cam2d ** gamma
# オーバレイ
W, H = img_pil.size
cam_resz = cv2.resize(cam2d, (W, H), interpolation=cv2.INTER_NEAREST)
heat = cv2.applyColorMap((cam_resz * 255).astype(np.uint8), cv2.COLORMAP_JET)
base = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
overlay = cv2.addWeighted(base, 0.55, heat, 0.45, 0)
plt.figure(figsize=(5,5))
plt.imshow(cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB))
plt.title(f"Attention Rollout (fuse={fuse}, α={alpha})")
plt.axis("off")
plt.show()

- 補足1
今回は、correct_samplesの中からメラノーマを抽出し可視化しました。
抽出は以下のように行いました。
items = list(correct_samples.items())
key, (img_pil, idx, true_label, pred_label) = items[2]
- 補足2
層別のときは1ブロック内のsoftmax済みattention行列をそのままCLS行ベクトルにしていました。このとき、各行の和は1に正規化されており、値のスケール感は一定になるため、シンプルにmin-max正規化のみ行いました。一方、Rolloutのときは複数層の行列を積み重ねるため、値の分布がどんどん尖っていきます。そのため、パーセンタイル正規化(use_pct)やガンマ補正(gamma)を入れています。
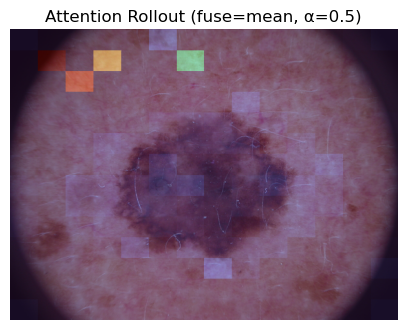
何も補正しなかったとき、以下のような結果になります。
visualize_rollout(img_pil, model, x_tensor, fuse="mean", alpha=0.5, use_pct=False, gamma=1.0)
- 補足3
今一つの画像だけで可視化しましたが、各画像ごとに独立してattentionを計算しているので画像ごとに別々のroll-out行列を持っていることになります。そのため、この可視化をミニバッチで行っても一枚だけで行っても得られるヒートマップに違いは生まれません(別の画像の情報が混ざることはないということ)
Attention行列の可視化において、注意すべきことはパッチ単位で情報をどれぐらい取得しているかが分かるだけで、クラスごとの判断根拠は分からないということです。
クラスごとに可視化したい場合は、次項以降の 勾配 を用いた可視化方法を使います。
可視化③ Transformer Explainer
やりたいこと
- 予測クラスに対する勾配をAttentionに掛け合わせ、層をまたいで伝播させることで、クラス特有の重要パッチを強調する
Rolloutとの違いについて
勾配とLRP(Layer-wise Relevance Propagation)を掛けていくことがポイントです。
論文で用いられているLRPで関連度を一つ一つの層で逆伝搬して求めるやり方をとります。
Githubに分かりやすく記載されていますので、良ければご参照ください。
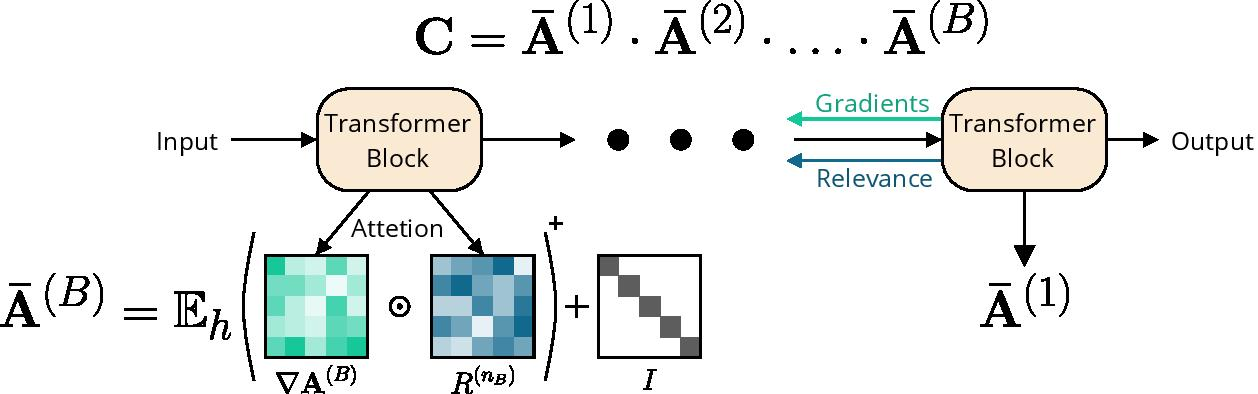
この数式の意味するところを簡単に説明します。
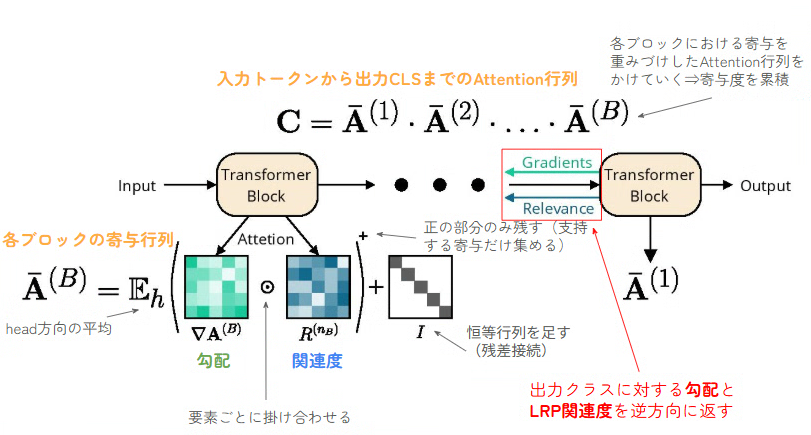
-
勾配×LRP関連度を作り、正の寄与のみを集め、head平均し、残差を加える
-
それをTransformer Blockの1からBまで掛け合わせる
⇒ 最終的にCLSがどの入力パッチに依存しているかを表す関連度行列Cが得られる -
Relevanceとは
最終的な出力スコア(logit)に対して、各ニューロンや各パッチがどれぐらい寄与したかを逆向きに分配した値
※ Attentionの値とは無関係。Attentionは「このパッチは他のどのパッチをどれぐらい参照するか」を計算しているのに対して、Relevanceは「このパッチは今回の分類スコアを上げるためにどれぐらい貢献しているか」を計算。
⇒ Attentionは「参照した」という事実しか分からないので、重要でない部分も強くなる場合がある。それを解決するために、Attention × Relevance × 勾配 を組み合わせる
Rolloutとの違いは、この画像をこのクラスと判定するときにどのパッチが効いたかを可視していることです。
実装
- githubから必要な関数を取得
- モデルにLRPを適用する
- ヒートマップへ可視化
githubから必要な関数を取得
以下のgithubから必要な関数を取得し、importします。
from baselines.ViT.ViT_LRP import VisionTransformer
from baselines.ViT.ViT_explanation_generator import LRP as LRP_CLASS
git clone すれば一気にディレクトリができてくれますが、不要なものは含めたくなかったので私は以下のようにディレクトリ構造を作りました。
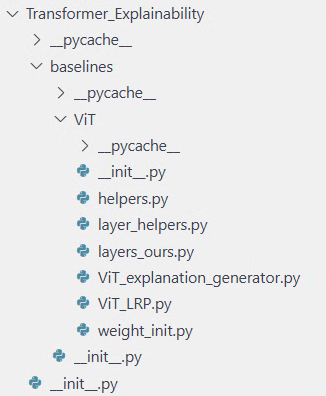
今までtimmモデルを使っていましたが、timmモデルにはrelprop(関連度逆伝播の仕組み)がありません。
そのため、LRP対応のVitをimportして、重みは今までのモデルと共有するような形にします。
これで、model_lrp.relprop(...)と呼べるようになります。
# LRP対応のVitを構築
model_lrp = VisionTransformer(img_size=224, patch_size=16, num_classes=7)
# 重みは今までのモデルと共有
model_lrp.load_state_dict(model.state_dict(), strict=False)
model_lrp.eval().to(device)
モデルにLRPを適用する
class CheferTransformerExplainer:
"""
timm の VisionTransformer に、Chefer 公式の LRP を適用する薄いラッパ。
- no_grad は使わない(LRPが勾配/フックを使うため)。
"""
def __init__(self, model):
"""
- model: LRP対応の VisionTransformer
- model.eval() にして渡す(Dropout/BNを固定)
- ただし forward 時に no_grad は使わない
"""
self.model = model
# 公式の LRP クラスを初期化。内部で必要なフックを登録する。
self.core = LRP_CLASS(self.model)
self._call_kind = "generate_LRP"
@torch.inference_mode(False) # 勾配を有効にする(evalだがno_gradにしない)
def explain(self, x: torch.Tensor, target_class: int,
start_layer: int = 1):
"""
クラス依存の説明マップ
- x: [B,3,H,W] テンソル(device は model と同じ)
- target_class: 可視化したいクラスID(logitのインデックス)
- start_layer: どの層から寄与伝播を開始するか(通常 1=パッチ埋め込み直後から)
- return: List[np.ndarray](各画像の 2D マップ)
"""
assert x.ndim == 4, f"x shape must be [B,3,H,W], got {tuple(x.shape)}"
B = x.size(0)
cams = []
for b in range(B):
xb = x[b:b+1] # [1,3,H,W]
cam = self.core.generate_LRP(
xb,
index=int(target_class),
method="transformer_attribution", # 公式の手法名
start_layer=start_layer,
)
if isinstance(cam, torch.Tensor):
cam = cam.detach().cpu().numpy()
cam = np.asarray(cam, dtype=np.float32)
cams.append(cam)
return cams
上記のクラスの中のgenerate_LRPが「各層で(∇𝐴⊙𝑅)+ を作り、残差も含めて**層間で合成(ロールアウト)**して最終関連度を出す」処理となります、
ヒートマップへ可視化
def visualize_transformer_explainer(img_pil, model, x_tensor, target_class, use_pct=True, gamma=0.9):
"""
Transformer_explainerのヒートマップを1枚表示する
- alpha: 残差の混合率(0.5)
- use_pct: 5-95パーセンタイルでクリップするか(外れ値を無視)
- gamma: ガンマ補正(1.0で補正なし、<1で強調、>1で弱調整)
"""
assert x_tensor.ndim == 4 and x_tensor.size(0) == 1, f"x_tensor shape must be [1,3,H,W], got {tuple(x_tensor.shape)}"
model.eval() # no_grad は付けない
explainer = CheferTransformerExplainer(model)
cams = explainer.explain(x_tensor, target_class=target_class, start_layer=1)
cam = cams[0] # 1枚目を取り出す(1, 196)※1枚なら不要
# cls_row_to_cam関数はtimmモデルのみに使える
if cam.ndim == 2 and cam.shape[0] == 1:
cam = cam.squeeze(0) # (1,196) -> (196,) 1次元ベクトルに変換
gh = gw = int(np.sqrt(cam.shape[0])) # 14
cam = cam.reshape(gh, gw) # (14,14)
cam = minmax(cam)
# 表示用の強調(外れ値クリップとガンマ補正)
if use_pct:
a, b = np.percentile(cam, [5, 95])
cam = np.clip((cam - a) / (b - a + 1e-8), 0, 1)
if gamma != 1.0:
cam = cam ** gamma
# オーバレイ
W, H = img_pil.size
cam_resz = cv2.resize(cam, (W, H), interpolation=cv2.INTER_NEAREST)
heat = cv2.applyColorMap((cam_resz * 255).astype(np.uint8), cv2.COLORMAP_JET)
base = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
overlay = cv2.addWeighted(base, 0.55, heat, 0.45, 0)
plt.figure(figsize=(5, 5))
plt.imshow(cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB))
plt.title(f"Transformer-Explainer (class={target_class})")
plt.axis("off")
plt.show()
では、実際に可視化してみます。
visualize_transformer_explainer(img_pil, model_lrp, x_tensor, target_class=5, use_pct=True, gamma=0.9)

可視化④ Grad-CAM
やりたいこと
- 最終ブロックのトークン表現とその勾配を用い、チャネルごとに重み付けして和を取ることで、クラス特有のパッチ重要度をヒートマップ化する
- CNNでは畳み込み層の 特徴マップ を対象にして、Vitでは最終ブロックの トークン表現 を対象に勾配をかけることに注意する
hookとは?
今回は、_register_hooks関数をクラス内で作成しました。
hookとは、特定のレイヤのforward / backwardの途中でテンソルを取得したいときに使います。forwardのhookは 特徴マップ、backwardのhookは 勾配 になります。
Grad-CAMでは、層の出力である特徴マップと、その勾配が必要なので上記を定義します。
hookの種類について余談
Moduleに付けるフック と Tensorに付けるフック があります。
- Module
-
register_forward_pre_hook… forward の「直前」に呼ばれる -
register_forward_hook…… forward の「直後」に呼ばれる(出力を観察できる) -
register_full_backward_pre_hook… backward の「その Module に到達する直前」に呼ばれる -
register_full_backward_hook…… backward の「その Module を通過した直後」に呼ばれる(入出力勾配を観察できる)
-
- Tensor
-
Tensor.register_hook…… そのテンソル自身の勾配が計算された直後に呼ばれる
-
今回のニーズとして、層の出力(特徴マップ)が欲しいのでmodule.register_forward_hookを使い、出力にout.register_hookをかけてその出力の勾配をピンポイントに取得する方針です。
実装
実装の流れは以下のとおりです。
- forwardでその層の出力(特徴)を保存
- backwardでその層の出力に対する勾配を保存
- チャネル平均の勾配を重みとして、重み付き和を計算
- CLSを除いたパッチ部分を2D(gh,gw)に並びなおしてヒートマップにする
特徴マップとその勾配を取得するクラス
import torch, numpy as np, cv2
class GradCam:
"""
ViT 用Grad-CAM
- target_layer は [B, N, C] 形のトークン表現を出す層
- CAM は CLS を除いたパッチトークンを (gh, gw) に並べ直して返す
"""
def __init__(self, model: torch.nn.Module, target_layer: torch.nn.Module):
self.model = model.eval() # eval だが no_grad は使わない
self.target = target_layer
self._feat = None # forward 出力([B,N,C])
self._grad = None # その出力に対する勾配([B,N,C])
self.h_fwd = None
# ---- hooks ----
def _register_hooks(self):
def fwd_hook(module, inp, out):
self._feat = out # forwardの出力out: [B, N, C]を保存
def save_grad(grad):
self._grad = grad # その出力に対する勾配を保存
out.register_hook(save_grad) # 出力テンソルにbackward hookを登録
# forwardする直前にフックを登録し、fwd_hookが呼ばれたときに特徴マップを保存
self.h_fwd = self.target.register_forward_hook(fwd_hook)
def _remove_hooks(self):
if self.h_fwd is not None:
self.h_fwd.remove()
self.h_fwd = None
# ---- 形状変換: [B,N,C] -> [B,C,gh,gw] ----
@staticmethod # <- インスタンス(self)に依存しない
def _tokens_to_map(toks: torch.Tensor, gh: int, gw: int) -> torch.Tensor:
# toks: [B, N, C](N=1+gh*gw or gh*gw)
if toks.dim() != 3:
raise ValueError(f"expected [B,N,C], got {toks.shape}")
B, N, C = toks.shape
# CLS を含むなら除去
if N == gh*gw + 1:
toks = toks[:, 1:, :] # 先頭を除く
N -= 1
if N != gh*gw:
raise ValueError(f"N={N} but gh*gw={gh*gw}")
# [B, gh*gw, C] -> [B, gh, gw, C] -> [B, C, gh, gw]
return toks.reshape(B, gh, gw, C).permute(0, 3, 1, 2).contiguous()
@torch.inference_mode(False) # 勾配を有効
def __call__(self, inputs: torch.Tensor, target_class: int | None = None,
img_size: tuple[int,int] = (224,224)) -> np.ndarray:
"""
return: CAM の 2D 配列(img_size にリサイズ済み, np.float32 [0..1])
"""
self._feat = self._grad = None
self._register_hooks()
x = inputs.to(device)
ph, pw = self.model.patch_embed.proj.kernel_size
sh, sw = self.model.patch_embed.proj.stride
H, W = x.shape[-2:]
gh = (H - ph) // sh + 1
gw = (W - pw) // sw + 1
# forward実行
self.model.zero_grad(set_to_none=True) # 勾配をゼロに初期化
out = self.model(x) # [B,C]
index = int(out[0].argmax(-1) if target_class is None else target_class)
# backward実行
out[0, index].backward(retain_graph=False) # autogradグラフを破棄
# 取得
feat = self._feat # [B,N,C]
grad = self._grad # [B,N,C]
if feat is None or grad is None:
self._remove_hooks()
raise RuntimeError("hooks did not capture features/gradients; check target_layer")
# トークン → マップ [B,C,gh,gw]
feat_map = self._tokens_to_map(feat, gh, gw)[0].detach().cpu().numpy()
grad_map = self._tokens_to_map(grad, gh, gw)[0].detach().cpu().numpy()
# 重要度(チャネル平均の勾配)
weight = grad_map.mean(axis=(1, 2)) # [C]
cam = np.sum(feat_map * weight[:, None, None], axis=0) # [gh,gw]
cam = np.maximum(cam, 0) # ReLU
# 正規化
cam_min, cam_max = float(cam.min()), float(cam.max())
if cam_max > cam_min:
cam = (cam - cam_min) / (cam_max - cam_min)
else:
cam = np.zeros_like(cam, dtype=np.float32)
# リサイズ
cam = cv2.resize(cam.astype(np.float32), img_size, interpolation=cv2.INTER_CUBIC)
self._remove_hooks()
return cam
- 補足1
hookがどこでどのようにかかっているかが分かりにくいので補足します。
__call__のところの順序を見ると、まずself._register_hooks()が記載されているので、以下の関数が登録されます。
def _register_hooks(self):
def fwd_hook(module, inp, out):
self._feat = out # forwardの出力out: [B, N, C]を保存
def save_grad(grad):
self._grad = grad # その出力に対する勾配を保存
out.register_hook(save_grad) # 出力テンソルにbackward hookを登録
# forwardする直前にフックを登録し、fwd_hookが呼ばれたときに特徴マップを保存
self.h_fwd = self.target.register_forward_hook(fwd_hook)
この関数の中を見ると、self.target つまり target_layer にregister_forward_hook()関数がかけられているので、target_layer層がforwardを終えたらfwd_hook関数が呼ばれます。
そして、fwd_hook関数では、出力のoutにregister_hook()関数がかけられています。
regidter_hook()関数は save_grad()関数を呼んでおり、これでforwardから出てきた出力テンソルの勾配を取得できることになります。
-
補足2
Vitの中間表現は[B,N,C]=[バッチ、トークン数(1+gh×gw)、埋め込み次元]ですが、Grad-CAMは[B,C,H,W]のようにチャネルごとに空間マップがある前提となっています。
そのため、トークン列 → 2Dグリッドに変換する必要があります。
今まで上記の動作を可視化①、②のときはcls_row_to_cam関数で、可視化③ではsqrt→reshapeで書いていましたが、今回はより頑健な形で記載しています。-
cls_row_to_cam関数- timmモデルが
model.patch_embed.grid_sizeでgh,gwを取り出せることを活かす。また、CLS が先頭、パッチが末尾に連続で並ぶ前提
- timmモデルが
-
sqrt→reshape-
camがCLS を除いた「パッチ数ベクトル」で、正方格子(14×14)であることを想定
-
-
【今回】
tokens_to_map関数 / gh,gwを一般の畳み込みの公式から求める- 入力が[B,N,C]でないときを検知
- CLSを含むなら除去(Distillationトークンの場合は
if N == gh*gw + 2: toks = toks[:, 2:, :]を追加すれば良し) - トークン数とグリッド数が一致していなければ並べ替え不能エラー
- timmモデルが実装しているkernel_size=patch_size, stride=patch_sizeを使って公式どおりにgh,gwを算出(入力サイズが動的であっても対応)
-
ヒートマップへ可視化
def show_gradcam(sample_dict, result, target_layer):
grad_cam = GradCam(model, target_layer)
for class_id, (pil_img, idx, true_label, pred_label) in sample_dict.items():
image_tensor = val_transform(pil_img).unsqueeze(0)
cam_mask = grad_cam(image_tensor, target_class=true_label, img_size=(224,224))
# ヒートマップ化
cam_min, cam_max = cam_mask.min(), cam_mask.max()
denom = cam_max - cam_min
if denom == 0:
heatmap = np.zeros_like(cam_mask)
else:
heatmap = (cam_mask - cam_min) / (denom + 1e-8)
heatmap = np.nan_to_num(heatmap)
# オーバレイ
W, H = pil_img.size
cam_resz = cv2.resize(heatmap, (W, H), interpolation=cv2.INTER_NEAREST)
heat = cv2.applyColorMap((cam_resz * 255).astype(np.uint8), cv2.COLORMAP_JET)
base = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
overlay = cv2.addWeighted(base, 0.55, heat, 0.45, 0)
plt.figure(figsize=(5, 5))
plt.imshow(cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB))
print(f"{result} Grad-CAM Class {class_id} idx:{idx} true:{true_label} pred:{pred_label}")
plt.axis("off")
plt.show()
- 補足3
今回いつもは正規化処理のみでしたが、ゼロ除算処理を丁寧に書いています。
これは、Grad-CAMはbackwardの勾配を使っており、数値が不安定になりやすいからです。-
denom == 0:情報がないときは全部ゼロにする -
+1e-8:denomが非常に小さいときでもゼロ除算を防ぐ -
np.nan_to_num:NumPy の配列に NaN(Not a Number)や ±inf が混じったときに、強制的にゼロに置き換える
-
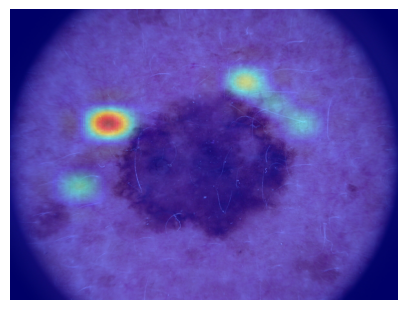
show_gradcam(correct_samples, "Correct", model.blocks[-1].norm1)
メラノーマは以下のようになりました。
-
補足4
今までと見え方の粒度が明らかに異なります。
これは、今までパッチ単位(16×16ブロック)の解像度で可視化していましたが、Grad-CAMは特徴マップの空間解像度まで落とし込んでいたのでより細かい粒度になっています。 -
補足5
どこを可視化するかについて、今回はblock[-1].norm1を可視化しました。
一般的にTransformer Blockの順序は一般的に以下のようになっています。- norm1 → 正規化
- Attention → マルチヘッド自己注意
- skip で入力と和をとる
- norm2 → 正規化
- MLP → フィードフォワードネット
- skip
norm1はAttentionに入る直前なので、CLS+パッチトークンが独立しており、パッチごとに整っています。
たいして、Attentionの出力後はトークン同士の関係を反映した行列積になっているので全体が混ざった特徴になっています。
Grad-CAM的には空間的な解釈性を大事にしているので、norm1が採用されることが多いです。
CNNの場合は、クラス分類直前の最終conv層が可視化に使われます。
VitとCNNの違い
VitとCNNでは、以下の点が大きく異なってきます。
-
出力テンソルの形
- CNN の target は最後の畳み込みの出力 → out: [B, C, H, W](空間マップそのもの)
- ViT の target はトークン表現 → out: [B, N, C](CLS + パッチトークン)
-
可視化前の整形
- CNN: そのまま C×H×W を使える(整形不要)
- ViT: N のうち CLS を除外し、残り N_p=gh×gw を (gh, gw) に
reshapeしてから C×gh×gw に並べ替える(= “トークン→2D” 変換)
-
どこにフックするか
- CNN: 分類直前の“最後の畳み込み出力”(解像度が残っていてクラスに近い)
- ViT: 最後のブロックの norm1(Attention に入る直前でパッチ単位の対応が明瞭)
出力が異なるのでoutの形が異なりますが、_register_hooks関数はそのまま使えます。
一方で、CNNはそのままチャネル平均勾配を重みにして重み付き和を取ることで cam が得られます。
out が[C,H,W]のため、整形は不要でVitのときと同様のコードで cam を取得できます。
weight = grad.mean(axis=(1, 2)) # [C]
cam = np.sum(feat * weight[:, None, None], axis=0) # [H,W]
cam = np.maximum(cam, 0)
上記のコードで行っていることは、以下の3つです。
- 勾配を空間平均(
mean(axis=(1,2)))にしてチャネルごとの重みweightを算出 -
weightを[C,1,1]にブロードキャストして、featの各チャネルに重みづけし、チャネル方向に和を取って2Dマップを作成 - 正の寄与だけを残す
全層可視化
最後にクラス別、層別にそれぞれ可視化してみましょう。
def show_all_gradcam(sample_dict):
num_blocks = len(model.blocks)
num_classes = len(sample_dict)
fig, axes = plt.subplots(nrows=num_classes, ncols=num_blocks, figsize=(num_blocks * 2, num_classes * 2))
for row, (class_id, (pil_img, _, true_label, _)) in enumerate(sample_dict.items()):
image_tensor = val_transform(pil_img).unsqueeze(0) # 各画像に対して再生成
for col, block in enumerate(model.blocks):
target_layer = block.norm1
grad_cam = GradCam(model, target_layer)
cam_mask = grad_cam(image_tensor, target_class=true_label, img_size=(224,224))
# スケーリング(ゼロ除算を避ける)
cam_min = cam_mask.min()
cam_max = cam_mask.max()
denom = cam_max - cam_min
heatmap = np.zeros_like(cam_mask) if denom == 0 else (cam_mask - cam_min) / denom
heatmap = np.nan_to_num(heatmap)
# ヒートマップ → カラー変換
W, H = pil_img.size
cam_resz = cv2.resize(heatmap, (W, H), interpolation=cv2.INTER_NEAREST)
heat = cv2.applyColorMap((cam_resz * 255).astype(np.uint8), cv2.COLORMAP_JET)
base = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
overlay = cv2.addWeighted(base, 0.55, heat, 0.45, 0)
ax = axes[row, col]
ax.imshow(cv2.cvtColor(overlay, cv2.COLOR_BGR2RGB))
ax.axis("off")
if row == 0:
ax.set_title(f"Block {col}", fontsize=10)
if col == 0:
ax.set_ylabel(f"Class {class_id}", fontsize=10)
plt.tight_layout()
plt.show()
show_all_gradcam(correct_samples)

解釈が難しいですが、Vision Transformerは複数の視点(=Block)で特徴をとらえているので、どの層もそれぞれ見ている箇所が異なることはこの結果からも読み取ることができます。
以上です。読んでいただきありがとうございました。