Icebergカタログとテーブルの準備
最近データレイク界隈で"Iceberg"というキーワードを聞くようになってきました。
Icebergは、公式サイトでは次のように書かれています。
Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
Icebergは巨大な分析テーブルのための高性能フォーマットです。IcebergはSQLテーブルの信頼性とシンプルさをビッグデータにもたらすと同時に、Spark、Trino、Flink、Presto、Hive、Impalaなどのエンジンが同じテーブルを同時に安全に扱うことを可能にします。
期待の技術のようですが、まだまだ開発途上ということもあり詳しい情報が分かりません。そこで、いくつかの製品ごとに性能評価をしてみようと思います。まずは以下の製品について調査をしようと思います。
共通
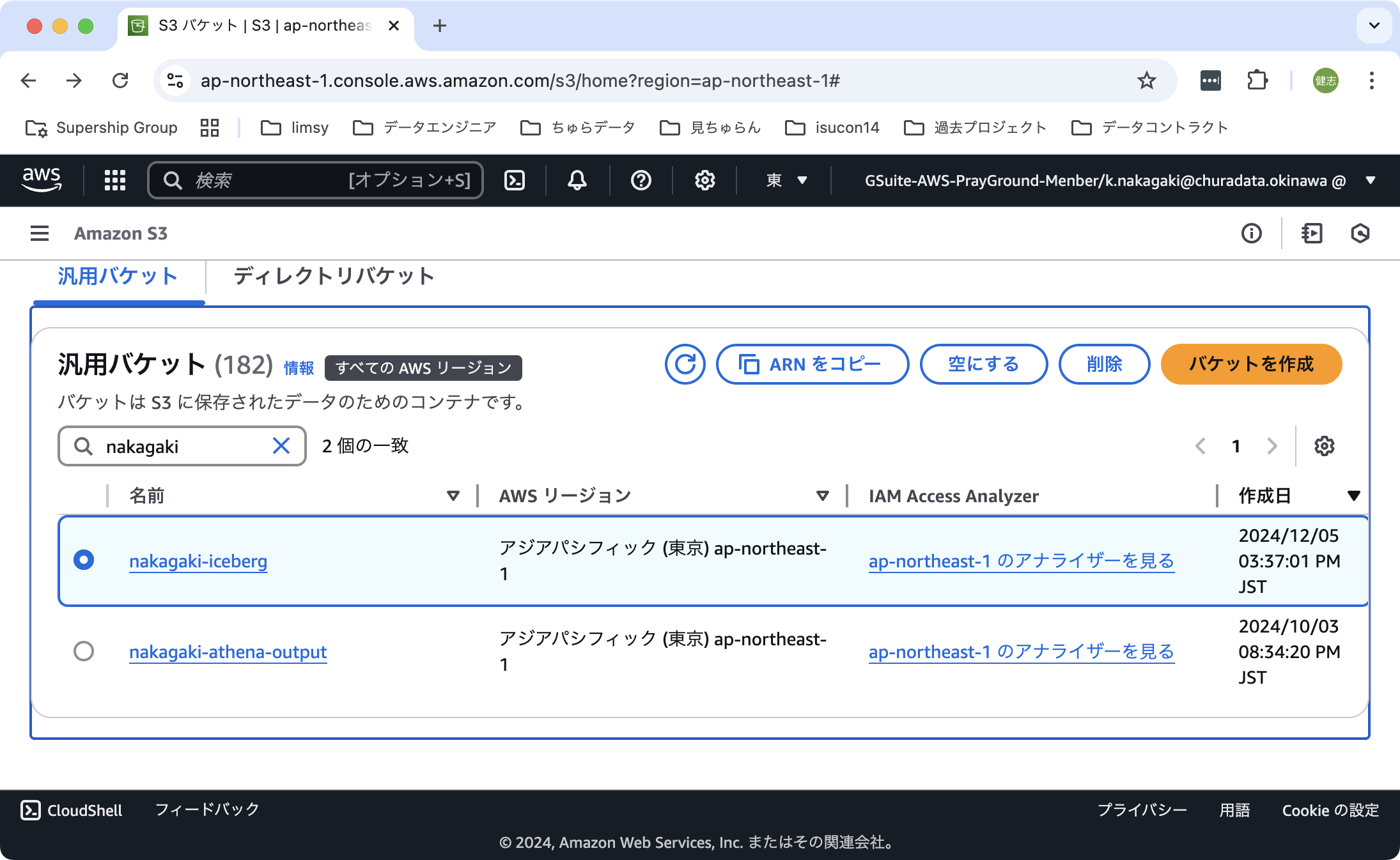
S3バケットの作成
Icebergカタログのメタ情報やデータを保存する場所として、S3が使われます。そのため、まずS3バケットを用意します。
具体的な手順は以下の通りです。
- 「Amazon S3 - 汎用バケット」の順に選択する。
- 「バケットを作成」をクリックする。
- バケット名を入力して、その他はデフォルトのまま、「バケットを作成」をクリックする。
これで、新しいバケットが作成されます。
Apache Spark
ここでは、Apache SparkでIceberg形式のカタログを作成する手順について説明します。
Apache SparkのIcebergは、Icebergのリファレンス実装という位置付けでもあるようで、導入方法はIcebergの公式サイトに書かれています。
ここでは上記のサイトの内容から抜粋して手順を記載します。
カタログの作成
- 以下のコマンドを実行する
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.7.0\
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.spark_catalog.type=hive \
--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.local.type=hadoop \
--conf spark.sql.catalog.local.warehouse=$PWD/warehouse
上記コマンドを実行するとカタログが作成されて、引き続きSQLを受け付けるプロンプトが表示された状態になります。
% spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.7.0\
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.spark_catalog.type=hive \
--conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.local.type=hadoop \
--conf spark.sql.catalog.local.warehouse=$PWD/warehouse
:: loading settings :: url = jar:file:/Users/kenji.nakagaki/.pyenv/versions/3.11.8/lib/python3.11/site-packages/pyspark/jars/ivy-2.5.1.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /Users/kenji.nakagaki/.ivy2/cache
The jars for the packages stored in: /Users/kenji.nakagaki/.ivy2/jars
org.apache.iceberg#iceberg-spark-runtime-3.5_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-f80cf748-fd92-4379-bc62-38a924aabf47;1.0
confs: [default]
found org.apache.iceberg#iceberg-spark-runtime-3.5_2.12;1.7.0 in central
:: resolution report :: resolve 51ms :: artifacts dl 1ms
:: modules in use:
org.apache.iceberg#iceberg-spark-runtime-3.5_2.12;1.7.0 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 1 | 0 | 0 | 0 || 1 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-f80cf748-fd92-4379-bc62-38a924aabf47
confs: [default]
0 artifacts copied, 1 already retrieved (0kB/2ms)
24/12/07 10:02:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/12/07 10:02:12 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
24/12/07 10:02:12 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
24/12/07 10:02:13 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
24/12/07 10:02:13 WARN ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore kenji.nakagaki@192.168.11.10
Spark Web UI available at http://192.168.11.10:4040
Spark master: local[*], Application Id: local-1733533332331
spark-sql (default)>
テーブルの作成
- プロンプトから、以下のSQLを実行する
spark-sql (default)> CREATE TABLE local.db.table (id bigint, data string) USING iceberg;
これで完了です。プロンプトはCTRL+Dで抜けることができます。
なおこの手順を実行すると、メタデータやデータを管理するファイルを保存するディレクトリが、実行したディレクトリにwarehouseという名前で作成されます。このディレクトリを削除することで、Icebergのカタログを削除できます。
AWS Glue
ここでは、AWS GlueでIceberg形式のカタログを作成する手順について説明します。
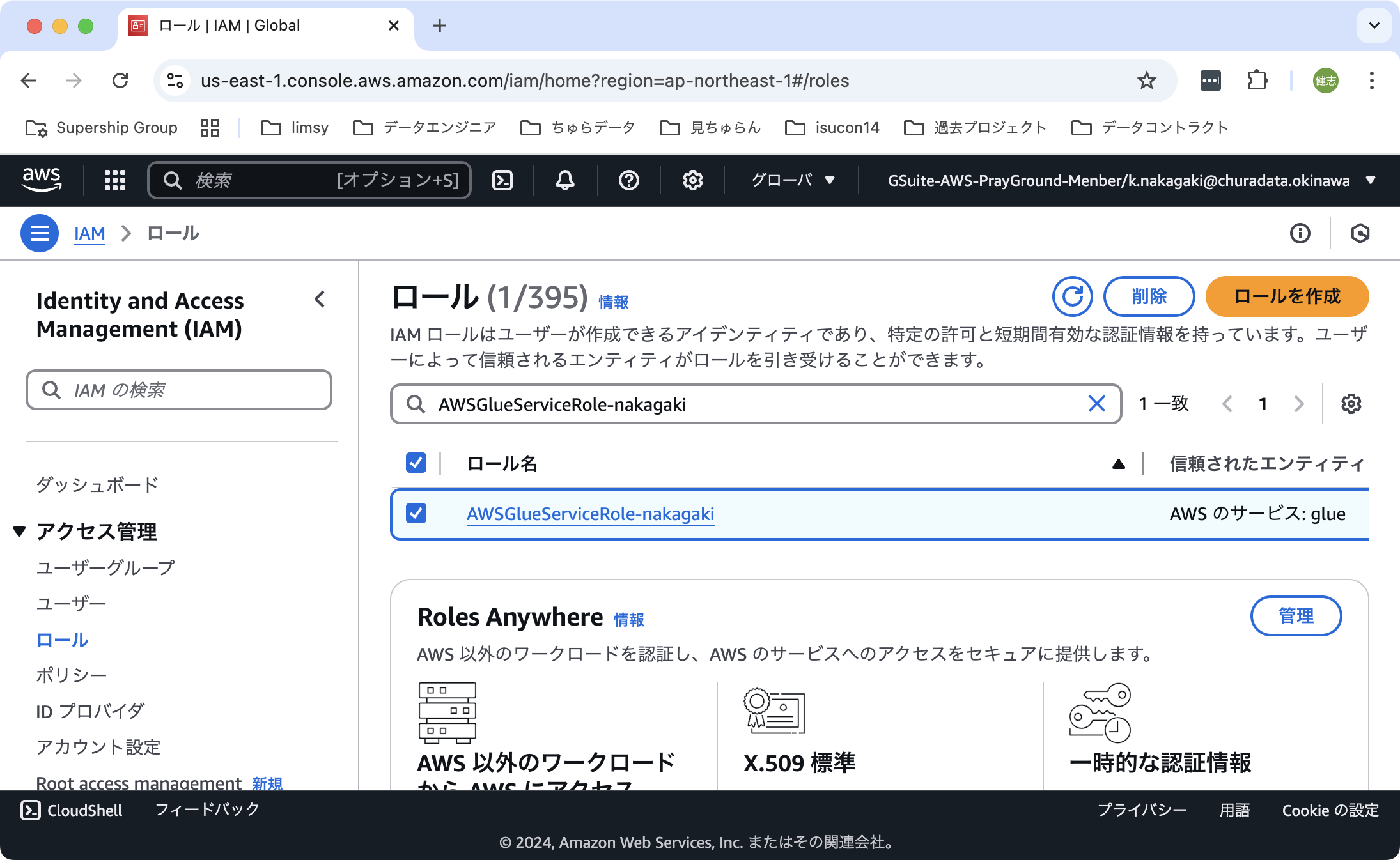
IAMロールの作成
AWS Glueカタログには、AWS Glueにアクセスするためのポリシーと、S3にアクセスするためのポリシーを持つロールを割り当てる必要があります。(AWSGlueConsoleFullAccessは必要かどうか試す)
コンソールユーザーからサービスにロールを渡すには、ロール名に文字列 AWSGlueServiceRole のプレフィックスが付けられていることが期待されています。もしこの条件を満たさない命名をしたい場合には、追加の設定が必要です。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/create-an-iam-role.html
具体的な手順は以下の通りです。
- 「IAM - ロール」の順に選択する。「ロールの作成」をクリックする。
- ステップ1では、信頼されたエンティティタイプに
AWSのサービス、サービスまたはユースケースにGlueを選択する。選択したら「次へ」をクリックする。 - ステップ2では、許可ポリシーに
AWSGlueServiceRoleポリシーと先に作成したS3バケットへのフルアクセスができるポリティー(ここでは簡易にAmazonS3FullAccessポリシーを使用する)を選択する。選択したら「次へ」をクリックする。 - ステップ3では、ロール名を入力する。上記の通り
AWSGlueServiceRoleで始まる名前とする。名前を入力したら「ロールを作成」をクリックする。
これでIAMロールが作成されます。
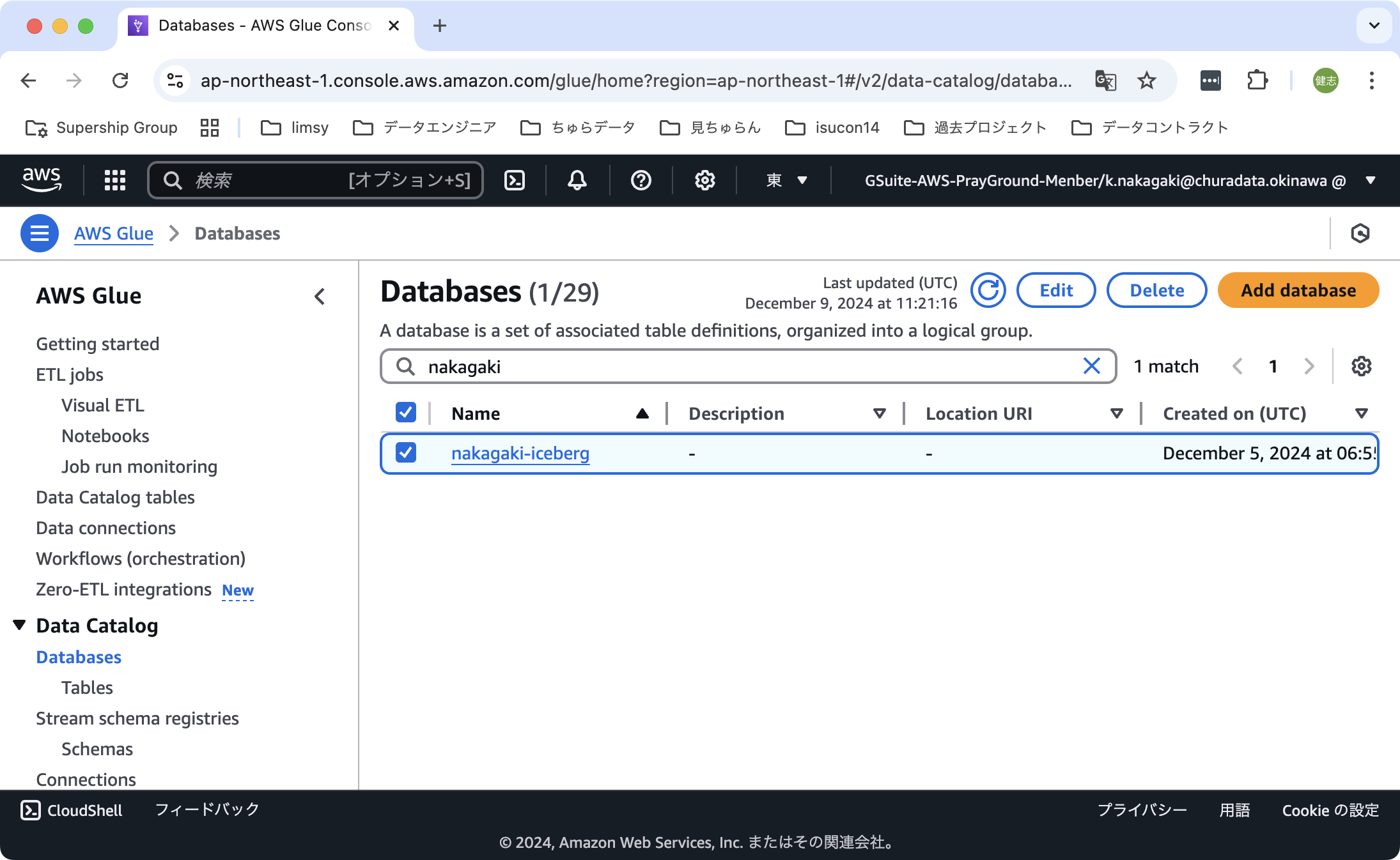
データベースの作成
これで必要なリソースの準備ができました。次にデータベースを作成します。
具体的な手順は以下の通りです。
- 「AWS Glue - Data Catalog - Database」の順に選択する。「Add Database」をクリックする。
- データベース名を入力する。入力したら「Create Database」をクリックする。
これでデータベースが作成されます。
テーブルの作成
続いて、先ほど作成したデータベースの中にテーブルの作成を行います。
具体的な手順は次のとおりです。
- 「AWS Glue - Data Catalog - Table」の順に選択する。「Add Table」をクリックする。
- Name(テーブル名)、Databaseを設定する。Table formatは
Apache Iceberg tableを指定する。IAM roleには、先に作成したロールを指定する。Table PathのInclude Pathには、最初に作成したs3バケットの中のディレクトリを指定する。その他の項目はデフォルトの値をそのまま利用する。すべて設定したら「Next」をクリックする。 - 「Choose or define schema」ではテーブルの列を追加する。ここではid(bigint), data(string)を指定する。すべて設定したら「Next」をクリックする。
- 確認画面で設定内容に間違いがないことを確認して、「Create」をクリックする。
これでIcebergテーブルが作成されます。
Snowflake
ここでは、SnowflakeでIceberg形式のカタログを作成する手順について説明します。
SnowflakeでIcebergカタログを作成する方法はいくつか存在します。
- Snowflakeで扱えるテーブルの種類の一つとして作成する
-
Snowflake Open Catalogのテーブルとして作成する
一つめの方法は、通常のSnowflakeのデータベースやスキーマの中に作成するテーブルとしてIcebergテーブルを作成する方法です。
作成方法は、Snowflake自身でテーブルの実態を管理する方法と、他のエンジンで管理されているIcebergカタログのテーブルを参照する方法の二種類が存在します。
https://docs.snowflake.com/ja/user-guide/tables-iceberg
もう一つのSnowflake Open Catalogは、Iceberg専用のカタログを管理するマネージドサービスです。実態は次に紹介するApache Polarisになります。
https://other-docs.snowflake.com/en/opencatalog/overview
ここでは、1.の方法のうち、Snowflake自身でテーブルの実態を管理する方法について説明していきます。
外部ボリュームの作成
外部ボリュームの作り方は、公式ドキュメントが詳しいです。
外部ボリュームは、AWSのS3やGoogle Cloud Storageのように、さまざまなクラウドベンダーのストレージサービス上に作成することができます。
一番初めに作成したAmazon S3バケットを使用します。
テーブルの作成
Icebergテーブルの作り方も、公式ドキュメントに詳しく書かれています。
ここでは、「SnowflakeをカタログとしてIcebergテーブルを作成する」の手順に沿ってテーブルを作成します。
以下はIcebergテーブルを作るためのSQL文です。
EXTERNAL_VOLUMEには、上で作成した外部ボリュームの名前を設定します。
CREATE OR REPLACE ICEBERG TABLE my_table (
id long,
data string
)
CATALOG = 'SNOWFLAKE'
EXTERNAL_VOLUME = 'my_ext_vol'
BASE_LOCATION = 'snowflake';
Apache Polaris
ここでは、Apache Polaris(以下、Polaris)でIceberg形式のカタログを作成する手順について説明します。
Polarisは、Snowflakeが開発しているオープンソースのIcebergカタログです。
Snowflake主体で開発されていますが、Polaris単体で動作させることができます。Snowflake環境は必要ありません。
またSnowflakeには、Snowflake Open Catalogというサービスが用意されていますが、これはSnowflakeによるPolarisのマネージド実装となります。
Polarisのインストール
Polarisはまだ開発途上なので、特にインストーラーなどは用意されていません。代わりにGitHubから最新のソースコードをクローンして、ビルド〜実行という流れになります。詳細は公式ドキュメントのQuick Startに書かれています。このドキュメントでは、Dockerを使った方法とJavaのソースコードをビルドして実行する方法の二つのデプロイ方法が掲載されています。このブログでは後者の方法で説明していきます。
まず、JDKを用意します。公式ドキュメントではjenvを使った複数バージョンのJDK管理を紹介しているので、そのようにインストールを行います。
brew install openjdk@21 jenv
jenv add $(brew --prefix openjdk@21)
次にSQLのエンジンとしてSparkを用意します。公式ドキュメントではGitHubのリポジトリをクローンしてビルドするところから始めているので、それに倣います。
git clone https://github.com/apache/spark.git
cd spark
./build/mvn -DskipTests clean package
最後にGitHubからリポジトリのクローンを行います。クローン場所は任意です。
git clone https://github.com/apache/polaris.git
Polarisの起動
準備ができたので、Polarisを起動します。まずは利用するJDKを指定します。ここでは、Polarisディレクトリ配下にローカルにJDKのバージョンを指定します。
cd polaris
jenv local 21
次にPolarisを起動します。起動には、gradlewコマンドを使用します。ダウンロードしたリポジトリ以下で次のコマンドを実行します。
./gradlew runApp
これでPolarisが起動します。流れていくログの中で、次のような出力がされているところを確認してください。これがpolarisにコマンドを発行するときに必要となる認証情報となります。
realm: default-realm root principal credentials: <client-id>:<client-secret>
カタログの作成
Polarisが起動したら、新しいカタログを用意します。Polarisを起動したターミナルとは別に新しいターミナルを開きます。次に先に確認した認証情報を、環境変数に設定します。
export CLIENT_ID=<client-id>
export CLIENT_SECRET=<client-secret>
次にカタログを作成していきます。以降の作業では、リポジトリ直下にあるpolarisコマンドを使います。このコマンドは内部ではvenvを使って独立したPython環境を作成して、その環境でコマンドを実行します。しかしGitHubからクローンしたソースではその環境が中途半端な状態になっていて動作に失敗することがあります。そこで1回目だけは、環境を削除しておく方が安全です。環境はpolaris-venvディレクトリに保存されています。
rm -r polaris-venv
以降は公式ドキュメントのQuick Startに沿って作業を進めていきます。
# カタログの作成
./polaris \
--client-id ${CLIENT_ID} \
--client-secret ${CLIENT_SECRET} \
catalogs \
create \
--storage-type FILE \
--default-base-location file:///tmp/quickstart_catalog \
quickstart_catalog
# ユーザーの作成
./polaris \
--client-id ${CLIENT_ID} \
--client-secret ${CLIENT_SECRET} \
principals \
create \
quickstart_user
# ロールの作成
./polaris \
--client-id ${CLIENT_ID} \
--client-secret ${CLIENT_SECRET} \
principal-roles \
create \
quickstart_user_role
./polaris \
--client-id ${CLIENT_ID} \
--client-secret ${CLIENT_SECRET} \
catalog-roles \
create \
--catalog quickstart_catalog \
quickstart_catalog_role
# ロールの割り当て
./polaris \
--client-id ${CLIENT_ID} \
--client-secret ${CLIENT_SECRET} \
principal-roles \
grant \
--principal quickstart_user \
quickstart_user_role
./polaris \
--client-id ${CLIENT_ID} \
--client-secret ${CLIENT_SECRET} \
catalog-roles \
grant \
--catalog quickstart_catalog \
--principal-role quickstart_user_role \
quickstart_catalog_role
./polaris \
--client-id ${CLIENT_ID} \
--client-secret ${CLIENT_SECRET} \
privileges \
catalog \
grant \
--catalog quickstart_catalog \
--catalog-role quickstart_catalog_role \
CATALOG_MANAGE_CONTENT
これで以下のようなカタログ、ユーザー、ロールが作成されます。
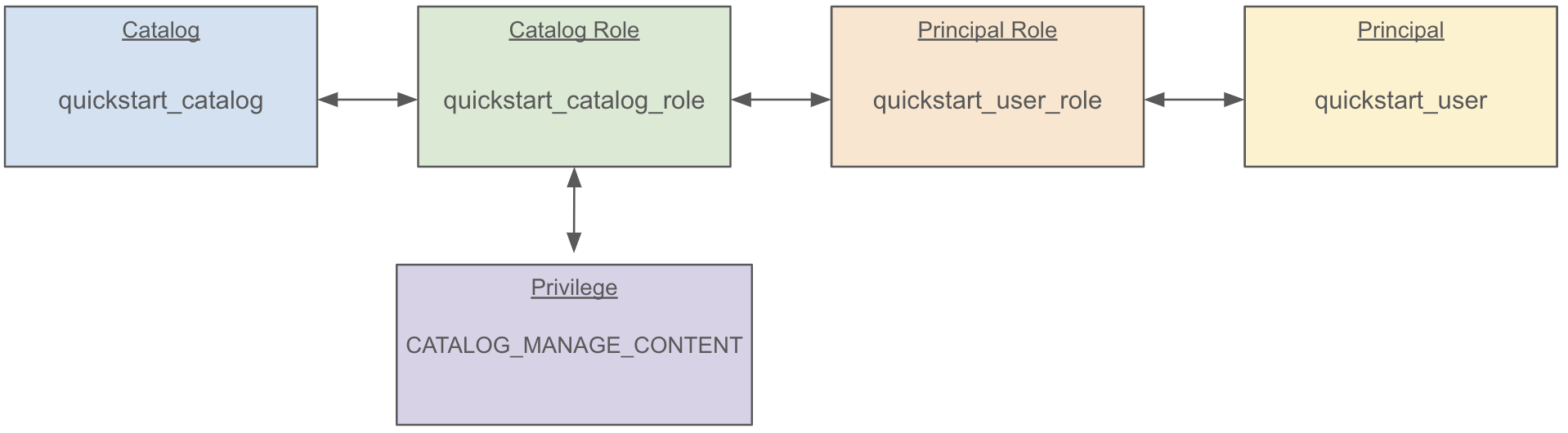
また作成中、以下のようなログが表示されたら書き留めておきます。これは作業中に作成したユーザーの認証情報になります。
{"clientId": "XXXXXXXX", "clientSecret": "YYYYYYYYYY"}
テーブルの作成 ###
テーブルを作成します。作成にはspark-shellを使います。
Sparkをクローンしたディレクトリに移動して、下記コマンドを実行します。
またコマンドの中で--conf spark.sql.catalog.quickstart_catalog.credential='XXXXXXXX:YYYYYYYYYY' \となっている場所は、上記のユーザーの認証情報に置き換えます。
bin/spark-shell \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.7.1,org.apache.hadoop:hadoop-aws:3.4.0 \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.quickstart_catalog.warehouse=quickstart_catalog \
--conf spark.sql.catalog.quickstart_catalog.header.X-Iceberg-Access-Delegation=vended-credentials \
--conf spark.sql.catalog.quickstart_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.quickstart_catalog.catalog-impl=org.apache.iceberg.rest.RESTCatalog \
--conf spark.sql.catalog.quickstart_catalog.uri=http://localhost:8181/api/catalog \
--conf spark.sql.catalog.quickstart_catalog.credential='XXXXXXXX:YYYYYYYYYY' \
--conf spark.sql.catalog.quickstart_catalog.scope='PRINCIPAL_ROLE:ALL' \
--conf spark.sql.catalog.quickstart_catalog.token-refresh-enabled=true
spark-shellが起動したら、Scalaのプログラムを通じでSQLを発行します。
spark.sql("USE quickstart_catalog")
spark.sql("CREATE NAMESPACE IF NOT EXISTS quickstart_namespace")
spark.sql("CREATE NAMESPACE IF NOT EXISTS quickstart_namespace.schema")
spark.sql("USE NAMESPACE quickstart_namespace.schema")
spark.sql("""
CREATE TABLE IF NOT EXISTS quickstart_table (
id BIGINT, data STRING
)
USING ICEBERG
""")
注:
pipでpysparkをインストールした、などといった操作で、パスの通った場所にspark-shellコマンドがある場合は、bin/spark-shell ...ではなくspark-shell ...で実行しても良いです。またその場合、任意のディレクトリで実行できます。