動機
標準では、下記のコードはエラーになります。
for s in "A"..."Z" {
// ^ error: protocol 'Sequence' requires that 'String' conform to 'Strideable'
}
for c in Character("A")...Character("Z") {
// ^ error: protocol 'Sequence' requires that 'Character' conform to 'Strideable'
}
let a = Array(Character("A")...Character("Z"))
// ^ error: missing argument label 'arrayLiteral:' in call
ClosedRange<String>やClosedRange<Character>が、Strideableに準拠していないからです。
よって、Array(1...10)のようなArray(Character("A")...Character("Z"))の書き方も使えません。
そこで、CharacterをStrideableに準拠させます。
Character型をStrideableに準拠させる
ただし、ASCIIコード限定です。
extension Character: @retroactive Strideable {
public func advanced(by n: Int) -> Self {
let nextValue = self.asciiCode + n
assert(nextValue < 128, "Out of bounds. \(nextValue)")
return Character(UnicodeScalar(nextValue)!)
}
public func distance(to x: Self) -> Int {
return x.asciiCode - self.asciiCode
}
}
extension Character {
var asciiCode: Int { Int(self.asciiValue ?? 0) }
}
使えるようになりました
for c in Character("A")...Character("Z") {
print(c, terminator: " ")
}
//A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
for c in stride(from: Character("z"), through: Character("v"), by: -1) {
print(c, terminator: " ")
}
//z y x w v
let a = Array(Character("A")...Character("Z"))
//["A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"]
よく使う文字セットを定義しておく
struct AsciiChars {
static let chars: ClosedRange<Character> = Character(0)...Character(127)
static let printable: ClosedRange<Character> = " "..."~"
static let number: ClosedRange<Character> = "0"..."9"
static let uppercase: ClosedRange<Character> = "A"..."Z"
static let lowercase: ClosedRange<Character> = "a"..."z"
}
extension Character {
init(_ value: UInt8) { self.init(UnicodeScalar(value)) }
var isPrintable: Bool { AsciiChars.printable.contains(self) }
}
func stride(from: Character, to: Character) -> StrideThrough<Character> { stride(from: from, through: to, by: 1) }
func stride(from: Character, downTo: Character) -> StrideThrough<Character> { stride(from: from, through: downTo, by: -1) }
例
for c in AsciiChars.uppercase {
print(c, terminator: " ")
}
//A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
print(String(Array(AsciiChars.lowercase)))
//abcdefghijklmnopqrstuvwxyz
for c in (Character("S")...Character("U")).reversed() {
print(c, terminator: " ")
}
//U T S
for c in stride(from: Character("z"), downTo: Character("v")) {
print(c, terminator: " ")
}
//z y x w v
CharacterSet型を使う
CharacterSetは、標準でいくつか 文字セットされています。
主な文字セット
CharacterSet.alphanumerics
CharacterSet.capitalizedLetters
CharacterSet.decimalDigits
CharacterSet.lowercaseLetters
CharacterSet.uppercaseLetters
CharacterSet.punctuationCharacters
CharacterSet.symbols
CharacterSet.newlines
CharacterSet.whitespaces
CharacterSet.whitespacesAndNewlines
しかし、Sequenceに準拠していないので、for文で使えません。
for c in CharacterSet.alphanumerics {
// ^ error: for-in loop requires 'CharacterSet' to conform to 'Sequence'
}
直接、準拠させたいところですが、7ビットのASCIIコード限定ということもあり、Sequence に準拠したラッパーを作成することで実現します。
extension CharacterSet {
struct ASCIICharacterIterator: IteratorProtocol {
private var current = 0
let set: CharacterSet
init(set: CharacterSet) {
self.set = set
}
mutating func next() -> Character? {
while current < 128 {
let value = current
current += 1
if let scalar = UnicodeScalar(value), set.contains(scalar) {
return Character(scalar)
}
}
return nil
}
}
struct ASCIICharacterSequence: Sequence {
let set: CharacterSet
func makeIterator() -> ASCIICharacterIterator {
ASCIICharacterIterator(set: set)
}
}
var asciiCharacters: ASCIICharacterSequence {
ASCIICharacterSequence(set: self)
}
}
for c in CharacterSet.alphanumerics.asciiCharacters {
print(c, terminator: " ")
}
//0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z
ClosedRange<Character>では表現できない(文字コードが連続していない)文字セットをイテレートできるので、こちらの方が 汎用性が高いです。
目的
使う頻度は少ないと思いますが、Character型をイテレートできると便利です。
おまけ
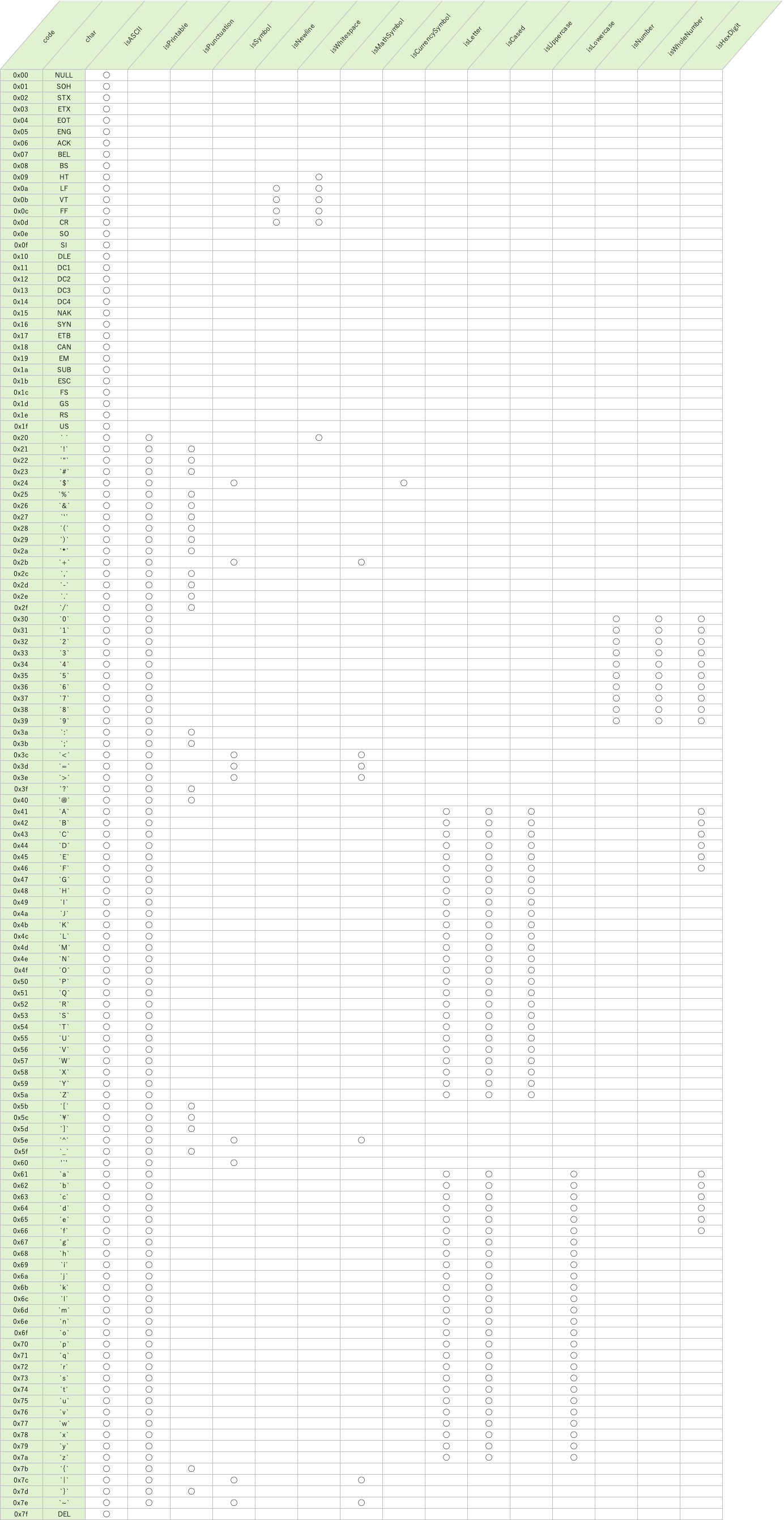
Character.isXXXX の結果を一覧表にしました。
| 凡例 ◯ : true |
|---|
 |
以上、ご参考まで。