Happy Elements 株式会社 カカリアスタジオ Advent Calendar 2016 の 7 日目です.本日の担当はインフラグループの @nagizero です.よろしくお願いします.
成果物
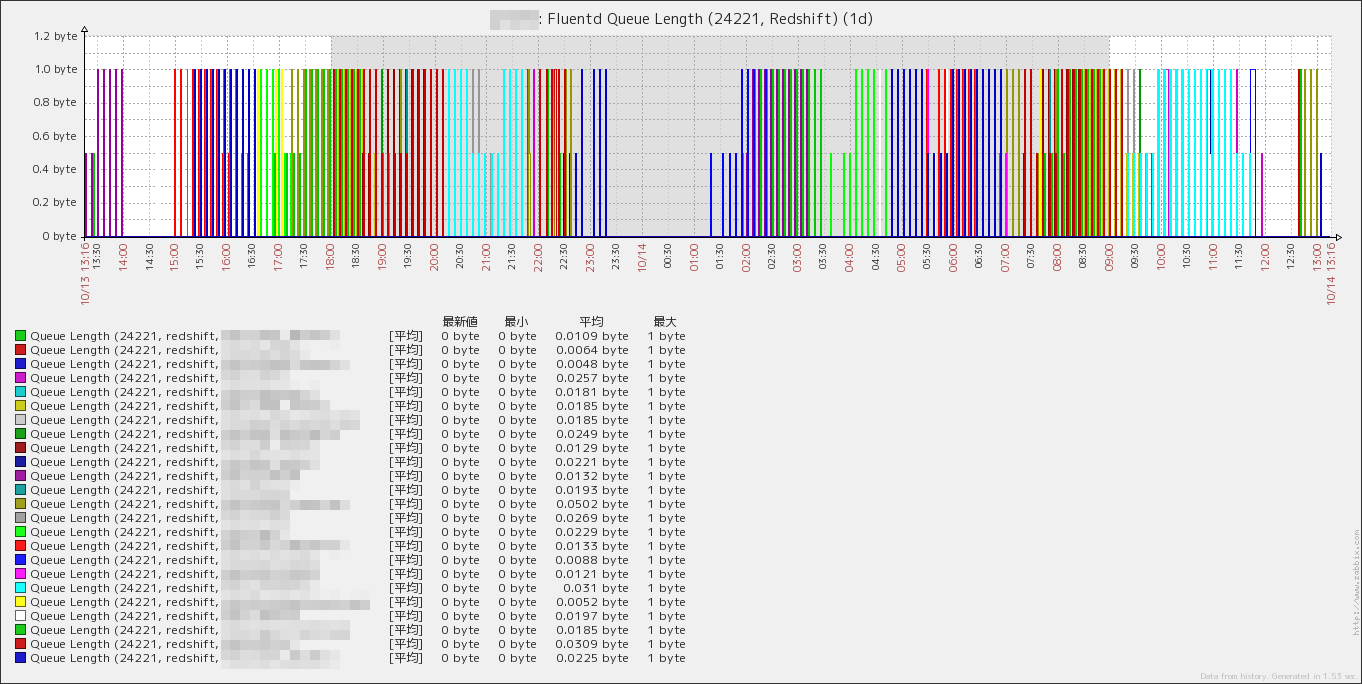
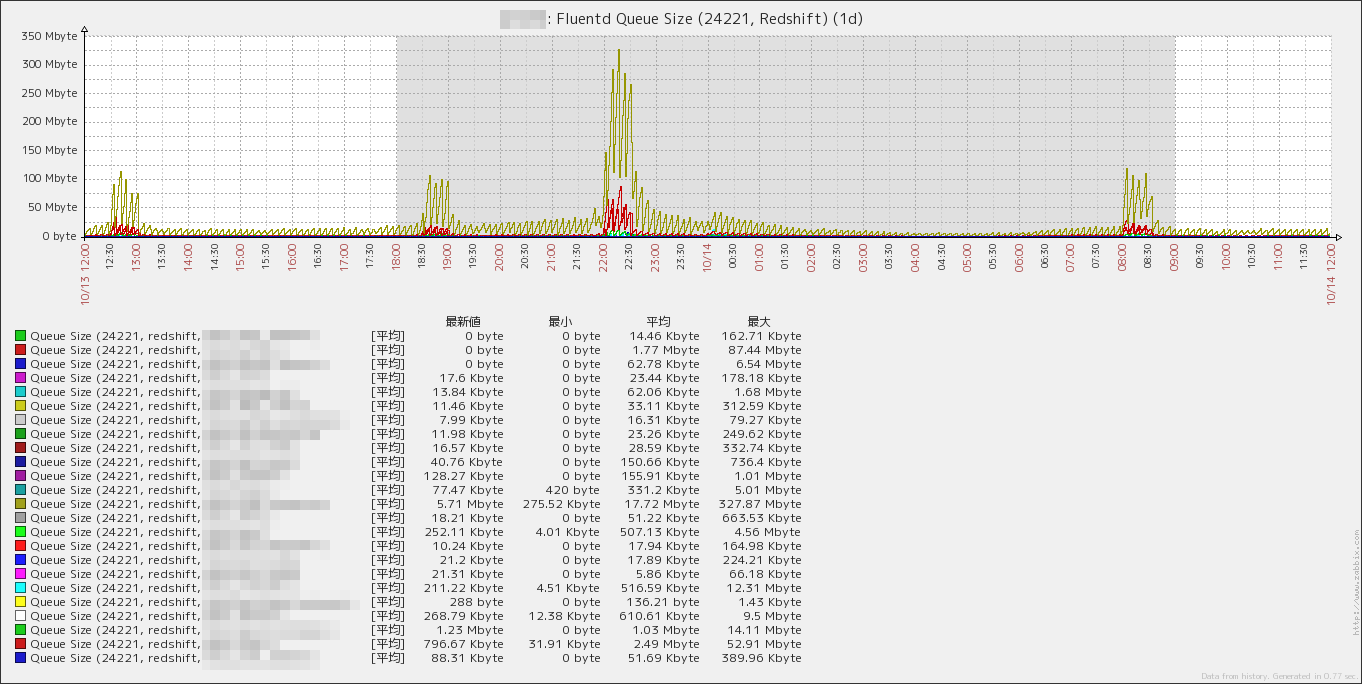
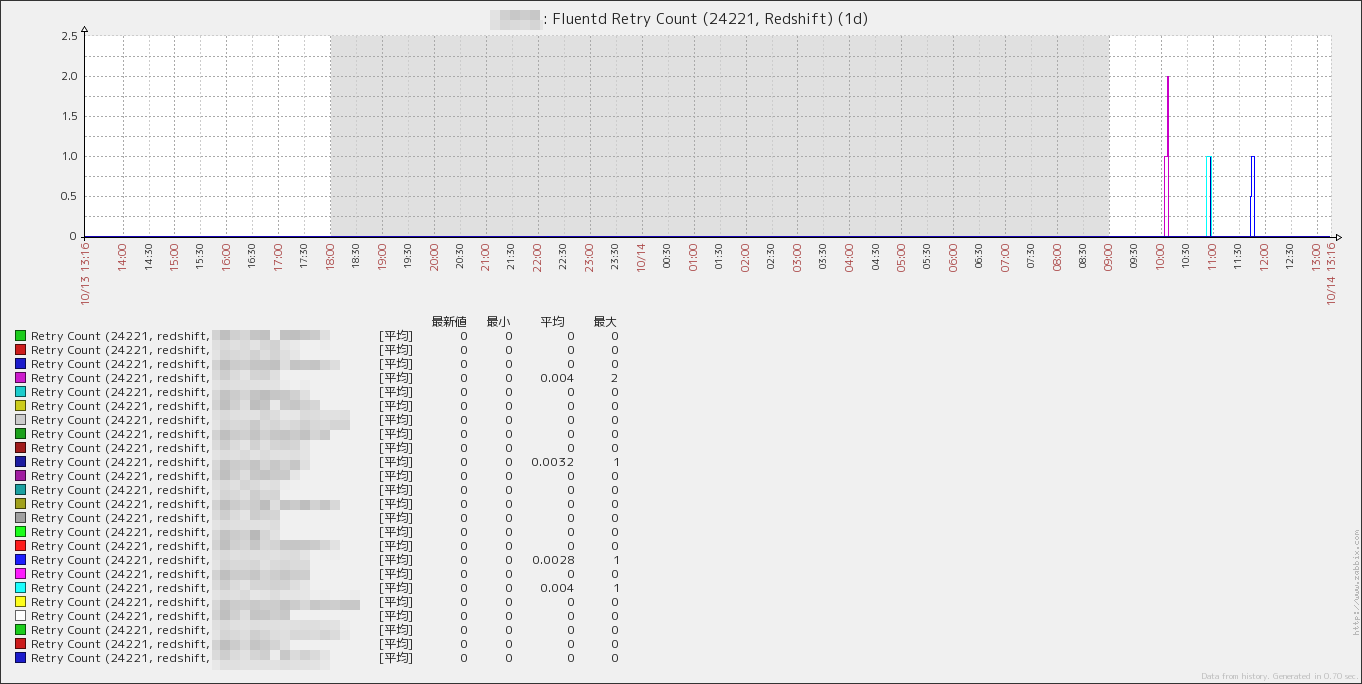
fluentd のキュー状況を表す時系列グラフを作成しました.
背景
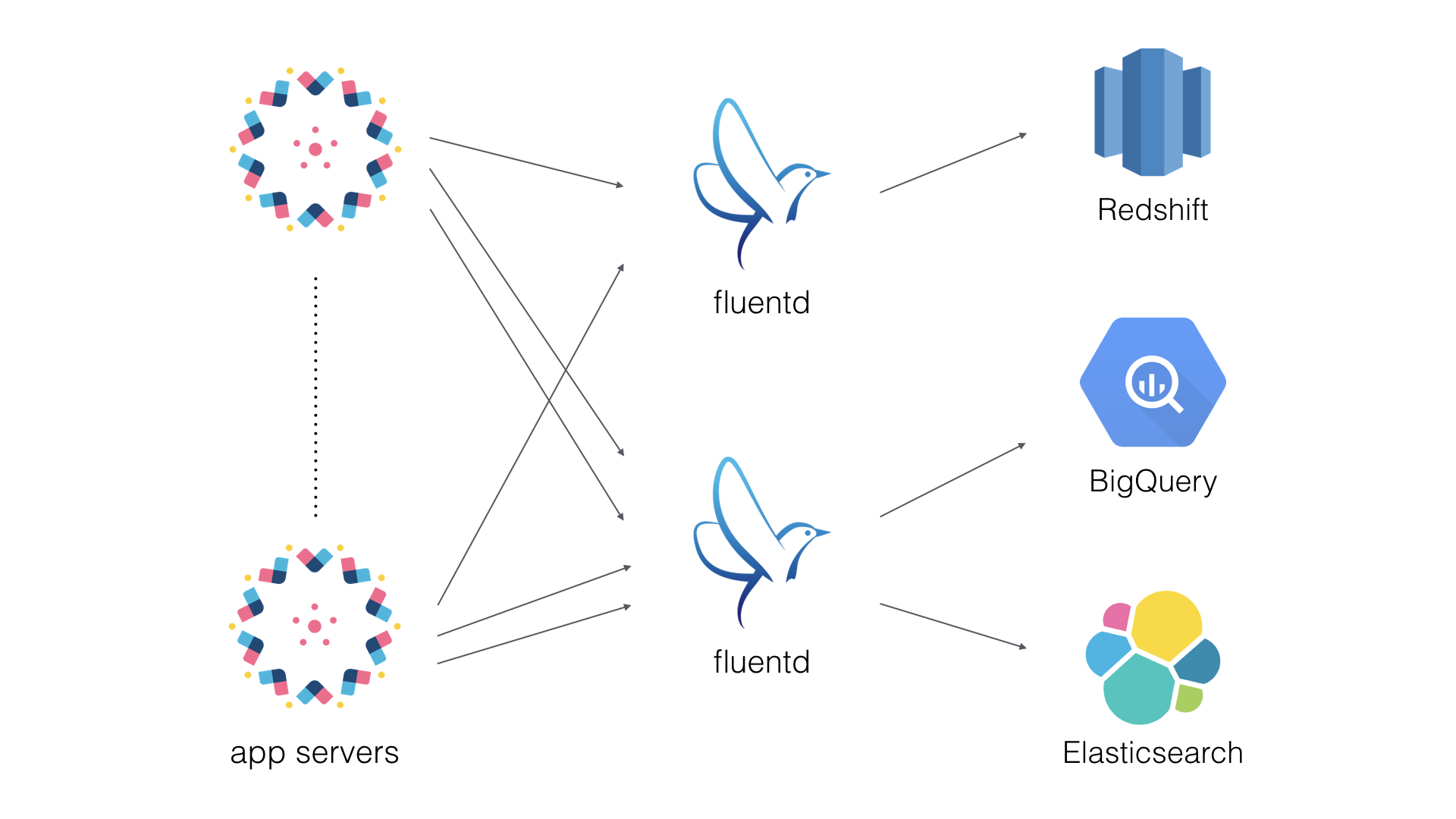
- fluentd を利用して複数のアプリケーションサーバのログを集約サーバ 2 台に転送している
- 集約サーバ 1 は Redshift へログを転送
- 集約サーバ 2 は BigQuery, Elasticsearch へログを転送
- fluentd の集約サーバは 2 つのポートで稼働している
- 24221
- 24222
- ログの転送先 (Redshift, BigQuery, Elasticsearch) によってテーブル名が異なる
- テーブル名は運用中に変更される可能性がある
- fluentd の集約サーバのキュー状況をざっと確認したい
- ログの転送処理が滞っていないか,バッファが溢れていないか
- メモリバッファのプロセスが OOM-Killer に殺されてしまう前に気付きたい
- 時系列グラフで一覧表示できるとよい
- 監視したい項目は転送先 × テーブル毎に 3 点ずつ
- キューの長さ (Queue Length)
- キューのサイズ (Queue Size)
- 転送のリトライ回数 (Retry Count)
- 監視には Zabbix を用いたい
方針
- fluentd のキュー状況の取得には monitoring agent を用いる
- テーブル名の変更やテーブルの追加に柔軟に対応できる作りとする
- Low-level discovery (LLD) を利用してテーブル名を自動で取得・登録する
- LLD で登録したテーブル名について,監視項目の値を自動で取得する
- 取得した値をグラフ化して確認できるようにする
- 望ましい形式のグラフを自動生成することができないため,グラフ関連の処理は手動で行う
- 生成したグラフをスクリーンにまとめて確認できるようにする
ToDo
fluentd 集約サーバ
- Monitoring agent を導入する
- Zabbix で用いるスクリプトを作成する
- fluentd の転送先テーブル名を取得するスクリプト
- 指定した転送先テーブルに関する値を取得するスクリプト
- キューの長さ
- キューのサイズ
- 転送のリトライ回数
- Zabbix agent にスクリプトを組み込む
Zabbix サーバ
- Zabbix agent 経由で fluentd 集約サーバからデータを取得する
Zabbix Web UI
- fluentd 集約サーバ用のテンプレートを作成する
- 作成したテンプレートを元に fluentd のデータを取得する
- 取得したデータをもとにグラフを作成する
- 作成したグラフをまとめてスクリーンを作成する
fluentd 集約サーバ
Monitoring agent の導入
Monitoring Fluentd に詳しいです.この API を叩いてキューの値を取得します.
転送先テーブル名を取得するスクリプトの作成
Monitoring agent の API から得られる JSON を下記のように整形します. Zabbix LLD で利用する JSON は data オブジェクトと配列で構成されている必要があります.
{
"data": [
{
"{#TABLE_NAME}": "foo"
},
{
"{#TABLE_NAME}": "bar"
}
]
}
上記の形式をデータを出力するスクリプトを作成します. JSON の整形には jq コマンドを利用します.例えば下記のように書けるでしょう.
# !/bin/bash
##
# $1: 24221 or 24222
#
PORT=$1
##
# $2: redshift or bigquery or elasticsearch
#
TYPE=$2
curl -s "localhost:${PORT}/api/plugins.json" | /usr/local/bin/jq ".plugins[] | select(.type==\"${TYPE}\") | {\"{#TABLE_NAME}\":(.config.redshift_tablename // .config.table // .config.type_name)}" | /usr/local/bin/jq --slurp "{data:.}"
このスクリプトの引数に fluentd のポート番号 とログの転送先 を指定して実行すると転送先テーブルの一覧が得られます.
$ /etc/zabbix/zabbix_discovery/fluentd.queue.discovery.sh 24221 redshift
指定したテーブルに関する値を取得するスクリプトの作成
テーブル名を取得できたので,今度は取得したテーブルのキュー状況を出力するスクリプトを作成します.
# !/bin/bash
##
# $1: 24221 or 24222
#
PORT=$1
##
# $2: redshift or bigquery or elasticsearch
#
TYPE=$2
##
# $3: target table
#
TABLE=$3
##
# $4: buffer_queue_length or buffer_total_queued_size or retry_count
#
VALUE=$4
curl -s "localhost:${PORT}/api/plugins.json" | /usr/local/bin/jq ".plugins[] | select(.type==\"${TYPE}\" and (.config.redshift_tablename // .config.table // .config.type_name)==\"${TABLE}\") | .${VALUE}"
引数に fluentd のポート番号,ログの転送先,テーブル名,取得したい値を指定して実行すれば OK です.
## キューの長さ
$ /etc/zabbix/zabbix_discovery/fluentd.queue.get.sh 24221 redshift foo buffer_queue_length
0
## キューのサイズ
$ /etc/zabbix/zabbix_discovery/fluentd.queue.get.sh 24221 redshift foo buffer_total_queued_size
255002
## 転送リトライ回数
$ /etc/zabbix/zabbix_discovery/fluentd.queue.get.sh 24221 redshift foo retry_count
0
Zabbix agent の設定
作成した 2 つのスクリプトを Zabbix agent に組み込みます.キー fluentd.queue.discovery および fluentd.queue.get として値を取得できるように設定します.
##
# $1: 24221 or 24222
# $2: redshift or bigquery or elasticsearch
#
UserParameter=fluentd.queue.discovery[*],/etc/zabbix/zabbix_discovery/fluentd.queue.discovery.sh $1 $2
##
# $1: 24221 or 24222
# $2: redshift or bigquery or elasticsearch
# $3: target table
# $4: buffer_queue_length or buffer_total_queued_size or retry_count
#
UserParameter=fluentd.queue.get[*],/etc/zabbix/zabbix_discovery/fluentd.queue.get.sh $1 $2 $3 $4
# service zabbix-agent restart
Zabbix サーバ
fluentd 集約サーバで稼働している Zabbix agent に問い合わせて, fluentd.queue.discovery および fluentd.queue.get を取得できることを確認します.
$ zabbix_get -s hostname -k fluentd.queue.discovery[24221,redshift]
{
"data": [
{
"{#TABLE_NAME}": "foo"
},
{
"{#TABLE_NAME}": "bar"
},
.
.
.
]
}
$ zabbix_get -s hostname -k fluentd.queue.get[24221,redshift,foo,buffer_queue_length]
0
Zabbix Web UI
fluentd 集約サーバ用テンプレートの作成
適当なテンプレートを作成して LLD を紐付けていきます.
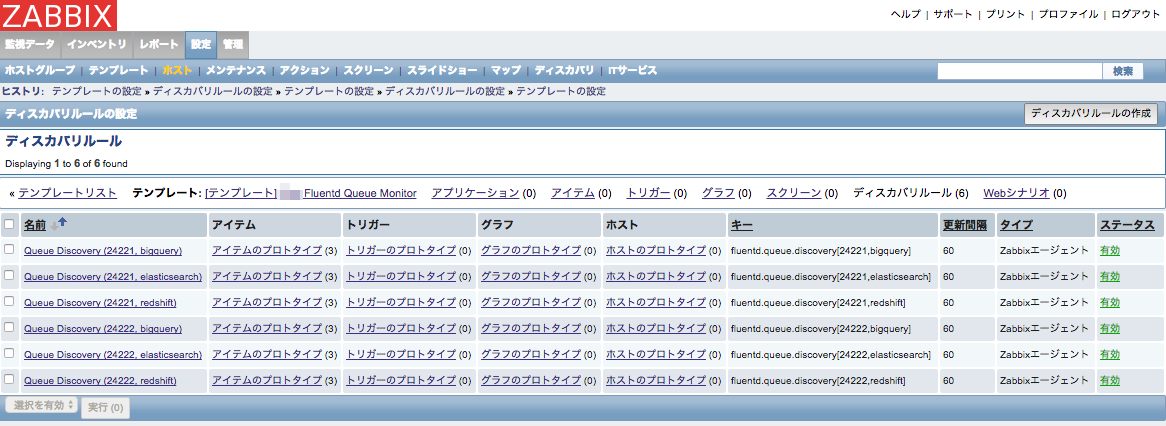
まず,テンプレートに ディスカバリルール を設定します.これは fluentd の宛先のテーブル名一覧を取得するためです.下図の通り,キーに fluentd.queue.discovery を指定します. fluentd 稼働ポート数 2 (24221, 24222) × ログの転送先の種類 3 (Redshift, BigQuery, Elasticsearch) = 6 通りのディスカバリルール を設定します.これでログの転送先ごとのテーブル名一覧が取得できるようになります.
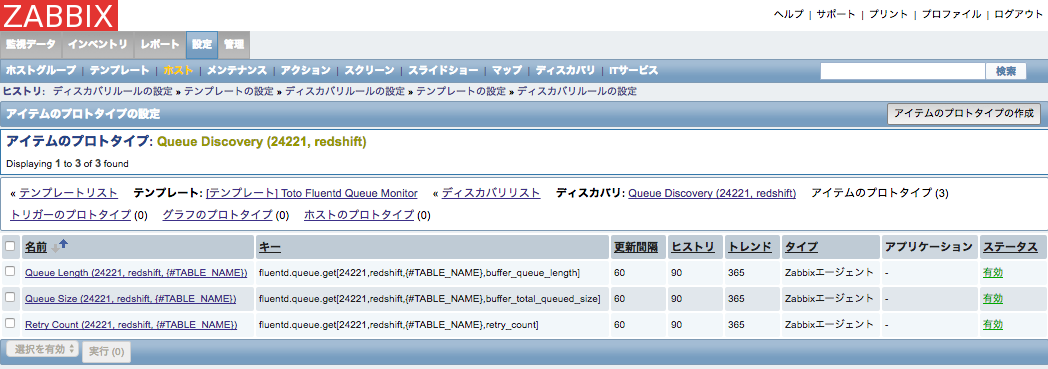
次に,各ディスカバリルールについて アイテムのプロトタイプ を設定します.キューの長さ,キューのサイズ,転送のリトライ回数を取得するため, アイテムのプロトタイプはディスカバリルール毎に 3 つ 必要となります.下図の通り,キーに fluentd.queue.get を指定します. {#TABLE_NAME} にはディスカバリルールで取得したテーブル名が格納されるため,すべての転送先テーブルについて自動で値が取得されるようになります.
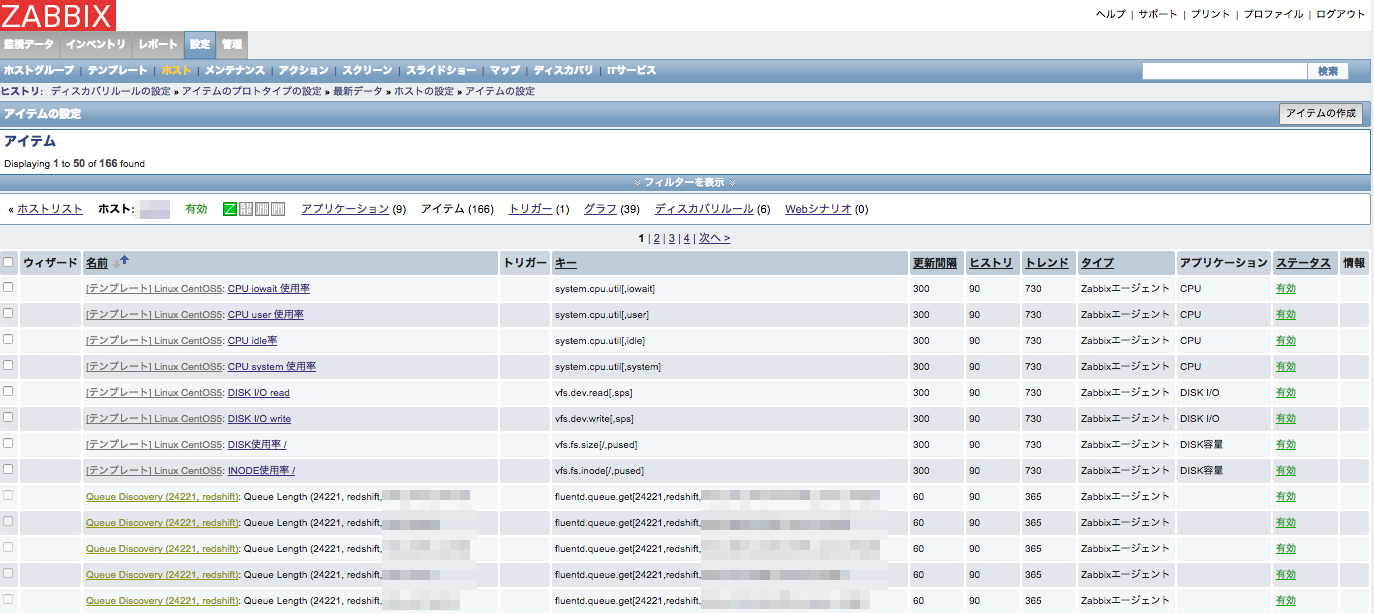
ディスカバリルールとアイテムのプロトタイプを設定したので,下図のように自動で値が取得されるようになります.名前の先頭に黄色の文字 (下図では Queue Discovery (24221, redshift)) が付いている項目がディスカバリルールによって自動で取得された値を示しています.
グラフの作成
LLD で自動取得したデータを用いてグラフを作成します.下図のような複数の同一項目を一纏めにしたグラフは自動では作成できないため,手作業でデータを選択する必要があります1.運用中にテーブルの追加やテーブル名の変更が生じた場合は,手作業でグラフの項目を修正する必要があります.
スクリーンの作成
当初の目的である「集約サーバのキュー状況をざっと確認したい」を実現するため,全グラフをまとめたスクリーンを作成して完了です.お疲れ様でした.
-
ディスカバリルールでグラフのプロトタイプとして定義できればよいのですが,古くから要望されていながら実現されていない機能の一つだそうです.今のところは API を叩いて独自に実装する他ありません ↩