GANとは
GAN(Generative Adversarial Networks)とは、訓練データを学習し、
それらに似た新しいデータを生成するモデルのことで、生成モデルと呼ばれるネットワークの一種です。
DCGAN(Deep Convolutional GAN)とは、
CNN(Convolutional Neural Network)を使ったGANのことです。
GANの仕組み
GANではgenerator(画像生成器)とdiscriminator(識別器)という2つのネットワークを使用します。
generatorではノイズから正解データに似た画像を生成し、
discriminator(識別器)を通して、それらが訓練データか、generatorによって生成されたデータかを識別します。
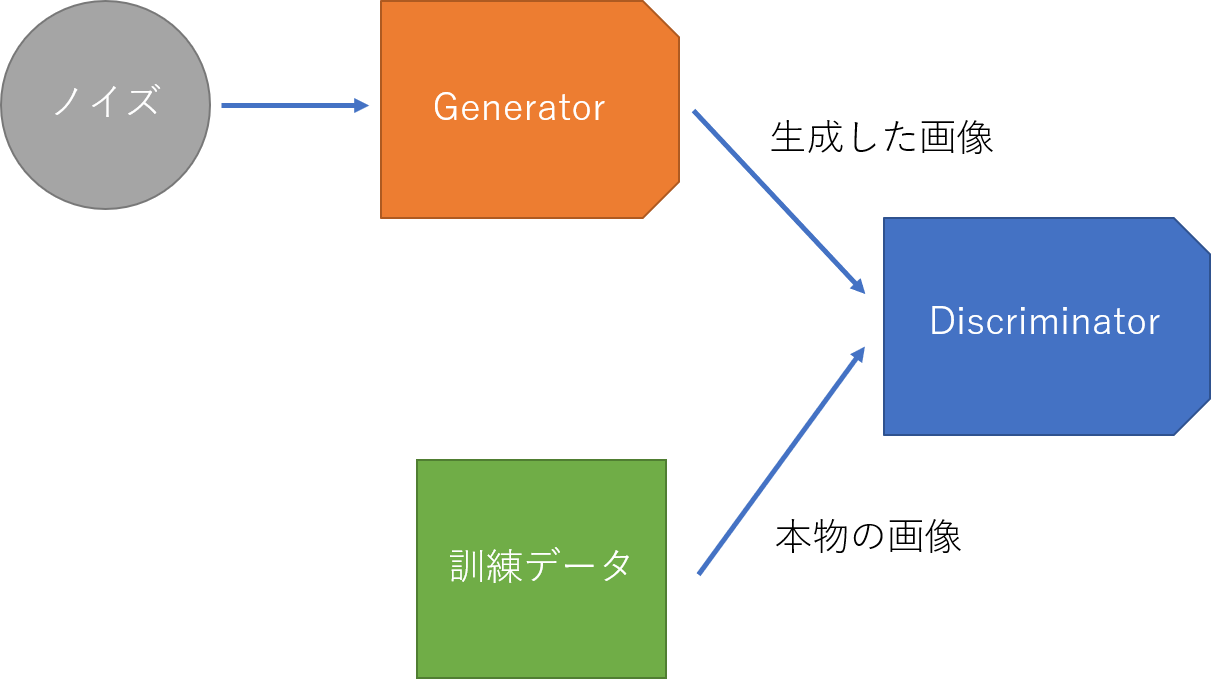
discriminatorでは訓練データのラベルが「1」、生成したデータのラベルが「0」と識別されるよう学習していきますが、
generatorでは、生成したデータをdiscriminatorに通したときに、
出力が「1」に近づく(生成データが訓練データと判断される)ように学習していきます。
最終的にdiscriminatorの正答率が「50%」になれば、訓練データと見分けがつかないデータを生成できていることになります。
この関係は、よく紙幣の偽造者と警察の関係に例えられます。
偽造者はなるべく本物の紙幣に似ている紙幣を造ろうとし、警察はそれらを本物の紙幣と見分けようとします。
次第に警察の能力が上がり、本物と偽造紙幣をうまく見分けられるようになれば、
偽造者は、更に本物に近い偽造紙幣を造るようになります。
最終的に偽造者は、本物と区別が付かない偽造紙幣を製造できるようになる…ということですね。
実際にやってみる
今回の訓練データはこちらです。
また、実装に関してはこちらの記事を参考にさせていただきました。
以下、今回実装したコードになります。
①まずは必要なライブラリをインポートします。
from keras.models import Sequential
from keras.layers import Dense, Activation, Reshape
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers import Flatten, Dropout
from keras.preprocessing.image import img_to_array, load_img
from keras.optimizers import Adam
import math
import numpy as np
import os
from PIL import Image
②generatorとdiscriminatorを作成します。
def generator_model():
model = Sequential()
model.add(Dense(input_dim=100, units=1024))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(32 * 32 * 128))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Reshape((32, 32, 128), input_shape=(32 * 32 * 128,)))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(64, (5, 5), padding="same"))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(3, (5, 5), padding="same"))
model.add(Activation('tanh'))
return model
generatorでは2x2のアップサンプリング(転置畳み込み)を2回行っているので、最終的な画像サイズは4倍になることに注意が必要です。
今回、訓練データの画像サイズは128×128のため、128÷4=32を最初のノードに設定しています。
def discriminator_model():
model = Sequential()
model.add(Conv2D(64, (5,5), strides=(2, 2), input_shape=(128, 128, 3), padding="same"))
model.add(LeakyReLU(0.2))
model.add(Conv2D(128, (5,5), strides=(2, 2)))
model.add(LeakyReLU(0.2))
model.add(Flatten())
model.add(Dense(256))
model.add(LeakyReLU(0.2))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
input_shapeのみ対応する画像サイズに変更する必要があります。
また、出力層を除いて活性化関数にLeaky ReLUを使用しているのも特徴です。
③生成画像を並べて表示するための関数を用意します。(※必須ではありません。)
def combine_images(generated_images):
total = generated_images.shape[0]
cols = int(math.sqrt(total))
rows = math.ceil(float(total)/cols)
width, height, ch= generated_images.shape[1:]
output_shape = (
height * rows,
width * cols,
ch
)
combined_image = np.zeros(output_shape)
for index, image in enumerate(generated_images):
i = int(index/cols)
j = index % cols
combined_image[width*i:width*(i+1), height*j:height*(j+1)] = image[:, :, :]
return combined_image
④最後に学習部分を作成します。
def train():
# 訓練データ読み込み
img_list = os.listdir(TRAIN_IMAGE_PATH)
X_train = []
for img in img_list:
img = img_to_array(load_img(TRAIN_IMAGE_PATH+img, target_size=(128,128,3)))
# -1から1の範囲に正規化
img = (img.astype(np.float32) - 127.5)/127.5
X_train.append(img)
# 4Dテンソルに変換(データの個数, 128, 128, 3)
X_train = np.array(X_train)
# generatorとdiscriminatorを作成
discriminator = discriminator_model()
d_opt = Adam(lr=1e-5, beta_1=0.1)
discriminator.compile(loss='binary_crossentropy', optimizer=d_opt)
# discriminatorの重みを固定(dcganの中のみ)
discriminator.trainable = False
generator = generator_model()
dcgan = Sequential([generator, discriminator])
g_opt = Adam(lr=2e-4, beta_1=0.5)
dcgan.compile(loss='binary_crossentropy', optimizer=g_opt)
num_batches = int(X_train.shape[0] / BATCH_SIZE)
print('Number of batches:', num_batches)
for epoch in range(NUM_EPOCH):
for index in range(num_batches):
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
generated_images = generator.predict(noise, verbose=0, batch_size=BATCH_SIZE)
# 生成画像を出力
if (index+1) % (num_batches) == 0:
image = combine_images(generated_images)
image = image*127.5 + 127.5
if not os.path.exists(GENERATED_IMAGE_PATH):
os.mkdir(GENERATED_IMAGE_PATH)
Image.fromarray(image.astype(np.uint8))\
.save(GENERATED_IMAGE_PATH+"%04d_%04d.png" % (epoch, index))
# discriminatorを更新
X = np.concatenate((image_batch, generated_images))
# 訓練データのラベルが1、生成画像のラベルが0になるよう学習する
y = [1]*BATCH_SIZE + [0]*BATCH_SIZE
d_loss = discriminator.train_on_batch(X, y)
# generator更新
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
# 生成画像をdiscriminatorにいれたときに
# 出力が1に近くなる(訓練画像と識別される確率が高くなる)ように学習する
g_loss = dcgan.train_on_batch(noise, [1]*BATCH_SIZE)
print("epoch: %d, batch: %d, g_loss: %f, d_loss: %f" % (epoch, index, g_loss, d_loss))
generator.save_weights('generator.h5')
discriminator.save_weights('discriminator.h5')
これで実装は完了です。
画像のパスやバッチサイズなどは自由に設定してください。
結果
epoch = 1

epoch = 100

epoch = 200

epoch = 600

epoch = 1000

思いのほか猫っぽくなりましたね。
まとめ
今回初めてDCGANを触ってみました。
DCGANを任意の画像でやろうとすると処理が重たいので、CPU環境ではMNISTなどで試すのがオススメです。
細かい理論についてはまだ詰め切れていない部分があるので、またの機会に。
参考リンク
はじめてのGAN
GANについて概念から実装まで ~DCGANによるキルミーベイベー生成~
GAN(論文)
DCGAN(論文)