2022年の自動運転モデルBEVFormerをGPUクラウドサービスの NVIDIA H200 で動かしてみました。上記は H200×2 で24エポック学習した BEVFormer-tiny の推論結果です。 左の12面はサラウンド6カメラを上下2段に並べたもので、上段6枚=モデルの予測(PRED)/下段6枚=正解(GT)。各カメラ画像には検出した3D物体を投影しており、枠の色は物体クラス(車・バス・バリアなど)に対応します。右は同じ瞬間の鳥瞰図(BEV、自車中心 ±51.2m)で、青=予測・緑=正解のボックスを重ねたもの。背景の点群は高さで色分けした参考用の LiDAR です(BEVFormer はカメラ映像だけで推論しており、LiDAR は答え合わせの参照に過ぎません)。上段の予測が下段の正解とよく重なり、BEV でも青と緑がほぼ一致しているのが、本記事で再現した精度の中身です。
前回の記事(RTX4060 で自動運転モデル BEVFormer を動かしてみた)では、手元の RTX 4060 Ti 16GB で BEVFormer を「とにかく動かす」ところまでをやりました。推論と数エポックの学習疎通までは確認できましたが、論文と同じ精度を出すための本格的な学習(nuScenes trainval を24エポック)は、家庭用GPUでは現実的な時間で終わりません。この記事はその続きで、クラウドGPU(H200×2)を借りて BEVFormer-tiny をフル学習させ、論文値を再現できるかを確認した記録になります。ローカルで「動く」ことを確認したモデルを、より大きなGPUへ持っていって「論文精度を出す」段階に進めた、という位置づけです。
結論(先に)
- BEVFormer-tiny を H200 SXM ×2(NVLink)で24エポックの DDP 学習させ、nuScenes trainval val(6,019フレーム)で mAP 0.2705 / NDS 0.3832 を得ました。公式論文値(mAP 0.252 / NDS 0.354)を mAP +7.4% / NDS +8.2% 上回る水準です。
- 学習は 実質エポック21で収束していました。22〜24エポックはほぼ確認フェーズで、21エポックで打ち切れば2〜3割のコスト削減ができたという実用的な知見が得られました。
- 一番時間を溶かしたのは学習そのものではなく、自作Dockerイメージが RunPod 上で起動すらしない問題でした。原因はGPUでもモデルでもなく、ベースイメージの起動挙動でした。
- H200(Hopper)特有の難所は、カスタムCUDAカーネルの再ビルドです。Deformable Attention のカーネルは prebuilt に sm_90 が無く、しかも誤っていても落ちずに精度だけ崩れるため、推論で論文値を再現できるかを健全性チェックにしました。
- DDP のスケーリング効率は ×2 で 約90%。VRAM はまったく余っており(実使用 約3.5GB に対して GPU1枚あたり 141GB)、H200 を選んだ意味は容量ではなく学習時間の短縮にありました。
なぜ H200×2 をクラウドで借りたのか
前回の RTX 4060 Ti でも推論と短い学習は動きました。ただ、論文と同じ条件(nuScenes trainval、24エポック)でフル学習しようとすると、試算で120時間を超えます。家庭の電力事情と現実的な納期を考えると、ローカルで回し続けるのは無理がありました。
ここで意外だったのは、VRAM容量は理由にならなかったことです。BEVFormer-tiny は推論でも学習でも数GB程度しか使わず、H200 の 141GB はまったくの過剰です。それでもデータセンターGPUを選んだのは、ひとえに1エポックあたりの時間を短くして、24エポックを現実的な日数に収めたいという理由でした。容量ではなく、メモリ帯域と演算スループットを買いに行った、という整理になります。
クラウドGPU業者は複数の選択肢があります(RunPod、Lambda、Vast.ai、CoreWeave、GMO など)。価格や在庫は変動が激しいので、検討時には各社の最新情報を確認することをおすすめします。今回 RunPod を選んだのは次の理由からです。
| 観点 | RunPod を選んだ理由 |
|---|---|
| GPUの種類 | H200 に加えて B200 も扱っており、第3弾(B200編)まで同じ環境で続けられる |
| ストレージ | 占有のネットワークストレージ領域(Network Volume)を確保でき、387GBのデータセットを毎回転送し直さずに済む |
| 自動化 | CLI と API が用意されており、Pod の起動・学習・後処理・削除をスクリプトで回せる |
Dockerイメージが「起動すらしない」
第1弾では Apptainer(SIF単一ファイル)で環境を固めましたが、RunPod は Docker ベースなので、bevformer.def を Dockerfile に書き直すところから始めました。nvidia/cuda:11.8.0-devel-ubuntu22.04 をベースに、第1弾の12パッチをそのまま引き継ぎ、Hopper(sm_90)対応のため TORCH_CUDA_ARCH_LIST="8.9;9.0" でビルドして Docker Hub に push しました。手元(KVM上のVM)でCPUビルドして約30分です。
ところが、このイメージを RunPod に載せると Pod が起動した直後に終了し、再起動を無限に繰り返す(restart loop) という状態になりました。手元では docker run -it で問題なく動いていたので、最初は原因がまったく見えませんでした。
切り分けに丸2日近くを溶かして分かった原因は、拍子抜けするものでした。nvidia/cuda:* 系イメージの CMD は /bin/bash です。手元では -it で疑似TTYが付くので bash は起動したまま待機しますが、RunPod の Pod 起動時はTTYが無いため、bash が即座に exit します。Pod 側はこれを「コンテナが異常終了した」とみなして再起動し、それが延々と繰り返されていた、というわけです。
# 手元では -it が付くので bash が居座る(露見しない)
docker run -it nabe2030/bevformer:cu118-pt201 # OK
# Pod 起動は TTY 無し → CMD の bash が即 exit → restart loop
解決は、ベースイメージを runpod/pytorch:* に置き換えることでした。このイメージは sshd と sleep infinity が組み込まれていて、TTYが無くても落ちません。
# Before: TTY 無しで即落ちする
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04
# After: sshd + sleep infinity 内蔵で常駐する
FROM runpod/pytorch:2.0.1-py3.10-cuda11.8.0-devel-ubuntu22.04
教訓としては、ローカルの docker run -it で動く=クラウドのPodで動く、ではないということです。コンテナの「起動後に何で常駐するか」は、TTYの有無で挙動が変わります。クラウド前提なら、常駐プロセスを持つベースを選ぶか、自前で sleep infinity 相当を仕込むのが安全だと思います。
もうひとつの難所:カスタムCUDAカーネルをHopperで正しく動かす
Docker が起動するようになっても、次の関門がありました。GPUのアーキテクチャに合わせて、カスタムCUDAカーネルをビルドし直す必要があることです。これが H200(Hopper)で動かすうえで、もっとも神経を使った部分でした。
第1弾で説明したとおり、BEVFormer の中核である Deformable Attention は、mmcv-full のカスタムCUDAカーネル ms_deform_attn_forward に依存しています。問題は、配布されている mmcv-full の prebuilt wheel に、新しい世代のGPU向けのバイナリが入っていないことです。RTX 4060 Ti(sm_89)までは PTX のフォワード互換で「一応動いて」しまいますが、H200(Hopper, sm_90)向けのカーネルは含まれていません。そのため、sm_90 を明示してソースからビルドし直す必要があります。
# prebuilt を避け、sm_89(RTX)と sm_90(Hopper)の両方を明示してソースビルド
TORCH_CUDA_ARCH_LIST="8.9;9.0" MMCV_WITH_OPS=1 FORCE_CUDA=1 \
pip install mmcv-full==1.7.2 --no-binary mmcv-full
ここで厄介なのは、ビルドが通っても、カーネルが silent に誤った結果を返しうることです。普通のバグなら例外やアサートで落ちてくれるので気づけますが、カスタムCUDA opは、対応していないアーキ上で「落ちずに、ただ精度だけが崩れる」という壊れ方をすることがあります。エラーが出ない以上、テストしない限り気づけません(実際、後の Blackwell 向けに別バージョンを用意したときに、この silent failure を踏みました)。
そこで本記事では、いきなり本学習に入る前に、公式の学習済み重みで論文値を再現できるかを先に確認しました(次節)。推論で論文と同じ mAP/NDS が出れば、Deformable Attention のカーネルが H200 上で正しく動いている、とメトリクスで保証できます。「移植が正しいか」を、目視ではなく数値で担保する、という考え方です。
この「カーネルを新アーキ向けに正しく再ビルドし、メトリクスで健全性を確認する」という手順は、より新しい Blackwell(sm_100 系)を扱う第3弾で、さらに切実になります。
RunPod での動作手順とデータ転送
起動できるようになった後の手順です。
ネットワークストレージ(Volume)。 nuScenes trainval は約387GBあります。Podは使い捨てなので、データセットとチェックポイントは占有のネットワークストレージ領域(Volume、今回は1TB)に置き、Podからマウントする構成にしました。Volumeを使う場合、RunPodではPodと同じデータセンター(リージョン)でしか確保できない点に注意が必要です。後述のGPU在庫難と合わせて、リージョンのピン留めが地味に効いてきます。
データ転送。 最初、手元のWindowsからVolumeへnuScenesを直接アップロードしようとしたら、1.21MB/sしか出ず、387GBでは非現実的でした。そこで発想を変えて、nuScenes公式の配信元(AWS S3/CloudFront)から、Pod側で aria2c を使って並列ダウンロードしたところ、990Mbpsまで出て、10分割のtar.gzを約20分で取得できました。データは「手元から押し込む」より「クラウド内で公式元から引く」ほうが速い、という当たり前ですが見落としがちな話です。
# 手元から直アップ:1.21MB/s(遅すぎて断念)
# Pod 側で公式元から並列 DL:約 990Mbps
aria2c -x16 -s16 -i nuscenes_urls.txt # -x/-s で接続を並列化
Podライフサイクルの自動化。 GPU時間はそのまま課金なので、起動・学習・後処理・削除を6本のスクリプトで自動化し、異常終了時には trap でPodを自動削除して孤児Pod(消し忘れて課金が続くPod)を防ぐようにしました。ひとつ罠があって、/exit で抜けると SIGKILL が飛ぶため trap が発火しません。意図せずPodが残り続けるので、終了はスクリプト経由に統一しました。
推論の動作確認と、本番学習の結果
推論の確認。 前節で触れたカーネルの健全性チェックを兼ねて、本番学習の前に、公式の学習済み重み bevformer_tiny_epoch_24.pth を nuScenes trainval val(6,019フレーム)で評価し、論文値を再現できるか確認しました。このとき H200 SXM ×1 が在庫切れだったので、H100 SXM 80GB にフォールバックしています。両者は sm_90(Hopper)で同一アーキテクチャなので、再ビルドしたカーネルもそのまま使え、mAP/NDS は等価で、所要時間だけがメモリ帯域比で前後します。結果は論文値(mAP 0.252 / NDS 0.354)に対して±2%以内で再現でき、約25分・約$1.5で済みました。カーネルが H200/H100 上で正しく動いていることが、これで数値的に確認できました。
なお前回のmini split(404フレーム)での評価値(mAP 0.2647 / NDS 0.3252)とは、評価対象のデータが違うため直接比較できません。miniは学習データの一部をvalに使うので、trainval valの数値とは別物として見る必要があります。
本番学習。 推論が通ったので、本命の学習に進みました。H200 SXM ×2(NVLink接続、合計約282GB HBM3e) を確保し、tools/dist_train.sh で --nproc_per_node=2 の DDP 学習を起動しました。設定は公式の bevformer_tiny.py をそのまま使い、24エポック、samples_per_gpu=1(実効バッチ2)、各エポック末に val 6,019フレームでの評価を自動実行しています。
学習トラジェクトリの後半(収束していく区間)を抜き出すと、次のとおりです(全24エポックは後掲のグラフを参照)。
| Epoch | end loss | mAP | NDS | lr | 備考 |
|---|---|---|---|---|---|
| 16 | 5.23 | 0.2483 | 0.3560 | 6e-05 | NDS が論文値(0.354)に到達 |
| 17 | 5.16 | 0.2594 | 0.3645 | 5e-05 | mAP も論文値(0.252)を超過 |
| 18 | 4.85 | 0.2600 | 0.3719 | 4e-05 | 両指標とも論文値を上回る |
| 19 | 4.79 | 0.2615 | 0.3725 | 3e-05 | NDS は緩やかに上昇 |
| 20 | 4.61 | 0.2616 | 0.3771 | 2e-05 | 連続して上昇継続 |
| 21 | 4.42 | 0.2688 | 0.3836 | 1e-05 | NDS がほぼピークに到達 |
| 22 | 4.39 | 0.2695 | 0.3827 | 1e-05 | 以降はノイズ範囲 |
| 23 | 4.49 | 0.2688 | 0.3825 | 0.0 | 微変動 |
| 24 | 4.30 | 0.2705 | 0.3832 | 0.0 | 最終 |
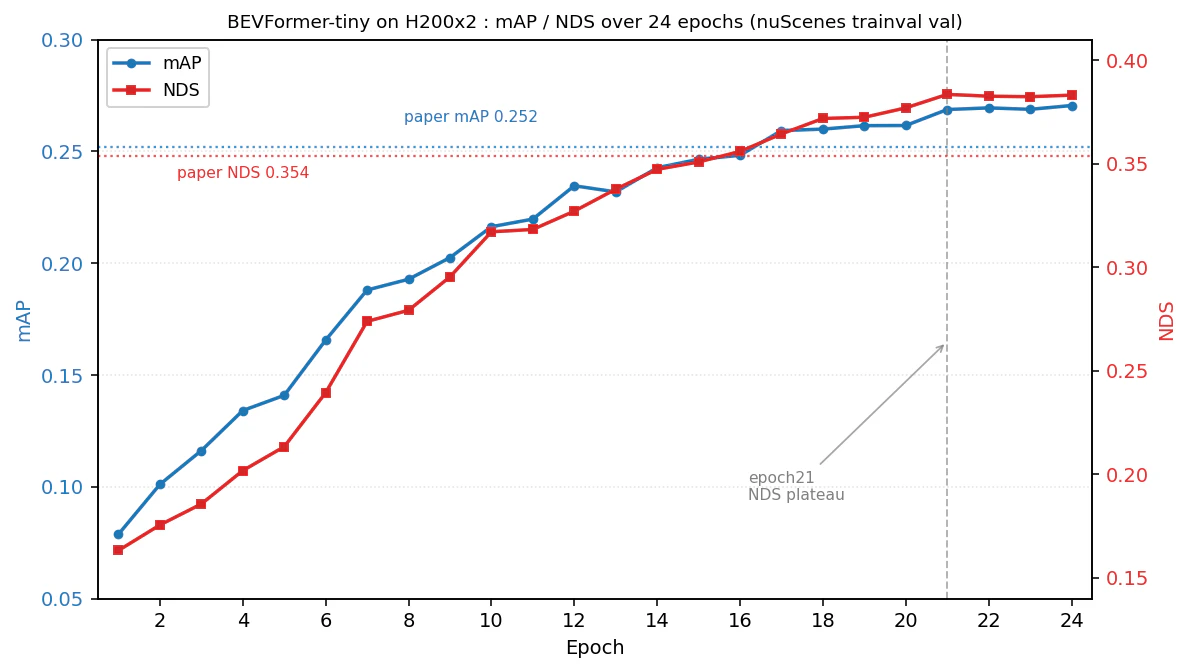
24エポック分の実測値。点線は論文値(mAP 0.252 / NDS 0.354)で、おおむねepoch16〜17で追い抜いています。NDSはepoch21あたりでほぼ頭打ちになり、以降はノイズ範囲に収まっています。
最終的に mAP 0.2705 / NDS 0.3832 で着地し、論文値(mAP 0.252 / NDS 0.354)の 107% / 108%(mAP +7.4% / NDS +8.2%)にあたります。
学習曲線を見て分かったことが二つあります。ひとつは収束の早さです。NDSはepoch16〜17で論文値を追い抜き、その後も緩やかに上昇して、epoch21でほぼ頭打ちになります。epoch22以降はmAP・NDSとも0.001程度のノイズ範囲でしか動いていません。学習率(lr)は段階的に落とすのではなく、warmup後に滑らかに減衰してepoch23〜24で実質ゼロになる連続的なスケジュールで、NDSの頭打ちはこのlrが十分に小さくなった時点と重なっています。実用上の含意は明確で、epoch21(約30時間)で打ち切れば、ほぼ同じ精度をより短時間・低コストで得られたということです。残りの22〜24は確認フェーズに過ぎず、次回以降の学習では「21エポック打ち切り」という選択肢が取れ、2〜3割のコスト削減につながります。
もうひとつは、epoch17〜18の段階で既に論文の24エポック値を上回っていたことです。DDPのスケーリング効率が×2で約90%出ていたことと、データ・スケジューリングとの相性の良さが効いているように思います。
学習時間は約46時間、RunPodでの実費は複数回チャージの合算で総額およそ$170でした(※H200×2のオンデマンド単価はリージョン・在庫で変動するので、コストは実際の請求で最終確認するのが安全です)。
まとめと次回
- BEVFormer-tiny を H200×2 で24エポック学習し、論文値を7〜8%上回る精度を再現できました。クラウドGPUに載せれば、2022年スタックのモデルでも論文精度まで素直に到達できます。
- 一番のハマりは学習ではなくDockerイメージの起動挙動で、「ローカルで動く≠クラウドで動く」を体で学びました。
- 21エポック打ち切りで十分という収束の早さ、**DDP約90%**のスケーリング効率は、次に同種の学習を回す人に効く実用知見だと思います。
次回(第3弾)は、最新世代の NVIDIA Blackwell B200 で同じモデルを動かし、性能の解析に踏み込みます。第1弾で触れた Deformable Attention の「少数点をgatherして補間する」性質が、ここで効いてきます。密な行列積ではないこの演算は、最新GPUのTensor Coreをうまく使えず、GPUを新しくしても素直には速くならない——その理由を、実測とともに掘り下げる予定です。あわせて、再現用のDockerイメージ配布もそちらで扱います。
おまけ:ハマりどころ小ネタ集
- Docker Hub のリポジトリが Private だと、Podは無言で起動失敗する。 pull access denied がCLIやAPIのログに出ず、Web Consoleのシステムログを見て初めて分かりました。リポジトリをPublicにしたら即解決。起動失敗の原因がイメージの中身とは限りません。
-
SSHセッションはDockerのENVを継承しない。
PATHとPYTHONPATHが引き継がれず、SSH越しのコマンドでpythonやモジュールが見つからない事故が起きます。SSHコマンド側で明示的に前置きする必要があります。 -
nuscenes-devkit の dict_keys 問題(Issue #1155)。
class_names = class_range.keys()がPython 3.8のmultiprocessingでpickle不可になるので、list(...)で包む小パッチが要ります。 - データは「手元から押す」より「クラウド内で公式元から引く」が速い。 1.21MB/s → 990Mbps。
-
/exitは SIGKILL なのでtrapが発火しない。 孤児Podが課金され続けるので、終了はスクリプト経由で。