
BEVFormer による3D物体検出の出力例。左上段が6カメラへの検出ボックス投影、右が鳥瞰図(BEV)上の予測と点群。※この可視化は次回記事(H200×2)で生成したものです
自動運転の認識モデルを、論文公開当時ではなく「いまの環境」で動かそうとすると、たいてい依存関係の壁にぶつかります。BEVFormer(ECCV 2022)もその典型で、公式が指定する PyTorch 1.9 / mmcv-full 1.4.0 / mmdet3d 0.17.1 という組み合わせは、2026年のGPUとCUDAでは素直に再現できません。
この記事は、その BEVFormer を手元の RTX4060Ti/16GB で動かすまでの記録です。何が難しくて、どこをどう回避したのか、そして最終的に Apptainer のイメージとして固めて再利用できるようにするまでを、順を追って書いていきます。
私自身は自動運転の研究者ではなく、ラボでGPU計算環境を運用しているエンジニアの立場です。なので「モデルの中身を深く論じる」よりも、「古いコードを現代のハードで動かす」という移植作業の視点が中心になります。同じように、少し古い研究コードを手元の環境で動かしたい方の参考になればと思います。
なお、この記事は連載の第1弾です。BEVFormer を題材に、次のような順序で進める予定です。
- 第1弾(本記事) RTX 4060 Ti でのローカル動作検証
- 第2弾(予定) クラウドGPU(H200)での学習と精度の確認
- 第3弾(予定) 最新GPU(B200)での性能の解析
ローカルの小さなGPUで「動くこと」を確認してから、徐々に大きなGPUへ持っていく流れです。本記事はその出発点にあたります。
BEVFormer とは
BEVFormer は、複数のカメラ画像から鳥瞰図(Bird's-Eye-View, BEV)の空間表現を作り、その上で3D物体検出などを行う、自動運転の認識モデルです。上海AI研究所と南京大学のグループによる ECCV 2022 の論文で、被引用も多く、その後のBEV系認識モデルの起点のひとつになっています。
ポイントは「カメラだけ」で3D認識を行うところです。LiDARを使わず、車両の周囲に取り付けた6台のカメラ画像を入力として、車や歩行者などの位置を3次元的に推定します。
全体の構成
BEVFormer の処理は、おおまかに4つの段階に分けて捉えると分かりやすいと思います。
- 特徴抽出 各カメラ画像から、Backbone(ResNet系)と FPN で画像特徴を取り出します。
- BEVエンコーダ ここが中核です。BEV空間に並べた「クエリ」が、6台のカメラ特徴を参照しながら、鳥瞰図上の表現を組み立てます。後述する2種類のAttentionが使われます。
- 検出ヘッド DETR系のクエリベース検出で、BEV表現から物体を出力します。
- 後処理 NMSを使わないデコード(NMSFreeCoder)で最終的な検出結果にまとめます。
2段階目のBEVエンコーダには、2つのAttentionがあります。
- Spatial Cross-Attention BEV上の各クエリが、6台のカメラ画像のうち「自分が映っているはずの場所」の特徴を参照します。鳥瞰図の各地点と、カメラ画像上の対応領域を結びつける役割です。
- Temporal Self-Attention 過去フレームのBEV特徴を参照します。これにより、一瞬隠れた物体や動いている物体に対しても、時間方向の情報を使って安定した認識ができるようになります。
この2つのAttentionが、いずれも次に説明する Deformable Attention という仕組みの上に成り立っています。

BEVFormer の全体構成。6カメラ画像から特徴を抽出し、BEVエンコーダの2つのAttentionで鳥瞰図表現を作り、検出ヘッドで3D物体を出力する
Deformable Attention — なぜ少ない計算で済むのか
通常のAttentionは、あるクエリが対象(キー)の「すべて」に対して重みを計算します。画像のように要素数が多いと、この総当たりの計算量が重くのしかかります。
Deformable Attention は、この発想を変えます。クエリは対象の全体ではなく、少数の参照点(サンプリング点)だけに注目します。しかもその参照点の位置は固定ではなく、入力に応じて動的にずらして(deform して)決められます。各参照点の特徴は、特徴マップ上の連続的な座標から bilinear補間 で取り出します。
つまり「全部を見る」のではなく「見るべき少数の点を選んで、そこだけを補間で拾う」という方式です。これによって、高解像度の特徴マップに対しても計算量を抑えられます。BEVFormer がカメラ6台ぶんの特徴をBEV空間に集約できるのは、この効率の良さに支えられている部分が大きいと思います。
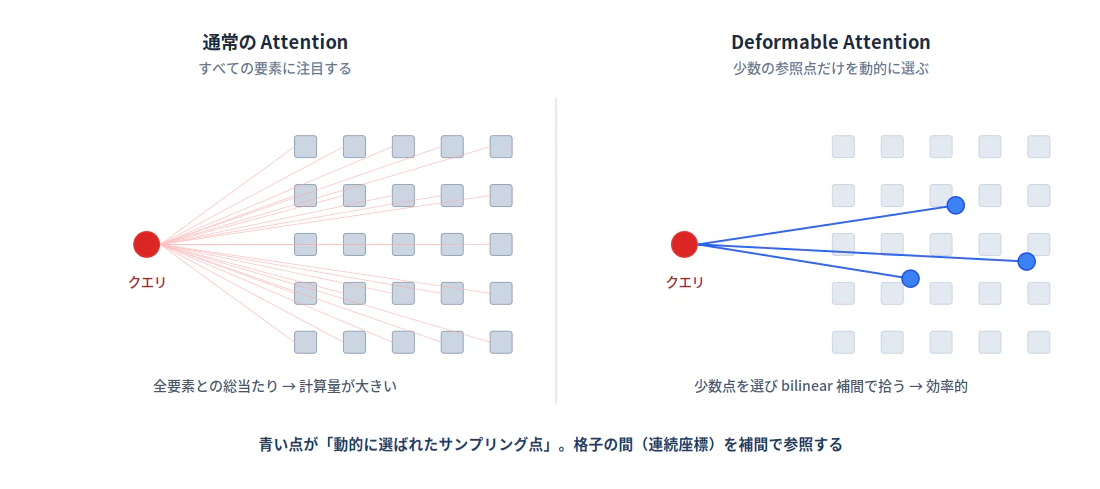
通常のAttention(左)は全要素に総当たりするのに対し、Deformable Attention(右)は少数の参照点を動的に選び、格子の間の連続座標を補間で参照する
実装上は、この演算は mmcv-full 内のCUDAカーネル ms_deform_attn_forward として提供されており、BEVFormer は mmcv._ext 経由でこれを呼び出します。Spatial Cross-Attention・Temporal Self-Attention の両方が、このカーネルに依存しています。
ここで一点だけ補足しておきます。この「少数の点を選んで補間で拾う」という性質は、効率の源であると同時に、最新GPUの性能を語るうえでも効いてきます。というのも、この演算は密な行列積とは計算の形が違うため、GPUを新しくしても期待ほど速くならない、という現象につながります。ただ、その話は学習や性能測定を扱う次回以降の記事で詳しく触れる予定です。本記事では「Deformable Attention はこういう仕組みで効率を稼いでいる」という理解までで十分です。
何が難しいのか
BEVFormer を手元で動かすうえで難しいのは、モデルそのものではなく、依存しているソフトウェアスタックが2022年当時のままで、現代の環境と噛み合わないことです。具体的には、次のような層で問題が重なります。
OpenMMLab 旧世代への全面依存
BEVFormer は OpenMMLab の旧世代、すなわち mmcv 1.x / mmdet 2.x / mmdet3d 0.x の上に作られています。これらはすでにメンテナンスが終了していて、後継の mmcv 2.x + mmengine では mmcv.runner や mmcv.parallel といったAPIが削除されています。
このコードベースは旧APIへの依存が広範で、import 箇所だけで29ファイル・76箇所に及びます。つまり「とりあえず pip で現行版を入れる」では動きません。かといって公式指定の古いバージョンは、今度はGPUやCUDAと合いません。
PyTorch / CUDA の世代ギャップ
公式が指定する PyTorch 1.9.1+cu111 は CUDA 11.1 向けで、手元のホスト環境(CUDA 13.1)とは互換性がありません。中間的な torch 1.13.1+cu118 も、すでにPyPIや配布URLから取得できなくなっていました。
このため、PyTorch 自体を新しめのバージョンに上げる必要がありますが、上げると今度は mmcv 側の互換が問題になります。古いものに合わせれば動かず、新しいものに合わせれば別の場所が壊れる、という板挟みです。
削除されたC++ヘッダ(THC/THC.h)
mmdet3d のCUDA拡張のうち、点群系のいくつかのソースが、PyTorch 2.0 で削除された THC/THC.h ヘッダと THCState 型を参照しています。これらが残っているとビルドが通りません。BEVFormer の推論パスで直接使うわけではない拡張も含まれますが、mmdet3d をソースビルドする以上、これらもコンパイルを通す必要があります。
Python・numpy・numba の古さ
公式指定は Python 3.8 で、これに紐づく numpy 1.19.5 / numba 0.48.0 もかなり古い世代です。Python 3.8 自体が2024年10月にサポート終了しており、Ubuntu 25.10 のシステムPythonは 3.13 です。システムにそのまま入れるのは現実的ではなく、環境を隔離する前提になります。
まとめると
難しさの本質は、個々の問題というより「これらが互いに絡み合っている」ことだと思います。PyTorchを上げればmmcvを上げる必要があり、mmcvを上げればバージョンチェックに引っかかり、CUDAを新しくすればビルドが通らない、という連鎖です。
そこで本記事では、ホスト環境を汚さずに、必要なバージョンの組み合わせを丸ごと隔離して固める方法をとりました。次章以降で、その環境(ハードとソフト)と、隔離の手段として選んだ Apptainer、そして実際に当てたパッチを順に説明していきます。
環境
今回の検証に使ったマシンは次のとおりです。
| 項目 | 内容 |
|---|---|
| GPU | NVIDIA RTX 4060 Ti 16GB(Ada Lovelace, sm_89) |
| OS | Ubuntu 25.10 |
| ホストCUDA | 13.1(ドライバ同梱) |
| コンテナ内CUDA | 11.8(後述) |
GPUは16GBで、データセンター向けではなくコンシューマ向けのグラフィック・カードです。それでも BEVFormer の中でも一番軽い bevformer_tiny であれば、推論はもちろん、小規模な学習の動作確認まで収まります。より大きい bevformer_small も推論は可能でした。
なお、このGPUノードは普段は電源を落としておき、ジョブを投げたときだけ Wake-on-LAN で起動して、終わったら自動で停止する、という省電力運用をしています。ジョブ管理には Slurm を使っていますが、この部分はラボ固有の構成で話が広がるため、別記事で改めて取り上げる予定です。本記事では「GPUノードに対してジョブを投げて実行した」程度の理解で読み進めてもらえれば大丈夫です。
ここで一つ問題になるのが、ホストのCUDAが 13.1 と新しいことです。前章で触れたとおり、BEVFormer が必要とする mmcv-full は CUDA 13.1 の nvcc でのコンパイルを想定していません。そのまま新しいCUDAでソースビルドしようとすると、C++ ABIやCUDA APIの違いでエラーになる可能性が高いです。
この食い違いを、次に説明する Apptainer のコンテナと、CUDAの前方互換性で解消します。
なぜ Apptainer か
依存を隔離する手段としては Docker が一般的ですが、今回は Apptainer を選びました。理由はいくつかあります。
| Apptainer の利点 | 留意点 | |
|---|---|---|
| 権限 | デーモン不要・root不要で実行できる | ビルド時は fakeroot 等の設定が要る |
| 配布 | イメージが SIF という単一ファイルになり、持ち運び・公開がしやすい | サイズは数GBになる |
| HPC適性 | Slurm など計算ジョブ環境と相性が良い | GPU利用には --nv 指定が必要 |
| 汎用性 | HPC系のGPUクラウドでもそのまま使える流儀 | Docker前提の手順は読み替えが要る |
特に効いたのが、SIFという単一ファイルで環境が完結する点です。15回以上ビルドを繰り返してようやく通った環境を、最終的に1つのファイルに固めておけば、後から同じものを再現するのも、他のマシンへ持っていくのも簡単になります。
CUDA前方互換性で世代差を吸収する
Apptainer を使ううえで鍵になったのが、コンテナの中では古いCUDA(11.8)を使い、GPUドライバはホスト側の新しいもの(CUDA 13.1世代)を借りるという構成です。
NVIDIAのGPUドライバには前方互換性があり、新しいドライバは古いCUDAランタイムで作られたプログラムを動かせます。これを利用すると、次のような役割分担ができます。
- ビルドと実行(コンテナ内) mmcv-full が想定する CUDA 11.8 でコンパイル・実行する
- GPUドライバ(ホスト) Ubuntu 25.10 が持つ新しいドライバをそのまま使う
つまり「mmcv が嫌がる新しいCUDAでビルドする」という事態を避けつつ、最新ドライバの恩恵は受ける、という形にできます。前章で挙げた「CUDA 13.1 とのギャップ」は、この前方互換性で回避しました。
ビルドの核心 — 何を入れて、どこにパッチを当てたか
ここが本記事の山場です。Apptainer の定義ファイル(.def)に、動く組み合わせを封入し、必要なパッチを当てていきます。
バージョンの組み立て
公式指定のままでは動かないので、PyTorch 2.0系を軸に、mmcv系をそれに合う最終バージョンへ引き上げました。引き上げにはメリットと引き換えのリスクがあります。
| 観点 | 引き上げで得たもの | 引き換えのリスク |
|---|---|---|
| mmcv-full 1.4.0 → 1.7.2 | PyTorch 2.0対応のプリビルドが使え、1.x系のAPI互換は保たれる | 1.x系の最終版であり、これ以上は上げられない |
| mmdet 2.14.0 → 2.28.2 | mmcv 1.7.2 をサポートする範囲に収まる | 2.14.0からAPIが変わった箇所で実行時エラーの可能性 |
| mmseg 0.14.1 → 0.30.0 | mmcv 1.7.x をサポート | 同上、組み合わせ依存 |
| PyTorch 1.9.1 → 2.0.1+cu118 | pipインデックスから取得でき、CUDA 11.8で動く | 一部の非推奨API警告が出る |
最終的なソフトスタックは次のようになりました。
| パッケージ | 採用バージョン |
|---|---|
| Python | 3.8(conda隔離) |
| PyTorch | 2.0.1+cu118 |
| mmcv-full | 1.7.2 |
| mmdet | 2.28.2 |
| mmsegmentation | 0.30.0 |
| mmdet3d | v0.17.1(ソースビルド+パッチ) |
| numpy | 1.24.4 |
| numba | 0.57.1 |
mmcv-full 1.7.2 は、PyTorch 2.0 / CUDA 11.8 向けのプリビルドホイールが配布されているため、ms_deform_attn_forward を含むCUDAカーネルをソースから組み直さずに済みました。これは作業量の面でかなり助かった点です。
パッチ1: mmdet3d のバージョンチェック緩和
mmdet3d v0.17.1 は、起動時に mmcv のバージョンが範囲内かをチェックします。デフォルトでは上限が 1.4.0 に設定されていて、1.7.2 を入れると弾かれます。ここを緩和します。
# mmdet3d の __init__.py で mmcv 上限バージョンを 1.4.0 → 1.8.0 に書き換える
sed -i "s/mmcv_maximum_version = '1.4.0'/mmcv_maximum_version = '1.8.0'/" \
mmdet3d/__init__.py # バージョン範囲チェックを通すための最小限の変更
mmdet(2.28.2)と mmseg(0.30.0)については、mmdet3d 側の要求範囲(mmdet は 2.14.0以上3.0.0未満、mmseg は 0.14.1以上1.0.0未満)に収まっているため、追加のパッチは不要でした。
パッチ2: 削除された THC/THC.h の除去
PyTorch 2.0 で THC/THC.h ヘッダと THCState 型が削除されたため、mmdet3d v0.17.1 の点群系CUDA拡張のうち6ファイルがビルドで止まります。該当ファイルは次のとおりです。
| ファイル | 対応 |
|---|---|
ops/ball_query/src/ball_query.cpp |
THC を ATen/cuda/CUDAContext.h に置換 |
ops/knn/src/knn.cpp |
THC の行を削除(ATen include は既存) |
ops/interpolate/src/interpolate.cpp |
THC を ATen/cuda/CUDAContext.h に置換 |
ops/group_points/src/group_points.cpp |
THC を ATen/cuda/CUDAContext.h に置換 |
ops/gather_points/src/gather_points.cpp |
THC の行を削除(ATen include は既存) |
ops/furthest_point_sample/src/furthest_point_sample.cpp |
THC の行を削除+.data<T>() を .data_ptr<T>() に |
幸い、THCState はいずれのファイルでも extern 宣言があるだけで実体としては参照されていなかったため、その行を削除するか、現行のATenのヘッダに置き換えるだけで済みました。furthest_point_sample.cpp だけは、これも PyTorch 2.0 で削除された .data<T>() を .data_ptr<T>() に直す必要がありました。
これらの拡張はBEVFormer の推論パスで直接使うものではありませんが、mmdet3d をソースビルドする以上は全拡張をコンパイルする必要があるため、まとめて通しておきます。
そのほかの細かな調整
上記以外にも、現代のライブラリと噛み合わせるために、いくつかの小さな調整を入れています。代表的なものを挙げます。
- numba の例外モジュールの参照先が変わっているため、
numba.errorsから現行の場所へ向け直す - OpenCV を、ヘッドレス環境で扱いやすい
opencv-python-headlessに差し替える -
setuptoolsを 59.5.0 に固定し、mmdet3d のsetup.py installが新しいビルドシステムで壊れないようにする
このあたりは環境によって出方が変わるので、ビルドのログを見ながら一つずつ潰していく形になりました。全体としては、定義ファイルの作成からビルド成功まで、15回以上の作り直しを経ています。地道ですが、最終的にSIF一つに固まってしまえば、この苦労を繰り返さずに済みます。
動作検証
環境ができたので、実際にBEVFormer を動かして、移植が正しくできているかを確認します。データセットには nuScenes の mini split(10シーン、404サンプル)を使いました。フルの trainval(約350GB)は重いので、まずは小さい mini で「正しく動くこと」を確かめる目的です。
推論
学習済みチェックポイントを使い、bevformer_tiny と bevformer_small で推論・評価を行いました。
# bevformer_tiny の推論・評価(単一GPU)
python tools/test.py \
projects/configs/bevformer/bevformer_tiny.py \
ckpts/bevformer_tiny_epoch_24.pth \
--eval bbox # nuScenes の検出メトリクス(mAP/NDS等)を計算する
評価結果は次のようになりました。
| 指標 | bevformer_tiny | bevformer_small |
|---|---|---|
| mAP | 0.2647 | 0.3544 |
| NDS | 0.3252 | 0.3989 |
| スループット | 約2.9 FPS | 約1.5 FPS |
| VRAM使用量 | 約3.5GB | 約8GB |
ここで数値の読み方に注意が要ります。この mAP / NDS は、論文で報告されている値とは直接比べられません。論文は trainval の val(6,019サンプル)で評価しているのに対し、ここでは mini split の81サンプルだけで評価しているためです。mini split には trailer・construction_vehicle・barrier といったクラスがそもそも含まれず、それらのAPが0として10クラス平均に効いてくるので、数値は低めに出ます。nuScenes mini split での評価結果は、論文値と直接比較できない点に注意が必要ということです。つまりここで確認したいのは「論文と同じ精度が出るか」ではなく、「移植したモデルが破綻なく動き、もっともらしい検出結果を出すか」です。その意味では、tiny / small ともに期待どおりに動作したと言えると思います。VRAMも16GBに対して余裕があり、コンシューマGPUでも推論は十分に回せることが分かりました。
学習パイプラインの疎通
推論だけでなく、学習が回るかどうかも確認しておきます。本格的な学習はクラウドのGPUで行う予定なので、ここでは「パイプラインが通るか」を見る目的で、mini split を使って数エポックだけ回しました。
# bevformer_tiny を nuScenes mini で学習(パイプライン疎通の確認用)
python tools/train.py \
projects/configs/bevformer/bevformer_tiny.py \
--work-dir work_dirs/tiny_mini # ログとチェックポイントの出力先
3エポック回したところ、loss はおおむね 23.1 から 13.5 へと下がっていきました。学習後に val で評価すると NDS は 0.041 とごく低い値ですが、これはデータが少ない mini split を3エポックだけ回した結果として当然で、ここで見たいのは精度ではありません。データの読み込み・前処理・順伝播・逆伝播・最適化という学習の一連の流れが、移植した環境で問題なく動くこと、それが確認できれば目的は達成です。本格的な学習と精度の評価は、次回のクラウドGPU編で扱う予定です。

nuScenes mini を3エポック学習したときの loss 推移。23.10 から 13.47 へ単調に減少し、パッチを当てた各モジュール(Deformable Attention のCUDA演算、データパイプライン、Temporal Self-Attention)を勾配が正しく流れていることを示す
まとめと次回
本記事では、2022年スタックに依存する BEVFormer を、コンシューマGPUの RTX 4060 Ti 16GB(sm_89)で動かすところまでを扱いました。要点を振り返ると次のようになります。
- 難しさはモデルではなく、EOLになった依存スタック(mmcv 1.x / mmdet 2.x / mmdet3d 0.x)と現代のPyTorch・CUDAとの噛み合わせにある
- ホストを汚さず、Apptainer のコンテナに動く組み合わせを隔離し、CUDA前方互換性で世代差を吸収した
- mmcv系のバージョン引き上げ、削除されたTHC/THC.hの除去など、いくつかのパッチでビルドを通した
- mini split で推論(tiny: mAP 0.2647 / NDS 0.3252)と学習パイプラインの疎通を確認した
ここまでで「動くこと」は確認できました。ただし mini split での確認なので、精度そのものはこれからです。次回は、クラウドのGPU(H200)に環境を持っていき、フルに近いデータで学習を回して、論文に近い精度が出るかを見ていく予定です。さらにその先では、最新世代のGPU(B200)を使って、本記事の冒頭で少し触れた「新しいGPUにしても期待ほど速くならないのはなぜか」という性能の話に踏み込んでいきます。