Supershipの名畑です。明治大学の米沢嘉博記念図書館・現代マンガ図書館で開催されている「『ぱふ』の50年とコミティアの40年」記念展、スペース自体は広くはないのですが、紡がれてきた一つの歴史に浸ることができて非常に充実した時間を過ごさせていただきました。
はじめに
これまで動画生成AIに関する以下のような記事を書いてきました。
- Runwayの「Gen-3 Alpha Turbo」のAPIを呼んで動画をAI生成してみた
- 動画生成AIサービス「Dream Machine」をWeb APIで呼び出してみた
- 動画生成AI「Gen-3 Alpha」のImage to Videoで画像を動画に変換してみたらやっぱり自然すぎて恐くなりもした
何度かRunway(社名かつプラットフォーム名)のGen-3-Alphaを取り上げてきました。
Gen-3-AlphaはLip Syncという機能を使って動画上の唇を音声に合わせて動かすことができます。
今回はこの機能を使って、歌に合わせた口パク動画の生成を行います。
最近の機能というわけではなくある程度前からあるものなのですが、備忘も兼ねまして。
アカウント作成
Sign upのページからアカウントを作成済みの前提とします。E-mailアドレスを用いての登録のほかにGoogleアカウント、Appleアカウントも利用できます。EnterpriseプランではSSOも対応しているそうですが使ったことはありません。
料金
Gen-3-Alphaは有料プランでなくては使えませんが、高速版のGen-3-Alpha Turboは無料のFreeプランでも使えます。
私は有料会員ではあるのですが、今回はGen-3-Alpha Turboを用います。理由としては縦長動画が可能だからです。
プラン毎の詳しい違いはpricingをご覧ください。
また、動画の生成、唇の抽出、唇を動かすといったそれぞれにクレジットが必要となるのでご注意ください。
元画像
今回は元となる静止画像を用意して、それを元にしたimage to videoでの生成とします。
以下の画像を使用しました。

Stable Image Ultraで生成したものです。Stable Image Ultraについて詳しくは過去記事「Stability AIの最新サービス「Stable Image Ultra」とStable Diffusionの過去モデル(2022年〜)の生成画像をひたすら比較して進化を実感してみた」
マイク等、画像として気になるところはあるものの、今回の本題としては唇の動きなのでこのまま進めます。
動画の生成
Gen-3では1コマ目(First)と最終コマ(Last)の画像を指定可能です。
今回は顔が途中で画面の外に出てしまうと意味がないため、以下のように最初と最後にあえて同じコマを置きました。
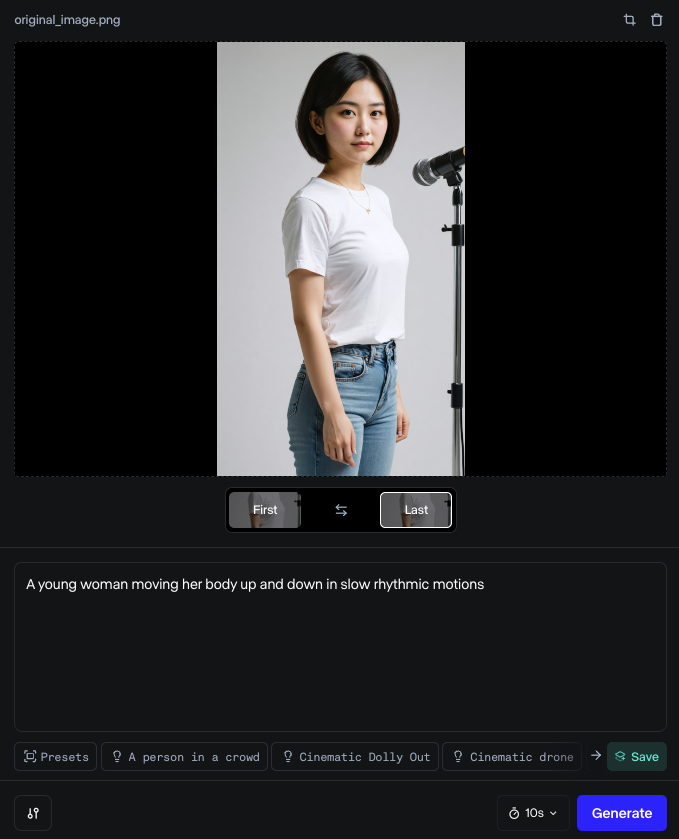
プロンプトには「A young woman moving her body up and down in slow rhythmic motions」と入れました。日本語訳すると「ゆっくりとしたリズミカルな動きで体を上下に動かす若い女性」です。
Generateを押します。
しばらく待つと動画が生成されます。
この時点での動画は以下です。まだもちろん歌も口パクもありません。それにしても、本当に自然。
この動画に対して唇の動きを付加することになります。
そのため、まずは途中段階として、再生して意図通りかを確認します。
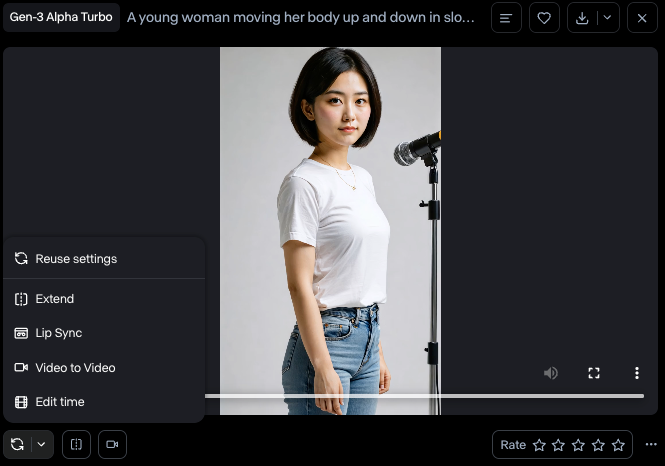
確認後、生成された動画の左下にある円系な二つの矢印のアイコン(Reuse settings)をクリックしてLip syncを選びます。
すると以下のメッセージが出て、動画から唇の抽出が行われます。唇の位置が認識しづらい動画だとここでエラーになって先には進めませんのでご注意ください。
Hang tight! We are detecting a face in your input video. This may take up to 20 seconds.
成功すると次に音声の指定となります。

「読み上げ音声の生成」「読み上げ音声の録音」「音声ファイルのアップロード」のいずれかとなります。
今回は音声ファイルをアップロードしました。音源としては龍崎一さんのINSOMNIAの一部を使用させていただきました。感謝申し上げます。
動画の長さと音声の長さが一致していなくてもGen-3側でループ等による調整はしてくれます。今回も元動画は約10秒で音声は約20秒です。
Generateをして、生成された動画が以下です。
違和感は正直あります。普通の発話ならともかく、歌だと唇の動き的に弱いですし、そもそも声と唇の形がさほど合っていなかったり。
ただ、声に合わせているというのはかなり伝わってきますし、使い所によっては充分に活用できそうです。
反省として、もう少し唇に寄った画像の方がわかりやすかったですね。
最後に
そう遠くない未来にはAI的な違和感がもっと0に近づいているんだろうなと思うと楽しみです。
宣伝
SupershipのQiita Organizationを合わせてご覧いただけますと嬉しいです。他のメンバーの記事も多数あります。
Supershipではプロダクト開発やサービス開発に関わる方を絶賛募集しております。
興味がある方はSupership株式会社 採用サイトよりご確認ください。