先日o1-miniのAPIを触ってましたが推論が入るAPIはレスポンスが遅いですね、何もしないと何秒もユーザーを待たせてしまいます。
LINE Messaging APIのローディングアニメーション機能
今年追加された機能でLINE Botにローディングアニメーションを表示させる機能があります。
POST https://api.line.me/v2/bot/chat/loading/startというエンドポイントです。
メッセージ関連は/v2/bot/messageにいるので/v2/bot/chatって珍しいですね。
現状他にないかも?
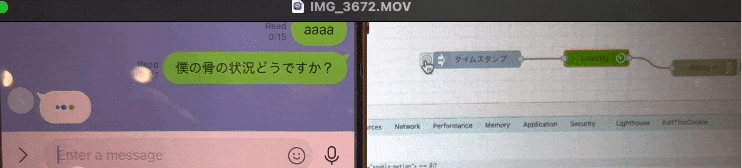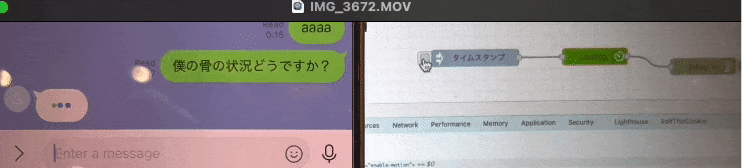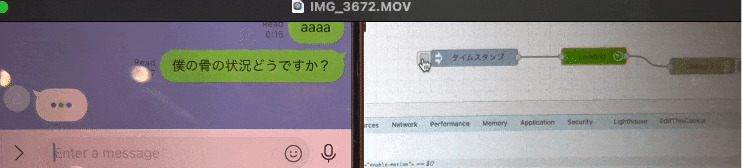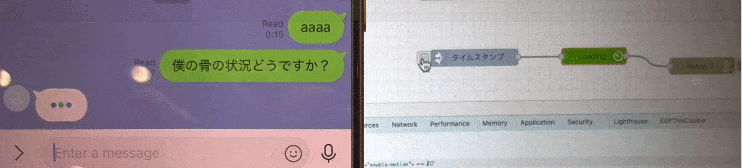
こんな感じで
「・・・(考え中)」 を表現できる様になりました。
実装時の注意 - 現状、個別のみ + 時間指定
Node.jsのSDKでは最近のバージョンでは対応してくれていて、showLoadingAnimation()というメソッドで利用できます。(古いバージョンは分かりません。)
const res = await client.showLoadingAnimation({
chatId: chatId, //現状user idのみ
loadingSeconds: loadingSeconds, //デフォは20らしい
});
注意が必要な点ですが、 現状グループメッセージでは使えず、個別のユーザーとの会話のみ となっています。
また、Pushメッセージを送るときはメッセージオブジェクトに{to: userId}みたいな指定ですが{chatId: userId}という指定です。 toじゃなくてchatIdというキー名なんですね。
また、loadingSecondsにアニメーションの時間を指定しますが、5,10,15と選択式のようです。4秒とか2秒とか刻んだ数字は指定できない模様です。
詳細はドキュメントを見てください。
GPTのAPIと組み合わせたLINE Bot
Node-REDで組んでみました。
node-red-contrib-line-messaging-apiノードのローディング機能を使いつつ試してみます。
o1-miniやo1-previewのAPIを使うと現状レスポンスが遅いのでローディングアニメーションしがいがあるのですが、gpt-4o-miniなどは割と応答が早くアニメーションしがいがないのでdelayノードでわざと処理を遅延させてアニメーションさせると挙動が試しやすいです。
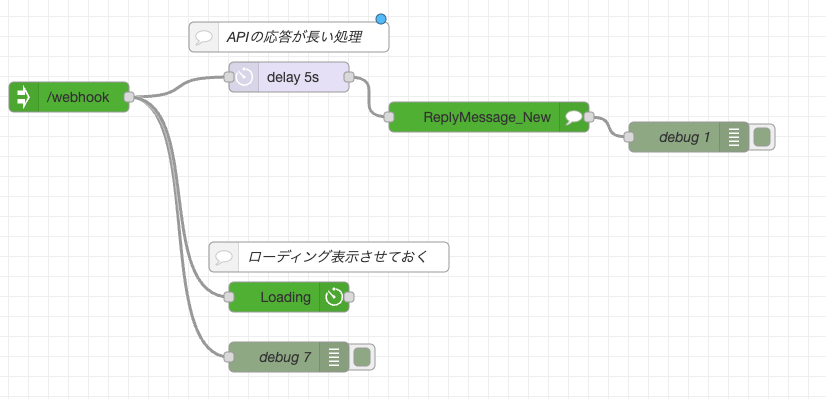
ローディングアニメーションは20秒などと指定していても、Botからのメッセージ送信処理が途中で行われるとローディングは中止になります。なのでアニメーションの観測をする際にはdelayノードのような遅延処理を挟むのが得策な気がしています。
OpenAIノード
こんな感じで node-red-contrib-openaiノード を使ってOpenAIのAPIにリクエストします。
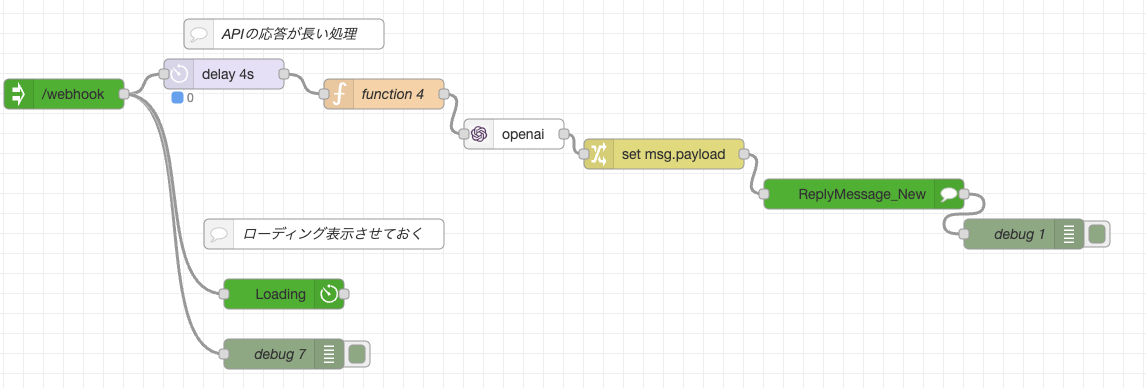
functionノード -> OpenAIノード -> Changeノード -> LINEのReplyMessageノードという流れで設定していきます。
functionノードは以下の様に設定します。
msg.api = 'chat/completions';
msg.params = {
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": msg.payload
}
],
"max_tokens": 30,
"temperature": 0
}
return msg;
OpenAIノードを挟み、Changeノードではmsg.payloadにmsg.payload.choices[0].message.contentを代入する様な設定にすることでOpenAIのAPIのレスポンスをLINE Messaging APIに渡すことができます。
その他気をつけるポイント
LINE Messaging APIのReplyノード的にはmsg.pyaloadにテキストが欲しいので、OpenAIノードからのレスポンスのmsg.payload.choices[0].message.contentをmsg.payloadに代入する必要があります。
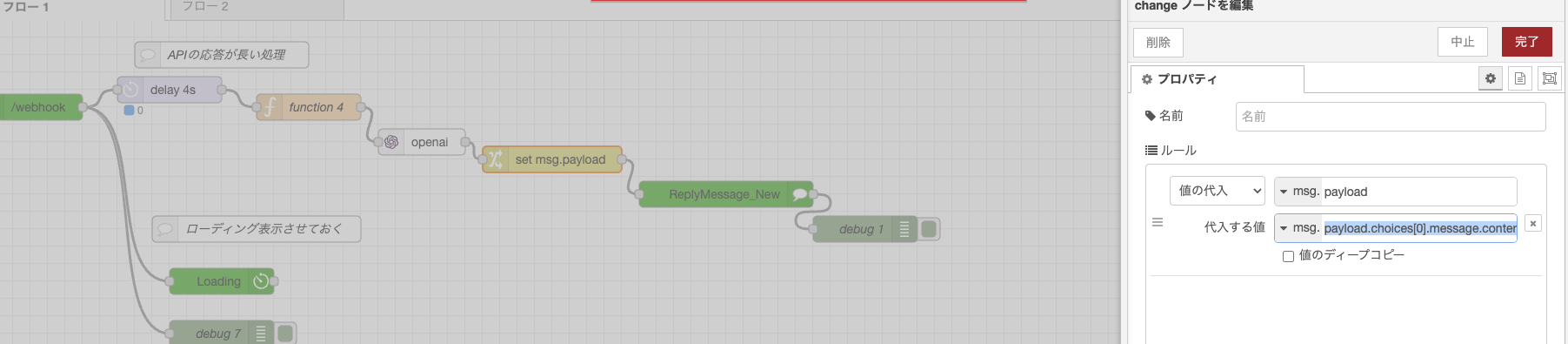
Changeノードを使いますが、スクリーンショットの情報でよく分からんな、、と言った場合は完成版のJSONを置いておくのでこれをインポートしてみてください。
- 完成系
[ { "id": "a03d009e174380de", "type": "Webhook", "z": "d9b855f597ec190b", "name": "", "url": "/webhook", "x": 560, "y": 1420, "wires": [ [ "be30017e44217ea4", "7a8e9a381eacda76", "7d6706eb096ba9f0" ] ] }, { "id": "e256f469d305e3d8", "type": "ReplyMessage_New", "z": "d9b855f597ec190b", "name": "", "replyMessage": "", "x": 1360, "y": 1520, "wires": [ [ "8723c73a9f132eba" ] ] }, { "id": "8723c73a9f132eba", "type": "debug", "z": "d9b855f597ec190b", "name": "debug 8", "active": true, "tosidebar": true, "console": false, "tostatus": false, "complete": "false", "statusVal": "", "statusType": "auto", "x": 1520, "y": 1560, "wires": [] }, { "id": "afee667091e9aff5", "type": "openai", "z": "d9b855f597ec190b", "name": "", "api": "", "creds": "", "x": 1010, "y": 1460, "wires": [ [ "9741e1614d896662" ] ] }, { "id": "ed78bd1ce234075c", "type": "function", "z": "d9b855f597ec190b", "name": "function 5", "func": "msg.api = 'chat/completions';\nmsg.params = {\n \"model\": \"gpt-4o-mini\",\n \"messages\": [\n {\n \"role\": \"system\",\n \"content\": \"You are a helpful assistant.\"\n },\n {\n \"role\": \"user\",\n \"content\": msg.payload\n }\n ],\n \"max_tokens\": 30,\n \"temperature\": 0\n}\nreturn msg;", "outputs": 1, "timeout": 0, "noerr": 0, "initialize": "", "finalize": "", "libs": [], "x": 880, "y": 1420, "wires": [ [ "afee667091e9aff5" ] ] }, { "id": "be30017e44217ea4", "type": "debug", "z": "d9b855f597ec190b", "name": "debug 9", "active": true, "tosidebar": true, "console": false, "tostatus": false, "complete": "true", "targetType": "full", "statusVal": "", "statusType": "auto", "x": 780, "y": 1680, "wires": [] }, { "id": "9741e1614d896662", "type": "change", "z": "d9b855f597ec190b", "name": "", "rules": [ { "t": "set", "p": "payload", "pt": "msg", "to": "payload.choices[0].message.content", "tot": "msg" } ], "action": "", "property": "", "from": "", "to": "", "reg": false, "x": 1160, "y": 1480, "wires": [ [ "e256f469d305e3d8" ] ] }, { "id": "7d6706eb096ba9f0", "type": "Loading", "z": "d9b855f597ec190b", "name": "", "loadingSeconds": "20", "x": 780, "y": 1620, "wires": [ [] ] }, { "id": "7a8e9a381eacda76", "type": "delay", "z": "d9b855f597ec190b", "name": "", "pauseType": "delay", "timeout": "4", "timeoutUnits": "seconds", "rate": "1", "nbRateUnits": "1", "rateUnits": "second", "randomFirst": "1", "randomLast": "5", "randomUnits": "seconds", "drop": false, "allowrate": false, "outputs": 1, "x": 720, "y": 1400, "wires": [ [ "ed78bd1ce234075c" ] ] }, { "id": "61ad65ea20535987", "type": "comment", "z": "d9b855f597ec190b", "name": "ローディング表示させておく", "info": "", "x": 820, "y": 1560, "wires": [] }, { "id": "ef6451cddaacedc9", "type": "comment", "z": "d9b855f597ec190b", "name": "APIの応答が長い処理", "info": "", "x": 780, "y": 1360, "wires": [] } ]
まとめ
OpenAIのAPI(現状だと特にo1系)などレスポンスが遅くなるAPIを利用したLINE Botは今後も増える気がしています。その時にただAPIを叩くのではなくローディングアニメーションが入れられるようになったのはだいぶ画期的なきがしています。
従来は、ユーザーから発話があり、重たいレスポンスの時は一旦Replyメッセージで発言(API処理中です... ちょっと待ってね...など)させてユーザーに正常挙動をしている安心感を伝えつつ、Pushメッセージで本題を送るといった実装や考え方が主流でした。
ローディングアニメーションが使えることでさらにその手前の表現ができる様になりました。
ローディングアニメーション > Replyメッセージでちょっと待ってね通知 > Pushメッセージという3段階の情報の送り方があり、左側にいけばいくほど、小さなタスクや短時間の処理に向いてそうな印象です。
ということで解像度が上がったのでみなさんLINE Bot作るときはぜひ活用してみてください。