この記事はリンク情報システム(Facebook)が主催するイベント「Tech Connect! Summer」のリレー記事です。
「Tech Connect! Summer」は engineer.hanzomon のグループメンバによってリレーされます。
本記事は4日目、8/3(土)分です。
先日弊社の社内アイデアソンで「チャットボットを考えよう」みたいなテーマやったんですが、その時自分で出した(そしてボツにした)レシピ検索ボットを作ってみました。
こんな感じでキーワードを入力したり
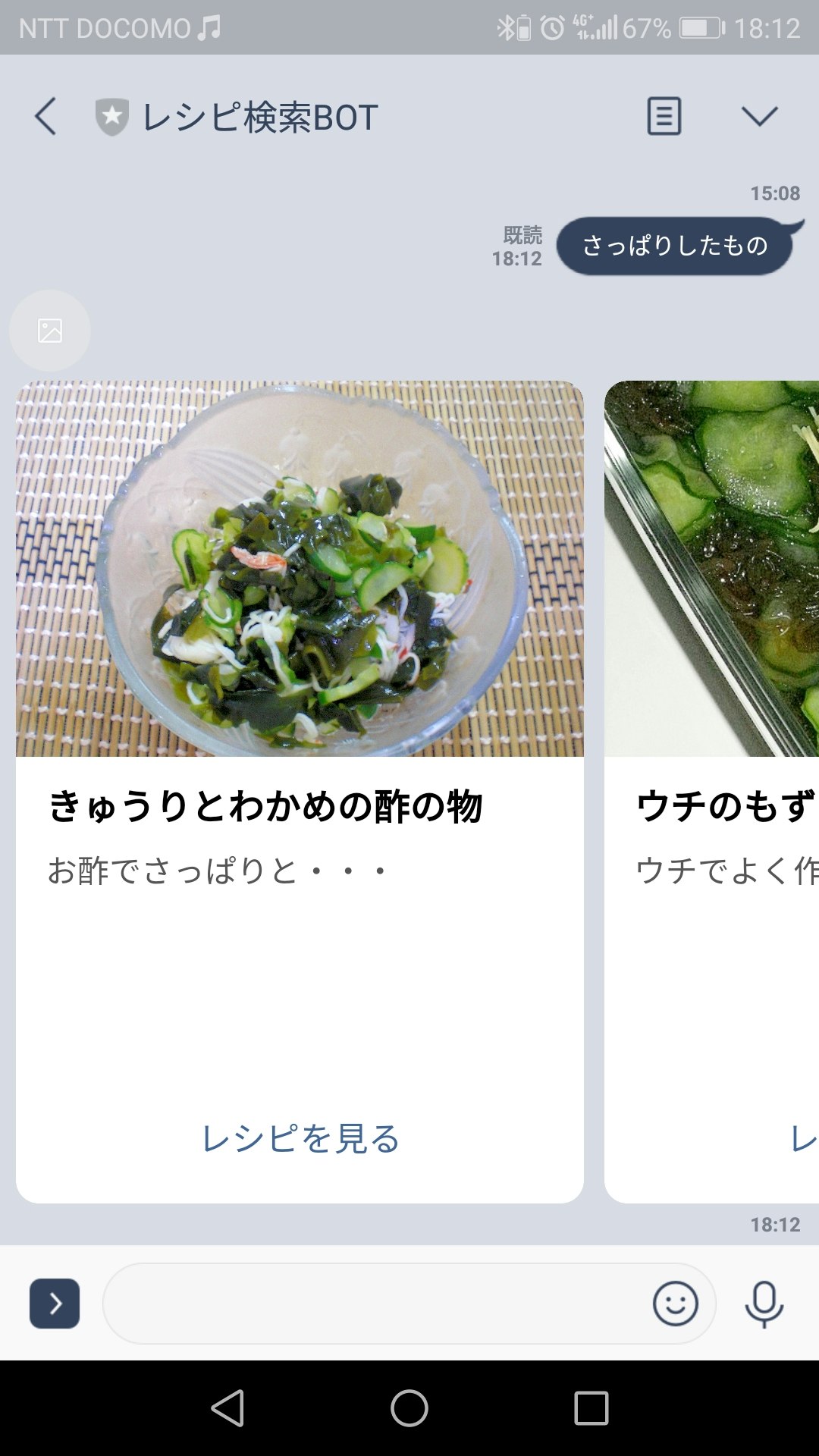
材料入れてみたりすると
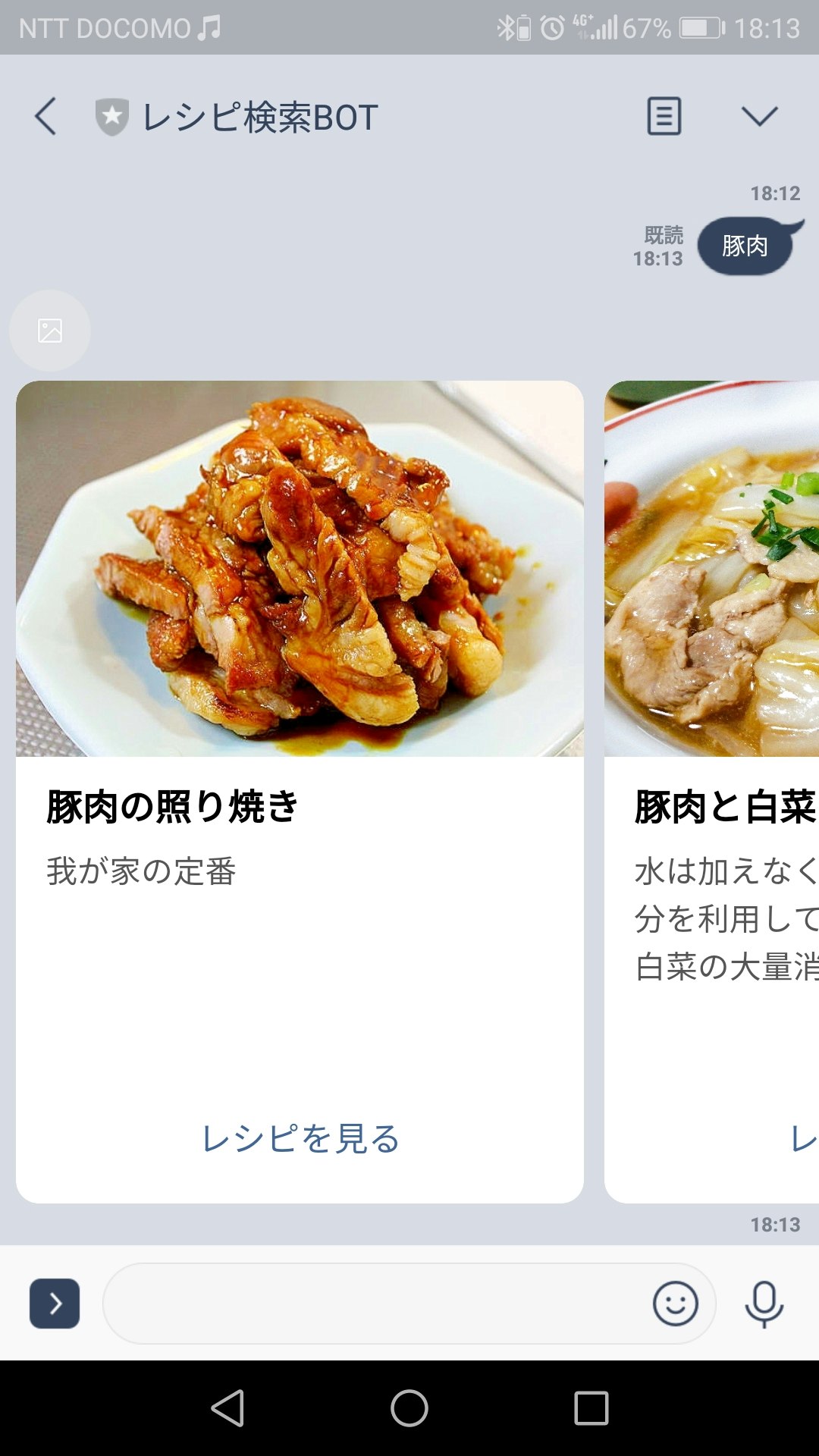
それっぽいレシピを5件くらい横並べで表示してくれます。
なんでボツにした案をやるかって?簡単そうだからだよ!
あとElasticsearch、というか全文検索をさわってみたかった。
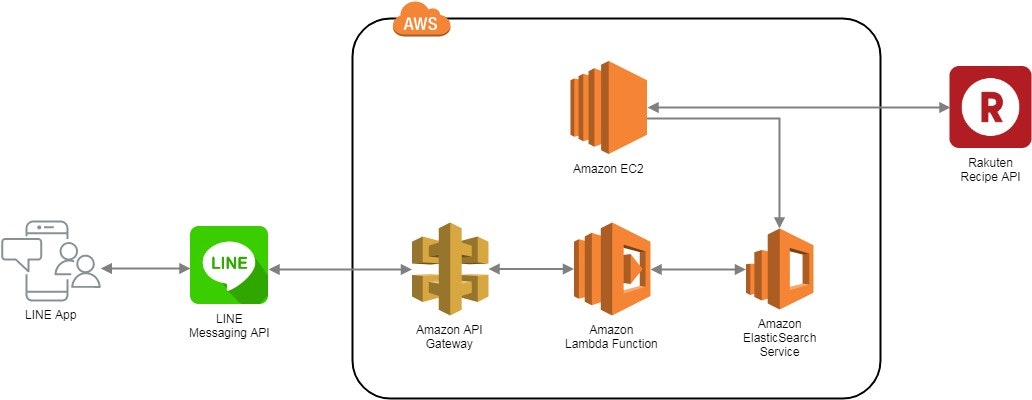
構成
今回はMessaging API(所謂LINE BOT) + AWS Lambda + AWS Elasticsearch + 楽天APIで作りました。
簡単な構成図は下記の通りとなります。
レシピの検索機構
レシピを引っ張ってくるのは楽天APIに任せたいところですが、楽天APIで提供されているのは
- 楽天レシピカテゴリ一覧API
- 楽天レシピカテゴリ別ランキングAPI
の2つとなっており、キーワードで検索するようなものは存在しません。
なので作ります。
流れとしてはカテゴリ一覧APIでカテゴリ取得→カテゴリ別ランキングAPIで各カテゴリの上位4件のレシピ取得→取ってきたレシピをElasticsearchにぶち込む→あとは良しなに
でいきます。
実際に書いたきったないコードが以下。
import os
import sys
import json
import requests
import boto3
from urllib.parse import urljoin, urlparse
from configparser import ConfigParser
from bs4 import BeautifulSoup
from time import sleep
from elasticsearch import Elasticsearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
def recipe_batch():
# Config読込
config = ConfigParser()
config.read('./config/recipe_batch.conf')
# AWSの認証情報
credentials = boto3.Session().get_credentials()
region = config.get('aws', 'region')
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, 'es')
# AWS Elasticsearchの接続
host = config.get('aws', 'es_endpoint')
es = Elasticsearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
# ElasticsearchのIndex作成
#es.indices.delete(index="recipe")
f = open('./config/settings.json', 'r')
settings = json.load(f)
es.indices.create(index='recipe', body=settings['settings'])
es.indices.put_mapping(index='recipe', doc_type='kuromoji_type', body=settings['mappings'])
# 楽天レシピカテゴリ検索API実行
application_id = config.get('rakuten', 'application_id')
api_endpoint = config.get('rakuten', 'api_endpoint')
recipe_category_list_api = config.get('rakuten', 'recipe_category_list_api_path') + config.get('rakuten', 'recipe_category_list_api_version')
item_url = urljoin(api_endpoint, recipe_category_list_api)
item_parameters = {
'applicationId': application_id,
'format': 'json',
'formatVersion': 2,
}
r = requests.get(item_url, params=item_parameters)
category_data = r.json()
# 取得したカテゴリ数分ループ
for category in category_data['result']['small']:
category_id = urlparse(category['categoryUrl']).path.split('/')[2]
# 楽天レシピカテゴリ別ランキングAPI実行
recipe_category_rank_api = config.get('rakuten', 'recipe_category_rank_api_path') + config.get('rakuten', 'recipe_category_rank_api_version')
item_url = urljoin(api_endpoint, recipe_category_rank_api)
item_parameters = {
'applicationId': application_id,
'format': 'json',
'formatVersion': 2,
'categoryId': category_id
}
r = requests.get(item_url, params=item_parameters)
rank_data = r.json()
# 取得したカテゴリ別ランキング数分ループ
for rank in rank_data['result']:
# レシピページの情報をBeautifuleSoupで読込
r = requests.get(rank['recipeUrl']).text.encode('utf-8')
soup = BeautifulSoup(r, 'html.parser')
# レシピID取得
recipe_id = soup.find(id="recipe_id")['value']
# 関連情報あれば取得
if soup.select_one('#detailContents > div.rcpAside > div.asideRackBtm > dl > dd'):
aside = " ".join(list(map(lambda x: x.text, soup.select('#detailContents > div.rcpAside > div.asideRackBtm > dl > dd > span'))))
else:
aside = ""
# Elasticsearchに投入
document = {
'title': rank['recipeTitle'],
'url': rank['recipeUrl'],
'image': rank['foodImageUrl'],
'description': rank['recipeDescription'],
'material': " ".join(rank['recipeMaterial']),
'aside': aside
}
es.index(index='recipe', doc_type='kuromoji_type', id=recipe_id, body=document)
# サーバに負荷かけないよう1秒Sleep
sleep(1)
if __name__ == '__main__':
recipe_batch()
カテゴリ別ランキングで取得されるレシピの紹介文だけだと検索キーワード的に弱い気がしたので実際のレシピページからBeautifulSoup使って関連キーワードをスクレイピングしてます。この部分すね。
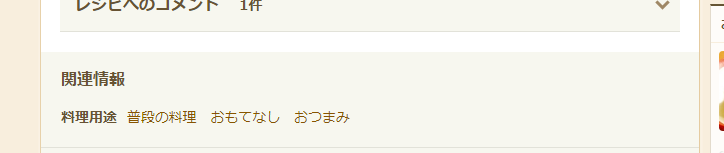
Elasticsearchのanalyzeの定義は以下の通りです。
AWS Elasticsearchだと日本語形態素解析はkuromojiがデフォルトで入ってるのでそれ使ってます。
{
"settings": {
"analysis": {
"tokenizer": {
"kuromoji": {
"type": "kuromoji_tokenizer"
}
},
"analyzer": {
"kuromoji_analyzer": {
"type": "custom",
"tokenizer": "kuromoji",
"char_filter": [
"icu_normalizer",
"kuromoji_iteration_mark"
],
"filter": [
"kuromoji_part_of_speech",
"ja_stop",
"kuromoji_readingform",
"kuromoji_stemmer"
]
}
}
}
},
"mappings": {
"kuromoji_type": {
"properties": {
"title": {
"type": "text",
"index": "true",
"analyzer": "kuromoji_analyzer"
},
"url": {
"type": "text",
"index": "true"
},
"image": {
"type": "text",
"index": "true"
},
"description": {
"type": "text",
"index": "true",
"analyzer": "kuromoji_analyzer"
},
"material": {
"type": "text",
"index": "true",
"analyzer": "kuromoji_analyzer"
},
"aside": {
"type": "text",
"index": "true",
"analyzer": "kuromoji_analyzer"
}
}
}
}
}
こいつを適当なEC2で流して一晩寝かせておけばレシピ検索サーバは完成です。
ボットサーバ
レシピの検索はできるようになったので、あとはボットサーバを作りましょう。
ボットサーバはLambda上に実装していきます。以下コード。
import os
import sys
import requests
import boto3
from elasticsearch import Elasticsearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
from linebot import LineBotApi, WebhookHandler
from linebot.models import (
MessageEvent,
TextMessage,
TextSendMessage,
CarouselColumn,
CarouselTemplate,
URITemplateAction,
TemplateSendMessage
)
from linebot.exceptions import LineBotApiError, InvalidSignatureError
import logging
logger = logging.getLogger()
logger.setLevel(logging.ERROR)
# Messaging APIの認証情報
channel_secret = os.getenv('LINE_CHANNEL_SECRET', None)
channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)
if channel_secret is None:
logger.error('Specify LINE_CHANNEL_SECRET as environment variable.')
sys.exit(1)
if channel_access_token is None:
logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.')
sys.exit(1)
line_bot_api = LineBotApi(channel_access_token)
handler = WebhookHandler(channel_secret)
def lambda_handler(event, context):
signature = event['headers']['X-Line-Signature']
body = event['body']
ok_json = {'isBase64Encoded': False,
'statusCode': 200,
'headers': {},
'body': ''}
error_json = {'isBase64Encoded': False,
'statusCode': 403,
'headers': {},
'body': 'Error'}
@handler.add(MessageEvent, message=TextMessage)
def message(line_event):
try:
# 入力されたキーワードでElasticsearch検索
results = search_recipe(line_event.message.text)
if not results:
# データが存在しない場合の応答
messages = TextSendMessage(text='みつからへんやった、すまんな')
else:
# 取得データ数分カルーセルメッセージ生成
columns = [
CarouselColumn(
thumbnail_image_url=result['_source']['image'],
title=result['_source']['title'][:40],
text=result['_source']['description'][:60],
actions=[
URITemplateAction(
label='レシピを見る',
uri=result['_source']['url']
)
]
)
for result in results
]
messages = TemplateSendMessage(
alt_text='template',
template=CarouselTemplate(columns=columns),
)
except Exception as e:
messages = TextSendMessage(text='なんや調子悪いわ、ちょい待ってからやってや')
# Messaging APIの応答
logger.debug(messages)
line_bot_api.reply_message(line_event.reply_token, messages)
try:
handler.handle(body, signature)
except LineBotApiError as e:
logger.error('Got exception from LINE Messaging API: %s' % e.message)
for m in e.error.details:
logger.error(' %s: %s' % (m.property, m.message))
return error_json
except InvalidSignatureError:
return error_json
return ok_json
def search_recipe(keyword):
try:
# AWSの認証情報
credentials = boto3.Session().get_credentials()
region = os.environ['REGION']
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, 'es', session_token=credentials.token)
# AWS Elasticsearchの接続
host = os.environ['ES_ENDPOINT']
es = Elasticsearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
# タイトル、説明文、材料、関連キーワードでQuery
body = {
'query': {
'multi_match': {
'fields': [
'title',
'description',
'material',
'aside'
],
'query': keyword
}
},
'size': 5
}
response = es.search(index='recipe', body=body)
logger.debug(response)
except Exception as e:
logger.error('Got exception from AWS Elasticsearch Scan: %s' % e.message)
raise e
# 取得データを返却
return response['hits']['hits']
入力されたキーワードを使ってElasticsearchで全文検索してます。
タイトル、説明文、材料、関連キーワードを対象にquery投げて、score上位5件を表示対象としています。
Messaging APIのレスポンスにはカルーセル形式でレシピ情報を詰め込んでます。
マッチするレシピが存在しない場合はそれっぽい文言を応答します。
接続
あとはMessaging APIとLambdaを疎通してやれば完成です。
Amazon API GatewayでPOSTメソッド作って、Messaging APIのWebhook URLに作ったURLを登録するだけ。いろんな人がやってるので割愛します。
終わりに
Elasticsearchは初めて触りましたが、いともたやすく検索サーバができるのでえらい便利そうですね。
ぶち込むデータを変えれば同じ仕組みでいくらでもボット作れそうなのでいろいろやれそうです。
お読みいただきありがとうございました。
他のTech Connect! Summerの記事も楽しみにしています。
明日は@t_slash_k さんです。