はじめに
文書を入力すると、どんなジャンル(恋愛とかファンタジーとか)になるかを判断してくれるものを作った。そのときに使ったモデルの構築などのメモ。
どんなことしたか
小説家になろうから、ジャンル別にランキング上位の小説のテキストを取得
ーRequests, BeaufitulSoupによるスクレイピング
Kerasで単語レベルの1次元畳み込みによる学習
ー単語分割にMeCab, 単語埋め込みの重みにfastTextの学習済みデータを使用
fastTextのデータは配布されているのを利用させていただきました。
・fastTextの学習済みモデルを公開しました - Qiita
1.テキストデータの取得
ディープラーニングの学習には、データが必要。今回は簡単に取得できるものとして「小説家になろう」からテキストデータを取得した。
ランキング上位1000個の小説からそれぞれ2000文字分を小説ごとにテキストファイルに保存した。
参考にさせていただいたサイト
・PythonとBeautiful Soupでスクレイピング - Qiita
実際使用したコードを書くと長くなるので、簡単な例を以下に
# timeはデータを取得するときに間隔を開けるために使用
import time
# python3ではurllib2は使えないのでrequestsを使用
import requests
from bs4 import BeautifulSoup
# 指定したurlのテキストを取得
hoge_url = 'https://hogehoge.com'
time.sleep(2)
# hoge_urlの内容を取得
page_res = requests.get(hoge_url)
# 文字化けを直すためにエンコーディングを適用
page_res.encoding = page_res.apparent_encoding
page_soup = BeautifulSoup(rank_page_res.text, 'html.parser')
# 小説家になろうの本文は以下のセレクタで抜き出せる
all_sentenses = novel_soup.select('#novel_honbun p')
# senteseに一行ずつのテキストが入る
for sentense in all_sentenses:
#処理内容、以下省略
2.単語に分割
単語分割するのは大変かと思っていたが、とても簡単にできた。
MeCabのインストール方法は公式のサイト通りにやった。
・MeCab: Yet Another Part-of-Speech and Morphological Analyzer
import MeCab
# 処理前のテキストファイルを保存したファイル
novel_dir = './novels/novel_1.txt'
# 処理後のテキスト書き込むファイル
wakati_dir = './wakati/wakati_1.txt'
# テキストファイルをread modeで読み込む
file = open(novel_dir, 'r')
# テキストを読み込んで、string型でtextに代入
text = file.read()
file.close()
# 全角スペースを半角スペースに置き換え
text = text.replace(' ',' ')
# 書き込むファイルをwrite modeで開く
wakati_file = open(wakati_dir,'w')
# -Owakatiは文章を区切ってスペースを挿入してくれる
tagger = MeCab.Tagger("-Owakati")
text = tagger.parse(text)
save_file.write(text)
save_file.close()
3.ラベル付け、データセットの作成
ファイルを読み込んで、それぞれをリストにした。
文章は単語ごとに半角スペースで区切られているのでsplitを使って、一つずつをリストに入れたものを
まとめて2次元のリストにした。
ラベルは、ジャンルの数だけ配列を用意し正解だけを1それ以外を0に、2次元のリストにした。

4.単語埋め込み
KerasのTokenizerで単語埋め込みを行った。
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# Tokenizerの引数にnum_wordsを指定すると指定した数の単語以上の単語数があった場合
# 出現回数の上位から順番に指定した数に絞ってくれるらしいが、うまくいかなかった
# 引数を指定していない場合、すべての単語が使用される
tokenizer = Tokenizer()
# list xは上に書いたようにテキストデータが格納されている
tokenizer.fit_on_texts(list(x))
sequence = tokenizer.texts_to_sequences(x)
# pad_sequenceでは、指定した数に配列の大きさを揃えてくれる
# 指定した数より配列が大きければ切り捨て、少なければ0で埋める
sequence = pad_sequences(sequence, maxlen=1000)
5.データセットを分割して、混ぜる
訓練データ、検証データ、テストデータにデータセットを分けたあと、それぞれ順番を混ぜた。
混ぜた理由は、そのままだと同じジャンルが連続していたため。
ラベルとの関連付けを崩さずに混ぜる方法は以下のようになる。
import numpy as np
def shuffle_detaset(x, y):
index = np.arange(x.shape[0])
np.random.shuffle(index)
x=x[index]
y=y[index]
return x, y
6.学習済みの単語埋め込み(fastText)を対応付ける
FastTextの学習済みデータは配布されているのを利用させていただいた。
対応付ける方法は以下を参考にさせていただいた。
・学習済みの分散表現をLSTMの埋め込み層に利用する - Qiita
import gensim
# 配布されていたfastTextの次元数は300だったので300
EMBEDDING_DIM = 300
embedding_metrix = np.zeros((len(tokenizer.word_index)+1,EMBEDDING_DIM))
word_vectors = gensim.models.KeyedVectors.load_word2vec_format('./fastText/model.vec', binary = False)
for word, i in tokenizer.word_index.items():
try:
embedding_vector = word_vectors[word]
embedding_metrix[i] = embedding_vector
except KeyError:
embedding_metrix[i] = np.random.normal(0, np.sqrt(0.25), EMBEDDING_DIM)
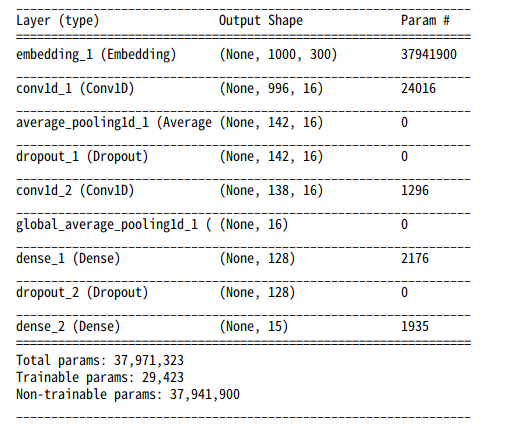
7.モデルを構築
あとは、普通にモデルを作れば良い。今回は1次元畳込みで作った。
MaxPoolingよりもAveragePoolingのほうがうまく行った。
from keras.models import Sequential
from keras.layers import Embedding, Dense
from keras import layers
model = Sequential()
model.add(Embedding((len(tokenizer.word_index)+1), EMBEDDING_DIM, input_length=x.shape[1]))
model.add(layers.Conv1D(16, 5, activation='relu'))
model.add(layers.AveragePooling1D(7))
model.add(layers.Dropout(0.5))
model.add(layers.Conv1D(16, 5, activation='relu'))
model.add(layers.GlobalAveragePooling1D())
model.add(layers.Dense(128,activation='relu'))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(y.shape[1], activation='softmax'))
model.summary()
モデルは以下のような構成になった
8.学習
学習済みの重みをEmmbedding層の重みにセットする。
また、このまま学習をしてしまうと、せっかくの学習済みの重みが破壊されてしまうかもしれないので
埋め込み層は学習しないようにする。その後、モデルをコンパイルし、学習する。
# 重みをセット
model.layers[0].set_weights([embedding_metrix])
# 学習しないようする
model.layers[0].trainable = False
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])
history = model.fit(x_train,y_train, epochs=20, batch_size=32, validation_data=(x_validation,y_validation))
結果
正解率は40%程度になった、期待値が6%であることを考えるとうまくいったのではないかと思う。
正解率を上げるには、データの数を増やすなどが必要になると思われる。
また、そもそも小説家になろうのジャンル自体、筆者が勝手に選んでいるので正解がほんとに正解とは限らないこと、
小説のどこを抜き出すかで全然違うジャンルに予測できることなど、問題も多くあるので正解率を8割などにするのは難しいと思う。
蛇足
ディープラーニングを利用アプリ自体リソースを多く使うのでサーバーサイドで実装するのはherokuなどの無料枠では厳しいと感じた。
解決策としては、javascriptを使う方法があるがモデルのデータはDLしてもらわないといけないので大きなモデルでは使いにくいと思う。
うまい解決策があれば教えてください。
あと、ハイパーパラメータの調整の方法で良い方法があれば、教えていただけると嬉しいです。
今回は、ひたすら何度も学習して結果見てを繰り返していたので...
追記(2019/3/26)
TensorFlow.jsを使ってwebアプリにしました。(PCのみ対応です https://myabu.dev/app/ganre/)
TensorFlow.jsの使いかたのメモも書きました。(https://qiita.com/myabu/items/3dbe0b27ba429217f828)