ISUCON のブログ記事等で当たり前に出てくる「N+1問題」を知らなかったので、調査した結果です。
TL;DR
N+1問題とは、このブログ記事にもう全部書いていますが、
- N件のデータ行を持つテーブルをごそっと読みだすのに1回
- 別のテーブルから、先述のテーブルの各行に紐づくデータを(1件ずつ)読み出すのに計N回
合計でN+1回のクエリを実行している状態です。
(1+N問題と考えた方が理解しやすい)
Nが大きいときは処理に非常に時間がかかるため、対応が必要になります。
対応策としては、
- JOIN句による表の結合
- Eager Loading(必要なデータを事前にロード)
の2種類があります。
例
図書館の本貸出管理システムを考えます。
以下のように、「書籍」テーブルと、図書館の「利用者1」テーブルがあるとします。
 各書籍について、借りている人の名前と、年齢を知りたいときを考えます。
欲しいのはこのような結果です。
各書籍について、借りている人の名前と、年齢を知りたいときを考えます。
欲しいのはこのような結果です。

このビュー作成の直観的な方法としては、
- まずアプリ側に、書籍テーブルの情報をドサッと持ってくる
SELECT * FROM 書籍;
- 各書籍の借用者IDを見て、対応する利用者の情報を取得する
-- 書籍ID=1 のとき、借用者ID=3なので、
SELECT * FROM 利用者 WHERE 利用者ID=3;
-- 書籍ID=2 のとき、借用者ID=1なので、
SELECT * FROM 利用者 WHERE 利用者ID=1;
...
-- 書籍ID=5 のとき、借用者ID=4なので、
SELECT * FROM 利用者 WHERE 利用者ID=4;
 というわけで、最初に書籍テーブル自体の1件+書籍データ件数の5件=計6件のクエリをアプリ側が発行します。
これが N=100万件とかになると、Nに応じた件数のクエリが必要になるので、
処理時間が膨大になってしまいます。
というわけで、最初に書籍テーブル自体の1件+書籍データ件数の5件=計6件のクエリをアプリ側が発行します。
これが N=100万件とかになると、Nに応じた件数のクエリが必要になるので、
処理時間が膨大になってしまいます。
対応策
JOIN句を使う
JOIN でテーブルを結合して取得する方法です。
結合自体に時間はかかりますが、1件のクエリで欲しい情報を取得できます。
SELECT 書籍.ID, 書籍.書籍名, 利用者.利用者名, 利用者.年齢
FROM 書籍 JOIN 利用者 ON 書籍.借用者ID = 利用者.ID
Eager Loading
- テーブルの取得に1回クエリ発行
- 別テーブルから、今後の処理に必要なデータを1回のクエリでまとめて取得
- その後アプリ側で、データの結合などの処理を行う
といった手法です。クエリは2件で済みます。
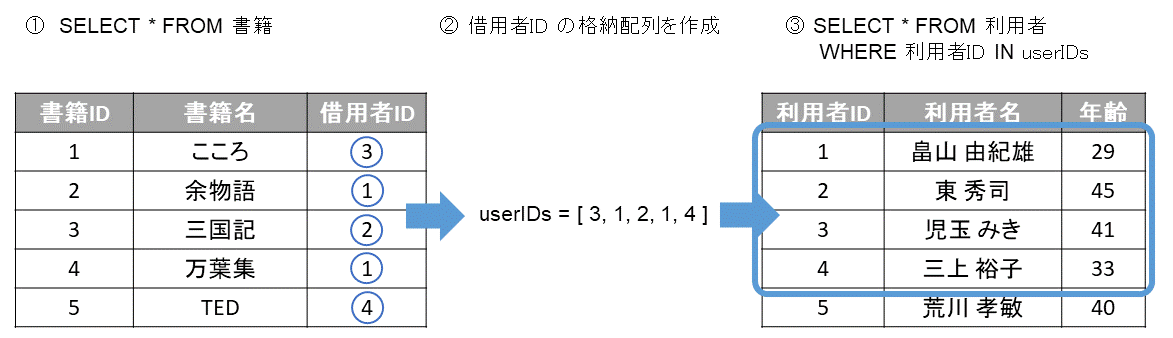
- まずアプリ側に、書籍テーブルの情報をドサッと持ってくる
SELECT * FROM 書籍;
- 各書籍の借用者IDを格納する配列を作成する
userIDs = [3, 1, 2, 1, 4]
よって、利用者テーブルから、IDが [ 3, 1, 2, 1, 4 ] の利用者の情報を取得すれば良さそう。
- 利用者テーブルから、利用者情報を取得する
SELECT * FROM 利用者 WHERE ID IN (3, 1, 2, 1, 4);
これで必要な書籍情報と、利用者情報が全て取得できました。今後クエリは発行しません。
- 利用者IDから利用者情報を対応付けるマップを作成する
userMap[1] = {1, 畠山由紀雄, 29}
userMap[2] = {2, 東秀司, 45}
...
userMap[4] = {4, 三上裕子, 33}
-
あとはこれらの情報からビューを作成するだけです。
例えば、3番目の書籍を借りている人の情報を知りたいとき- ID=3の書籍の、借用者IDは2です。
-
userMap[2] = {2, 東秀司, 45}です。
よって、3番目の書籍を借りている人の名前は「東秀司」で、年齢は45歳です。
借用者IDを参照する代わりに、userIDsを使うこともできます。
i 番目の書籍の利用者情報は、userMap[userIDs[i-1]]で検索できます2。
Go言語での実装
Go 言語での実装を考えてみます。(エラー処理はすべて省略しています。)
DB は PostgreSQL を使用しています。ソースコード達はこちらにあります。
まずはテーブルと、構造体の定義です。
CREATE TABLE book (
id SERIAL PRIMARY KEY,
title VARCHAR(20) NOT NULL,
user_id INTEGER NOT NULL
);
CREATE TABLE luser (
id SERIAL PRIMARY KEY,
uname VARCHAR(20) NOT NULL,
age INTEGER NOT NULL
);
type Book struct {
ID int
Title string
UserID int
Uname string
Age int
}
type Luser struct {
ID int
Uname string
Age int
}
N+1状態
N+1クエリでの実装は以下のようになります。
// 書籍一覧を格納する配列
var books []*Book
// 書籍一覧の取得
rows, _ := Db.Query("SELECT * FROM book")
// 取得した各列について
for rows.Next() {
// 書籍データの取得
var book Book
rows.Scan(&book.ID, &book.Title, &book.UserID)
// 利用者テーブルから抽出、利用者データの取得
Db.QueryRow("SELECT uname, age FROM luser WHERE id = $1;", book.UserID).Scan(&book.Uname, &book.Age)
// データを books に格納
books = append(books, &book)
}
// 結果の表示
for _, book := range books {
fmt.Println(book.ID, book.Title, book.Uname, book.Age)
}
実行した結果は以下のようになります。
root@44ecf0cb93cd:/go/src/app/go# go run n_1.go
1 こころ 児玉 みき 41
2 余物語 畠山 由紀雄 29
3 三国記 東 秀司 45
4 万葉集 畠山 由紀雄 29
5 TED 三上 裕子 33
JOIN句
JOIN句を使用した場合。スッキリしています。
var books []*Book
// 書籍テーブルと利用者テーブルを結合、取得
rows, _ := Db.Query("SELECT book.id, book.title, luser.uname, luser.age FROM book JOIN luser ON book.user_id = luser.id")
// 取得した各列について
for rows.Next() {
// 書籍、利用者データの取得
var book Book
rows.Scan(&book.ID, &book.Title, &book.Uname, &book.Age)
books = append(books, &book)
}
// 結果の表示
for _, book := range books {
fmt.Println(book.ID, book.Title, book.Uname, book.Age)
}
実行結果はN+1の時と同じ。
mapを使用
map を使用した場合。少し複雑になります。
var books []*Book
// 借用者ID を文字列として格納する配列
var userIDs []string
// 利用者ID -> 利用者情報へのマップ
userMap := make(map[int]Luser)
// 書籍一覧の取得、格納
rows, _ := Db.Query("SELECT * FROM book")
for rows.Next() {
var book Book
rows.Scan(&book.ID, &book.Title, &book.UserID)
books = append(books, &book)
// 借用者IDを文字列に変換して格納
userIDs = append(userIDs, strconv.Itoa(book.UserID))
}
// SQL 文の組み立て
sql := "SELECT id, uname, age FROM luser WHERE id IN (" + strings.Join(userIDs, ",") + ");"
// 利用者テーブルから抽出、データの取得
rows, _ = Db.Query(sql)
for rows.Next() {
var luser Luser
err = rows.Scan(&luser.ID, &luser.Uname, &luser.Age)
// 利用者データを map に格納
userMap[luser.ID] = luser
}
for _, book := range books {
// map から利用者データの取得
book.Uname = userMap[book.UserID].Uname
book.Age = userMap[book.UserID].Age
// 結果の表示
fmt.Println(book.ID, book.Title, book.Uname, book.Age)
}
これも実行結果はN+1の時と同じ。
処理時間を検証
テストデータの追加
書籍データを20万件、利用者データを1万件まで追加して、各手法の処理時間を検証します。
書籍データ、利用者データの内容は次の通りです。
| 書籍ID | 書籍名 | 借用者ID |
|---|---|---|
| 自動採番 | ランダムな平仮名3文字 | 利用者IDの範囲からランダム |
| 利用者ID | 利用者名 | 年齢 |
|---|---|---|
| 自動採番 | 平仮名2文字+平仮名3文字 | 10~80の範囲からランダム |
データ追加のコードは以下になります。
// データ件数
const nBook = 200000
const nLuser = 10000
fmt.Println("書籍データの追加中...")
for i := 5; i < nBook; i++ {
rand.Seed(time.Now().UnixNano())
// 書籍データをテーブルに追加
Db.Exec("INSERT INTO book (title, user_id) VALUES ('" + RandString(3) + "', " + strconv.Itoa(rand.Intn(nLuser)+1) + ")")
}
fmt.Println("利用者データの追加中...")
for i := 5; i < nLuser; i++ {
rand.Seed(time.Now().UnixNano())
// 利用者データをテーブルに追加
Db.Exec("INSERT INTO luser (uname, age) VALUES ('" + RandString(2) + " " + RandString(3) + "', " + strconv.Itoa(rand.Intn(70)+10) + ")")
}
処理時間の計測
このテストデータを用いて、処理時間を計測していきます。計測のために、コードに次のような行を追加しました。
// 時間計測開始
start := time.Now()
// ...処理...
// 時間計測終了
end := time.Now()
// 結果の表示
for i := 0; i < min(9, len(books)); i++ {
book := books[i]
fmt.Println(book.ID, book.Title, book.Uname, book.Age)
}
// 処理時間の表示
fmt.Printf("処理時間: %f秒\n", (end.Sub(start)).Seconds())
計測結果
結果は以下のようになりました。
| N+1 | JOIN | map |
|---|---|---|
| 80.8秒 | 1.7秒 | 2.6秒 |
この結果から、
- N+1 は圧倒的に時間がかかる
- JOIN はクエリ1回で済み、かつアプリで余計な処理が不要なため、速い
- map はクエリ2回で、かつアプリ内の処理が多いため、JOINほど速くはない
ことが考えられます。
まとめ
- N+1問題は、
- 一覧の取得に1回
- 関連データの取得にN回
計N+1回のクエリを発行する時に起きる性能問題。
- JOIN句、Eager Loading といった対応策の、Go言語での実装例を示しました
- また、これらの対応策により、速度が大幅に改善されることを示しました。
追記予定
これから追記していきたい内容です。
N+1クエリの見つけ方
自分はクエリのログを目視で見ていって発見したので、その過程を
また、発見用のツールもあるらしいので、それの紹介を書きたい
複数カラムでのEager Loading
WHERE の検索条件が複数になるときはどうすればいいか、このあと調べます。
検索条件に合わせて、2次元以上の map を作成するんですかね?
参考書籍
今回は全部ネットで調べていったけど、
SQLやDBMSの性能について、体系的に教えてくれる良い書籍があれば
参考
- Railsライブラリ紹介: N+1問題を検出する「bullet」
- N+1問題は1+N問題
- N+1問題 NoahOrblog
- Go言語でランダムな文字列を生成する方法の比較
- golangでかかった処理時間を計算するには?
-
名前はテストデータ・ジェネレータで作成しました。人の名前が古っぽいのがアレですけど、便利なサイトです。 ↩
-
userID は配列で、インデックスを0から開始しています。userMap は配列ではなく、利用者IDをキーにしたマップなので、IDから-1をせず、そのままの検索しています ↩