概要
ML-Agents(Unityが公開した機械学習のライブラリ)が公開されました。
3年前の自作のゲームをAIで動かしてみることにしました。

目的
強化学習をする上で、実ゲーム上ではどのようにrewardを与えてあげるべきかということを知りたく実施。
その過程で気づいたことをここで公開しました。
ML-Agentsの導入・使用方法
公式ドキュメント以外にもわかりやすく説明してくれているものがあります。
Unityが機械学習のライブラリを公開したので使ってみる (和訳付き)
Unity 2017 で Machine Learning Agents を使ってみる
ゲーム仕様
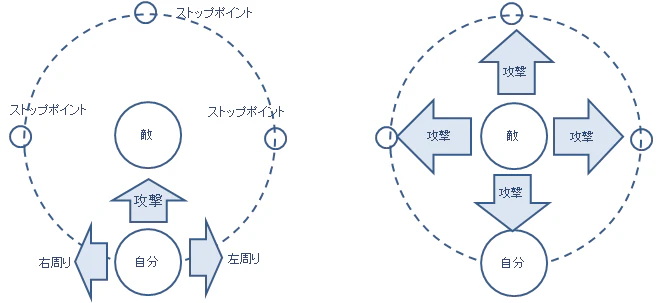
- プレーヤーは敵の周りを円形に移動できる
- プレーヤーは敵の前後左右のストップポイント上でのみ攻撃できる
- 敵は上下左右に向きを変えて、上下左右のストップポイントに向かって攻撃する
- 障害物の後ろは敵の攻撃は受けない
- 光る玉(体力回復アイテム)を取ると体力が回復する(※一定条件を満たすと出現)
ソースコード
このゲームはPlayerとEnemyをManagerクラスが管理している構成。
もともとのつくりの都合もありますが、Mangerコンポーネントが貼ってあるGameObjectにAgentを付けることにしました。
public class RoundAgent : Agent {
BattleManager manager;
public override void InitializeAgent()
{
InitCallback ();
}
bool isCallbackSetted = false;
void InitCallback()
{
if (isCallbackSetted)
return;
manager = GetComponent<BattleManager>();
if (manager == null)
return;
manager.OnPlayerDamage += damage => {
// Playerがダメージを受ける
AddReward(-0.025f);
};
manager.OnPlayerHeal += hp => {
// Playerのダメージを回復する
AddReward(0.015f);
};
manager.OnEnemyDamage += damage => {
// Playerがダメージを与える
AddReward(0.025f);
};
manager.OnWin += () => {
// 勝利
AddReward(1f);
Done();
};
manager.OnLose += () => {
// 敗北
AddReward(-1f);
Done();
};
isCallbackSetted = true;
}
public override void CollectObservations()
{
AddVectorObs(manager.Player != null ? manager.Player.gameObject.transform.position.x : 0f);
AddVectorObs(manager.Player != null ? manager.Player.gameObject.transform.position.z : 0f);
AddVectorObs(manager.Player != null ? manager.Player.GetHpRate() : 0f);
AddVectorObs(manager.Enemy != null ? manager.Enemy.gameObject.transform.rotation.x : 0f);
AddVectorObs(manager.Enemy != null ? manager.Enemy.gameObject.transform.rotation.y : 0f);
AddVectorObs(manager.Enemy != null ? manager.Enemy.gameObject.transform.rotation.z : 0f);
AddVectorObs(manager.Enemy != null ? manager.Enemy.GetHpRate() : 0f);
AddVectorObs(GetRecoverItemType()); // 回復アイテムの配置場所に応じたType(int型)を返す
}
//public override void AgentStep(float[] act)
public override void AgentAction(float[] vectorAction, string textAction)
{
InitCallback();
if (brain.brainParameters.vectorActionSpaceType == SpaceType.discrete) {
if (manager != null && !manager.CanPlayerAction ()) {
// Playerがストップポイント以外の場所いる場合はなにもしない
return;
}
int action = (int)vectorAction[0];
switch (action) {
case 0:
// 右周り
if (manager.Player != null)
manager.Player.TryMoveLeft();
break;
case 1:
// 左周り
if (manager.Player != null)
manager.Player.TryMoveRight();
break;
case 2:
// 攻撃
if (manager.Player != null)
manager.Player.ExecuteAttack();
break;
}
if (IsDone()) {
AddReward(0.005f);
}
Monitor.Log ("Action", action, MonitorType.text);
}
}
public override void AgentReset()
{
manager.Restart();
}
public override void AgentOnDone()
{
manager.Restart();
}
}
stateについて
(ver0.3ではVector Observationだが、以下stateパラメータと表記)
このゲーム上のシチュエーションを決める構成要素。よって下記の項目にしました。
- Playerの位置(x, z)
- PlayerのHP率(HP/最大HP)
- Enemyの回転角度
- EnemyのHP率(HP/最大HP)
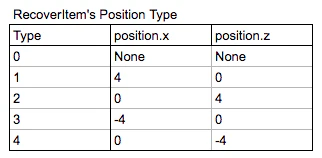
- 体力回復アイテムの位置のタイプ (※2018/01/29追記)
actionについては
- 右に移動
- 左に移動
- 敵に向かって攻撃
上記の動作はPlayerがストップポイントに立っているときのみ有効になります。
実ゲーム上でもそうですが、ストップポイント以外の場所で上記の動作を開始しても無効とします。
rewardについて
- ゲーム上の結果である勝利を目指してほしいので、勝利報酬を1、敗北報酬を-1
- ストップポイントに着いたら移動か攻撃の何らかのアクションするようになって欲しいので、ストップポイント上で指定のアクションを行ったら報酬を0.005
- その結果、相手にダメージを与えることができたら報酬を0.025、逆に相手からダメージを貰った場合は-0.025
- 回復アイテムをもらった結果、回復した場合は0.015
設定
Brain
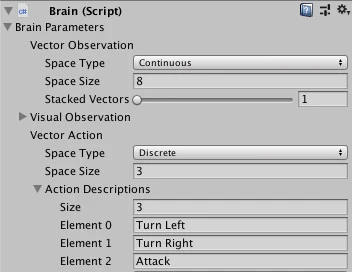
RoundAgentはstateを表すパラメータであるvector observationの数を8、actionの数を3にしました。(デフォルトは12と4)
上記のデフォルト値から変更する場合、Brainコンポーネント上のBrain Parameterの下記のサイズを合わせます。
- Vector ObservationのSpace Sizeを8にする
- Vector ActionのSpace Sizeを3にする
- Action DescriptionsのSizeを3にする
ActionSpaceTypeについては、設定によってAgentActionの引数の中身が変わってきます。
- Discrete (型はfloatだが、0, 1, 2のように分散的値。実行するactionインデックスのような場合はこちら)
- Continuous (float: 連続的値。locationの座標などの場合はこちら)
今回は実行するactionのインデックス値を受取りたいのでDiscreteとしました。
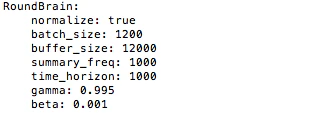
Academy
Max Stepsを適切な値に設定します。
ここのMax StepsはAcademy.Reset()を実施するまでのstepsです。(ppo.pyもしくはPPO.ipynbのmax_stepsとは別)
単純に学習させるだけでしたら、デフォルトの0のままでも各Agentは学習してくれます。
ここでは深く扱いませんがcurriculum-learningを行う場合は、
AcademyのMax Stepsを0より上の値に設定しないと、他の条件が満たされても次のLessonへと進んでくれません。

python側
trainer_config.yamlにBrain情報を追加
学習の改善
stateパラメータを減らす
こちらを掲載した当初(2017/12/22)ではstateパラメータは7でした。だだ、いくら学習してもcumulative_rewardが収束しませんでした。
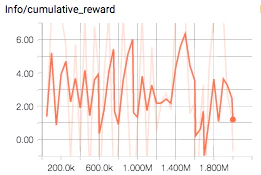
その後、ゲームの状況を正しく伝えきれていないことに気づき、回復アイテムのポジションのパラメータ(x, z)を渡し(結果9stateパラメータにて)学習しました。
AddVectorObs(manager.RecoverItem != null ? manager.RecoverItem.transform.position.x : 0f);
AddVectorObs(manager.RecoverItem != null ? manager.RecoverItem.transform.position.z : 0f);
ただし、こちらでの学習は収束せずかつ勝敗率も悪く、効果的でないことがわかりました。
回復アイテムはゲーム使用上ストップポイント上にしか配置されないので、1つのパラメータで表せます。
よって最終的には上記のstateについての通りとして学習を行いました結果、下記の通りとなりました。
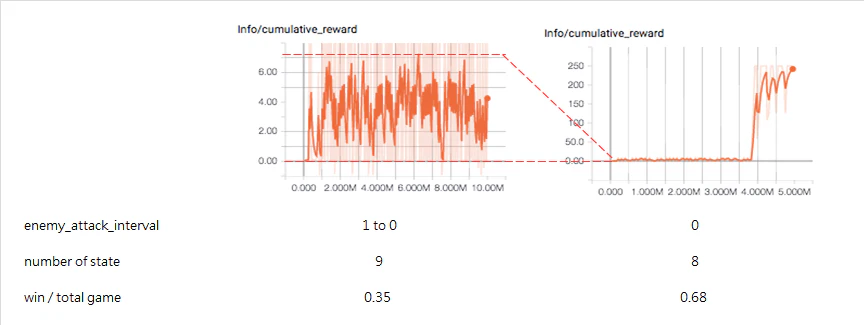
最後に
今まで2ヶ月ちかく動かしてみて私なりにわかったことを記載します。
-
stateパラメータは集約する
上記で記載したとおりです。パラメータが1つ増えるだけで学習時間は飛躍的に伸びてしまいます。 -
バグは修正する
当たり前のことなんですが、存在すると正しい学習結果が得られません。
また、ゲームとして適切なつくりであることが大切です。
物理演算的にごまかしてなんとか動いているみたいな箇所があると、そこが学習を阻害する要因になったりしました。