この記事は2024年5月2日に弊社ブログにて公開されたものを移植したものです。
古い情報が含まれている可能性がありますのでご注意ください。
本記事ではAmazon Transcribeを、GoogleColaboratoryで実行してみます。さらに、カスタムボキャブラリーを適用して動かします。Amazon TranscribeのAPIをPythonで叩いてみたい方や、追加機能を試したい方は是非ご覧ください。
Amazon Transcribeを始める前に
Amazon Transcribeを利用するにはAWSアカウントが必要です。またAWSには様々なサービスに対して無料利用枠というものが用意されており、一部サービスは一定期間無料で使用できます。Amazon Transcribeも無料利用枠が用意されているのでそちらを利用します。無料利用枠を使い切っている場合は料金がかかってきますのでご注意ください。Amazon Transcribeの料金はこちらからご確認ください。
AWSの準備
GoogleColaboratoryで動かす前にAmazon Transcribeを動かす為の準備をします。最低限の設定しか行っていないため、接続制限等の細かな設定は各自でお願いします。
- IAMダッシュボードを開く
- 左側のハンバーガーメニュー>アクセス管理>ユーザーを選択
- 権限を付与したいユーザーを選択
- 許可を追加▼を押下
- 許可オプションで『ポリシーを直接アタッチする』を選択
- 許可ポリシーで『AmazonTranscribeFullAccess』を検索し、チェックマークを入れる
- 上記の選択が終わったら次へ
- 許可を追加を押下
- アクセスキーを作成を押下
- AWSの外部で実行せれるアプリケーションを選択し次へ
- アクセスキーを作成を押下
- アクセスキーたちが発行されるので保存する
音声認識の実行手順
まずは、GoogleColaboratoryに必要事項を書いていきます。コードを書く前に音声認識したい音声ファイルをアップロードしてきます。
左のバーのファイルをクリックし、開いた箇所(下記画像の赤枠部分)へ音声認識させたい音声ファイルをドラック&ドロップします。
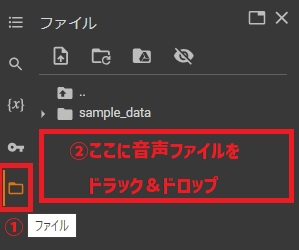
GoogleColaboratoryに必要事項を書いていきます。
#AWS
!pip install amazon-transcribe
!python -m pip install amazon-transcribe
!git clone https://github.com/awslabs/amazon-transcribe-streaming-sdk.git
%cd "amazon-transcribe-streaming-sdk"
!python -m pip install .
!pip install aiofile
コードは公式のgitに掲載されているQuick Startをベースに一部変更して利用します。アクセスキー、シークレットアクセスキー、音声ファイルのパスは各自のものに書き換えてください。
import os
import asyncio
import aiofile
import nest_asyncio
from amazon_transcribe.client import TranscribeStreamingClient
from amazon_transcribe.handlers import TranscriptResultStreamHandler
from amazon_transcribe.model import TranscriptEvent
from amazon_transcribe.utils import apply_realtime_delay
os.environ['AWS_ACCESS_KEY_ID'] = ''
os.environ['AWS_SECRET_ACCESS_KEY'] = ''
SAMPLE_RATE = 16000
BYTES_PER_SAMPLE = 2
CHANNEL_NUMS = 1
AUDIO_PATH = "アップした音声ファイルのパス"
CHUNK_SIZE = 1024 * 8
REGION = "ap-northeast-1" #音声認識するリージョンの指定(今回はアジアパシフィック(東京))
class MyEventHandler(TranscriptResultStreamHandler):
async def handle_transcript_event(self, transcript_event: TranscriptEvent):
results = transcript_event.transcript.results
for result in results:
if result.is_partial is False:
for alt in result.alternatives:
print(alt.transcript)
async def basic_transcribe():
# Setup up our client with our chosen AWS region
client = TranscribeStreamingClient(region=REGION)
# Start transcription to generate our async stream
stream = await client.start_stream_transcription(
language_code="ja-JP", #言語設定
media_sample_rate_hz=SAMPLE_RATE,
media_encoding="pcm",
# vocabulary_name = "my-first-vocabulary"
)
async def write_chunks():
async with aiofile.AIOFile(AUDIO_PATH, "rb") as afp:
reader = aiofile.Reader(afp, chunk_size=CHUNK_SIZE)
await apply_realtime_delay(
stream, reader, BYTES_PER_SAMPLE, SAMPLE_RATE, CHANNEL_NUMS
)
await stream.input_stream.end_stream()
handler = MyEventHandler(stream.output_stream)
await asyncio.gather(write_chunks(), handler.handle_events())
loop = asyncio.get_event_loop()
loop.run_until_complete(basic_transcribe())
実行してみます。今回自分で用意した音声は『本日の東京の天気は晴れ。明日の大阪の天気は曇りです。』という音声なのでどのような結果が出るでしょうか。

無事音声が認識されました、認識内容も問題ありません。
カスタムボキャブラリーを作成する
カスタムボキャブラリーは特定の単語やフレーズを正確に認識しやすくするための機能です。これだけ言われても分かりづらいので実際に使ってみましょう。

『赤いリンゴがあります』という音声を用意し、音声認識を行うと上記の結果が出ました。『赤い』を『紅い』に、『リンゴ』を『林檎』と優先的に出力されるようにしていきたいと思います。
ではカスタムボキャブラリーを作成していきたいと思います。AWSのAmazon Transcribeのカスタムボキャブラリーのボキャブラリーを作成というボタンから作成できます。カスタムボキャブラリーを使用するには音声認識と同じリージョンでなければエラーが起こります。今回音声認識のリージョンはアジアパシフィック(東京)なのでカスタムボキャブラリーも同じリージョンにしてください。
リージョンを正しく設定したらボキャブラリーを作成していきます。カスタムボキャブラリー名は好きな名前を設定してください。設定した名前を後でコードに記載するので分かりやすい名前だと後で楽になります。日本語のカスタムボキャブラリーを作成するので、設定言語は日本語にします。語彙の作成とインポートはコンソールでボキャブラリーを作成を選択して、形式に沿ったファイルをアップすることでも作成することもできます。
ボキャブラリーを作成を選択すると語彙の表示と編集が表示されると思います。行を追加し、下記画像のようにフレーズに『赤い』『リンゴ』、DisplayAsに『紅い』『林檎』を入力します。すべて入力できたら、ボキャブラリー作成を押し完了です。カスタムボキャブラリーの作成が進行中と表示されるので少し待ちます。
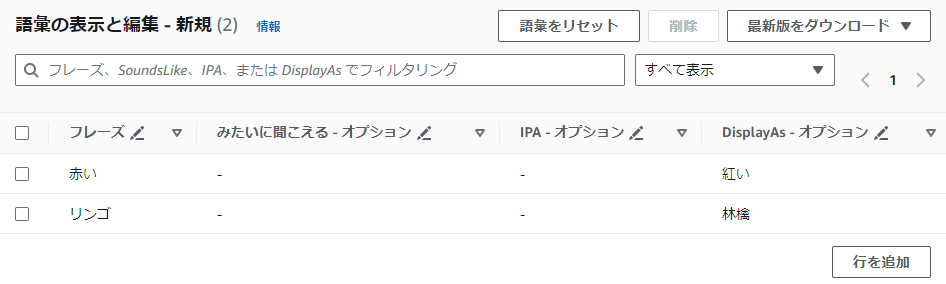
先ほどのコードのvocabulary_nameのコメントアウトを外し、作成したカスタムボキャブラリー名を記入して実行します。
async def basic_transcribe():
# Setup up our client with our chosen AWS region
client = TranscribeStreamingClient(region=REGION)
# Start transcription to generate our async stream
stream = await client.start_stream_transcription(
language_code="ja-JP", #言語設定
media_sample_rate_hz=SAMPLE_RATE,
media_encoding="pcm",
vocabulary_name = "作成したカスタムボキャブラリー名"
)
『赤い』が『紅い』に、『リンゴ』が『林檎』と認識されました。

終わりに
AWSのAmazon Transcribeを利用して、Google Colaboratory上で実行する方法について説明しました。カスタムボキャブラリーの適用を行い、実際の音声ファイルを用いてその効果を検証することができました。これにより、特定の単語やフレーズをより正確に認識することが可能となり、音声認識技術の応用範囲が広がることをお見せすることができたと思います。